这些知识点你都知道吗,测试你的C++入门程度
Posted 一去丶二三里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这些知识点你都知道吗,测试你的C++入门程度相关的知识,希望对你有一定的参考价值。
做公众号以来,很多人都私信问我如何入门C++,其实之前也有很多人问过这个问题,觉得还是有必要写一篇完整的文章,给大家参考。
既然要写一篇文章,程序喵本着对读者负责任的态度,在写这篇文章前我咨询了好多人,既有身经百战的大佬,也有初入职场的精英码农,我也查阅了好多入门C++相关的资料(发现内容都差不多),结合自身经历,整理出一篇文章分享给大家。

不同人入门C++的方式应该都有所不同,就我自己而言,大一先学习了C语言,稀里糊涂一个学期过去了,用C语言做个控制台界面的学生管理系统,然后大一下学期学习C++时,恰好上了一门编译原理的课,当时实现了个小编译器,做过校园导航系统,小型数据库系统,有点小成就感,原以为算是“C++入门”了吧。现在想想其实很多东西学生时期还是知其然而不知其所以然。之后在工作中使用C++做项目,才是真正意义的“入门”了,所以对我而言,可能更多的是依靠“实战”去入门的C++。
本篇文章我不会全篇介绍入门C++需要看什么书,看什么视频,因为这种文章太多了,相信读者看的已经眼花缭乱了,正文主要介绍C++的一些基础的知识点,基本上对每个知识点我会贴一段示例代码,读者如果要具体了解某个知识点,可以去文末的书籍或视频中针对性学习,我会在文末列出比较容易入门的几本书和视频。老规矩,废话停止,直接开始:

C++是什么?
通俗的讲,可以简单理解为C语言的延伸语言,这里会主要介绍C++相对于C语言来说,有哪些特性。
C++的一些特点:
允许重载:函数名相同,参数类型不同,参数个数不同,即可重载,使用见下面代码:
// overload.cc
#include <iostream>
using std::cout;
void func(int a) { cout << "func " << a << "\\n"; }
void func(int a, int b) { cout << "func " << a << " " << b << "\\n"; }
void func(float a) { cout << "func " << a << "\\n"; }
int main() {
func(1);
func(1, 2);
func(1.1f);
return 0;
}
namespace:namespace是什么?其实就相当于为变量和函数划个范围
如果不加namespace会有什么问题:
// namespace.cc
#include <iostream>
void func() {
std::cout << "n1 func" << "\\n";
}
void func() {
std::cout << "n2 func" << "\\n";
}
// redefinition of 'func'
int main() {
func();
return 0;
}
结果大家可能都知道,这样的代码编译会报错:redefinition of 'func'
一般规定一个程序内不允许同一个强符号有多个定义,那怎么解决?
可使用namespace:
// namespace.cc
#include <iostream>
namespace n1 {
void func() {
std::cout << "n1 func"
<< "\\n";
}
} // namespace n1
namespace n2 {
void func() {
std::cout << "n2 func"
<< "\\n";
}
} // namespace n2
// redefinition of 'func'
int main() {
n1::func();
n2::func();
return 0;
}
这样编译成功,加入namespace后其实对编译器来说就是两个不同的函数,因为生成的是两个不同的符号:
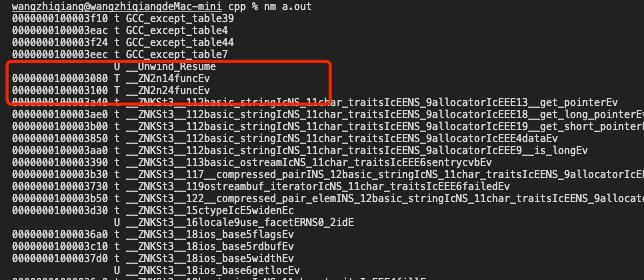
注意:不要过多using namespace xxx,例如using namespace std;可能就容易引起符号冲突问题,
可以使用using std::cout这种方式。
class & struct:
很多面试官可能都会问class和struct的区别?具体答案我这里就不贴出来了,大家自己搜索答案就可,或者留言问我,它俩在C++里其实没什么区别,就是默认权限不同而已。
这里需要掌握几个知识点:
如何定义一个类
构造函数的定义及使用
析构函数的定义及使用
拷贝构造函数的定义及使用
移动构造函数的定义及使用
赋值构造函数的定义及使用
移动赋值函数的定义及使用
下面贴出一段示例代码:
// class.cc
#include <iostream>
#include <memory>
using std::cout;
class TClass {
public:
TClass() {
cout << "构造函数1" << "\\n";
}
TClass(int a) : a_(a) {
cout << "构造函数2" << "\\n";
data_ = new int[10];
}
TClass(const TClass &a) : a_(a.a_) {
cout << "拷贝构造函数" << "\\n";
data_ = new int[10];
memcpy(data_, a.data_, 10 * sizeof(int));
}
TClass(TClass &&a) : a_(a.a_), data_(a.data_) {
