01 关于 sds
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01 关于 sds相关的知识,希望对你有一定的参考价值。
前言
关于 redis 的数据结构 sds
相关介绍主要围绕着如下测试用例, 来看看 sds 的存储, 以及 相关的 api
本文的 sds 相关代码 拷贝自 Redis 2.9.11 (1ce33fe5/1) 64 bit
我这的代码基于 redis-3.0-annotated-cmake-in-clion, 来自于 https://github.com/htw0056/redis-3.0-annotated-cmake-in-clion
后续的代码会基于 redis-6.2.0
测试用例
测试用例如下, 呵呵 我们一个一个的来
//
// Created by Jerry.X.He on 2021-02-13.
//
#include <iostream>
#include "libs/sds.h"
using namespace std;
// Test24SdsUsage
int main(int argc, char** argv) {
sds result = sdsnew(" hh xyz ee ");
cout << result << endl;
cout << sdstrim(result, "h e") << endl;
cout << sdslen(result) << endl;
cout << sdsavail(result) << endl;
// inspect copied
sds copied = sdsdup(result);
// inspect grow zero
sds growZero = sdsgrowzero(result, 30);
// inspect concated
sds concated = sdscat(sdsempty(), "__tail");
// inspect concatedSds
sds concatedSds = sdscatsds(sdsempty(), sdsnew("__tail"));
// inspect copiedSds
sds copiedSds = sdscpy(sdsempty(), "__copied");
sds rangeSds = sdsnew(" jerry.x.he ");
sdsrange(rangeSds, 3, 5);
// inspect rangeSds
sds clearSds = sdsnew(" jerry.x.he ");
sdsclear(clearSds);
// inspect clearSds
int compResult = sdscmp(rangeSds, clearSds);
// inspect compResult
sds splitSds = sdsnew(" jerry.x.he ");
int splitLen = 0;
sdssplitlen(splitSds, sdslen(splitSds), ".", 1, &splitLen);
// inspect sdssplitlen
sds caseSds = sdsnew(" jerry.x.he ");
sdstoupper(caseSds);
// inspect sdstoupper
sdstolower(caseSds);
// inspect sdstolower
sds llSds = sdsfromlonglong(111111111);
// inspect llSds
sds reprSds = sdsnew(" init ");
sdscatrepr(reprSds, " \\r\\n你⑦ ", 10);
// inspect reprSds
char cmdLine[] = {"*3\\r\\n$3\\r\\nset\\r\\n$4\\r\\nname\\r\\n$2\\r\\nhx\\r\\n"};
int newArgc = 0;
sds* newArgv = sdssplitargs(cmdLine, &newArgc);
sds beforeMapSds = sdsnew(" jerry.x.he ");
sds afterMapSds = sdsmapchars(beforeMapSds, ".", ">", 1);
