7个提升PyTorch性能的技巧
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7个提升PyTorch性能的技巧相关的知识,希望对你有一定的参考价值。
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路

作者:William Falcon,来源:AI公园、Datawhale干货
在过去的10个月里,在PyTorch Lightning工作期间,团队和我已经接触过许多结构PyTorch代码的风格,我们已经发现了一些人们无意中引入瓶颈的关键地方。
我们非常小心地确保PyTorch Lightning不会对我们为你自动编写的代码犯任何这些错误,我们甚至会在检测到这些错误时为用户纠正这些错误。然而,由于Lightning只是结构化的PyTorch,而你仍然控制所有的PyTorch,因此在许多情况下,我们不能为用户做太多事情。
此外,如果不使用Lightning,可能会在无意中将这些问题引入代码。
为了帮助你训练得更快,这里有8个技巧,你应该知道它们可能会减慢你的代码。
在DataLoaders中使用workers

第一个错误很容易纠正。PyTorch允许同时在多个进程上加载数据。
在这种情况下,PyTorch可以通过处理8个批次绕过GIL锁,每个批次在一个单独的进程上。你应该使用多少workers?一个好的经验法则是:
num_worker = 4 * num_GPU
https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/7这里对此有一个很好的讨论。
警告:缺点是你的内存使用也会增加
Pin memory

