Elasticsearch:从写入原理谈写入优化
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:从写入原理谈写入优化相关的知识,希望对你有一定的参考价值。

【CSDN 编者按】在做数据同步的时候,由于数据大小的原因,会发现写入到ES的速度会很慢,那该怎么办呢,那就来优化吧~
作者 | 铭毅天下 责编 | 欧阳姝黎

线上实战问题
问题 1:想要请问一下,我这边需求是每分钟利用 sparksteaming 插入按天的索引 150 万条数据。一般情况下还好,索引 7 个分片,1 副本,但是偶尔会出现延迟很高的情况。比如:一般情况下 1 分钟插入 150 万能正常插入,可能突然就出现了需要 5 分钟才能插入成功,然后又正常了。很头疼。
请问这种情况我需要怎么去查看一下是否正常。我已经把副本设置成了 0,还把批量插入的参数从 5000 设置成 2 万。我节点是 12 个 16g 的,但是好像还是没有改观。
问题 2:由于使用了多个分词器的原因造成数据写入慢,请问有什么优化的方法吗?
问题 3:求问:现在日志 收集链路 kafka-logstash-es,压力测试 logstash输出 70M/s,而 Elasticsearch 索引写入一半不到。这边的性能损失可能是什么原因呢?需要怎么调优呢?
类似问题还有很多、很多......

问题分析
以上三个问题各有各自特点,但基本都是基于不同的数据源向 Elasticsearch 写入过程中遇到的问题。
可以简单归结为:Elasticsearch 写入问题或者写入优化问题。Elasticsearch 写入问题涉及写入流程、写入原理及优化策略。
本文针对如上几点展开讨论。

