BatchNorm的相关细节
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BatchNorm的相关细节相关的知识,希望对你有一定的参考价值。
训练和测试的区别
训练的时候会用当前batch的mean和var,同时也会滑动平均计算全局的running_mean和running_var,然后inference的时候就用全局的running_mean和running_var
- 训练时,当前batch的var是除以m,

- 而测试时用到的running_var在计算时是除以m-1,是无偏估计
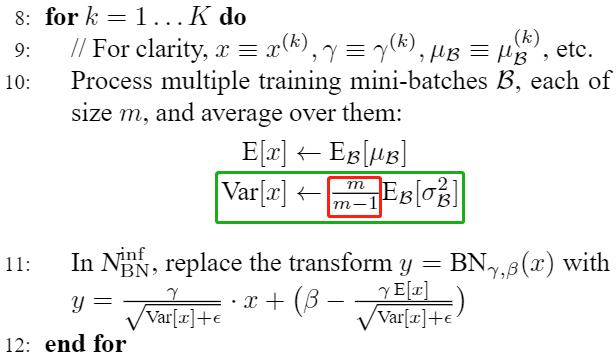
- 为什么训练时计算的var和running_var不一样呢?
样本方差的无偏估计与(n-1)的由来:我们在计算随机变量的均值和方差时,一般情况下无法知道该随机变量的分布公式,因此我们通常会采样一些样本,然后计算这些样本的均值和方差作为该随机变量的均值和方差。由于计算这些样本的方差时减的是样本均值而不是随机变量的均值,而样本均值是和采样的样本有关的(知道n-1个样本和均值可以推断出第n个样本),少了一个自由度,因此这个方差是有偏估计,如果要得到无偏估计,需要乘以 n/n-1
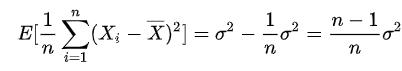
训练时,计算当前batch var时,当前batch的样本就是该随机变量的所有样本了,因此支持除以n就好了。而running_var是全局样本的var,因此当前batch的样本只是该随机变量的部分采样样本,因此为了是无偏估计,必须乘以 n/n-1
BN解决的问题
-
BN论文:缓解了Internal Covariate Shift(ICS)问题(训练和测试样本分布不一致),但是后续的论文里降到加上ICS也仍然可以取得好的结果
-
主流观点,Batch Normalization调整了数据的分布,不考虑激活函数,它让每一层的输出归一化到了均值为0方差为1的分布,这保证了梯度的有效性


-
可以使用更大的学习率,文[2]指出BN有效是因为用上BN层之后可以使用更大的学习率,从而跳出不好的局部极值,增强泛化能力,在它们的研究中做了大量的实验来验证。
-
损失平面平滑。文[3]的研究提出,BN有效的根本原因不在于调整了分布,因为即使是在BN层后模拟ICS,也仍然可以取得好的结果。它们指出,BN有效的根本原因是平滑了损失平面。之前我们说过,Z-score标准化对于包括孤立点的分布可以进行更平滑的调整。
running_var计算代码
当前batch var计算代码
pytorch issue
为什么样本方差(sample variance)的分母是 n-1? - 张英锋的回答 - 知乎
样本方差的无偏估计与(n-1)的由来
深度学习中 Batch Normalization为什么效果好? - 我不坏的回答 - 知乎
深度学习中 Batch Normalization为什么效果好? - 言有三的回答 - 知乎
深度学习中 Batch Normalization为什么效果好? - 魏秀参的回答 - 知乎
以上是关于BatchNorm的相关细节的主要内容,如果未能解决你的问题,请参考以下文章
BBuf的CUDA笔记二,解析 OneFlow BatchNorm 相关算子实现
BBuf的CUDA笔记二,解析 OneFlow BatchNorm 相关算子实现
Batch Normalization 在CNN中的实现细节