redis的dict结构
Posted 翔之天空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis的dict结构相关的知识,希望对你有一定的参考价值。
极客时间:02 | 数据结构:快速的Redis有哪些慢操作?
redis设计与实践
Redis的一个database中所有key到value的映射,就是使用一个dict来维护的
dict数据结构
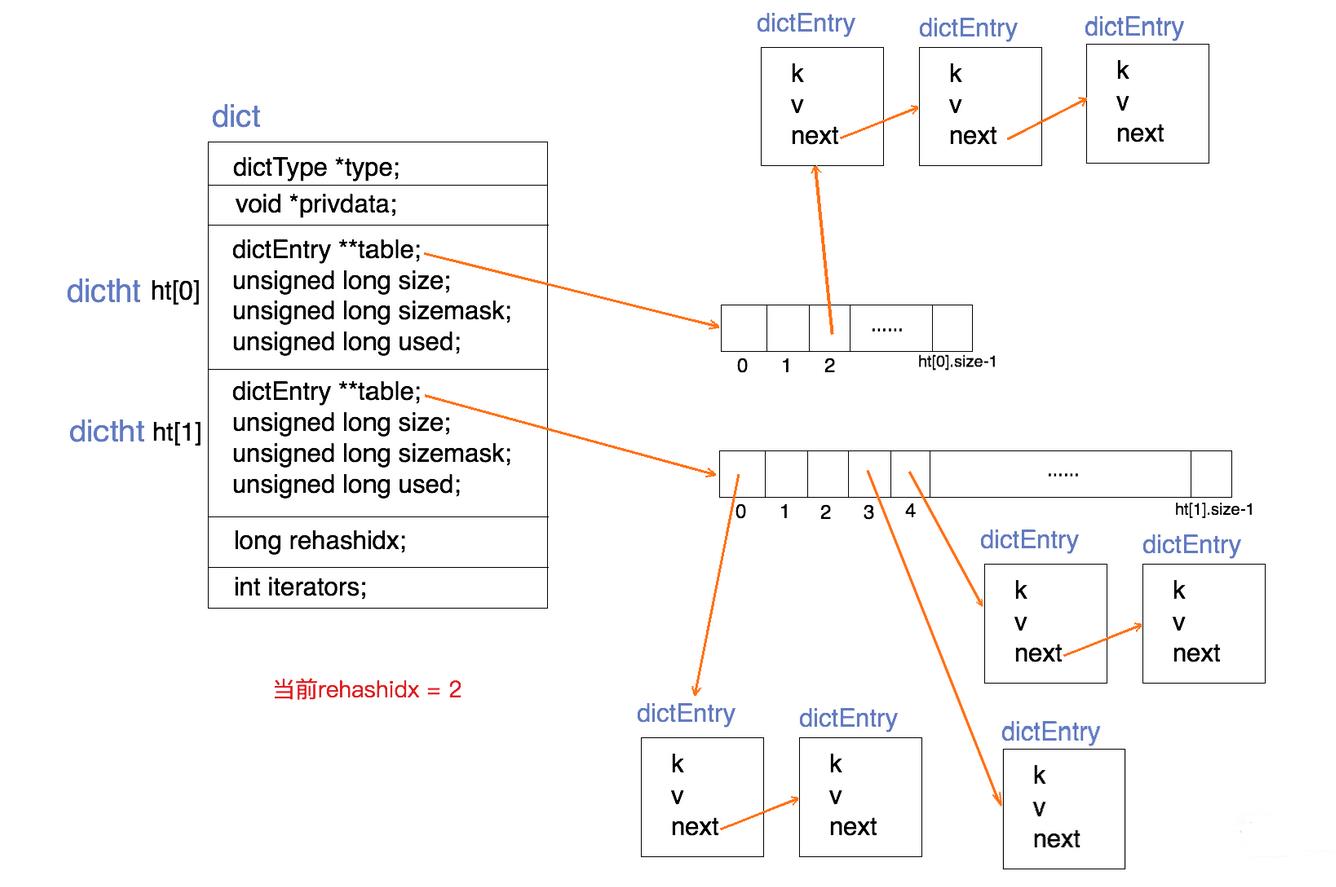
--1、新增一个key的流程: set msg 999
main
|-aeMain //事件处理器的主循环, aeMain 函数其实就是一个封装的 while 循环,循环中的代码会一直运行直到 eventLoop 的 stop 被设置为 true
|-aeProcessEvents //实际用于处理事件的函数
|-processInputBuffer
|-processCommand
|-call
|-setCommand //具体命令的解析 这里是set命令: SET key value [NX] [XX] [EX <seconds>] [PX <milliseconds>] 命令
|-setGenericCommand //set类型命令的通用方法,包括 :SET, SETEX, PSETEX, SETNX
|-setKey //set key的具体方法
|-lookupKeyWrite //查找是否存在此key,如果不存在用dbAdd添加,如果存在走dbOverwrite(db,key,val);覆盖 详见如下
|-lookupKey
|-dictFind //查找key的具体方法 计算出ht[].table.index 具体的bucket, hash效率O(1), 除非哈希冲突链表 很长
|-dbAdd
|-dictAdd //新增key 和value值
|-dictAddRaw //新增key 操作,详见如下
|-_dictRehashStep //rehash的步骤
|-_dictKeyIndex //经过hash后 确认在哪个bucket中 赋值给index ,在index冲突链表的表头添加这个key : entry->next = ht->table[index]; ht->table[index] = entry;
|-_dictExpandIfNeeded //判断hash table是否需要扩展 需要的话扩展一倍buckets数量
|-dictExpand //创建hash table
|-dictSetKey //添加key
|-dictSetVal(d, entry, val) //添加value
|-dbOverwrite //如果要set的key存在 走dbOverwrite(db,key,val);覆盖
|-dictReplace //具体的逻辑实现 还是继续dictAddRaw 和dictSetVal 方式 添加key和value ,详见如下
#1 0x0000000000428371 in dictAddRaw (d=d@entry=0x7ffff0818540, key=0x7ffff0816761, existing=existing@entry=0x0) at dict.c:302
#2 0x0000000000428541 in dictAdd (d=0x7ffff0818540, key=<optimized out>, val=val@entry=0x7ffff088f9f0) at dict.c:267