基于单文档/批量文档写入流程谈写入优化
单个文档写入对应 Index 请求,批量写入对应 Bulk 请求,Index 和 Bulk 是相同的处理逻辑,请求统一封装到 BulkRequest中。
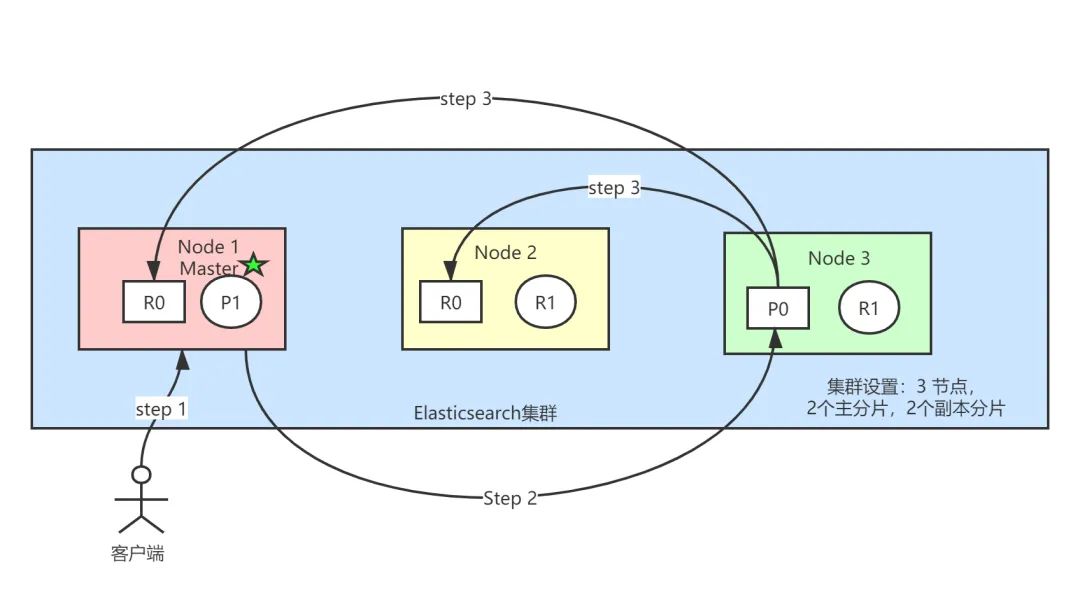
流程拆解如下:
第一:客户端向 Node 1 发送写数据请求。
注意,此时 Node1 便充当协调节点(cooridiniate)的角色。
第二:节点 Node1 使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
使用文档的 _id 确定文档所属分片的方法是:路由算法。
路由算法计算公式:
shard = hash(routing) % number_of_primary_shards
routing:文档 _id。
number_of_primary_shards: 主分片个数。
shard: 文档 _id 所属分片号。
第三:Node 3 在主分片上面执行写入操作。如果写入成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告写入成功,协调节点向客户端报告写入成功。
如上流程拆解后的注意点:
写操作必须在主分片执行成功后,才能复制到相关的副本分片。
主分片写入失败,则整个请求被认为是写失败。
如果有部分副本写失败(前提:主分片写入成功),则整个请求被认为是写成功。
如果设置了副本,数据会先写入主分片,主分片再同步到副本分片,同步操作会加重磁盘 IO,间接影响写入性能。
基于以上分析,既然主分片的写入起到写入成败的决定性作用。那么写入前将:副本分片写入前置为0,待写入完成后复原副本,是不是就能提升写入性能了呢?
是的!
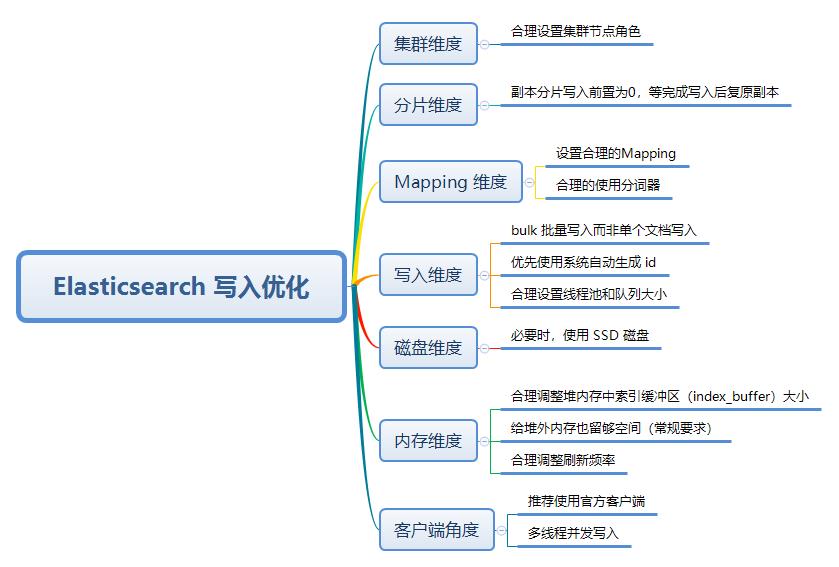
写入优化一:副本分片写入前置为0,等完成写入后复原副本
PUT test-0001
{
"settings": {
"number_of_replicas": 0
}
}
写入优化二:优先使用系统自动生成 id
文档的_id 的生成有两种方式,
第一:系统自动生成id。
第二:外部控制自增id。
但,如果使用外部 id,Elasticsearch 会先尝试读取原来文档的版本号,以判断是否需要更新。
也就是说,使用外部控制 id 比系统自动生成id要多一次读取磁盘操作。
所以,非特殊场景推荐使用系统自动生成的 id。

