ThreadLocal源码分析_02 内核(ThreadLocalMap)
Posted 兴趣使然の草帽路飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadLocal源码分析_02 内核(ThreadLocalMap)相关的知识,希望对你有一定的参考价值。
- 本篇文章是接着上一篇:ThreadLocal源码分析_01 入门案例以及表层源码分析,继续分析!
- 本篇主要介绍ThreadLocal的内核ThreadLocalMap(ThreadLocal的静态内部类),在学习ThreadLocalMap内核前,再来复习一下ThreadLocal的执行流程图:

下面就正式分析一下ThreadLocalMap的原理:
1、成员属性
/**
* 初始化当前map内部散列表数组的初始长度 16
*/
private static final int INITIAL_CAPACITY = 16;
/**
* threadLocalMap 内部散列表数组的引用,数组的长度必须是2的次方数
*/
private Entry[] table;
/**
* 当前散列表数组占用情况,存放多少个entry。
*/
private int size = 0;
/**
* 扩容触发阈值,初始值为: len * 2/3
* 触发后调用 rehash() 方法。
* rehash() 方法先做一次全量检查全局过期数据,把散列表中所有过期的entry移除。
* 如果移除之后,当前散列表中的entry个数仍然达到(threshold - threshold/4),
* 即,当前threshold阈值的3/4就进行扩容。
*/
private int threshold; // Default to 0
/**
* Set the resize threshold to maintain at worst a 2/3 load factor.
* 将阈值设置为 (当前数组长度 * 2)/ 3。
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
/**
* 将阈值设置为 (当前数组长度 * 2)/ 3。
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
2、内部类
这里内部类Entry继承了弱引用WeakReference:
-
什么是弱引用呢?eg:
A a = new A(); // 强引用 WeakReference weakA = new WeakReference(a); // 弱引用当
a = null;,则下一次GC时对象a就被回收了,不管有没有弱引用是否在关联这个对象: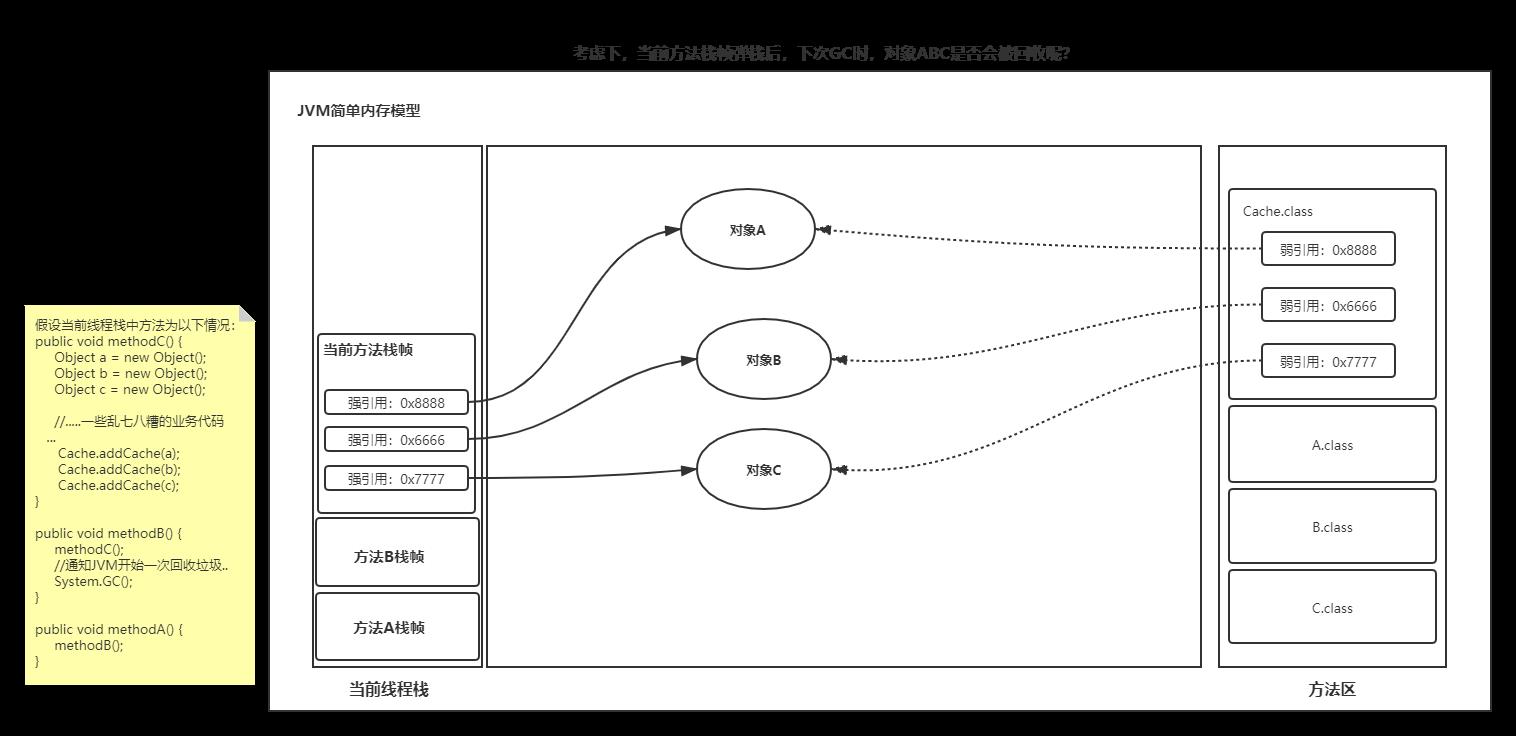
对于弱引用强引用详细介绍,可以参考:这篇文章第1小节总结了Java种的5种引用!
-
key 使用的是弱引用保留,key保存的是threadLocal对象。
-
value 使用的是强引用,value保存的是 threadLocal对象与当前线程相关联的 value。
/**
* ThreadLocalMap的Entry内部类: 成员属性有2个 ---> key 和 value
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
// value:使用的是强引用,value保存的是 threadLocal对象与当前线程相关联的value。
Object value;
// k: key 使用的是弱引用保留,key保存的是threadLocal对象。
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
Entry的key这样设计有什么好处呢?
- 当threadLocal对象失去强引用且对象GC回收后,散列表中的与 threadLocal对象相关联的 entry#key 再次去