char** newArgv2 = new char*[2];
newArgv2[0] = {"jerry1"};
newArgv2[1] = {"jerry2"};
char sep[] = {"->"};
sds joinedSds = sdsjoin(newArgv2, 2, sep);
return 0;
}
数据结构
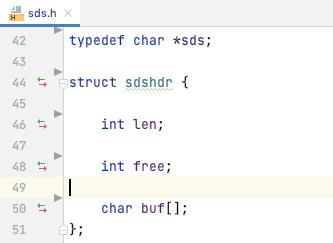
可以看到 sds 其实是等价于 char*
sdshdr 中存储了当前 sds 的长度, 以及可用空间, 以及实际的业务数据
sdsnew
为当前 sds 分配了 sdshdr[len + free 8字节] + initlen[" hh xyz ee " 11字节] + 1[字符串结束符'\\0' 1字节] 的空间
然后设置了 sds 的元数据信息[sdshdr], 设置了 len 和 free
之后拷贝了 init 里面的数据的内容到 sdshdr->buf[位于 free 之后]
最后补充 sds 对应的字符串的结束符
返回的是 兼容 c 的字符串的地址, 取元数据通过偏移获取 sdshdr
我们来 inspect 一下 sh[sdshdr] 的信息, sh 的起始地址为 0x7fdc265001f0
前四个字节为 len, 0x0b = 11
之后四个字节为 free, 0x00 = 0
之后的 11 个字节为字符串的内容, " hh xyz ee "
之后的 1 个字节为字符串结束符 '\\0'
这个就是 sds 的存储方式
(lldb) x 0x7fdc265001f0
0x7fdc265001f0: 0b 00 00 00 00 00 00 00 20 68 68 20 78 79 7a 20 ........ hh xyz
0x7fdc26500200: 65 65 20 00 ff 7f 00 00 96 21 76 67 ff 7f 00 00 ee ......!vg....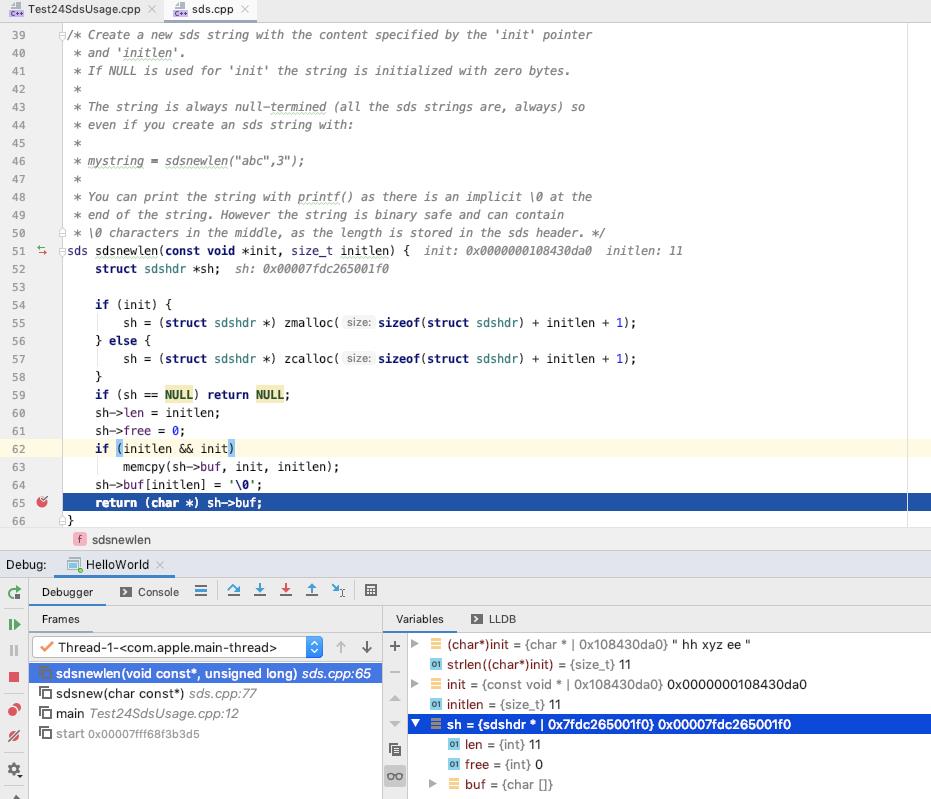
sdsnew 返回给业务这边的是 sdshdr->buf 的地址, 也就是兼容 c 的这个 char*, sds 的类型定义也是 char*
typedef char *sds;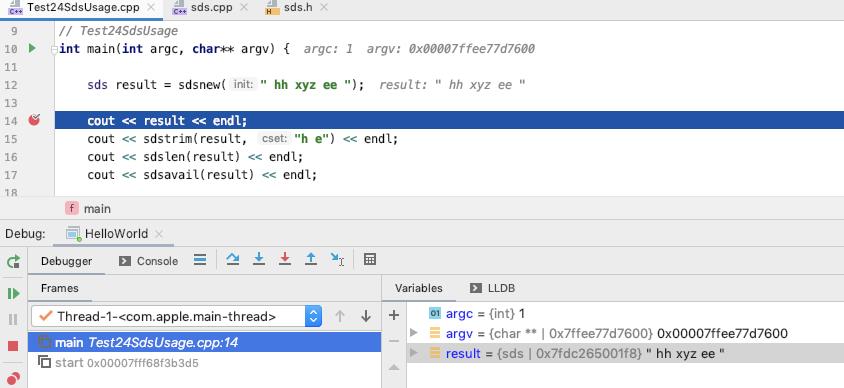
sdstrim
从 sds 头遍历找到第一个不在 cset 的位置, 从 sds 尾遍历找到第一个不在 cset 的位置
然后 保留中间的部分, 重新计算 sdshdr 的 len, free
移动需要保留的数据到 sds, 设置好字符串的结束符, 返回 sds
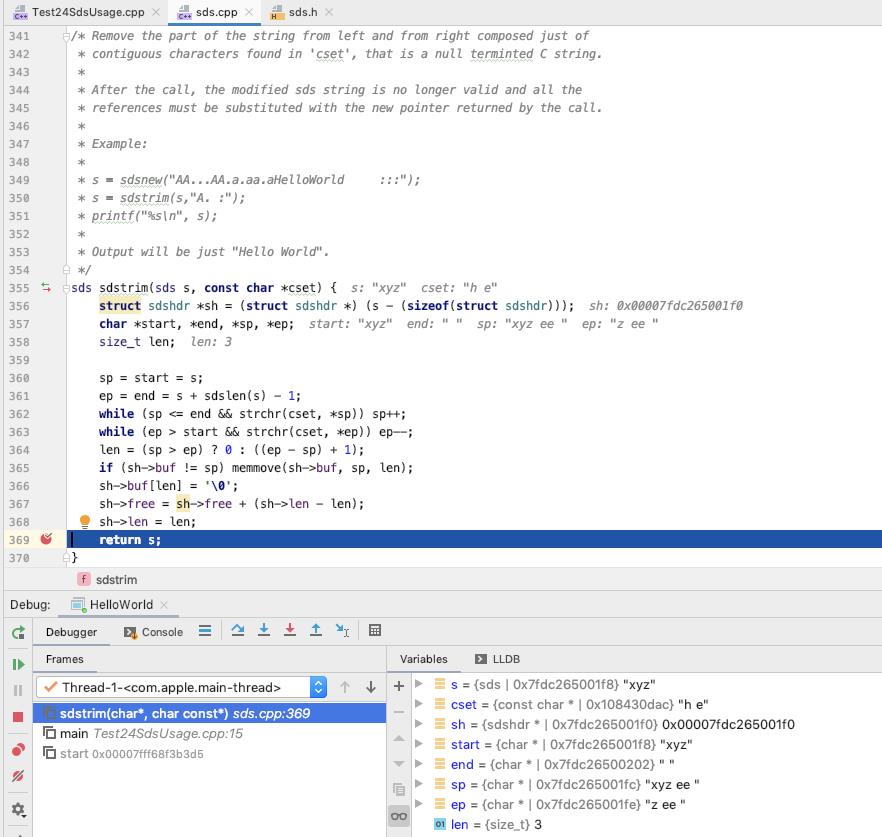
此时的 result 的 sdshdr 如下
前四个字节为 len, 0x03 = 3
之后四个字节为 free, 0x08 = 8
之后的 3 个字节为字符串的内容, "xyz"
之后的 1 个字节为字符串结束符 '\\0'
之后的 8 个字节为 free 的空间
(lldb) x 0x7fdc265001f0
0x7fdc265001f0: 03 00 00 00 08 00 00 00 78 79 7a 00 78 79 7a 20 ........xyz.xyz
0x7fdc26500200: 65 65 20 00 ff 7f 00 00 96 21 76 67 ff 7f 00 00 ee ......!vg....
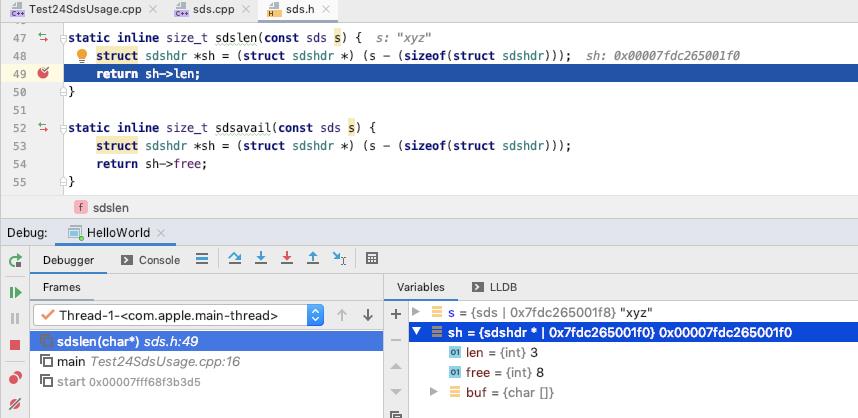
sdslen/sdsavail
这两个相对比较简单, 一起看, 基于 sds 定位到 sdshdr, 直接取元数据
sdsdump
基于当前 sds 的逻辑部分复制一个 sds, 同样是基于上面的 sdsnew 的操作

copied内容如下 : len 为 3, free 为 0, 之后为 被复制的sds的数据
(lldb) x 0x7fdc26500290
0x7fdc26500290: 03 00 00 00 00 00 00 00 78 79 7a 00 fd 07 00 70 ........xyz....p
0x7fdc265002a0: 00 00 00 00 00 00 00 b0 00 00 00 00 00 00 00 b0 ................