a.data_ = nullptr;
cout << "移动构造函数" << "\\n";
}
TClass &operator=(TClass &a) {
a_ = a.a_;
if (data_) delete[] data_;
data_ = new int[10];
memcpy(data_, a.data_, 10 * sizeof(int));
cout << "赋值构造函数" << "\\n";
return *this;
}
TClass &operator=(TClass &&a) {
a_ = a.a_;
if (data_) delete[] data_;
data_ = a.data_;
a.data_ = nullptr;
cout << "移动赋值函数" << "\\n";
return *this;
}
~TClass() {
cout << "析构函数" << "\\n";
if (data_) delete[] data_;
}
void func() { cout << "a " << a_ << " \\n"; }
private:
int a_;
int *data_;
};
int main() {
TClass a(1); //构造函数2
TClass b(a); //拷贝构造函数
TClass c(std::move(a)); //移动构造函数
c = b; //赋值构造函数
c = std::move(b); //移动赋值函数
TClass d = c; //拷贝构造函数
TClass e = std::move(d); //移动构造函数
a.func();
b.func();
return 0;
}
模板
模板主要分为函数模板和类模板,下面有示例代码:
// template.cc
#include <iostream>
using std::cout;
template <typename T>
T max(T a, T b) { // 函数模板
return a > b ? a : b;
}
template <typename T>
struct Vec { // 类模板
Vec(T a) : a_(a) {}
void func() { cout << "func value " << a_ << "\\n"; }
T a_;
};
int main() {
cout << "max(1, 2) " << max(1, 2) << "\\n";
cout << "max(1.1f, 2.2f) " << max(1.1f, 2.2f) << "\\n";
cout << "max(1.10, 2.20) " << max(1.10, 2.20) << "\\n";
Vec<int> vi(1);
vi.func();
Vec<float> vf(1.1f);
vf.func();
return 0;
}
引用:C++里多了个引用的概念,很多人面试应该有被问到过引用和指针有什么区别吧?
关于指针和引用,在这里强烈推荐大家阅读《面试系列之指针和引用的使用场景》这篇文章,通俗易懂的纯干货型文章。
大家可以记住一个关键点就是引用追求从一而终,它的指向永远不会变,而指针是个善变的东西,它的指向随时可以改变,一般开发中会使用const &方式进行参数传递,省去不必要的对象拷贝:
void func(const A& a) {}
多态:这是C++语言所支持的或者说面向对象的一个重要特性,直接看代码:
// polymorphic.cc
#include <iostream>
using std::cout;
struct Base {
Base() {
cout << "base construct" << "\\n";
}
virtual ~Base() {
cout << "base destruct" << "\\n";
}
void FuncA() {}
virtual void FuncB() { cout << "Base FuncB \\n"; }
int a;
int b;
};
struct Derive1 : public Base {
Derive1() { cout << "Derive1 construct \\n"; }
~Derive1() { cout << "Derive1 destruct \\n"; }
void FuncB() override { cout << "Derive1 FuncB \\n"; }
};
struct Derive2 : public Base {
Derive2() { cout << "Derive2 construct \\n"; }
~Derive2() { cout << "Derive2 destruct \\n"; }
void FuncB() override { cout << "Derive2 FuncB \\n"; }
};
int main() {
{
Derive1 d1;
d1.FuncB();
}
cout << "======= \\n";
{
Derive1 d1;
d1.FuncB();
Base &b1 = d1;
b1.FuncB();
}
cout << "======= \\n";
{
Derive2 d2;
d2.FuncB();
Base &b2 = d2;
b2.FuncB();
}
cout << "======= \\n";
{
Base b;
b.FuncB();
}
cout << "======= \\n";
{
Base *b = new Derive1();
b->FuncB();
delete b;
}
return 0;
}
这里简单介绍了实现多态的两种方式:通过指针或者通过引用。
注意:
构造函数不能是虚函数
基类析构函数最好是虚函数
尽量不要使用多继承
new和delete
C++内存申请和释放会使用new和delete关键字,而基本不会使用C语言中的malloc和free,可看下面的示例代码:
// new_delete.cc
#include <iostream>
using std::cout;
struct A {
int a_;
};
int main() {
A* a1 = new A;
delete a1;
A* a2 = new A[10];
delete[] a2;
return 0;
}
注意:
new和delete要配对使用
new[]和delete[]要配对使用
maloc和free要配对使用
类型转换:既然使用了C++语言,在类型转换方面就一定要使用C++风格,这比C语言风格的强制类型转换更安全。
static_cast
float f = 1.0f;
int a = static_cast<int>(f);
const_cast
const char* cc = "hello world\\n";
char* c = const_cast<char*>(cc);
dynamic_cast
struct Base {};
struct Derive : public Base {};
void func() {
Base* base = new Derive;
Derive* derive = dynamic_cast<Derive*>(base);
}
reinterpret_cast
A *a = new A;
void* d = reinterpret_cast<void*>(a);
C++11常用新特性
C++的重大变革肯定是C++11啦,C++11标准引入了很多有用的新特性,这仿佛打开了新世界的大门,让C++开发者开发效率大幅提高,下面我会列出C++11常用的新特性,并附上简单的实例代码:
auto & decltype:用于类型推导
auto用于推导变量类型,decltype用于推导表达式返回值类型
// auto_decltype.cc
int main() {
auto a = 10; // 10是int型,可以自动推导出a是int
int x = 0;
decltype(x) y; // y是int类型
decltype(x + y) z; // z是int类型
return 0;
}
std::function:用于封装一个函数,功能类似于函数指针,但却比函数指针方便的多。
// function.cc
#include <functional>
#include <iostream>
using std::cout;
void printNum(int i) { cout << "print num " << i << "\\n"; }
typedef void (*FuncPtr)(int i);
int main() {
FuncPtr ptr = printNum;
ptr(2);
void (*ptr2)(int) = printNum;
ptr2(3);
std::function<void(int)> func = printNum;
func(1);
return 0;
}
lambda表达式:随时可方便定义的一个匿名函数。
// lambda.cc
#include <iostream>
using std::cout;
int main() {
auto func = [](int a) -> int { return a + 1; };
int b = func(2);
cout << b << "\\n";
return 0;
}
注意:lambda表达式的变量捕获方式分为值捕获和引用捕获
int a = 0;
auto f1 = [=](){ return a; }; // 值捕获a
cout << f1() << endl;
auto f2 = [=]() { return a++; }; // 修改按值捕获的外部变量,error
auto f3 = [=]() mutable { return a++; };
std::function和std::bind使得我们平时编程过程中封装函数更加的方便,而lambda表达式将这种方便发挥到了极致,可以在需要的时间就地定义匿名函数,不再需要定义类或者函数等,在自定义STL规则时候也非常方便,让代码更简洁,更灵活,开发效率也更高。
std::thread:C++11中使用std::thread创建线程,使用非常的方便,直接看代码:
void func() { std::cout << "new thread \\n"; }
int main() {
std::thread t(func);
if (t.joinable()) {
t.join(); // 或者t.detach();
}
return 0;
}
注意:使用std::thread一定要记得join或者detach。
RAII:既然使用C++,那一定要理解RAII风格(利用对象生命周期管理资源),继续往下看:
如果不使用RAII风格,加锁解锁我们怎么办?
// 不使用RAII
void func() {
std::mutex mutex;
mutex.lock();
if (xxx) {
mutex.unlock();
return;
}
if (xxxx) {
mutex.unlock();
return;
}
...
mutex.unlock();
}
而如果使用RAII呢:
void func() {
std::unique_lock<std::mutex> lock(mutex);
if (xxx) return;
if (xxxx) return;
...
