MLP回归,无需卷积自注意力,纯多层感知机视觉架构媲美CNNViT
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MLP回归,无需卷积自注意力,纯多层感知机视觉架构媲美CNNViT相关的知识,希望对你有一定的参考价值。
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路

机器之心报道
当前,卷积神经网络(CNN)和基于自注意力的网络(如近来大火的 ViT)是计算机视觉领域的主流选择,但研究人员没有停止探索视觉网络架构的脚步。近日,来自谷歌大脑的研究团队(原 ViT 团队)提出了一种舍弃卷积和自注意力且完全使用多层感知机(MLP)的视觉网络架构,在设计上非常简单,并且在 ImageNet 数据集上实现了媲美 CNN 和 ViT 的性能表现。
计算机视觉的发展史证明,规模更大的数据集加上更强的计算能力往往能够促成范式转变。虽然卷积神经网络已经成为计算机视觉领域的标准,但最近一段时间,基于自注意力层的替代方法 Vision Transformer(ViT)实现新的 SOTA 性能。从技术上讲,ViT 模型延续了长久以来去除模型中手工构建特征和归纳偏置的趋势,并进一步依赖基于原始数据的学习。
近日,原 ViT 团队提出了一种不使用卷积或自注意力的 MLP-Mixer 架构(简称 Mixer),这是一种颇具竞争力并且在概念和技术上都非常简单的替代方案。
Mixer 架构完全基于在空间位置或特征通道重复利用的多层感知机(MLP),并且仅依赖于基础矩阵乘法运算、数据布局变换(如 reshape 和 transposition)和非线性层。

论文地址:https://arxiv.org/pdf/2105.01601.pdf
项目地址:https://github.com/google-research/vision_transformer/tree/linen
结果表明,虽然 Mixer 架构很简单,但取得了极具竞争力的结果。当在大型数据集(约 1 亿张图像)上进行预训练时,该架构在准确率 / 成本权衡方面能够媲美 CNN 和 ViT,实现了接近 SOTA 的性能,在 ImageNet 数据集上取得了 87.94% 的 top1 准确率。
对于该研究提出的 Mixer 架构,特斯拉 AI 高级总监 Andrej Karpathy 认为:「很好!1×1 卷积通常利用深度卷积实现堆叠或交替,但在这里,通道或空间混合得到简化或者实现完全对称。」

另一用户表示:「CV 领域网络架构的演变从 MLP 到 CNN 到 Transformer 再回到 MLP,真是太有意思了。」
不过,谷歌 DeepMind 首席科学家 Oriol Vinyals 也提出了质疑,他认为:「per-patch 全连接,那不就是卷积吗」