key.get()时,拿到的是null。 - 站在map角度就可以区分出哪些entry是过期的,哪些entry是非过期的。
3、构造方法
Thread.threadLocals字段是延迟初始化的,只有线程第一次存储threadLocal-value时才会创建!
/**
* firstKey: threadLocal对象
* firstValue: 当前线程与threadLocal对象关联的value
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 创建entry数组长度为16,表示threadLocalMap内部的散列表。
table = new Entry[INITIAL_CAPACITY];
// 寻址算法:key.threadLocalHashCode & (table.length - 1)
// table数组的长度一定是 2 的次方数。
// 2的次方数-1 有什么特征呢? 转化为2进制后都是1. 16 ==> 1 0000 - 1 => 1111
// 1111与任何数值进行&运算后 得到的数值 一定是 <= 1111
// i计算出来的结果一定是 <= b1111
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 创建entry对象 存放到指定位置的slot中。
table[i] = new Entry(firstKey, firstValue);
// 设置size = 1
size = 1;
// 设置扩容阈值 (当前数组长度 * 2)/ 3 => 16 * 2 / 3 => 10
setThreshold(INITIAL_CAPACITY);
}
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
4、成员方法
nextIndex方法
/**
* 获得下一个数组下标位置:
* 参数1:当前散列表数组下标
* 参数2:当前散列表数组长度
*/
private static int nextIndex(int i, int len) {
// 当前数组下标i+1,如果计算结果:小于散列表数组长度,则返回 +1后的值
// 否则:这种情况就是 下标i+1 == len ,返回0
return ((i + 1 < len) ? i + 1 : 0);
// 实际形成一个环绕式的访问,如下图:
}
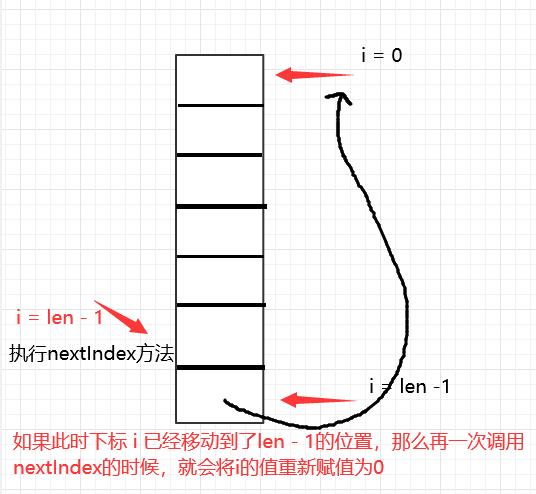
prevIndex方法
/**
* 获得上一个数组下标位置:
* 参数1:当前散列表数组下标
* 参数2:当前散列表数组长度
*/
private static int prevIndex(int i, int len) {
// 当前下标i-1 大于等于0,则返回 i-1后的值。
// 否则,说明当前下标i-1 == -1. 此时返回散列表最大下标。
// 实际形成一个环绕式的访问。
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
getEntry方法
- ThreadLocal对象的
get()方法实际上是由ThreadLocalMap.getEntry()代理完成的!
/**
* 根据ThreadLocal对象,获取Entry
* key: 某个ThreadLocal对象,因为散列表中存储的entry.key类型是ThreadLocal。
* @return Entry
*/
private Entry getEntry(ThreadLocal<?> key) {
// 桶位路由规则: ThreadLocal.threadLocalHashCode & (table.length - 1) ==> index
int i = key.threadLocalHashCode & (table.length - 1);
// 访问散列表中指定位置的slot桶,拿到 Entry