}
是不是方便了很多,这里介绍了std::unique_lock的使用,还有一种锁是std::lock_guard,使用方式相同,至于它们之间有什么区别,我这里卖个关子,大家可以自行查找哈,锻炼一下自己的搜索能力。
智能指针也是典型的RAII风格,如果不使用智能指针管理内存是这样:
void func() {
A* a = new A;
if (xxx) {
delete a;
return;
}
if (xxxx) {
delete a;
return;
}
...
delete a;
}
而如果使用智能指针是这样:
void func() {
std::shared_ptr<A> sp = std::make_shared<A>(); // unique_ptr类似
std::shared_ptr<A> sp = std::shared_ptr<A>(new A); // 尽可能使用make_shared或者make_unique(C++14)
if (xxx) return;
if (xxxx) return;
...
}
又方便了很多吧,unique_ptr和shared_ptr的区别本文也不介绍,文章最后我会列出学习资料,在学习资料里可以找到答案。
原子操作:使用std::atomic可达到原子效果,使用方法:
std::atomic<int> ai;
ai++;
ai.store(100);
int a = ai.load();
enum class:带有作用域的枚举类型,可用于完全替代enum,为什么要使用enum class呢?我们先看一段直接使用enum的代码:
enum AColor {
kRed,
kGreen,
kBlue
};
enum BColor {
kWhite,
kBlack,
kYellow
};
int main() {
if (kRed == kWhite) {
cout << "red == white" << endl;
}
return 0;
}
不带作用域的枚举类型可以自动转换成整形,且不同的枚举可以相互比较,代码中的kRed居然可以和kWhite比较,这都是潜在的难以调试的bug,而这种完全可以通过有作用域的枚举来规避。
所以出现了enum class:
enum class AColor {
kRed,
kGreen,
kBlue
};
enum class BColor {
kWhite,
kBlack,
kYellow
};
int main() {
if (AColor::kRed == BColor::kWhite) { // 编译失败
cout << "red == white" << endl;
}
return 0;
}
使用enum class可以在编译层面就规避掉一些难以调试的bug,使代码健壮性更高。
condition_variable:条件变量
std::condition_variable cv;
std::mutex mutex_;
void func1() {
std::unique_lock<std::mutex> lock(mutex_);
--count;
if (count == 0) cv.notify_all();
}
void func2() {
std::unique_lock<std::mutex> lock(mutex_);
while (count) {
cv.wait(lock);
}
}
注意:不要直接用wait,而要记得使用wait(mutex, cond)或者while(cond) {wait(mutex);}
nullptr:表示空指针可以使用nullptr,不要使用NULL
void func(char*) {
cout << "char*";
}
void func(int) {
cout << "int";
}
int main() {
func(NULL); // 编译失败 error: call of overloaded ‘func(NULL)’ is ambiguous
func(nullptr); // char*
return 0;
}
chrono:时间相关函数可以考虑使用chrono库,例如休眠某个时间段:
void customSleep() {
std::this_thread::sleep_for(std::chrono::milliseconds(5));
std::this_thread::sleep_for(std::chrono::seconds(5));
}
使用chrono可以精确的指定时间单位,可以明确的之道休眠的是几毫秒还是几秒,非常方便。
chrono中包含三种时钟:
steady_clock:单调时钟,只会增加,常用语记录程序耗时
system_clock:系统时钟,会随系统时间改动而变化
high_resolution_clock:当前系统最高精度的时钟,通常就是steady_clock
拿计时举例:
void customSleep() {
std::this_thread::sleep_for(std::chrono::milliseconds(5));
std::this_thread::sleep_for(std::chrono::seconds(5));
}
int main() {
std::chrono::time_point<std::chrono::high_resolution_clock> begin = std::chrono::high_resolution_clock::now();
customSleep();
auto end = std::chrono::high_resolution_clock::now();
auto diff = end - begin;
long long diffCount = std::chrono::duration_cast<std::chrono::milliseconds>(diff).count();
cout << diffCount << "\\n";
return 0;
}
STL
使用C++有几个能不用STL标准库的,这里列出了常用的STL,并贴出使用代码。
std::vector:可以理解为动态可自动扩容的数组,使用vector需要掌握几个常用函数的使用
resize
reserve
capacity
clear
swap
at
灵活使用
void func() {
std::vector<int> vec;
std::cout << "vector size " << vec.size() << "\\n"; // vector size 0
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 0
vec.push_back(1);
vec.emplace_back(2);
vec.push_back(3);
std::cout << "====================== \\n";
std::cout << "vector size " << vec.size() << "\\n"; // vector size 3
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 4
vec.reserve(200);
std::cout << "====================== \\n";
std::cout << "vector size " << vec.size() << "\\n"; // vector size 3
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 200
vec.resize(20);
std::cout << "====================== \\n";