基于 Elasticsearch 写入原理谈写入优化
Elasticsearch 中的 1 个索引由一个或多个分片组成,每个分片包含多个segment(段),每一个段都是一个倒排索引。如下图所示:
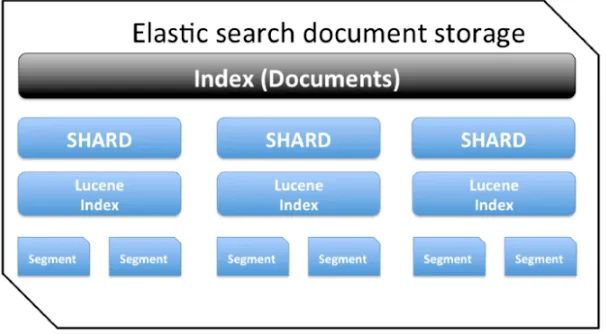
在 lucene 中,为了实现高索引速度,使用了 segment 分段架构存储。一批写入数据保存在一个段中,其中每个段最终落地为磁盘中的单个文件。
将文档插入 Elasticsearch 时,它们会被写入缓冲区中,然后在刷新时定期从该缓冲区刷新到段中。刷新频率由 refresh_interval 参数控制,默认每1秒刷新一次。
也就是说,新插入的文档在刷新到段(内存中)之前,是不能被搜索到的。如下图所示:
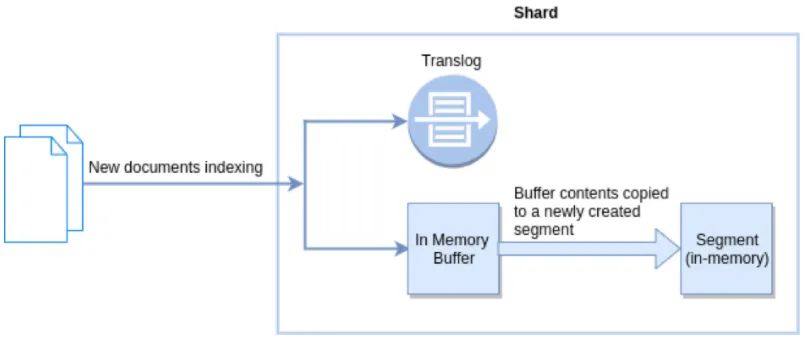
刷新的本质是:写入数据由内存 buffer 写入到内存段中,以保证搜索可见。
来看个例子,加深对 refresh_inteval 的理解,注释部分就是解读。
PUT test_0001/_doc/1
{
"title":"just testing"
}
# 默认一秒的刷新频率,秒级可见(用户无感知)
GET test_0001/_search
如下设置后,写入后 60s 后才可见。
DELETE test_0001
# 设置了60s的刷新频率
PUT test_0001
{
"settings": {
"index":{
"refresh_interval":"60s"
}
}
}
PUT test_0001/_doc/1
{
"title":"just testing"
}
# 60s后才可以被搜索到
GET test_0001/_search
关于是否需要实时刷新:
如果新插入的数据需要近乎实时的搜索功能,则需要频繁刷新。
如果对最新数据的检索响应没有实时性要求,则应增加刷新间隔,以提高数据写入的效率。
所以,自然我们想到的优化是:调整刷新频率。
写入优化三:合理调整刷新频率
调整方法如下:
方法1:写入前刷新频率设置为 -1,写入后设置为业务实际需要值(比如:30s)。
PUT test-008
{
"settings": {
"refresh_interval": -1
}
}
方法2:直接设置为业务实际需要值(比如:30s)
PUT test-008
{
"settings": {
"refresh_interval": "30s"
}
}
写入优化四:合理调整堆内存中索引缓冲区(index_buffer)大小
堆内存中 index_buffer 用于存储新索引的文档。
填满后,缓冲区中的文档将最终写入磁盘上的某个段。
index_buffer_size 默认值如下所示,为堆内存的 10%。
indices.memory.index_buffer_size: 10%
例如,如果给 JVM 31GB的内存,它将为索引缓冲区提供 3.1 GB的内存,一般情况下足以容纳大量数据的写入操作。
但,如果着实数据量非常大,建议调大该默认值。比如:调整为堆内存的 20%。
调整建议:必须在集群中的每个数据节点上进行配置。
缓存区越大,意味着能缓存数据量越大,相同时间段内,写盘频次低、磁盘 IO 小,间接提升写入性能。
写入优化五:给堆外内存也留够空间(常规要求)
这其实算不上写入优化建议,而是通用集群配置的常规配置。
内存分配设置堆内存比例官方建议:机器内存大小一半,但不超过 32 GB。
一般设置建议:
如果内存大小 >= 64 GB,堆内存设置:31 GB。
如果内存大小 < 64 GB,堆内存设置:内存大小一半。
堆内存之外的内存留给:Lucene 使用。
推荐阅读:干货 | 吃透Elasticsearch 堆内存
写入优化六:bulk 批量写入而非单个文档写入
批量写入自然会比单个写入性能要好(批量写入意味着相同时间产生的段会大,段的总个数自然会少),但批量值的设置一般需要慎重,不要盲目一下搞的很大。
一般建议:递增步长测试,直到达到资源使用上限。
比如:第一次批量值设置:100,第二次:200,第三次:400,以此类推......
批量值 bulk 已经 ok 了,但集群尚有富余资源,资源利用并没有饱和怎么办?
上多线程,通过并发提升写入性能。
写入优化七:多线程并发写入
这点,在 logstash 同步数据到 Elasticsearch,基于spark、kafka、Flink 批量写入 Elasticsearch时,经常会出现:Bulk Rejections 的报错。
当批量请求到达集群中的某个节点时,整个请求将被放入批量队列中,并由批量线程池中的线程进行处理。批量线程池处理来自队列的请求,并将文档转发到副本分片,作为此处理的一部分。子请求完成后,将响应发送到协调节点。
Elasticsearch 具有有限大小的请求队列的原因是:为了防止集群过载,从而增加了稳定性和可靠性。
如果没有任何限制,客户端可以很容易地通过恶意攻击行为将整个集群搞宕机。
这里就引申出下面的优化点。
写入优化八:合理设置线程池和队列大小
关于线程池和队列,参考:Elasticsearch 线程池和队列问题,请先看这一篇。
核心建议就是:结合 CPU 核数和 esrally 的测试结果谨慎的调整 write 线程池和队列大小。
为什么要谨慎设置?
针对批量写入拒绝(reject)的场景,官方建议:
增加队列的大小不太可能改善集群的索引性能或吞吐量。相反,这只会使集群在内存中排队更多数据,这很可能导致批量请求需要更长的时间才能完成。
队列中的批量请求越多,将消耗更多的宝贵堆空间。如果堆上的压力太大,则可能导致许多其他性能问题,甚至导致集群不稳定。
推荐阅读:
https://www.elastic.co/cn/blog/why-am-i-seeing-bulk-rejections-in-my-elasticsearch-cluster

