2021年大数据Flink(三十九):Table与SQL 总结 Flink-SQL常用算子
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Flink(三十九):Table与SQL 总结 Flink-SQL常用算子相关的知识,希望对你有一定的参考价值。
目录
总结 Flink-SQL常用算子
SELECT
SELECT 用于从 DataSet/DataStream 中选择数据,用于筛选出某些列。
示例:
SELECT * FROM Table;// 取出表中的所有列
SELECT name,age FROM Table;// 取出表中 name 和 age 两列
与此同时 SELECT 语句中可以使用函数和别名,例如我们上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word;
WHERE
WHERE 用于从数据集/流中过滤数据,与 SELECT 一起使用,用于根据某些条件对关系做水平分割,即选择符合条件的记录。
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE 是从原数据中进行过滤,那么在 WHERE 条件中,Flink SQL 同样支持 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合,最终满足过滤条件的数据会被选择出来。并且 WHERE 可以结合 IN、NOT IN 联合使用。举个例子:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
DISTINCT
DISTINCT 用于从数据集/流中去重根据 SELECT 的结果进行去重。
示例:
SELECT DISTINCT name FROM Table;
对于流式查询,计算查询结果所需的 State 可能会无限增长,用户需要自己控制查询的状态范围,以防止状态过大。
GROUP BY
GROUP BY 是对数据进行分组操作。例如我们需要计算成绩明细表中,每个学生的总分。
示例:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
UNION 和 UNION ALL
UNION 用于将两个结果集合并起来,要求两个结果集字段完全一致,包括字段类型、字段顺序。
不同于 UNION ALL 的是,UNION 会对结果数据去重。
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
JOIN
JOIN 用于把来自两个表的数据联合起来形成结果表,Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
这里的 JOIN 的语义和我们在关系型数据库中使用的 JOIN 语义一致。
示例:
JOIN(将订单表数据和商品表进行关联)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
LEFT JOIN 与 JOIN 的区别是当右表没有与左边相 JOIN 的数据时候,右边对应的字段补 NULL 输出,RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN 相当于 RIGHT JOIN 和 LEFT JOIN 之后进行 UNION ALL 操作。
示例:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
Group Window
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种 Bounded Window:
Tumble,滚动窗口,窗口数据有固定的大小,窗口数据无叠加;
Hop,滑动窗口,窗口数据有固定大小,并且有固定的窗口重建频率,窗口数据有叠加;
Session,会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加。