sdsgrowzero
操作也相对比较简单, 如果当前 sds 长度大于 len, 直接返回
否则 扩展当前 sds 的长度为 len[这里 sdsMakeRoomFor 有一个预分配策略, 如果空间小于 SDS_MAX_PREALLOC[默认1M], 则分配空间翻倍, 否则增加分配 SDS_MAX_PREALLOC 的空间]
设置 增加的这部分数据为 0
更新 sdshdr 的元数据信息, 返回 sds

所以我们这里 期望的结果 growZero 最终应该是 len 为 30, free 为 30, sdshdr->buf 为 "xyz", 后面27个字节为 '\\0'
如下 0x1e 为 30
(lldb) x 0x7fdc26700e90 -c 0x50
0x7fdc26700e90: 1e 00 00 00 1e 00 00 00 78 79 7a 00 00 00 00 00 ........xyz.....
0x7fdc26700ea0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x7fdc26700eb0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x7fdc26700ec0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x7fdc26700ed0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
sdscat/sdscatsds
二者均是 sdscatlen 实现
确保 sds 可以存储 t, 空间不够则扩容
然后将 t 的数据复制到 sds 中
更新 sdshdr 的元数据信息, 返回 sds
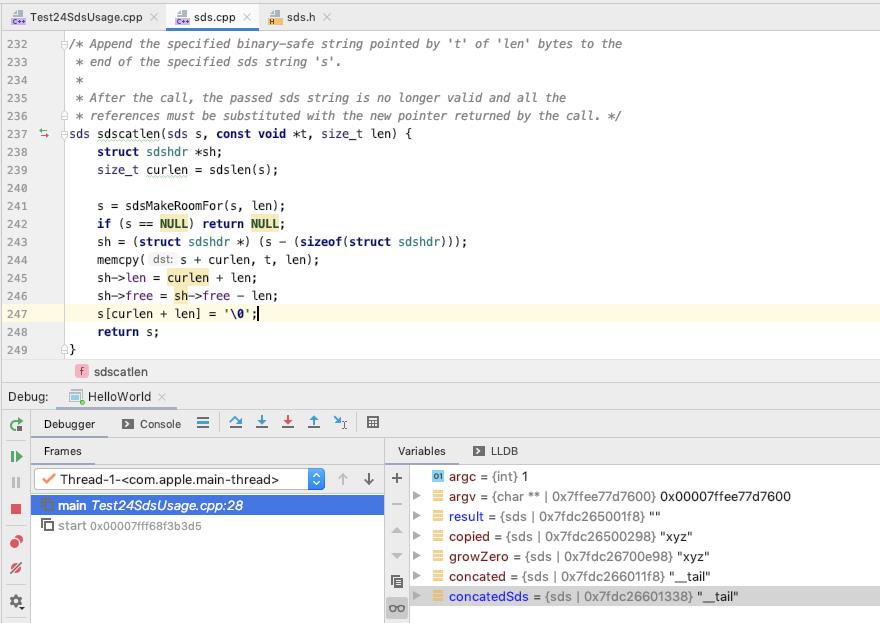
concated / concatedSds 内容如下 : len 为 6, free 为 6, sdshdr->buf 为 sdsempty() + "__tail"
(lldb) x 0x7fdc266011f0
0x7fdc266011f0: 06 00 00 00 06 00 00 00 5f 5f 74 61 69 6c 00 80 ........__tail..
0x7fdc26601200: a0 28 40 26 dc 7f 00 00 00 00 00 00 00 00 00 00 .(@&............
(lldb) x 0x7fdc26601330
0x7fdc26601330: 06 00 00 00 06 00 00 00 5f 5f 74 61 69 6c 00 b0 ........__tail..
0x7fdc26601340: 02 00 40 26 dc 7f 00 00 00 00 00 00 00 00 02 00 ..@&............
sdscpy
直接将目标的数据, 覆盖 s 的已有的数据
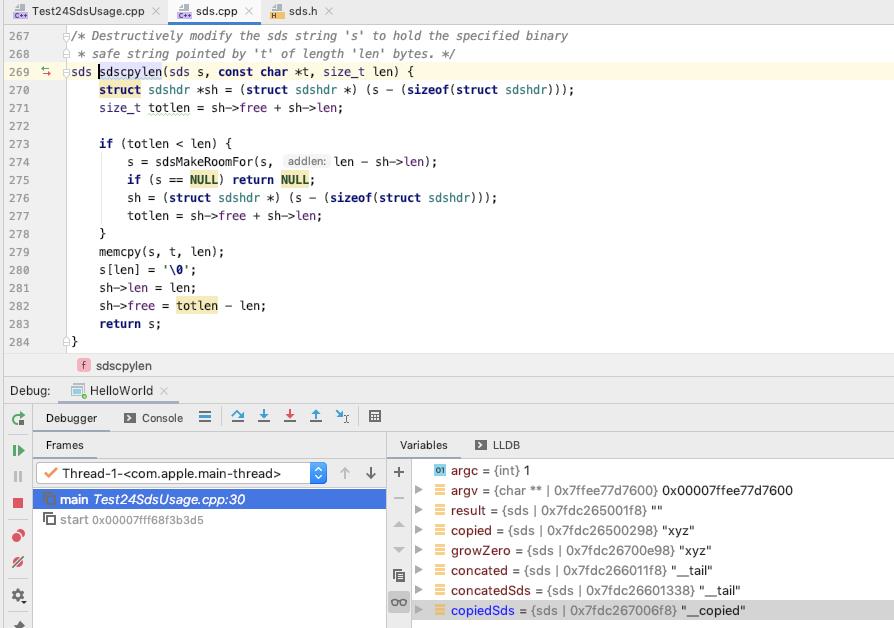
copiedSds 内容如下 : len 为 8, free 为 8, sdshdr->buf 为 "__copied"
(lldb) x 0x7fdc267006f0
0x7fdc267006f0: 08 00 00 00 08 00 00 00 5f 5f 63 6f 70 69 65 64 ........__copied
0x7fdc26700700: 00 00 00 00 00 00 00 b0 00 00 00 00 00 00 00 b0 ................