#3 0x0000000000440d55 in dbAdd (db=0x7ffff094f038, key=0x7ffff08a9ed0, val=0x7ffff088f9f0) at db.c:169
#4 0x0000000000441235 in setKey (db=0x7ffff094f038, key=key@entry=0x7ffff08a9ed0, val=val@entry=0x7ffff088f9f0) at db.c:208
#5 0x000000000044c378 in setGenericCommand (c=c@entry=0x7ffff0962340, flags=flags@entry=0, key=0x7ffff08a9ed0, val=0x7ffff088f9f0,
expire=expire@entry=0x0, unit=unit@entry=0, ok_reply=ok_reply@entry=0x0, abort_reply=abort_reply@entry=0x0) at t_string.c:86
#6 0x000000000044c58f in setCommand (c=0x7ffff0962340) at t_string.c:139
#7 0x000000000042c0de in call (c=c@entry=0x7ffff0962340, flags=flags@entry=15) at server.c:2229
#8 0x000000000042c7e7 in processCommand (c=0x7ffff0962340) at server.c:2515
#9 0x000000000043b8d5 in processInputBuffer (c=0x7ffff0962340) at networking.c:1357
#10 0x0000000000426820 in aeProcessEvents (eventLoop=eventLoop@entry=0x7ffff083c050, flags=flags@entry=11) at ae.c:443
#11 0x0000000000426aeb in aeMain (eventLoop=0x7ffff083c050) at ae.c:501
#12 0x00000000004238ef in main (argc=<optimized out>, argv=0x7fffffffe168) at server.c:3899
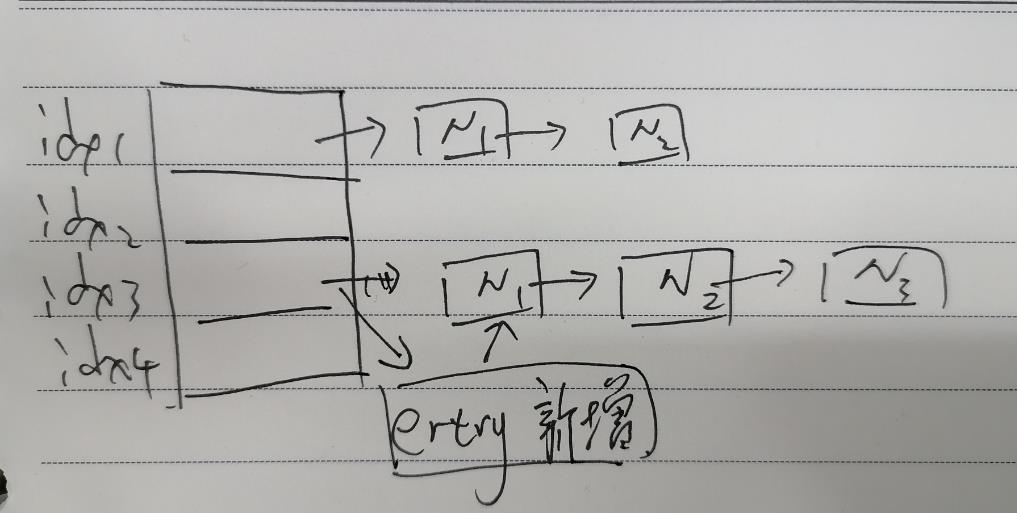
--2、具体新增key的方法 dictAddRaw
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果条件允许的话,进行单步 rehash
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) // 计算键在哈希表中的索引值
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 如果字典正在 rehash ,那么将新键添加到 1 号哈希表, 否则,将新键添加到 0 号哈希表
entry = zmalloc(sizeof(*entry)); // 为新节点分配空间
