爬虫日记(71):用OCR来对抗字体反爬
Posted caimouse
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫日记(71):用OCR来对抗字体反爬相关的知识,希望对你有一定的参考价值。
在开发爬虫的过程中,经常会遇到一些网站,用浏览器查看是正常的,但是当你去查看html的源码时,就会与显示的不一样,如下面的网站:

这段是在浏览器里查看的,接着来查看一下HTML源码里显示的:
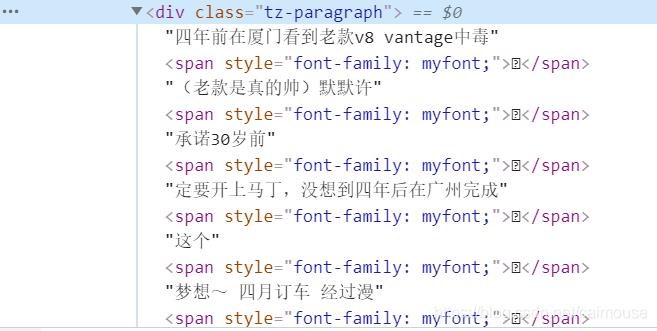
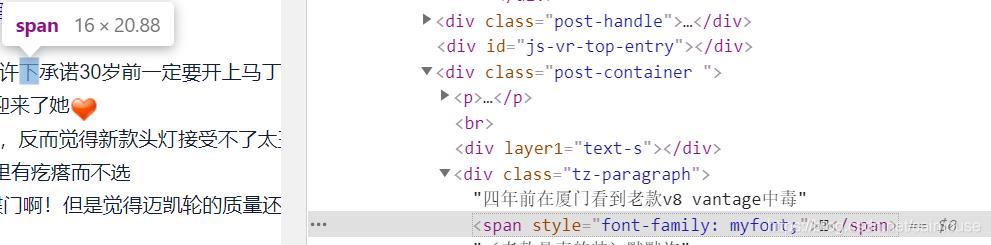
可以看到这一段文字,已经被自定义的字体进行分割,不可能直接得到原文了,它的对应关系如下:
以上是关于爬虫日记(71):用OCR来对抗字体反爬的主要内容,如果未能解决你的问题,请参考以下文章