sdsrange
将目标 sds 指定的 [start, end] 区间的数据保留下来
更新 sdshdr 的元数据信息
start, end 为负约定为从末尾开始计算索引
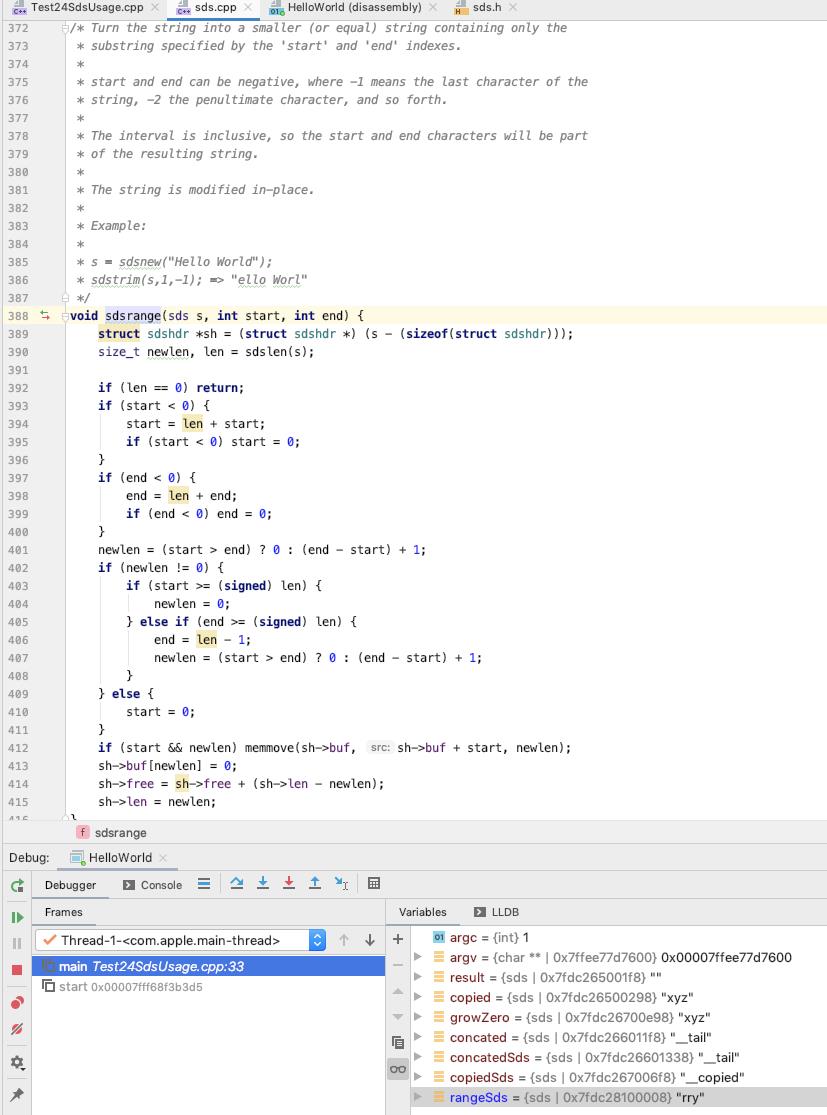
rangeSds 内容如下 : len 为 3, free 为 9, sdshdr->buf 为 "rry"
后面 free 的空间还可以看到 rangeSds 初始化的时候的数据
(lldb) x 0x7fdc28100000
0x7fdc28100000: 03 00 00 00 09 00 00 00 72 72 79 00 72 79 2e 78 ........rry.ry.x
0x7fdc28100010: 2e 68 65 20 00 00 00 00 00 00 00 00 00 00 00 00 .he ............
sdsclear
设置 第0个元素为 '\\0', 字符串结束符
更新 sdshdr 的元数据信息
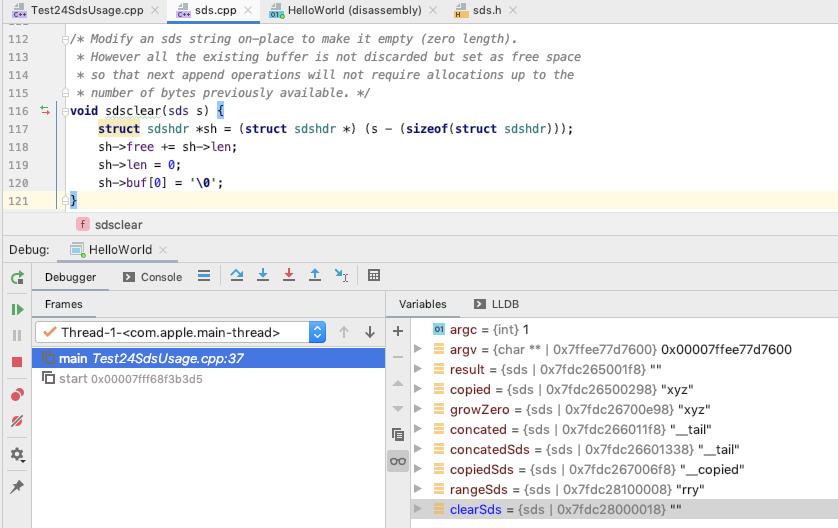
clearSds 内容如下 : len 为 0, free 为 12, sdshdr->buf 为 ""
后面 free 的空间还可以看到 clearSds 初始化的时候的数据
(lldb) x 0x7fdc28000010
0x7fdc28000010: 00 00 00 00 0c 00 00 00 00 6a 65 72 72 79 2e 78 .........jerry.x
0x7fdc28000020: 2e 68 65 20 00 00 00 00 00 00 00 00 00 00 00 00 .he ............