entry->next = ht->table[index]; // 将新节点插入到链表表头,详见下图 在bucket桶(idx3) 中每次都插入到链表头部 再次查找时减少比较次数
ht->table[index] = entry;
ht->used++; // 更新哈希表已使用节点数量
/* Set the hash entry fields. */
dictSetKey(d, entry, key); // 设置新节点的键
return entry;
}
--3、具体覆盖key的方法
dictReplace
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, *existing, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
entry = dictAddRaw(d,key,&existing); //再次尝试添加key到redis中,如果key不存在那么 添加成功 直接返回, 存在的话 记录位置 existing
if (entry) {
dictSetVal(d, entry, val);
return 1;
}
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry = *existing; //说明key已存在 保存原有值的指针
dictSetVal(d, existing, val); //设置新的值
dictFreeVal(d, &auxentry); //释放旧的值
return 0;
}
--4、获取key的流程 get msg
#0 dictFind (d=0x7ffff0818540, key=0x7ffff08a9f13) at dict.c:477
#1 0x000000000043fcb4 in lookupKey (db=db@entry=0x7ffff094f038, key=key@entry=0x7ffff08a9f00, flags=flags@entry=0) at db.c:54
#2 0x0000000000440f55 in lookupKeyReadWithFlags (db=0x7ffff094f038, key=0x7ffff08a9f00, flags=flags@entry=0) at db.c:127
#3 0x0000000000440fe7 in lookupKeyRead (key=<optimized out>, db=<optimized out>) at db.c:138
#4 lookupKeyReadOrReply (c=c@entry=0x7ffff0962340, key=<optimized out>, reply=0x7ffff0817920) at db.c:152
#5 0x000000000044c798 in getGenericCommand (c=0x7ffff0962340) at t_string.c:160
#6 0x000000000042c0de in call (c=c@entry=0x7ffff0962340, flags=flags@entry=15) at server.c:2229
#7 0x000000000042c7e7 in processCommand (c=0x7ffff0962340) at server.c:2515
#8 0x000000000043b8d5 in processInputBuffer (c=0x7ffff0962340) at networking.c:1357