Entry e = table[i];
// 条件一:成立 说明slot有值
// 条件二:成立 说明entry#key 与当前查询的key一致,返回当前entry给上层就可以了。
if (e != null && e.get() == key)
return e;
else
// 有几种情况会执行到这里?
// 情况一:桶位上的 e == null
// 情况二:根据key没有查询到 e.key != key
// getEntryAfterMiss方法:会继续向当前桶位后面继续搜索 e.key == key 的entry.
// 为什么这样做呢??
// 因为存储时如果发生hash冲突后,并没有在entry层面形成链表...
// 那么,当存储时,如果hash冲突了,处理的方式就是线性的向后找到一个可以使用的slot,并且将entry存放进去。
return getEntryAfterMiss(key, i, e);
}
getEntryAfterMiss方法
- 继续在桶位i之后的桶中寻找满足
e.key == key条件的桶!
/**
* 继续在桶位i之后的桶中寻找满足e.key == key条件的桶!
* @param threadLocal对象表示key
* @param i表示key计算出来的index
* @param e表示table[index] 中的 entry
* @return Entry
*/
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
// 获取当前threadLocalMap中的散列表table
Entry[] tab = table;
// 获取table长度
int len = tab.length;
// while循环条件:e != null 说明向后查找的范围是有限的,碰到 slot == null 的情况,则搜索结束!
// e: 循环处理的当前元素
while (e != null) {
// 获取当前slot中entry对象的key
ThreadLocal<?> k = e.get();
// k == key条件成立:说明向后查询过程中找到合适的entry了,直接返回entry就ok了。
if (k == key)
// 找到的情况下,就从这里返回了~
return e;
// k == null条件成立:说明当前slot中的entry#key 关联的ThreadLocal对象已经被GC回收了..
// 因为key是弱引用,key = e.get() == null.
if (k == null)
// 做一次探测式过期数据回收。
expungeStaleEntry(i);
else
// 更新index,继续向后搜索
i = nextIndex(i, len);
// 获取下一个slot中的entry。
e = tab[i];
}
// 执行到这里,说明关联区段内都没找到相应数据。
return null;
}
expungeStaleEntry方法
- 探测式清理过期数据:以staleSlot位置开始继续向后查找过期数据,直到碰到
slot == null的情况结束,并返回结束时的数组下标位置~
/**
* 参数staleSlot: table[staleSlot]就是一个过期数据,
* 以这个位置开始继续向后查找过期数据,直到碰到slot == null的情况结束:
*/
private int expungeStaleEntry(int staleSlot) {
// 获取散列表
Entry[] tab = table;
// 获取散列表当前长度
int len = tab.length;
// help gc
tab[staleSlot].value = null;
// 因为staleSlot位置的entry是过期的,所以这里直接置为Null
tab[staleSlot] = null;
// 因为上面干掉一个元素,所以 size-1.