其他写入优化建议
写入优化九:设置合理的 Mapping
实战业务场景中不推荐使用默认 dynamic Mapping,一定要手动设置 Mapping。
举例1:默认字符串类型是:text 和 keyword 的组合类型,就不见得适用所有业务场景。要结合自己业务场景设置,正文 cont 文本内容一般不需要设置 keyword 类型(因为:不需要排序和聚合操作)。
举例2:互联网采集数据存储场景,正文需要全文检索,但包含 html 样式的文本一般留给前端展示用,不需要索引。这时候 Mapping 设置阶段要果断将 index 设置为 false。
写入优化十:合理的使用分词器
分词器决定分词的粒度,常见的中文分词 IK 可细分为:
粗粒度分词:ik_smart。
细粒度分词:ik_max_word。
从存储角度基于 ik_max_word 分词的索引会比基于 ik_smart 分词的索引占据空间大。
而更细粒度自定义分词 ngram 会占用大量资源,并且可能减慢索引速度并显着增加索引大小。
所以要结合检索指标(召回率和精准率)、结合写入场景斟酌选型。
写入优化十一:必要时,使用 SSD 磁盘
SSD 很贵,但很香。
尤其针对写入密集型场景,如果其他优化点都考虑了,这可能是你最后一根“救命稻草“。
写入优化十二:合理设置集群节点角色
这也是经常被问到的问题,集群规模小的时候,一般节点会混合多种角色,如:主节点 + 数据节点、数据节点 + 协调节点混合部署。
但,集群规模大了之后,硬件资源相对丰富后,强烈建立:独立主节点、独立协调节点。
让各个角色的节点各尽其责,对写入、检索性能都会有帮助。
写入优化十三:推荐使用官方客户端
推荐使用官方 Elasticsearch API,因为官方在连接池和保持连接状态方面有优化。
高版本 JAVA API 推荐:官方的High-level-Rest API。
其他写入优化
待补充......

写入过程中做好监控
如下是 kibana 监控截图,其中:index Rate 就是写入速率。

index rate: 每秒写入的文档数。
search rate:每秒的查询次数(分片级别,非请求级别),也就意味着一次查询请求命中的分片数越多,值越大。

小结
Elasticsearch 写入优化没有普适的最优优化建议,只有适合自己业务场景的反复试验、调优,形成属于自己业务场景的最佳实践。
你的业务场景做过哪些写入优化?欢迎留言讨论交流。
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/tune-for-indexing-speed.html
《Elasticsearch源码解析与优化实战》
https://wx.zsxq.com/dweb2/index/search/%E5%88%86%E7%89%87%E6%95%B0/alltopics
https://t.zsxq.com/v7qNNRz
https://opster.com/blogs/improve-elasticsearch-indexing-rate/
国外博客
☞拼多多否认对极兔快递“政策倾斜”;86版西游记“红孩儿”成中科院博士;AirTag遭破解 | 极客头条☞从头开发一个 RPC 是种怎样的体验?☞2021微信大数据挑战赛正式启动报名!以上是关于Elasticsearch:从写入原理谈写入优化的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 写入优化,从 3000 到 8000/s,让你的 ES 飞起来。。。
Elasticsearch 写入优化,从 3000 到 8000/s,让你的 ES 飞起来!
Elasticsearch 写入优化记录,从3000到8000/s