sdscmp
基于 memcmp 比较 s1, s2 的共同长度部分的内容, 如果能够比较出结果 返回比较结果
否则 返回二者长度 之差
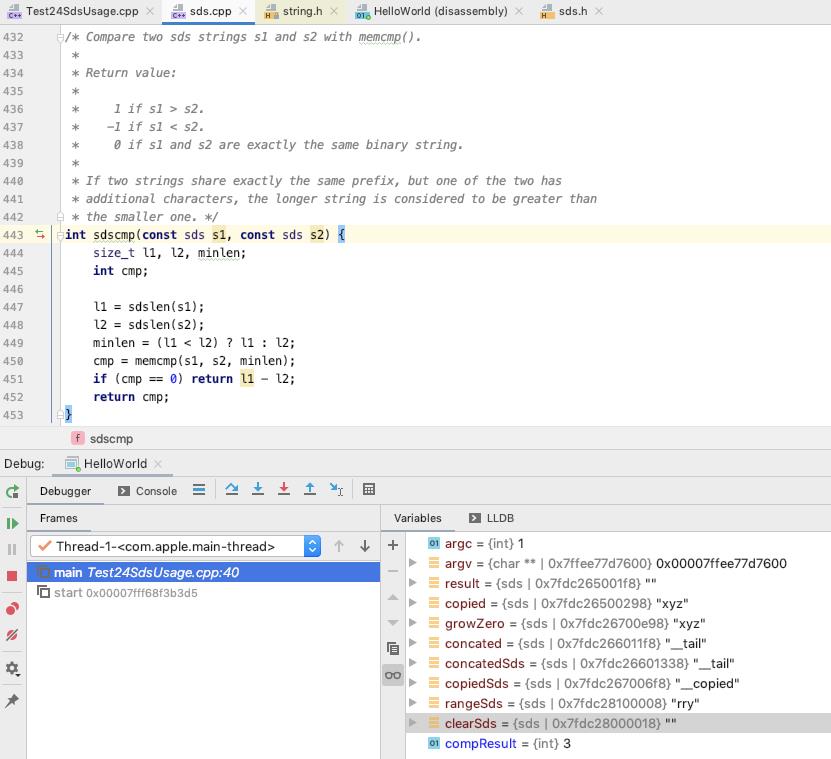
所以 这里 compResult 的结果为 3 = (3 - 0)
sdssplitlen
从 s 中查询给定的 seprator
将 seprator 分割的各个块封装成 sds, 填充到结果数组里面[tokens]
下面的 slots < elements+2 为结果数组的扩容操作
最终更新 *count, 返回 tokens
sdstoupper
遍历每一个字符, toupper
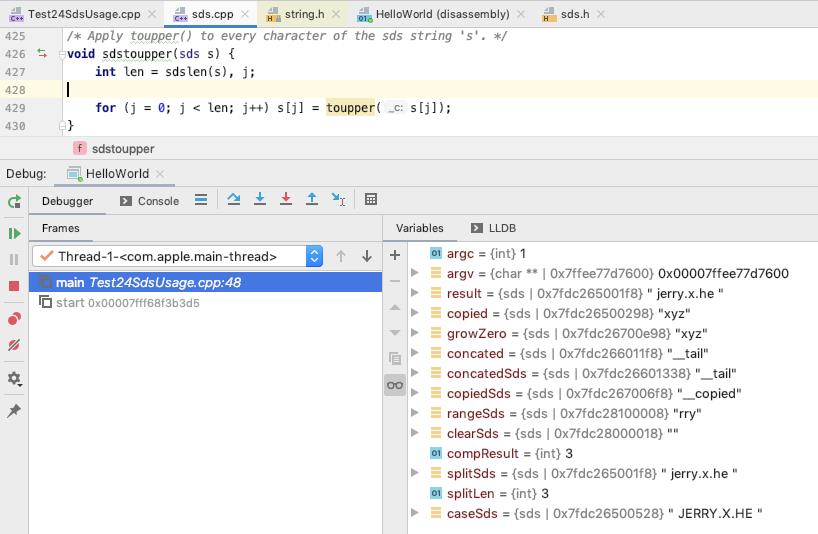
caseSds 内容如下 : len 为 12, free 为 0, sdshdr->buf 为 " JERRY.X.HE "
(lldb) x 0x7fdc26500520
0x7fdc26500520: 0c 00 00 00 00 00 00 00 20 4a 45 52 52 59 2e 58 ........ JERRY.X
0x7fdc26500530: 2e 48 45 20 00 00 00 00 00 00 00 00 00 00 00 00 .HE ............
sdstolower
遍历每一个字符, tolower
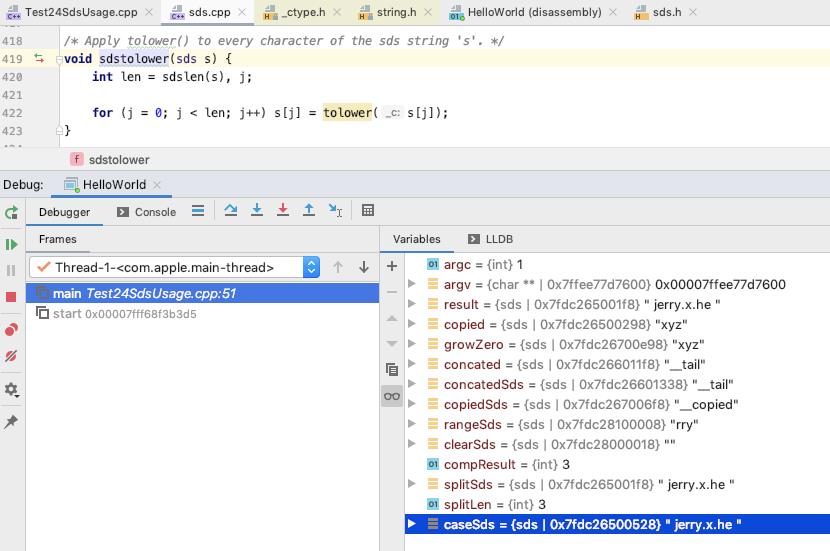
caseSds 内容如下 : len 为 12, free 为 0, sdshdr->buf 为 " jerry.x.he "
(lldb) x 0x7fdc26500520
0x7fdc26500520: 0c 00 00 00 00 00 00 00 20 6a 65 72 72 79 2e 78 ........ jerry.x
0x7fdc26500530: 2e 68 65 20 00 00 00 00 00 00 00 00 00 00 00 00 .he ............