size--;
// e:表示当前遍历节点
Entry e;
// i:表示当前遍历的index
int i;
// for循环从staleSlot + 1的位置开始搜索过期数据,直到碰到 slot == null 结束:
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
// 进入到for循环里面 当前entry一定不为null
// 获取当前遍历节点 entry 的key.
ThreadLocal<?> k = e.get();
// 条件成立:说明k表示的threadLocal对象已经被GC回收了...
// 则,当前entry属于脏数据了...
if (k == null) {
// help gc
e.value = null;
// 脏数据对应的slot置为null
tab[i] = null;
// 因为上面干掉一个元素,所以 size-1.
size--;
} else {
// 执行到这里,说明当前遍历的slot中对应的entry 是非过期数据:
// 因为前面有可能清理掉了几个过期数据,且当前entry存储时有可能碰到hash冲突了,
// 应该往后偏移存储,这个时候应该去优化位置,让这个位置更靠近正确位置!
// 这样的话,查询的时候效率才会更高!
// 重新计算当前entry对应的 index
int h = k.threadLocalHashCode & (len - 1);
// 条件成立:说明当前entry存储时 就是发生过hash冲突,然后向后偏移过了...
if (h != i) {
// 将entry当前位置 设置为null
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
// h 是正确位置。
// 以正确位置h 开始,向后查找第一个 可以存放entry的位置。
while (tab[h] != null)
h = nextIndex(h, len);
// 将当前元素放入到 距离正确位置 更近的位置(有可能就是正确位置)。
tab[h] = e;
}
}
}
return i;
}
该方法执行流程图如下所示:
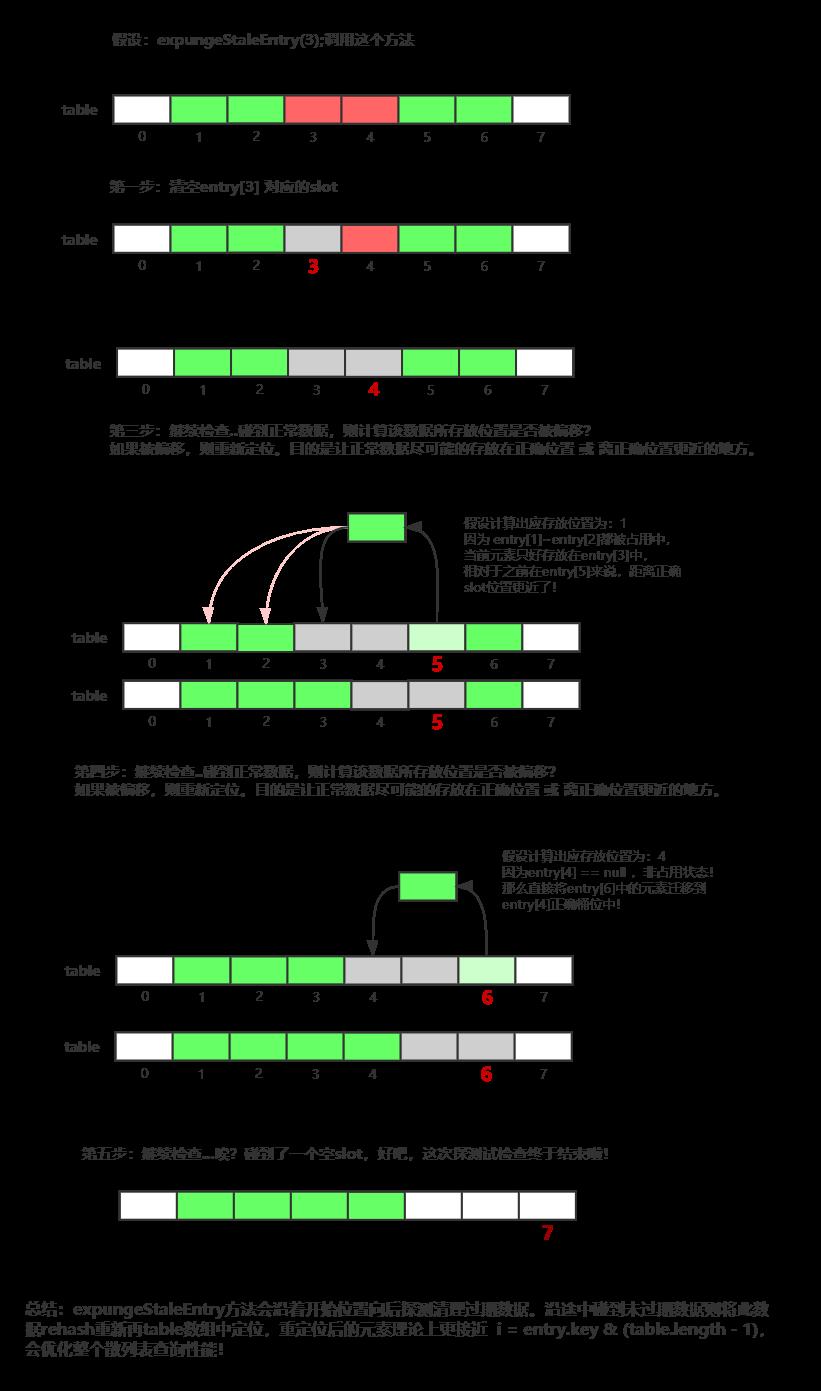
set方法
