华为云PB级数据库GaussDB(for Redis)揭秘第十期:GaussDB(for Redis)迁移系列(上)
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为云PB级数据库GaussDB(for Redis)揭秘第十期:GaussDB(for Redis)迁移系列(上)相关的知识,希望对你有一定的参考价值。
本文分享自华为云社区《华为云PB级数据库GaussDB(for Redis)揭秘第十期:GaussDB(for Redis)迁移系列(上)》,原文作者:高斯Redis官方博客 。
GaussDB(for Redis)是一款基于计算存储分离架构,兼容Redis生态的云原生NoSQL数据库,基于共享存储池的多副本强一致机制,支持持久化存储。在保障数据库的高兼容、搞性价比、高可靠、无损扩容等特点的同时,GaussDB(for Redis)团队针对不同的数据库产品,为用户提供了多种数据迁移方案,本期将详细介绍社区版Redis、kvrocks和Pika到GaussDB(for Redis)的迁移。
1、Redis到GaussDB (for Redis)的迁移
社区版Redis作为非常受欢迎的内存数据库,因具有性能高,数据结构丰富等优点,得到广泛使用。GaussDB(for Redis)是兼容Redis生态的持久化数据库,不仅提供优秀的读写性能,还提供数据持久化能力,依托超前的系统架构,以极低的成本保证了数据三副本强一致特性,可以避免社区版Redis需要fork、成本高等问题。
1.1 迁移原理
使用华为云自研的迁移工具drs-redis进行源端Redis到目标端GaussDB(for Redis)的迁移。迁移过程中,drs-redis伪装成源端Redis的从节点运行,与源端Redis建立连接后,触发Redis的主从同步。源端Redis生成RDB文件,传输给drs-redis完成全量同步。然后发送缓冲区保存的所有写命令到drs-redis完成增量同步。 drs-redis迁移工具接收并解析源端Redis的RDB文件,将解析后的数据通过redis命令的方式发送到GaussDB(for Redis),然后以命令传播的方式将增量数据也发送到GaussDB(for Redis),完成迁移。
1.2 前提条件
- 部署迁移工具drs-redis。
- 保证迁移工具drs-redis、源端Redis和目标端GaussDB(for Redis)网络互通。
1.3 操作步骤
- 正确修改drs相关配置文件。
- 清理迁移程序中可能的遗留数据。
- 启动drs,跟踪日志,确保迁移正确进行。
1.4 使用须知
- drs-redis伪装成源端Redis的从节点,只读取源端的全量数据和增量命令,无数据受损风险。
- 源端增加对drs-redis写数据的流程,因此性能会有轻微影响。
- GaussDB(for Redis)支持多个数据库,若源端是单节点Redis,需要保留多个数据库时,可以在GaussDB(for Redis)侧开启namespace功能,避免将多个数据库的数据迁移到同一空间,造成数据丢失。
- 如果之前源端不存在从节点,源端会新增replication-buffer来缓存增量命令。
问题:redis主从同步的replication-buffer是ring buffer,若写入buffer太快,会覆盖掉未发送给drs-redis的数据,源端Redis为了数据一致性会主动断开连接,造成迁移失败。
建议:迁移过程中,降低源端Redis写入数据的速率,在低压时间段进行迁移。配置redis的client-output-buffer-limit参数,适量增大replication-buffer的大小。
1.5 迁移性能参考
环境:源端单节点Redis和迁移工具drs-redis部署在华为云8U32GB的弹性云服务器上,目标端为4U16GB,3节点GaussDB(for Redis)实例。
- 场景一:
− 源端replication buffer采用默认值(slave 268435456 67108864 60),该默认值表示缓存积压数据超过268435456bytes(256MB),或超过67108864bytes(64MB)且持续60s,源端会主动断开与从节点的连接。
− 源端写入速率5MB/s,迁移过程可持续进行,不会产生源端buffer满造成的同步失败。
− 迁移工具读取数据的速率和源端写入速率一致。
- 场景二:
− 源端replication buffer不做限制(config set "client-output-buffer-limit" "slave 0 0 0")。
− 源端写入速率10MB/s,容量充足的情况下,迁移持续进行。
− 迁移工具读取数据的速率和源端写入速率一致。
结论: 在华为云环境,使用8U32GB弹性云服务器部署迁移工具,若源端replication buffer采用默认值,迁移可在源端5MB/s的写入速率下进行;若源端对replication buffer不做限制,迁移可在源端10MB/s的写入速率下进行。
2、Kvrocks到GaussDB(for Redis)的迁移
Kvrocks是一款开源的兼容Redis生态的NoSQL key-value数据库,底层基于RocksDB实现,提供namespace功能支持数据分区。Kvrocks集群管理功能相对薄弱,自建集群时需要与外部组件配合。Kvrocks支持的redis命令也不够全面,例如缺少在消息流和统计场景经常使用的stream及hyperloglog数据结构。
GaussDB(for Redis)以不亚于RedisCluster的兼容度,使用户在应用时无需修改代码,可直接使用,100%兼容原生接口。GaussDB(for Redis)在适配Kvrocks业务的同时,还能克服器管理能力弱、对Redis兼容度不高等缺点。