sdsfromlonglong
创建一个 buffer
依次放入 低位, 再 shift 掉低位, 然后不断循环
比如 1234, 会依次放入 buf[31] = 4, buf[30] = 3, buf[29] = 2, buf[28] = 1
然后 根据 buf[28], 长度为 4, 构造 sds
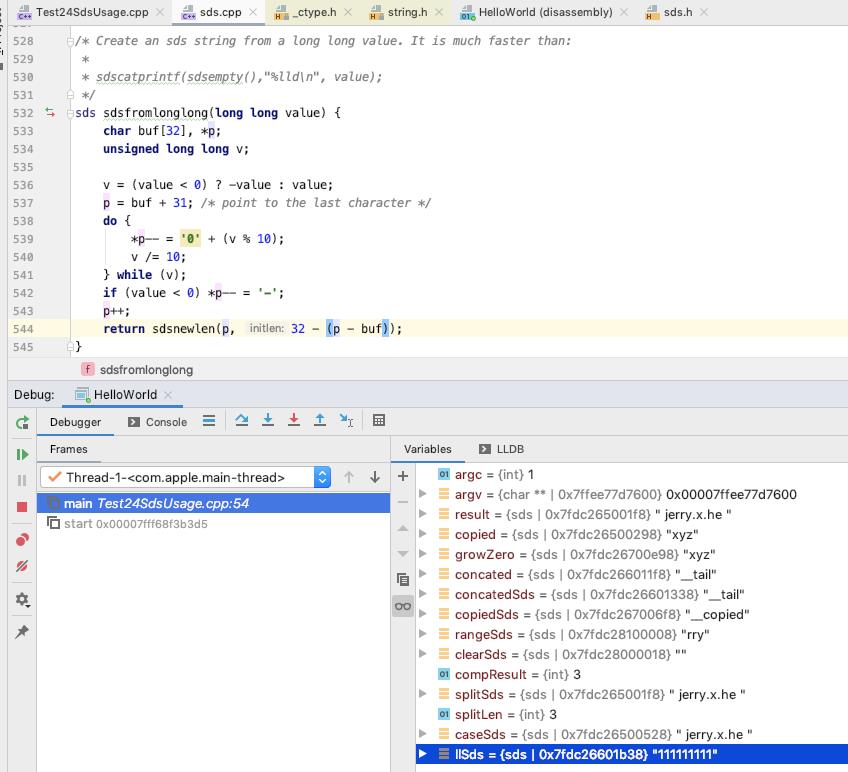
value 为 111111111, 转换出来 llSds 为 "111111111"
sdscatrepr
将给定的字符串内容转义输出出来
"\\r\\n你好" 会被转义为 "\\\\r\\\\n\\\\xe4\\\\xbd\\\\xa0\\\\xe2\\\\x91\\\\xa6", 其中 "0xe4bda0 0xe291a6" 为 "你⑦" 的 utf8 编码之后的字节序列的十六进制的展示形式
我的理解应该是主要是用于调试, 其他工具相关 api 吧, 就好比在 常见的网络交互中我们想要打印出 客户端/服务器 传递过来的字节序列
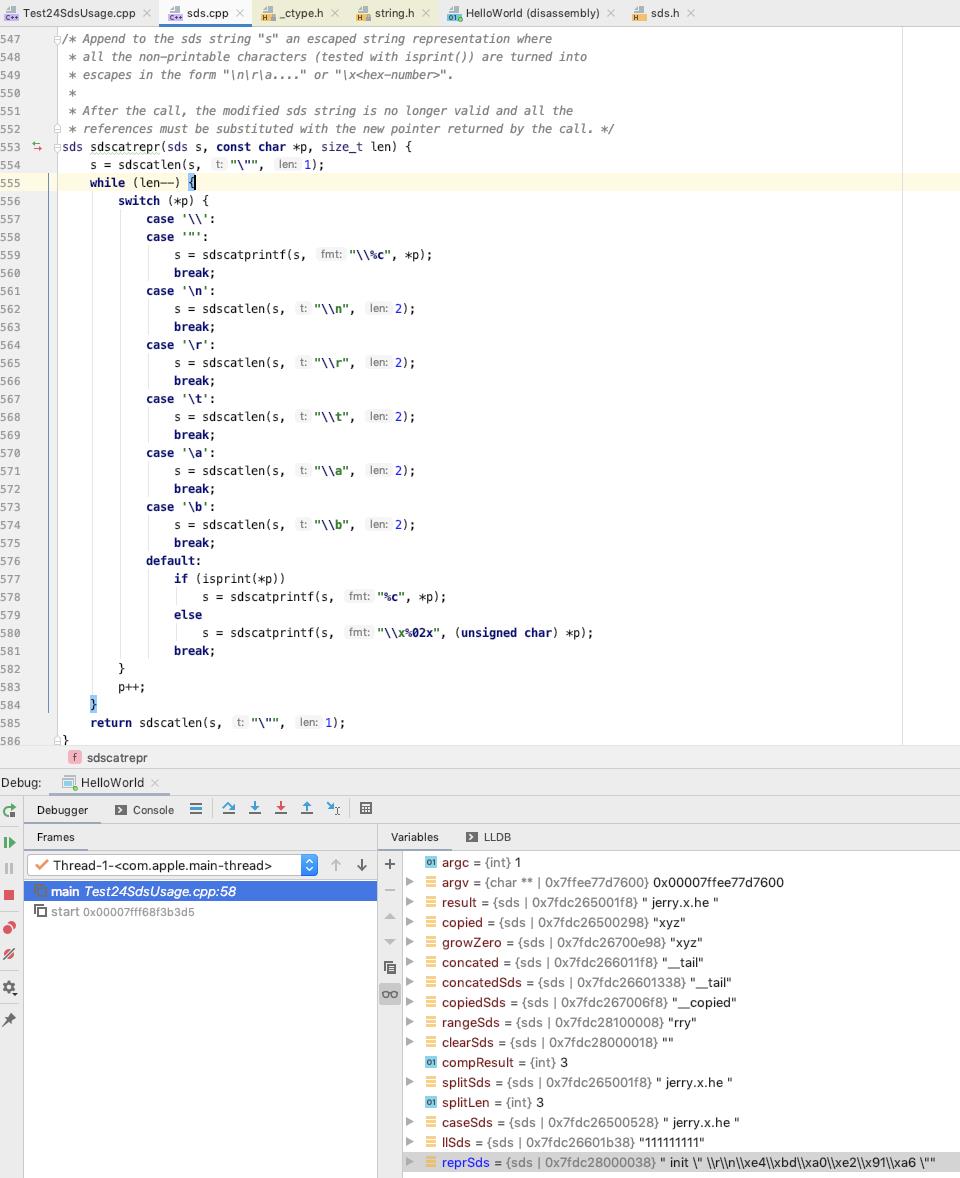
reprSds 内容如下 : len 为 38, free 为 34, sdshdr->buf 为 "init \\" \\\\r\\\\n\\\\xe4\\\\xbd\\\\xa0\\\\xe2\\\\x91\\\\xa6 \\""
(lldb) x 0x7fdc28000030 -c 0x30
0x7fdc28000030: 26 00 00 00 22 00 00 00 20 69 6e 69 74 20 22 20 &..."... init "
0x7fdc28000040: 5c 72 5c 6e 5c 78 65 34 5c 78 62 64 5c 78 61 30 \\r\\n\\xe4\\xbd\\xa0
0x7fdc28000050: 5c 78 65 32 5c 78 39 31 5c 78 61 36 20 22 00 00 \\xe2\\x91\\xa6 "..