- ThreadLocal使用set方法给当前线程添加 threadLocal-value键值对:
/**
*
* ThreadLocal使用set方法给当前线程添加 threadLocal-value键值对
*
* @param key:threadLocal对象(Entry的key值)
* @param value:Entry的value值
*/
private void set(ThreadLocal<?> key, Object value) {
// 获取散列表
Entry[] tab = table;
// 获取散列表数组长度
int len = tab.length;
// 计算当前key 在散列表中的对应的位置
int i = key.threadLocalHashCode & (len-1);
// 以当前key对应的slot位置向后查询,直到找到可以使用的slot桶位:
// 什么时候slot桶位可以使用呢??
// 1.k == key说明是替换
// 2.碰到一个过期的slot ,这个时候可以强行占用
// 3.查找过程中碰到 slot == null
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 获取当前元素key
ThreadLocal<?> k = e.get();
// 条件成立:说明当前set操作是一个替换操作:
if (k == key) {
// 做替换逻辑:
e.value = value;
return;
}
// 条件成立:说明向下寻找过程中碰到entry#key == null 的情况了,说明当前entry是过期数据:
if (k == null) {
// 碰到一个过期的slot ,这个时候可以强行占用该桶位
// 替换过期数据的逻辑:
replaceStaleEntry(key, value, i);
return;
}
}
// 执行到这里,说明for循环碰到了slot == null 的情况。
// 在合适的slot中,创建一个新的entry对象:
tab[i] = new Entry(key, value);
// 因为是新添加,所以++size.
int sz = ++size;
// 做一次启发式清理:
// 条件一:!cleanSomeSlots(i, sz) 成立,说明启发式清理工作未清理到任何数据..