std::cout << "vector size " << vec.size() << "\\n"; // vector size 20
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 200
vec.clear();
std::cout << "====================== \\n";
std::cout << "vector size " << vec.size() << "\\n"; // vector size 0
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 200
std::vector<int>().swap(vec);
std::cout << "====================== \\n";
std::cout << "vector size " << vec.size() << "\\n"; // vector size 0
std::cout << "vector capacity " << vec.capacity() << "\\n"; // vector capacity 0
}
注意:for循环中erase某一个节点时要处理好迭代器的指向问题
void erase(std::vector<int> &vec, int a) {
for (auto iter = vec.begin(); iter != vec.end();) { // 正确
if (*iter == a) {
iter = vec.erase(iter);
} else {
++iter;
}
}
for (auto iter = vec.begin(); iter != vec.end(); ++iter) { // error
if (*iter == a) {
vec.erase(iter);
}
}
}
继续注意:remove函数不会真正的删除某个元素,它只会把某个要删除的元素移动到容器尾部,真正要删除还需使用erase,需要remove要和erase搭配使用。
bool isOdd(int i) { return i & 1; }
void print(const std::vector<int>& vec) {
for (const auto& i : vec) {
std::cout << i << ' ';
}
std::cout << std::endl;
}
int main() {
std::vector<int> v = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
print(v);
std::remove(v.begin(), v.end(), 5); // error
print(v);
v.erase(std::remove(v.begin(), v.end(), 5), v.end());
print(v);
v.erase(std::remove_if(v.begin(), v.end(), isOdd), v.end());
print(v);
}
std::array:开发时可以考虑用std::array代替普通数组,因为它有获取长度,遍历,边界检查等功能
int main() {
std::array<int, 10> array;
// int array[10];
array.at(10) = 20; // terminating with uncaught exception of type std::out_of_range: array::at
std::cout << "hello " << array.at(10) << "\\n";
return 0;
}
std::map & std::unordered_map:都是key-value级别的字典,使用方式相同,一个使用树实现,一个使用哈希表实现,可根据需求选择具体使用哪种字典。
int main() {
std::map<int, std::string> map;
map[1] = std::string("hello");
std::cout << map[1] << "\\n";
return 0;
}
std::list:链表
int main() {
std::list<int> list{1, 2, 3, 2};
list.sort();
// std::sort(list.begin(), list.end());
for (auto i : list) {
std::cout << i << " ";
}
std::cout << "\\n";
return 0;
}
注意:list的排序需要使用list.sort(),不能使用std::sort
std::tuple:我个人经常使用,tuple像结构体一样,也可以理解为pair的延伸
struct T {
int a_;
int b_;
int c_;
T(int a, int b, int c) : a_(a), b_(b), c_(c) {}
};
int main() {
T a(1, 2, 3);
std::cout << "a " << a.a_ << " b " << a.b_ << " c " << a.c_ << "\\n";
std::tuple<int, int, int> tuple = std::make_tuple(2, 3, 4);
std::cout << "a " << std::get<0>(tuple) << " b " << std::get<1>(tuple) << " c " << std::get<2>(tuple) << "\\n";
return 0;
}
编码规范
每一门语言基本都有几种常见的编码规范,想必大多数C++开发者都会基于google的C++编码规范去开发,下面是格式化代码常用的一些配置:
// .clang-format
BasedOnStyle: Google
IndentWidth: 4
ColumnLimit: 120
SortIncludes: true
MaxEmptyLinesToKeep: 2
下面再列出一些常见的命名规则:
文件命名:文件名字要全部小写,中间用_相连,后缀名为.cc .cpp和.h
hello_world.cc
hello_world.cpp
hello_world.h
类型命名:类型名称的每个单词首字母均大写:
struct MyExcitingClass;
常量和枚举命名:声明为 constexpr 或 const 的变量, 或在程序运行期间其值始终保持不变的, 命名时以 “k” 开头, 大小写混合
const int kDaysInAWeek = 7;
函数命名:大驼峰方式
MyExcitingFunction()
命名空间命名:全部小写
namespace abcdefg{}
成员变量命名:小写字母加下划线分隔,最后加个下划线
普通变量命名:小写字母加下划线分隔
struct A {
int a_;
}
void f(int a) {
int b;
}
代码:
struct A {
int a_;
}
void f(int a) {
int b;
}
规范要点总结
下面是我查阅很多资料又结合自身工作经验总结的一些要点:
每个头文件都要使用#ifndef #define或者#pragma once修饰,避免被重复引用
每个命名都要尽可能表达清晰其具体含义,除非特别常用,否则不要使用缩写,宁可名字特别长
鼓励在 .cc 文件内使用匿名命名空间或 static 声明. 使用具名的命名空间时, 其名称可基于项目名或相对路径. 尽量不要使用 using 指示
一行尽量不要超过120个字符,一个函数尽量不要超过40行(性能优化除外),同时一个文件尽量控制在500行内.