sdssplitargs
对于符合 redis 协议字符串的 split
以 ' ', '\\r', '\\n', '\\t', '\\0' 作为拆分 整个字符串
如果是在双引号内部会尝试反转义 "\\\\xe4", "\\\\r", "\\\\n", "\\\\t", "\\\\b", "\\\\a"[对应于上面的 sdscatrepr 的转义]
如果是在单引号内部会尝试反转义 "\\'",
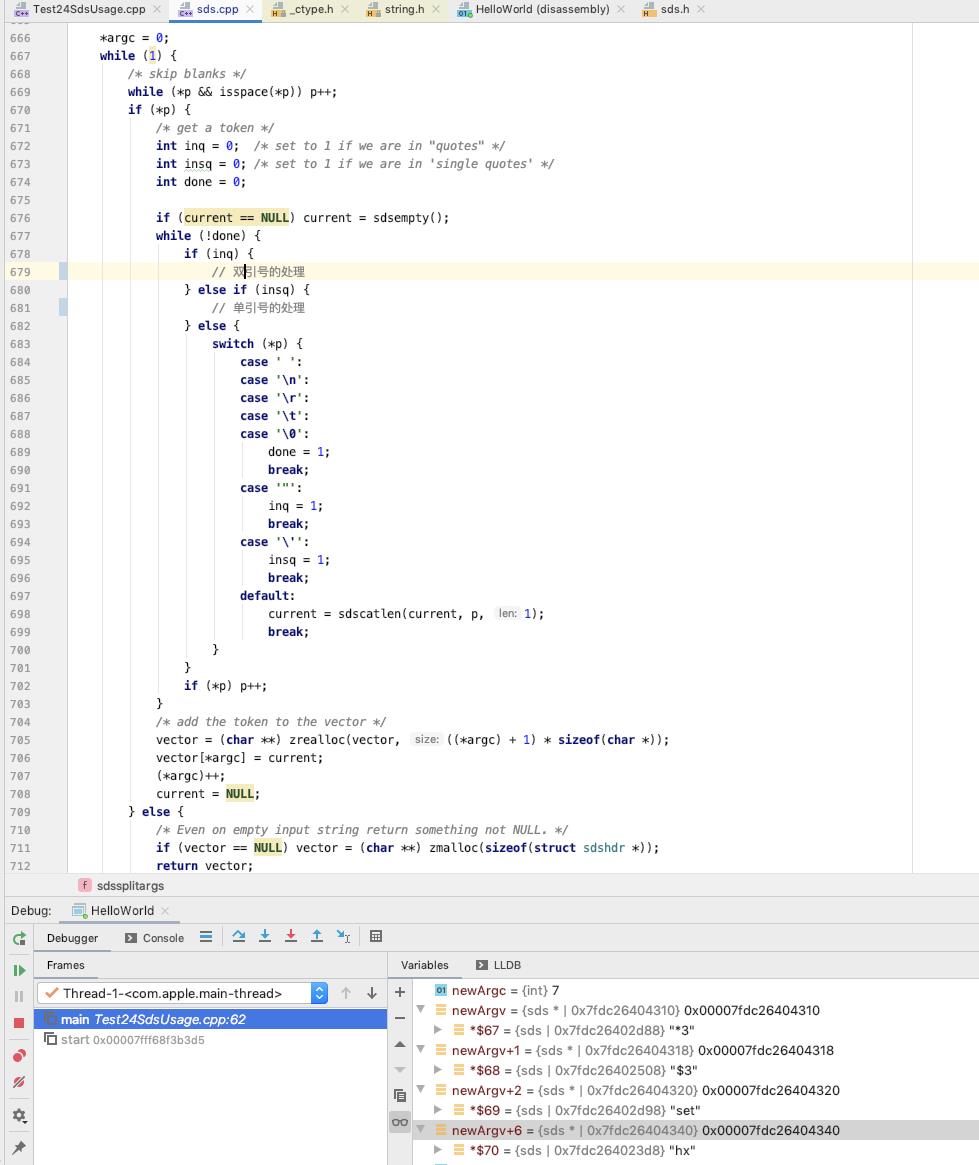
比如这里的 "*3\\r\\n$3\\r\\nset\\r\\n$4\\r\\nname\\r\\n$2\\r\\nhx\\r\\n" 会被拆分成为 "*3", "$3", "set", "$4", "name", "$2", "hx"
sdsmapchars
将给定的 字符串中 from 中存在的字符, 更新为对应位置的 to 中的字符
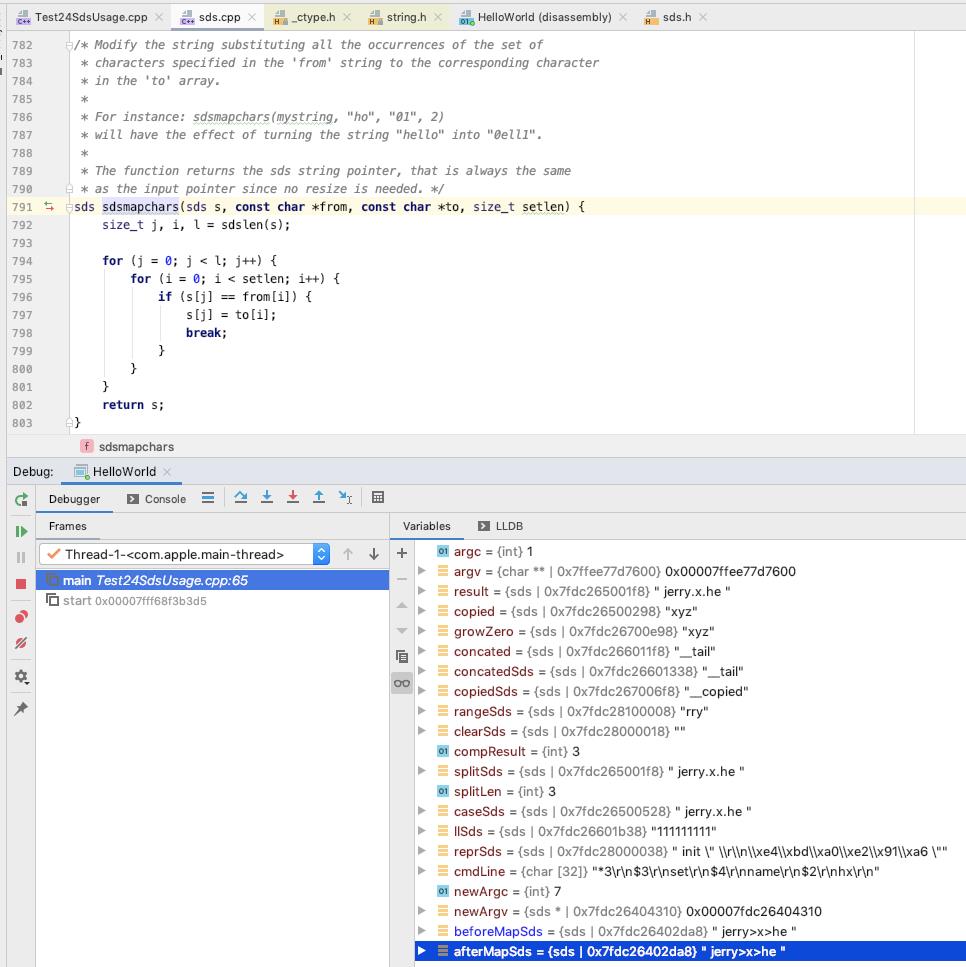
beforeMapSds/afterMapSds 内容如下 : len 为 12, free 为 0, sdshdr->buf 为 " jerry>x>he "
(lldb) x 0x7fdc26402da0
0x7fdc26402da0: 0c 00 00 00 00 00 00 00 20 6a 65 72 72 79 3e 78 ........ jerry>x
0x7fdc26402db0: 3e 68 65 20 00 7f 00 00 f8 24 40 26 dc 7f 02 00 >he .....$@&....
sdsjoin
基于已有的 api 实现的 sdsjoin
concat 元素1
concat seprator
concat 元素2
concat seprator
....
concat 元素N

joinedSds 内容如下 : len 为 14, free 为 14, sdshdr->buf 为 " jerry1->jerry2 "
(lldb) x 0x7fdc26500540
0x7fdc26500540: 0e 00 00 00 0e 00 00 00 6a 65 72 72 79 31 2d 3e ........jerry1->
0x7fdc26500550: 6a 65 72 72 79 32 00 00 00 00 00 00 00 00 00 00 jerry2..........
相对来说 还是比较简单, 主要是需要理解 sds 的存储方式
至于各个函数语义, 可以稍微看下 doc 就明确了
redis-3.2.x 关于 sds 的调整