// 条件二:sz >= threshold 成立,说明当前table内的entry已经达到扩容阈值了..会触发rehash操作。
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
replaceStaleEntry方法
- 在
set()方法向下寻找可用solt桶位的过程中,如果碰到key == null的情况,说明当前entry是过期数据,这个时候可以强行占用该桶位,通过replaceStaleEntry方法执行替换过期数据的逻辑:
/**
* @param key: 键 threadLocal对象
* @param value: val
* @param staleSlot: 上层方法set方法,迭代查找时发现的当前这个slot是一个过期的entry
*/
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
// 获取散列表
Entry[] tab = table;
// 获取散列表数组长度
int len = tab.length;
// 临时变量
Entry e;
// slotToExpunge表示开始探测式清理过期数据的开始下标:默认从当前staleSlot开始。
int slotToExpunge = staleSlot;
// 以当前staleSlot开始 向前迭代查找,找有没有过期的数据。for循环一直到碰到null结束。
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len)){
// 条件成立:说明向前找到了过期数据,更新 探测清理过期数据的开始下标为 i
if (e.get() == null){
slotToExpunge = i;
}
}
// 以当前staleSlot向后去查找,直到碰到null为止。
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
// 获取当前元素 key
ThreadLocal<?> k = e.get();
// 条件成立:说明是一个替换逻辑:
if (k == key) {
// 替换新数据
e.value = value;
// 交换位置的逻辑..
// 将table[staleSlot]这个过期数据 放到 当前循环到的 table[i] 这个位置。
tab[i] = tab[staleSlot];
// 将tab[staleSlot] 中保存为 当前entry。 这样的话,这个数据位置就被优化了..
tab[staleSlot] = e;
// 如果条件成立:
// 1.说明replaceStaleEntry 一开始时 的向前查找过期数据 并未找到过期的entry.
// 2.向后检查过程中也未发现过期数据..
if (slotToExpunge == staleSlot)
// 开始探测式清理过期数据的下标 修改为 当前循环的index。
slotToExpunge = i;
// cleanSomeSlots :启发式清理
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 条件1:k == null 成立,说明当前遍历的entry是一个过期数据..
// 条件2:slotToExpunge == staleSlot 成立,一开始时的向前查找过期数据并未找到过期的entry.
if (k == null && slotToExpunge == staleSlot)
// 因为向后查询过程中查找到一个过期数据了,更新slotToExpunge为当前位置。
// 前提条件是 前驱扫描时 未发现 过期数据..
slotToExpunge = i;
}
// 什么时候执行到这里呢?
// 向后查找过程中 并未发现 k == key 的entry,说明当前set操作 是一个添加逻辑..
// 直接将新数据添加到 table[staleSlot] 对应的slot中。