Tumble Window
Tumble 滚动窗口有固定大小,窗口数据不重叠,具体语义如下:
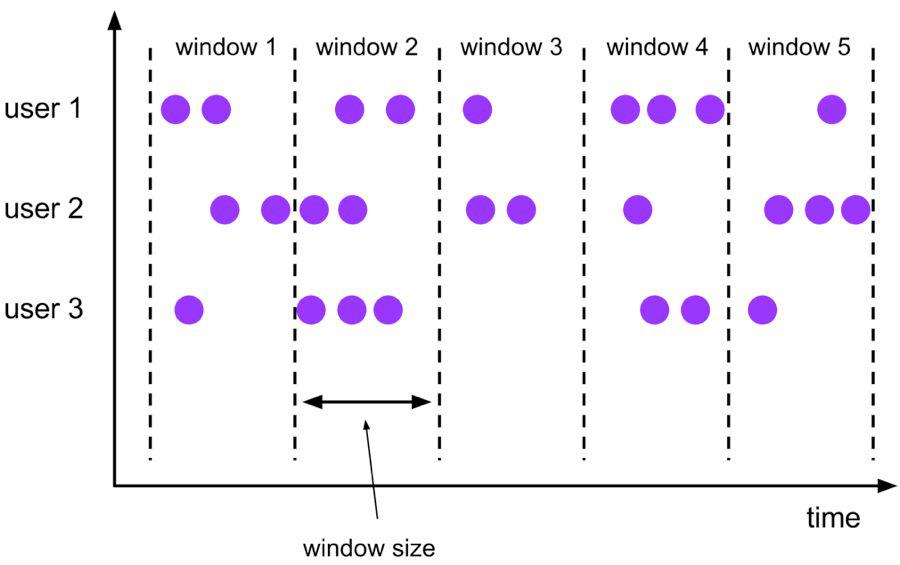
Tumble 滚动窗口对应的语法如下:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
其中:
[gk] 决定了是否需要按照字段进行聚合;
TUMBLE_START 代表窗口开始时间;
TUMBLE_END 代表窗口结束时间;
timeCol 是流表中表示时间字段;
size 表示窗口的大小,如 秒、分钟、小时、天。
举个例子,假如我们要计算每个人每天的订单量,按照 user 进行聚合分组:
SELECT user, TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart, SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
Hop Window
Hop 滑动窗口和滚动窗口类似,窗口有固定的 size,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的新建频率。因此当 slide 值小于窗口 size 的值的时候多个滑动窗口会重叠,具体语义如下:
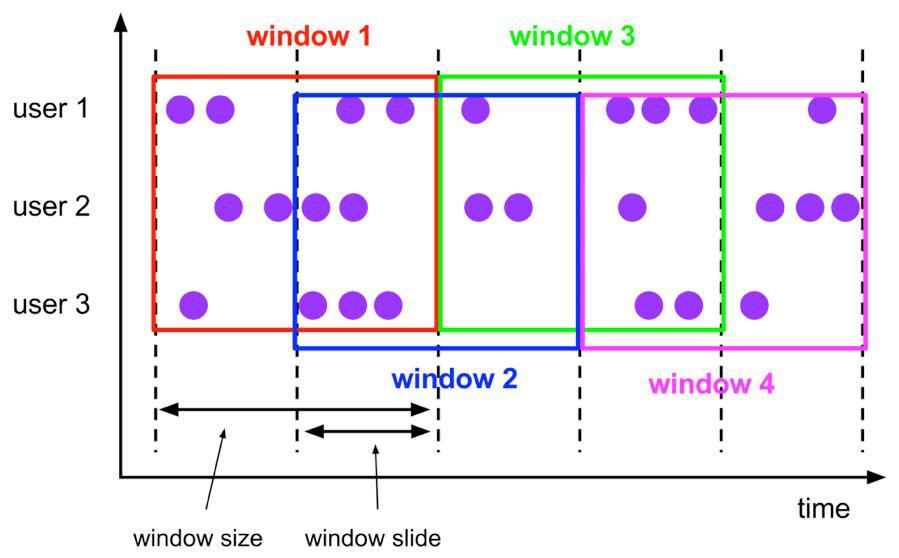
Hop 滑动窗口对应语法如下:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
每次字段的意思和 Tumble 窗口类似:
[gk] 决定了是否需要按照字段进行聚合;
HOP_START 表示窗口开始时间;
HOP_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
slide 表示每次窗口滑动的大小;
size 表示整个窗口的大小,如 秒、分钟、小时、天。
举例说明,我们要每过一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount)
FROM Orders
GROUP BY product,HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY)
Session Window
会话时间窗口没有固定的持续时间,但它们的界限由 interval 不活动时间定义,即如果在定义的间隙期间没有出现事件,则会话窗口关闭。
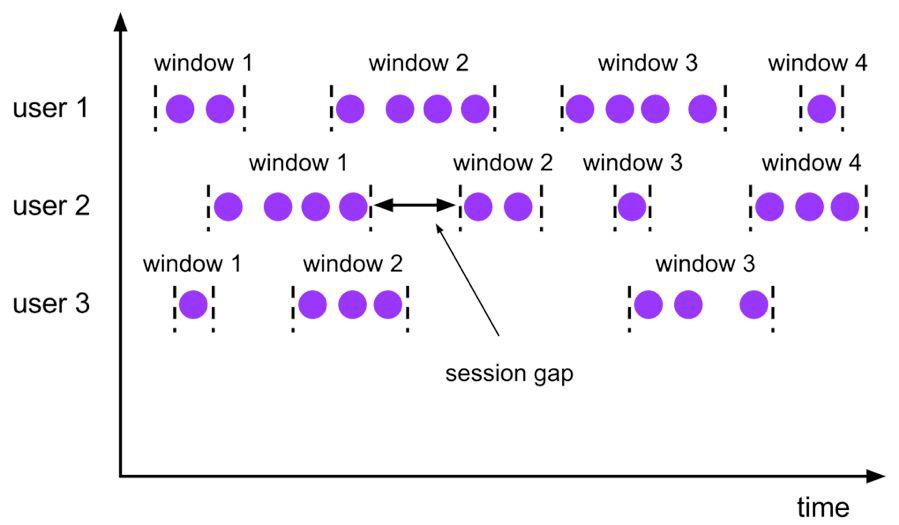
Seeeion 会话窗口对应语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
[gk] 决定了是否需要按照字段进行聚合;
SESSION_START 表示窗口开始时间;
SESSION_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
gap 表示窗口数据非活跃周期的时长。
例如,我们需要计算每个用户访问时间 12 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd, SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
以上是关于2021年大数据Flink(三十九):Table与SQL 总结 Flink-SQL常用算子的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Flink(三十四):Table与SQL 案例一
2021年大数据Flink(三十):Flink Table API & SQL 介绍
2021年大数据Flink(三十二):Table与SQL案例准备 API
2021年大数据Flink(三十一):Table与SQL案例准备 依赖和程序结构