2.1迁移原理
使用开源工具kvrocks2redis进行Kvrocks到GaussDB(for Redis)的迁移,在此基础上,从GaussDB(for Redis)源码层面对Kvrocks的namespace功能进行适配。
迁移过程分为全量和增量两个阶段:迁移开始后,先进行全量迁移,此时对kvrocks打快照,并记录对应的数据版本(seq)。然后解析全量数据文件成redis命令写入GaussDB(for Redis)。全量迁移完成后进入持续的增量迁移过程,迁移工具循环给Kvrocks发送PSYNC命令,将获取到的增量数据不断转发给GaussDB(for Redis),完成增量迁移 。
2.2 前提条件
- 部署kvrocks2redis到独立主机。
- 确保源端、目标端、迁移工具之间网络互通。
- 源端Kvrocks实例提前做好数据备份。
- 目标端GaussDB(for Redis)实例清空全部数据。
2.3 操作步骤
- 修改迁移工具配置文件,填入源端kvrocks连接信息、目标端GaussDB (for Redis) 连接信息、源端kvrocks namespace到目标端GaussDB (for Redis) DB的映射关系。
- 确保配置文件内容正确。
- 启动迁移工具。
- 跟踪日志,确保全量迁移顺利完成,进入持续增量迁移过程。
- 进行验证。确保数据迁移后,目标端GaussDB (for Redis) 已正确加载全部数据。
- 待后续业务侧压力转移到GaussDB (for Redis) 后,停止增量迁移,即手动停止迁移工具的运行。
2.4 使用须知
- kvrocks2redis需要从Kvrocks提取数据到本地文件,并从中解析出命令发送到目标端GaussDB(for Redis) ,该过程中可能影响源端性能,但理论上不会有数据受损风险。
- 迁移工具运行过程中,若出现问题,迁移工具会自动停止,方便问题定位。
- GaussDB(for Redis)从安全性角度出发,不提供清库语义命令,因此要在迁移开始前确保无数据。
3、Pika到GaussDB(for Redis)的迁移
Pika是一个可持久化的大容量Redis存储服务,解决了Redis由于存储数据量巨大而导致内存不够用的容量瓶颈。但其集群管理功能较为薄弱,需要使用twemproxy或者codis实现静态数据分片,数据一致性较弱。同时由于数据全部存储在磁盘中,相比于社区版Redis,性能明显下降。
GaussDB(for Redis)实现了冷热分离,解决了缓存(cache)与数据库(Data Base,DB)之间交互访问的问题,当用户数据量小于内存时可以达到和社区版redis相当的性能。通过proxy代理,使上层业务可以不感知内核处理扩缩容过程中的数据迁移。
3.1迁移原理
使用开源迁移工具pika-port进行Pika到GaussDB(for Redis)的迁移。pika-port伪装成Pika的从节点运行,通过主从复制的方式进行数据迁移。Pika主节点通过比较pika-port和自己的binlog偏移量判断做全量迁移还是增量迁移。如果需要做全量迁移,Pika主节点会将全量数据快照发送给pika-port,pika-port将解析后的快照数据发送给GaussDB(for Redis)。全量迁移结束后进入增量迁移,pika-port将增量数据解析后以redis命令的形式发送给GaussDB(for Redis)。
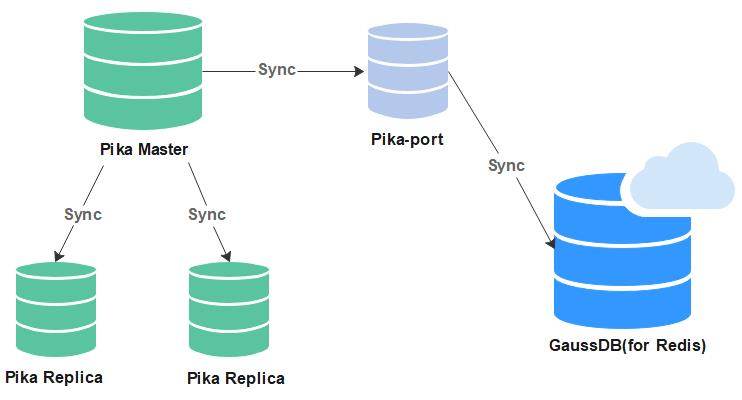
3.2 前提条件
- 部署迁移工具pika-port
- 确保源端Pika实例、pika-port和目标端GaussDB(for Redis)实例网络互通。
3.3 操作步骤
- 正确修改pika-port配置文件;
- 启动迁移工具pika-port;
- 跟踪日志,确保全量迁移完成后停服,进入增量迁移过程;
- 增量迁移完成后,校验迁移数据的正确性和完备性;
- 校验完毕将业务切到GaussDB (for Redis).
3.4 使用须知
- pika-port伪装成源端Pika的从节点,只读取全量和增量数据,无数据受损风险。
- 源端增加了和pika-port的主从同步流程,可能会影响源端性能。
- 全量和增量结合迁移可以不停服,业务切入GaussDB(for Redis)时短暂停服。
3.5 迁移性能参考
环境:Pika(单节点)和pika-port同时部署在华为云8U32GB的弹性云服务器上,目标端为8U16GB,3节点GaussDB(for Redis)实例。
预置数据:使用memtier_benchmark工具预置200GB数据。
迁移性能:约50000qps。
4、结语
高斯 Redis 在社区版 Redis 的基础上,结合华为自研强一致存储DFV Pool,具有强一致、秒扩容、超可用、低成本等优势,保证了计数的准确性、可靠性。
本文作者:华为云高斯Redis团队。
杭州西安深圳简历投递:yuwenlong4@huawei.com
更多技术文章,关注高斯Redis官方博客:https://bbs.huaweicloud.com/community/usersnew/id_1614151726110813
以上是关于华为云PB级数据库GaussDB(for Redis)揭秘第十期:GaussDB(for Redis)迁移系列(上)的主要内容,如果未能解决你的问题,请参考以下文章
华为云PB级数据库GaussDB(for Redis)揭秘第九期:与HBase的对比
华为云PB级数据库GaussDB(for Redis)揭秘第13期:如何搞定推荐系统存储难题
解读 SSDBLevelDB 和 RocksDB 到 GaussDB(for Redis) 的迁移