你知道有时候你的GPU内存显示它是满的但你很确定你的模型没有使用那么多?这种开销称为pinned memory。这个内存被保留为一种“working allocation”类型。
当你在一个DataLoader中启用pinned_memory时,它“自动将获取的数据张量放在pinned memory中,并使数据更快地传输到CUDA-enabled的gpu”
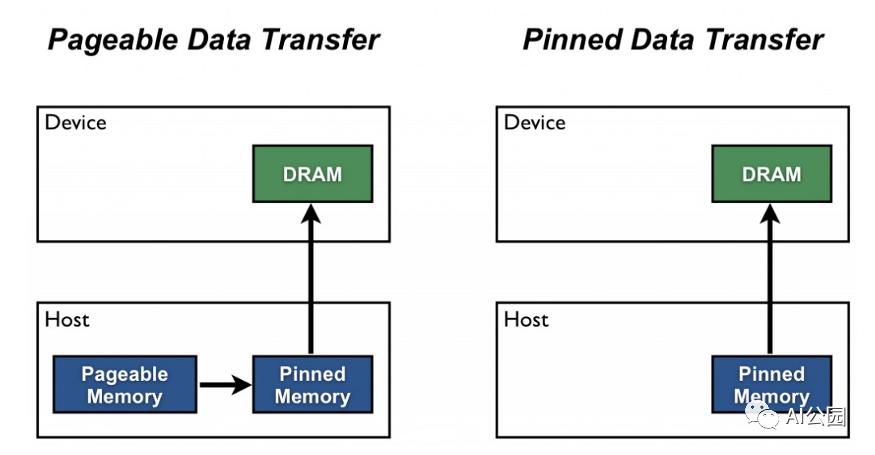
这意味着你不应该不必要的去调用:
torch.cuda.empty_cache()
避免CPU到GPU的传输,反之亦然
# bad.cpu()
.item()
.numpy()
我看到大量使用.item()或.cpu()或.numpy()调用。这对于性能来说是非常糟糕的,因为每个调用都将数据从GPU传输到CPU,从而极大地降低了性能。
如果你试图清除附加的计算图,请使用.detach()。
# good.detach()
这不会将内存转移到GPU,它会删除任何附加到该变量的计算图。
直接在GPUs上构建张量
大多数人都是这样在GPUs上创建张量的
t = tensor.rand(2,2).cuda()
然而,这首先创建CPU张量,然后将其转移到GPU……这真的很慢。相反,直接在想要的设备上创建张量。
t = tensor.rand(2,2, device=torch.device('cuda:0'))
如果你正在使用Lightning,我们会自动把你的模型和批处理放到正确的GPU上。但是,如果你在代码的某个地方创建了一个新的张量(例如:为一个VAE采样随机噪声,或类似的东西),那么你必须自己放置张量。
t = tensor.rand(2,2, device=self.device)
每个LightningModule都有一个方便的self.device调用,无论你是在CPU上,多 GPUs上,还是在TPUs上,lightning会为那个张量选择正确的设备。
使用DistributedDataParallel不要使用DataParallel
PyTorch有两个主要的模式用于在多 GPUs训练。第一种是DataParallel,它将一批数据分割到多个GPUs上。但这也意味着模型必须复制到每个GPU上,一旦在GPU 0上计算出梯度,它们必须同步到其他GPU。
这需要大量昂贵的GPU传输!相反,DistributedDataParallel在每个GPU(在它自己的进程中)上创建模型副本,并且只让数据的一部分对该GPU可用。这就像是让N个独立的模型进行训练,除了一旦每个模型都计算出梯度,它们就会在模型之间同步梯度……这意味着我们在每批处理中只在GPUs之间传输一次数据。
在Lightning中,你可以在两者之间轻松切换
Trainer(distributed_backend='ddp', gpus=8)
Trainer(distributed_backend='dp', gpus=8)
请注意,PyTorch和Lightning都不鼓励使用DP。
使用16-bit精度
这是另一种加快训练速度的方法,我们没有看到很多人使用这种方法。在你的模型进行16bit训练的部分,数据从32位变到到16位。这有几个优点:
你使用了一半的内存(这意味着你可以将batch大小翻倍,并将训练时间减半)。
某些GPU(V100, 2080Ti)可以自动加速(3 -8倍),因为它们针对16位计算进行了优化。
在Lightning中,这很简单:
Trainer(precision=16)
注意:在PyTorch 1.6之前,你还必须安装Nvidia Apex,现在16位是PyTorch的原生版本。但如果你使用的是Lightning,它同时支持这两种功能,并根据检测到的PyTorch版本自动切换。
对你的代码进行Profile
如果没有Lightning,最后一条建议可能很难实现,但你可以使用cprofiler这样的工具来实现。然而,在Lightning中,你可以通过两种方式获得所有在训练期间所做的调用的总结:
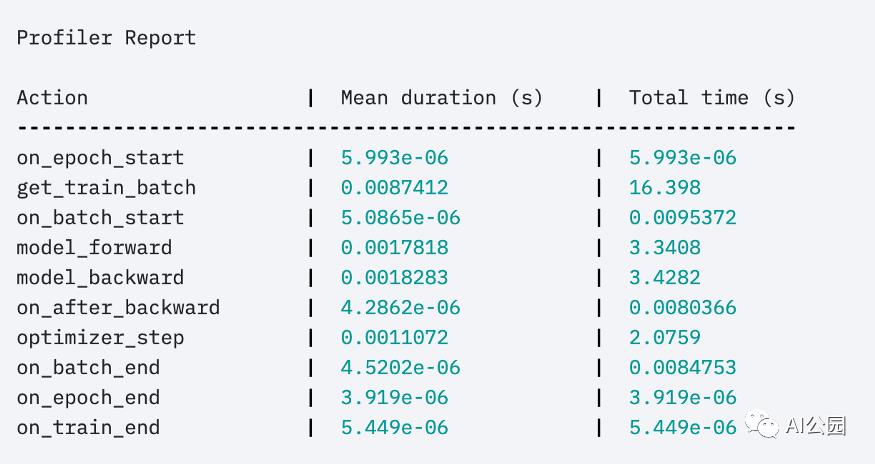
首先,内置的basic profiler
Trainer(profile=True)
可以给出这样的输出:
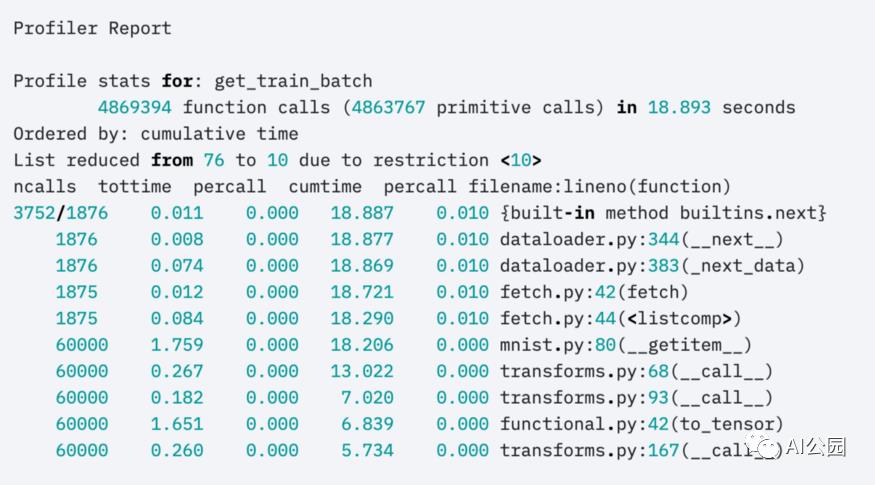
或者是高级的profiler:
profiler = AdvancedProfiler()
trainer = Trainer(profiler=profiler)
得到更小粒度的结果:
英文原文:https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259


以上是关于7个提升PyTorch性能的技巧的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch实现苹果M1芯片GPU加速:训练速度提升7倍,性能最高提升21倍