架构思路
下图 1 描述了 Mixer 的宏观架构,它以一系列图像块的线性投影(输入的形状为 patches × channels)作为输入,先将输入图片拆分为 patch,通过 Per-patch Fully-connected 将每个 patch 转换为 feature embedding,接着馈入 N 个 Mixer Layer,最后通过 Fully-connected 进行分类。
Mixer 架构采用两种不同类型的 MLP 层:channel-mixing MLP 和 token-mixing MLP。channel-mixing MLP 允许不同通道之间进行通信,token-mixing MLP 允许不同空间位置(token)之间进行通信。这两种类型的层交替执行以促进两个维度间的信息交互。
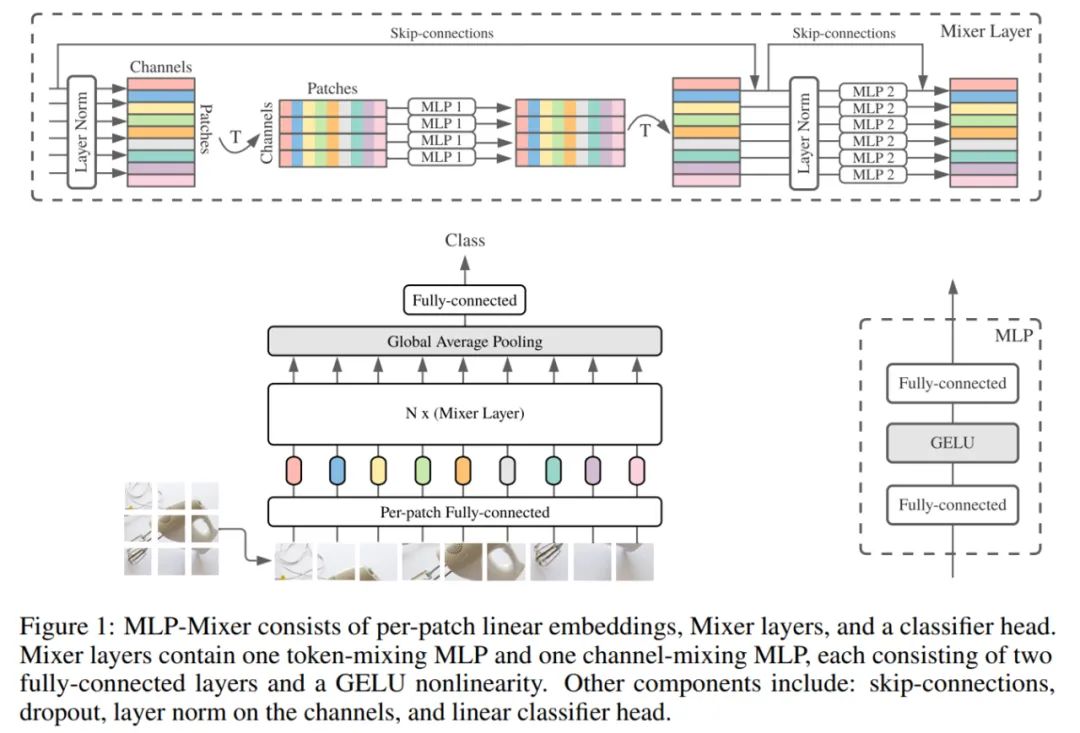
另外,在极端的情况下,Mixer 架构可以看做是一个特殊的 CNN,使用 1×1 卷积进行 channel mixing,同时全感受野和参数共享的的单通道深度卷积进行 token mixing。
设计思想
Mixer 架构的设计思想是清楚地将按位置(channel-mixing)操作 (i) 和跨位置(token-mixing)操作 (ii) 分开,两种操作都通过 MLP 来实现。
该架构如图 1 所示,Mixer 将一系列 S 个不重叠的图像 patch 作为输入,每个 patch 投影到所需的隐藏维度 C 上。这将产生二维实值(real-valued)输入表 X ∈ R^S×C。
Mixer 由大小相同的多个层组成。每个层由 2 个 MLP 块组成,其中,第一个块是 token-mixing MLP 块,第二个是 channel-mixing MLP 块。每个 MLP 块包含两个全连接层,以及一个单独应用于其输入数据张量的每一行的非线性层。Mixer 层描述如下:
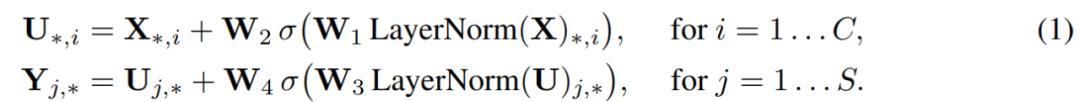
Mixer 中的每个层(初始 patch 投影层除外)都采用相同大小的输入,这种「各向同性(isotropic)」的设计与使用固定宽度的 Transformer 或其他域中的深度 RNN 大致相似。这不同于大多数具有金字塔结构的 CNN,即较深的层具有较低分辨率的输入,但是有较多通道(channel)。
除了 MLP 层,Mixer 还使用其他标准架构组件:跳远连接(skip-connection)和层归一化。此外,和 ViT 不同,Mixer 不使用位置嵌入,因为 token-mixing MLP 对输入 token 的顺序很敏感,因此能够学会表征位置。最后,Mixer 将标准分类头与全局平均池化层配合使用,随后使用线性分类器。

实验及结果
该研究用实验对 MLP-Mixer 模型的性能进行了评估。其中,模型在中大规模数据集上进行预训练,采用一系列中小型下游分类任务,并对以下三个问题进行重点研究:
在下游任务上的准确率;
预训练的总计算成本,这对于在上游数据集上从头开始训练模型非常重要;
推断时的吞吐量,这在实际应用中非常重要。
该研究的实验目的不是展示 SOTA 结果,而在于表明:一个简单的基于 MLP 的模型就可以取得与当前最佳的 CNN、基于注意力的模型相媲美的性能。
下表 1 列出了 Mixer 模型的各种配置以对标一些最新的 SOTA CNN 和基于注意力的模型:

下表 2 给出了最大 Mixer 模型与 SOTA 模型的性能对比结果:

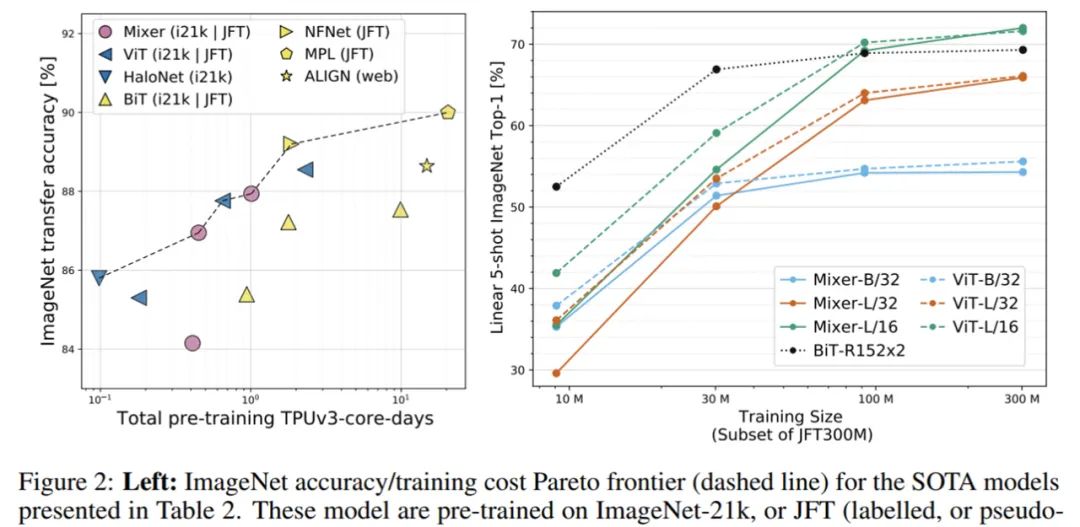
当在 ImageNet-21k 上进行带有额外正则化的预训练时,Mixer 实现了非常好的性能(ImageNet 上 84.15% top-1),略低于其他模型。当上游数据集的大小增加时,Mixer 的性能显著提高。具体来说,Mixer-H/14 在 ImageNet 上取得了 87.94% top-1 的准确率,比 BiT-ResNet152x4 高 0.5%,比 ViT-H/14 低 0.5%。值得一提的是,Mixer-H/14 的运行速度要比 ViT-H/14 快 2.5 倍,比 BiT 快 2 倍。
图 2(左)展示了表 2 中 SOTA 模型在 ImageNet 数据集上的准确率、训练成本帕累托前沿(Pareto frontier):
下表展示了在多种模型和预训练是数据集规模上,Mixer 和其他一些模型的性能对比结果。

由上表可得,当在 ImageNet 上从头开始训练时, Mixer-B/16 取得了一个合理的 top-1 准确率 76.44%,这要比 ViT-B/16 低 3%。随着预训练数据集的增大,Mixer 的性能逐步提升。值得一提的是,在 JFT-300M 数据集上预训练、微调到 224 分辨率的 Mixer-H/14 取得了 86.32% 的准确率,比 ViT-H/14 仅低 0.3%,但运行速度是其 2.2 倍。


以上是关于MLP回归,无需卷积自注意力,纯多层感知机视觉架构媲美CNNViT的主要内容,如果未能解决你的问题,请参考以下文章
谷歌最新提出无需卷积注意力 ,纯MLP构成的视觉架构!网友:MLP is All You Need ?...
谷歌最新提出无需卷积注意力 ,纯MLP构成的视觉架构!网友:MLP is All You Need ?...
R语言使用caret包构建多层感知机MLP(Multi-Layer Perceptron )构建回归模型通过method参数指定算法名称通过trainControl函数控制训练过程