======================= add at 2021.02.27 =======================
呵呵 突然想起 几年前看到的一个 sds 的版本, 呵呵 不是有几种 case 么, 各种 case 使用的头是不一样的, 占用的内存也有一些区别
然后在查询了一下, redis 3.2.x 之后的版本 sds 的设计有一些调整
https://github.com/antirez/sds/commit/f74b9b785b63c6d8ea312d7e7864df5267149c85
关于 header 的设计有一些调整, 对于 大部分的小字符串来说是 节省了空间
调整之后 sdshdr 根据编码类型[flags] 映射到如下五种 sdshdr##type
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
调整之后 sdshdr5 占用 1 字节
sdshdr8 占用 3 字节
sdshdr16 占用 5 字节,
sdshdr32 占用 9 字节
sdshdr64 占用 17 字节
调整之前 sdshdr 定义为, header 占用 8 字节
struct sdshdr {
int len;
int free;
char buf[];
};
相关业务调整为 创建对象的时候需要根据长度进行计算, 选择哪一种 header, 以及分配对应的空间
业务中需要获取 sdsHdr 的时候, 根据给定的类型进行计算
sdsMakeRoomFor 进行扩容的时候, 判断更新之后的长度属于哪一种类型, 如果不同 新建的时候更新 sdshdr 信息
sdsRemoveFreeSpace 移除一部分无用的空间的时候, 判断更新之后的长度属于哪一种类型, 如果不同 新建的时候更新 sdshdr 信息
我们看一个 sds5 的一个实例
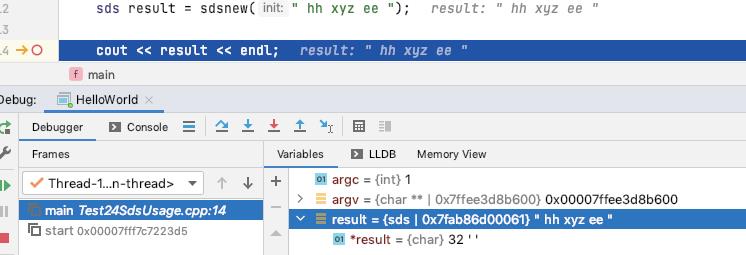
(lldb) x 0x7fab86d00060
0x7fab86d00060: 58 20 68 68 20 78 79 7a 20 65 65 20 00 00 00 e0 X hh xyz ee ...�
0x7fab86d00070: 00 00 00 00 00 00 00 e0 00 00 00 00 00 00 00 e0 .......�.......�
0x58 = 0b0101 10000, 后2bit约束类型, 表示是 sdshdr5, 前面 5bit 表示的是 sdshdr5 的长度, 0b01011 = 11
整个字符串为 " hh xyz ee ", 长度为 11
整体 api 的相关思路上面 基本上和上面是保持一致的
完
以上是关于01 关于 sds的主要内容,如果未能解决你的问题,请参考以下文章