#9 0x0000000000426820 in aeProcessEvents (eventLoop=eventLoop@entry=0x7ffff083c050, flags=flags@entry=11) at ae.c:443
#10 0x0000000000426aeb in aeMain (eventLoop=0x7ffff083c050) at ae.c:501
#11 0x00000000004238ef in main (argc=<optimized out>, argv=0x7fffffffe168) at server.c:3899
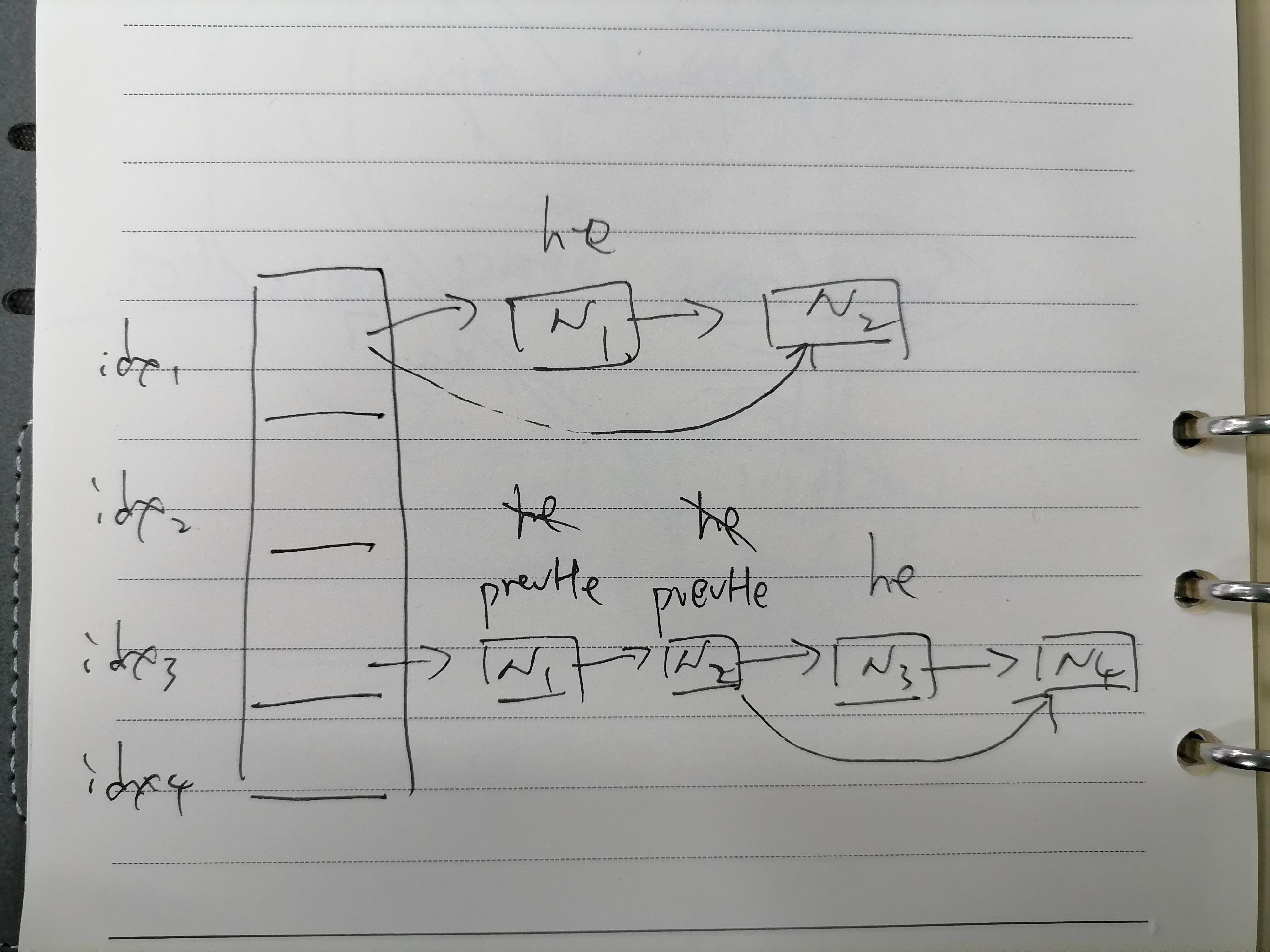
--5、删除key的方法 :dictGenericDelete
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL; //如果hash表总元素为空,直接返回空
if (dictIsRehashing(d)) _dictRehashStep(d); //如果正在做rehashing,那么帮忙做一桶的迁移工作
h = dictHashKey(d, key); //获取key相关的hash值
for (table = 0; table <= 1; table++) { //查找table0,table1两张hash表
idx = h & d->ht[table].sizemask; //获取所在桶的索引 和sizemask掩码与 和 取余一样
he = d->ht[table].table[idx]; //获取桶的首元素
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) { //如果找到了相同的元素
/* Unlink the element from the list */
if (prevHe) //不是在首位置,即在中间,链表中跳过这个元素即可
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next; //在首位的情况下,就直接去掉首位
if (!nofree) { //如果需要释放,将键和值的空间释放,并且将这个元素的空间也释放
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he; //没有找到相同额元素,将自身赋值给prevHe保存
he = he->next; //查找下一个
}
if (!dictIsRehashing(d)) break; //没有做rehashing,那么值需要查找表0即可
}
return NULL; /* not found */没有找到元素,返回空
}
举例:在第一个bucket桶里(idx1)中,此时单向链表首位置n1是he,如果he找到了匹配的key 那么 走else选项 用 he的next指针 赋给d->ht[table].table[idx] 也就是去掉首位置的n1节点
在第三个bucket桶里(idx3)中,在n1和n2节点都没有匹配到key 在n3匹配到了, 那么n3是he 、n3的前一个节点n2是prevHe 此时要把 he的next指针 赋给 prevHe->next 也就是把n3节点去掉
以上是关于redis的dict结构的主要内容,如果未能解决你的问题,请参考以下文章