2021年大数据常用语言Scala(二十三):函数式编程 扁平化映射 flatMap
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据常用语言Scala(二十三):函数式编程 扁平化映射 flatMap相关的知识,希望对你有一定的参考价值。
目录
扁平化映射 flatMap
扁平化映射也是将来用得非常多的操作,也是必须要掌握的。
定义
可以把flatMap,理解为先map,然后再flatten
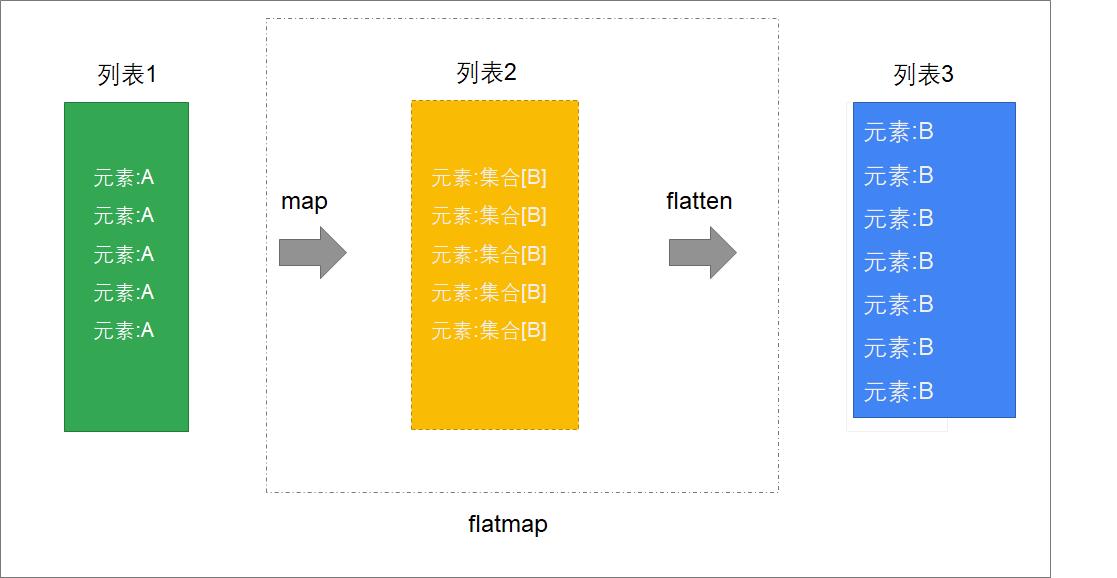
就是说, 我们对待处理列表, 正常我们处理它 需要 先对其进行map操作, 然后再进行flatten操作 这样两步操作才可以得到我们想要的结果.
如果我们有这样的需求, 我们就可以使用flatMap( 此方法帮我们实现 先map 后flatten的操作)
- map是将列表中的元素转换为一个List
- 这是什么意思呢? 这里是指待处理列表中的每一个元素, 都有转换成一个list的需求, 如果我们没有这样的需求, 那么其实就用不到flatMap 直接用flatten方法就行.
- 可能大家还是有点晕, 我们向下看, 到下面具体的例子就会明白.
- flatten再将整个列表进行扁平化
方法签名
def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B]
方法解析
| flatmap方法 | API | 说明 |
| 泛型 | [B] | 最终要转换的集合元素类型 |
| 参数 | f: (A) ⇒ GenTraversableOnce[B] | 传入一个函数对象<br />函数的参数是集合的元素<br />函数的返回值是一个集合 |
| 返回值 | TraversableOnce[B] | B类型的集合 |
案例
案例说明
有一个包含了若干个文本行的列表:"hadoop hive spark flink flume", "kudu hbase sqoop storm"
获取到文本行中的每一个单词,并将每一个单词都放到列表中
思路分析
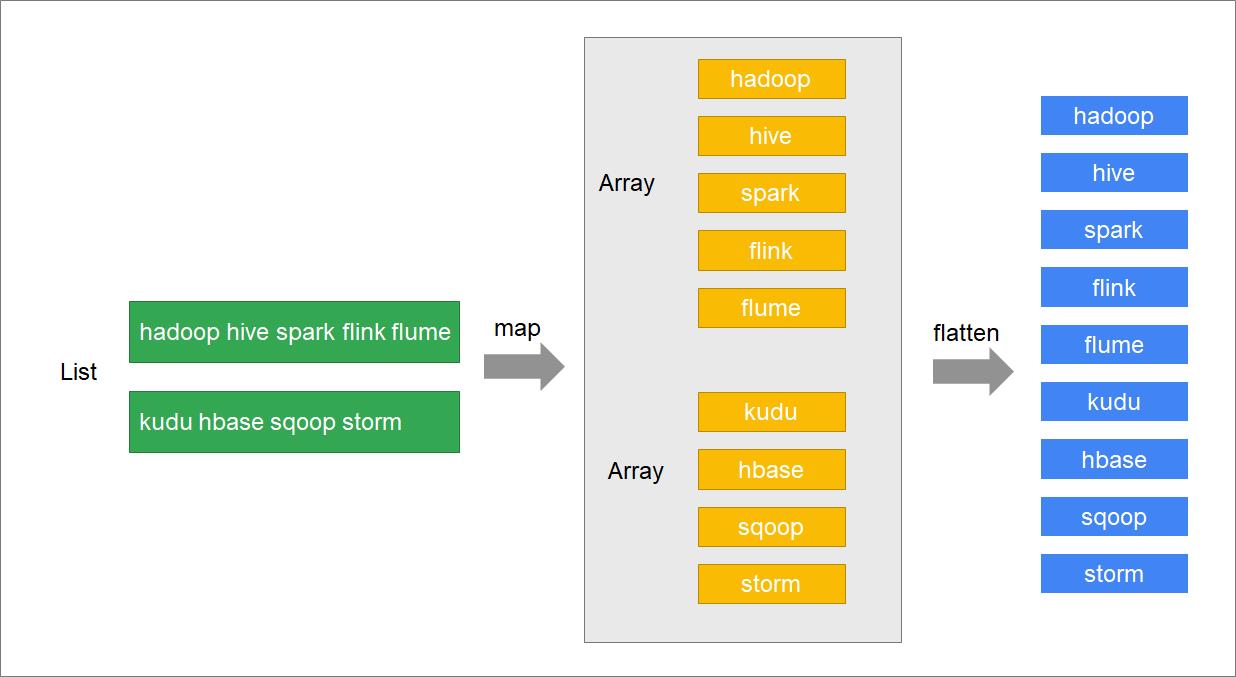
步骤
使用map将文本行拆分成数组
再对数组进行扁平化
参考代码
// 定义文本行列表
scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")
a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm)
// 使用map将文本行转换为单词数组
scala> a.map(x=>x.split(" "))
res5: List[Array[String]] = List(Array(hadoop, hive, spark, flink, flume), Array(kudu, hbase, sqoop, storm))
// 扁平化,将数组中的
scala> a.map(x=>x.split(" ")).flatten
res6: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)
使用flatMap简化操作
参考代码
scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")
a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm)
scala> a.flatMap(_.split(" "))
res7: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)
以上是关于2021年大数据常用语言Scala(二十三):函数式编程 扁平化映射 flatMap的主要内容,如果未能解决你的问题,请参考以下文章