Hive入门函数入门
Posted 杀智勇双全杀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive入门函数入门相关的知识,希望对你有一定的参考价值。
Hive入门(五)函数入门
内置函数
查看
开启beeline后输入show functions;:
0: jdbc:hive2://node3:10000> show functions;
+-------------------------+--+
| tab_name |
+-------------------------+--+
| ! |
| != |
| $sum0 |
| % |
| & |
| * |
| + |
| - |
| / |
| < |
| <= |
| <=> |
| <> |
| = |
| == |
| > |
| >= |
| ^ |
| abs |
| acos |
| add_months |
| aes_decrypt |
| aes_encrypt |
| and |
| array |
| array_contains |
| ascii |
| asin |
| assert_true |
| atan |
| avg |
| base64 |
| between |
| bin |
| bround |
| case |
| cbrt |
| ceil |
| ceiling |
| chr |
| coalesce |
| collect_list |
| collect_set |
| compute_stats |
| concat |
| concat_ws |
| context_ngrams |
| conv |
| corr |
| cos |
| count |
| covar_pop |
| covar_samp |
| crc32 |
| create_union |
| cume_dist |
| current_database |
| current_date |
| current_timestamp |
| current_user |
| date_add |
| date_format |
| date_sub |
| datediff |
| day |
| dayofmonth |
| decode |
| degrees |
| dense_rank |
| div |
| e |
| elt |
| encode |
| ewah_bitmap |
| ewah_bitmap_and |
| ewah_bitmap_empty |
| ewah_bitmap_or |
| exp |
| explode |
| factorial |
| field |
| find_in_set |
| first_value |
| floor |
| format_number |
| from_unixtime |
| from_utc_timestamp |
| get_json_object |
| get_splits |
| greatest |
| hash |
| hex |
| histogram_numeric |
| hour |
| if |
| in |
| in_file |
| index |
| initcap |
| inline |
+-------------------------+--+
| tab_name |
+-------------------------+--+
| instr |
| isnotnull |
| isnull |
| java_method |
| json_tuple |
| lag |
| last_day |
| last_value |
| lcase |
| lead |
| least |
| length |
| levenshtein |
| like |
| ln |
| locate |
| log |
| log10 |
| log2 |
| lower |
| lpad |
| ltrim |
| map |
| map_keys |
| map_values |
| mask |
| mask_first_n |
| mask_hash |
| mask_last_n |
| mask_show_first_n |
| mask_show_last_n |
| matchpath |
| max |
| md5 |
| min |
| minute |
| month |
| months_between |
| named_struct |
| negative |
| next_day |
| ngrams |
| noop |
| noopstreaming |
| noopwithmap |
| noopwithmapstreaming |
| not |
| ntile |
| nvl |
| or |
| parse_url |
| parse_url_tuple |
| percent_rank |
| percentile |
| percentile_approx |
| pi |
| pmod |
| posexplode |
| positive |
| pow |
| power |
| printf |
| quarter |
| radians |
| rand |
| rank |
| reflect |
| reflect2 |
| regexp |
| regexp_extract |
| regexp_replace |
| repeat |
| replace |
| reverse |
| rlike |
| round |
| row_number |
| rpad |
| rtrim |
| second |
| sentences |
| sha |
| sha1 |
| sha2 |
| shiftleft |
| shiftright |
| shiftrightunsigned |
| sign |
| sin |
| size |
| sort_array |
| soundex |
| space |
| split |
| sqrt |
| stack |
| std |
| stddev |
| stddev_pop |
| stddev_samp |
+-------------------------+--+
| tab_name |
+-------------------------+--+
| str_to_map |
| struct |
| substr |
| substring |
| substring_index |
| sum |
| tan |
| to_date |
| to_unix_timestamp |
| to_utc_timestamp |
| translate |
| trim |
| trunc |
| ucase |
| unbase64 |
| unhex |
| unix_timestamp |
| upper |
| var_pop |
| var_samp |
| variance |
| version |