所有的引用形参如不做改动一律加const,在任何可能的情况下都要使用 const或constexpr
new内存的地方尽量使用智能指针,c++11 就尽量用std::unique_ptr
合理使用移动语义或者COW,减少内存拷贝
使用 C++ 的类型转换, 如 static_cast<>(). 不要使用 int y = (int)x 或 int y = int(x) 等转换方式
明确使用前置++还是后置++的具体含义,如不考虑返回值,尽量使用前置++ (++i)
不要使用uint类型,如果需要使用大整型可以考虑int64,否则类型的隐式类型转换会带来很多麻烦
如无特殊必要不要使用宏,可以考虑使用const或constexpr替代宏,宏的全局作用域很麻烦,如果非要用在马上要使用时才进行 #define, 使用后要立即 #undef
尽可能用 sizeof(varname) 代替 sizeof(type).使用 sizeof(varname) 是因为当代码中变量类型改变时会自动更新. 或许会用 sizeof(type) 处理不涉及任何变量的代码,比如处理来自外部或内部的数据格式,这时用变量就不合适了
类型名如果过长的话可以考虑使用auto关键字
注释统一使用 // ,不要通过注释禁用代码,擅用git,不要为易懂的代码写注释
写完代码后记得format,每个项目最好都有统一的.clang_format文件
使用C++的string替代C语言风格的char*
尽量使用STL标准库的容器而不是C语言风格的数组,数组的越界访问之类当时是不会报错的,反而可能弄脏堆栈信息,导致奇奇怪怪难以排查的bug
可以更多的使用模板元编程,尽量多的使用constexpr等编译期计算,编译器是我们的好搭档,个人认为模板元编程以后会是C++的主流技术
可以考虑更多的使用异常处理方式,而不是C语言风格的errno错误码等
常用大括号控制生命周期,能提前结束的就可以提前结束
注意memcpy和memset的使用,仅适用于POD结构
理解内存对齐,可以使结构体更小,也可以使访问速度更快
基类析构函数一定要加virtual修饰
谨慎使用多继承,可能导致菱形继承
全局变量不要有任何依赖关系
这里我只列出来两本学习C++的书,可以按顺序阅读,我相信读完并理解这两本书的内容可以算是入门C++啦~
书
《C++ Primer Plus》 注意是Plus!
《Effective Modern C++》
视频
有喜欢看书的也有喜欢看视频的,这里再推荐两个比较好的C++视频教程:
①清华大学郑莉教授的视频,通俗易懂
https://www.bilibili.com/video/BV1QE41147RT?from=search&seid=8449657388898463710
②还有一个是技术交流群群友推荐,也是清华大学的课程
https://www.bilibili.com/video/BV1yk4y1d7ns?p=1
③喜欢英文的同学可以看看MIT或斯坦福的C++课程
具体是看书快还是看视频快,因人而异。适合自己的才是最实在、最好的。
再推荐两个比较好的C++学习网站:
最好的肯定是cppreference啦,不用多说,也可以看看cppfaq,里面的很多问题可以增长我们的见识,让我们对C++的理解也更加深刻。
http://www.sunistudio.com/cppfaq/
C++学习资料免费获取方法:关注程序喵大人,后台回复“程序喵”即可免费获取40万字C++进阶独家学习资料。
以上是关于这些知识点你都知道吗,测试你的C++入门程度的主要内容,如果未能解决你的问题,请参考以下文章