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 条件成立:除了当前staleSlot 以外 ,还发现其它的过期slot了.. 所以要开启清理数据的逻辑..
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
replaceStaleEntry执行流程图如下:
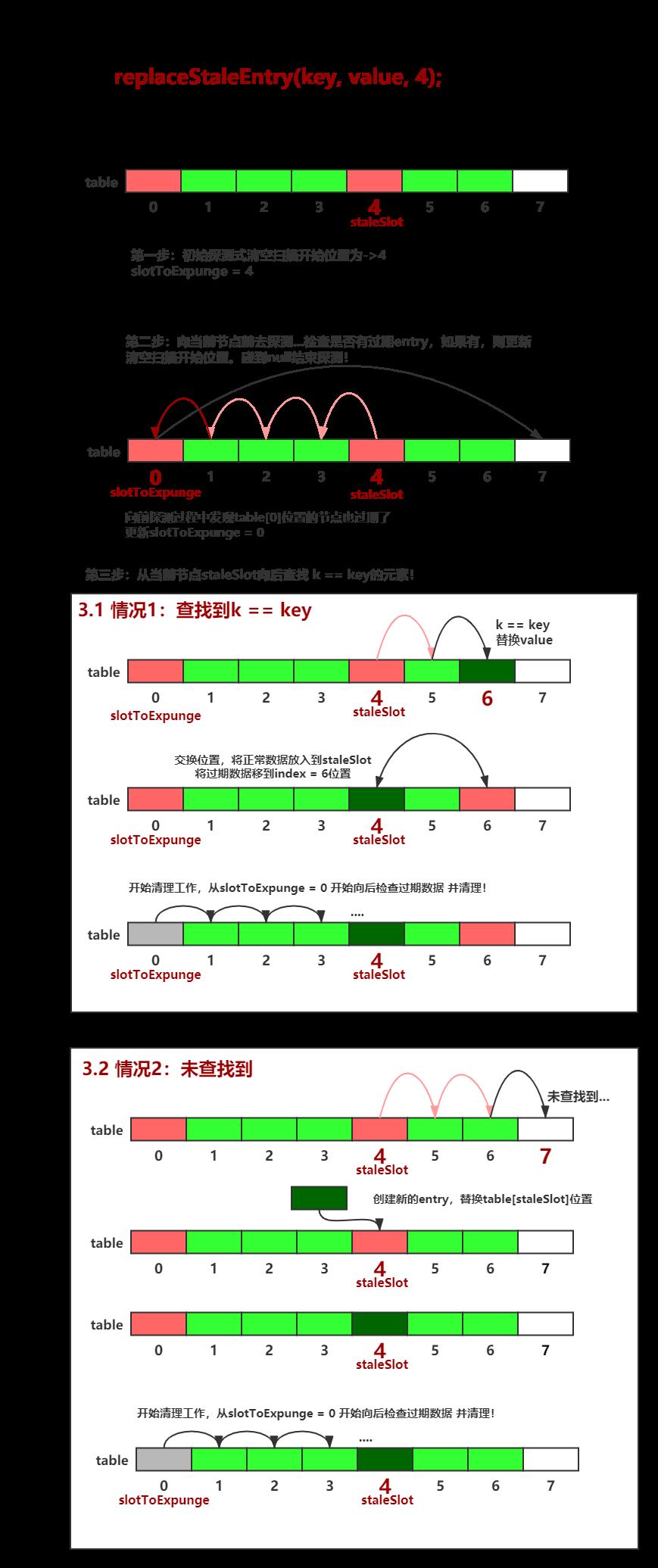
cleanSomeSlots方法
- 启发式清理工作的方法:
/**
* 启发式清理工作的方法:
* 参数 i:启发式清理工作开始位置
* 参数 n:一般传递的是 table.length ,这里n 也表示结束条件。
* @return true if any stale entries have been removed.
*/
private boolean cleanSomeSlots(int i, int n) {
// 表示启发式清理工作,是否清楚过过期数据
boolean removed = false;
// 获取当前map的散列表引用
Entry[] tab = table;
// 获取当前散列表数组长度
int len = tab.length;
do {
// 这里为什么不是从i就检查呢?
// 因为cleanSomeSlots(i = expungeStaleEntry(???), n) expungeStaleEntry(???)
// 返回值一定是null!
// 获取当前i的下一个下标
i = nextIndex(i, len);
// 获取table中当前下标为i的元素
Entry e = tab[i];
// 条件一:e != null 成立
// 条件二:e.get() == null 成立,说明当前slot中保存的entry 是一个过期的数据..
if (e != null && e.get() == null) {
// 重新更新n为 table数组长度
n = len;
// 表示清理过数据.
removed = true;
// 以当前过期的slot为开始节点 做一次 探测式清理工作
i = expungeStaleEntry(i);
}
// 假设table长度为16
// 16 >>> 1 ==> 8
// 8 >>> 1 ==> 4
// 4 >>> 1 ==> 2
// 2 >>> 1 ==> 1
// 1 >>> 1 ==> 0
} while ( (n >>>= 1) != 0);
return removed;
}
cleanSomeSlots启发式清理流程图:

rehash方法
- 扩容方法:
private void rehash() {
// 这个方法执行完后,当前散列表内的所有过期的数据,都会被干掉。
expungeStaleEntries();
// 条件成立:说明清理完 过期数据后,
// 当前散列表内的entry数量仍然达到了threshold * 3/4,则真正触发扩容!
if (size >= threshold - threshold / 4)
// 真正执行扩容的方法:
resize();
}
resize方法
- 真正执行扩容的方法:
private void resize() {
// 获取当前散列表
Entry[] oldTab = table;
// 获取当前散列表长度
int oldLen = oldTab.length;
// 计算出扩容后的表大小 oldLen * 2(旧容量的2倍)
int newLen = oldLen * 2;
// 创建一个新的散列表
Entry[] newTab = new Entry[newLen];
// 表示新table中的entry数量。
int count = 0;
// 遍历老表 迁移数据到新表:
for (int j = 0; j <以上是关于ThreadLocal源码分析_02 内核(ThreadLocalMap)的主要内容,如果未能解决你的问题,请参考以下文章