| weekofyear |
| when |
| windowingtablefunction |
| xpath |
| xpath_boolean |
| xpath_double |
| xpath_float |
| xpath_int |
| xpath_long |
| xpath_number |
| xpath_short |
| xpath_string |
| year |
| | |
| ~ |
+-------------------------+--+
237 rows selected (0.064 seconds)
帮助&功能描述
使用这句可以查看帮助:
desc function [extended] 函数名;
很复杂。。。常用的函数都有很多:
常用函数
聚合函数:
count,sum,avg,max,min。
条件函数:
if,case when。
字符串函数
截取:substring,substr。
拼接:concat,concat_ws。
分割:split。
查找:instr。
替换:regex_replace。
长度:length。
日期函数
转换:unix_timestamp,from_unixtime。
日期:current_date,date_sub,date_add。
获取:year,month,day、hour。
特殊函数
JSON:json_tuple,get_json_object。
URL:parse_url,parse_url_tuple。
窗口函数
聚合窗口:sum,count……
位置窗口:lag,lead,first_value,last_value。
分析函数:row_number,rank,dense_rank。
自定义函数
自定义函数分类
UDF:一对一函数,类似于substr。
UDAF:多对一函数,类似于聚合函数:count。
UDTF:一对多函数,explode将一行中的每个元素变成一行。
自定义UDF
用户定义(普通)函数,只对单行数值产生作用。
自定义一个类,继承UDF类。
在类中至少实现一个evaluate方法定义处理数据的逻辑。
打成jar包,添加到hive的环境变量中,例如:
add jar /export/data/udf.jar;
将类注册为函数:
create temporary function transFDate as 'com.aa.hive.udf.UserUDF';
调用函数:
select transFDate("24/Dec/2019:15:55:01");
自定义UDAF
User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数。
将类注册为函数:
create temporary function userMax as 'com.aa.hive.udaf.UserUDAF';
调用函数:
select userMax(cast(deptno as int)) from db_emp.tb_dept;
cast时强制类型转换函数,可以把某一列转换为某种类型。
自定义UDTF
User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行。
将类注册为函数:
create temporary function transMap as 'com.aa.hive.udtf.UserUDTF';
调用函数:
select transMap("uuid=root&url=www.taobao.com") as (userCol1,userCol2);
parse_url_tuple
这是个UDTF函数,可以一次性解析多个元素。
如果在BD搜“JD”:
https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_1ae98d66d61e4e47a001e86731031dce
https是请求头,www.jd.com是域名HOST,有时候会有/index.jsp这种访问路径PATH(?前),cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_1ae98d66d61e4e47a001e86731031dce是参数依据QUERY。手动写函数解析还是比较费力的,好在Hive有这么个方法,省的用户手写了。。。
编辑数据源:
vim /export/data/lateral.txt
插入网址。。。
建表:
create table tb_url(
id int,
url string
) row format delimited fields terminated by '\\t';
加载数据:
load data local inpath '/export/data/lateral.txt' into table tb_url;
查询:
select parse_url_tuple(url,'HOST','PATH','QUERY') from tb_url;
这年头好多网站喜欢用https加密,有时候并不好使。
lateral view
UDTF函数的问题
UDTF函数有诸多问题:
udtf只能直接select中使用,
不可以添加其他字段使用,
不可以嵌套调用,
不可以和group by/cluster by/distribute by/sort by一起使用。
lateral view可以把UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表,用以解决UDTF的问题。
select …… from 表名 lateral view UDTF(xxx) 别名 as col1,col2,col3……
lateral view一般是搭配UDTF函数使用,将UDTF函数的结果变成类似于视图的表,方便与原表进行操作。
UDTF函数的用法
单独在select后面使用,select中不能包含别的字段。
搭配lateral view使用。
explode
将集合类型(一般是Map和Array)中的每个元素转换成一行。
语法格式:
explode( Map集合或Array集合)
例如:
select explode(work_locations) as loc from complex_array;
select explode(hobby) from complex_map;
或者:
select
a.id,
a.name,
b.*
from complex_map a lateral view explode(hobby) b as hobby,deep;
多行转多列
node3命令行:
vim /export/data/r2c1.txt
插入内容:
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
f c 7
DataGrip连接Hive后,建表:
create table row2col1(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\\t';
在浏览器打开node1:50070:
发现建表成功,单现在还只是个空文件夹。
加载数据:
load data local inpath '/export/data/r2c1.txt' into table row2col1;
刷新浏览器:
发现数据加载成功。
DataGrip中:
select col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from row2col1
group by col1;
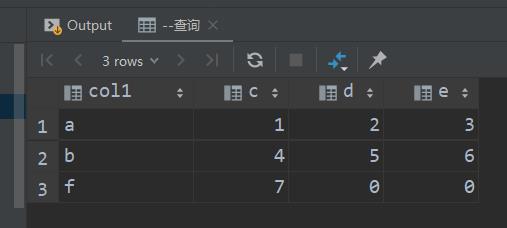
查询后:
或者直接在启动了beeline的命令行:
0: jdbc:hive2://node3:10000> select col1 as col1,
. . . . . . . . . . . . . .> max(case col2 when 'c' then col3 else 0 end) as c,
. . . . . . . . . . . . . .> max(case col2 when 'd' then col3 else 0 end) as d,
. . . . . . . . . . . . . .> max(case col2 when 'e' then col3 else 0 end) as e
. . . . . . . . . . . . . .> from row2col1
. . . . . . . . . . . . . .> group by col1;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+----+----+----+--+
| col1 | c | d | e |
+-------+----+----+----+--+
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
| f | 7 | 0 | 0 |
+-------+----+----+----+--+
3 rows selected (16.825 seconds)
结果是一致的。这段SQL意思是从col1中查询,按照字段col1分组,原表字段2中为c的那行中字段3的值填入新表字段2,原表字段2中为d的那行中字段3的值填入新表字段3,原表字段2中为e的那行中字段3的值填入新表字段4,其余情况置0。
数据分析、数据清洗等操作经常需要行列转换。∵一般是多种数值,也就是多分支(多条件判断场景),故最常用的是case~when而不是if。语法为:
case 字段名1 when 字段值1 then 字段名2 else 字段值2 end
或者:
case when 字段1 = 字段值1 then 字段值2 else 字段值3 end
多行转单列
vim /export/data/r2c2.txt
插入:
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
建表:
create table row2col2
(
col1 string,
col2 string,
col3 int
) row format delimited fields terminated by '\\t';
加载数据:
load data local inpath '/export/data/r2c2.txt' into table row2col2;
查询数据:
select col1, col2, concat_ws(",", collect_set(cast(col3 as string))) as col3
from row2col2
group by col1, col2;
为了排版好看,用beeline的结果:
+-------+-------+--------+--+
| col1 | col2 | col3 |
+-------+-------+--------+--+
| a | b | 1,2,3 |
| c | d | 4,5,6 |
+-------+-------+--------+--+
2 rows selected (10.643 seconds)
类型转换函数
cast(字段名 as 数据类型):用于转换字段的数据类型。
聚合函数
用于将多行的内容合并为一行内容。
collect_list
collect_list(字段名):不做去重。
collect_set
collect_set(字段名):做去重。
字符串拼接函数
用于字符串拼接。
concat
concat(字段1,字段2,字段3...):不能自定义分隔符(字段中没用空格之类的分隔符数据就会粘一起),只要有1个null整个结果就全部为null。
concat_ws
concat_ws("分隔符",字段1,字段2,字段3...):可以自定义分隔符,只要其中有1个不是null结果就不是null。
多列转多行
vim /export/data/c2r1.txt
插入:
a 1 2 3
b 4 5 6
建表:
create table col2row1(
col1 string,
col2 int,
col3 int,
col4 int
)row format delimited fields terminated by '\\t';
加载数据:
load data local inpath '/export/data/c2r1.txt' into table col2row1;
查询:
select col1,'c' as col2,col2 as col3 from col2row1
union all
select col1,'d' as col2,col3 as col3 from col2row1
union all
select col1,'e' as col2,col4 as col3 from col2row1;
结果:
+----------+----------+----------+--+
| u1.col1 | u1.col2 | u1.col3 |
+----------+----------+----------+--+
| a | c | 1 |
| a | d | 2 |
| a | e | 3 |
| b | c | 4 |
| b | d | 5 |
| b | e | 6 |
+----------+----------+----------+--+
6 rows selected (14.224 seconds)
行合并函数
union
对两个结果集进行并集操作,不包括重复行,相当于distinct,同时进行默认规则的排序。
select…… union select ……
union all
对两个结果集进行并集操作,包括重复行,即所有的结果全部显示,不管是不是重复。
select…… union all select ……
多列转单行
vim /export/data/c2r2.txt
插入:
a b 1,2,3
c d 4,5,6
建表:
create table col2row2
(
col1 string,
col2 string,
col3 string
) row format delimited fields以上是关于Hive入门函数入门的主要内容,如果未能解决你的问题,请参考以下文章