运行 JavaPythonGo 等 25 种代码后,发现性能最强的竟然是它!
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运行 JavaPythonGo 等 25 种代码后,发现性能最强的竟然是它!相关的知识,希望对你有一定的参考价值。

本文通过一道程序面试题,使用不同的编程语言来实现,检验每种语言的简单版本与优化后版本的运行速度分别是多少,横向对比 Python、Go、C++、C、Rust 等编程语言的性能,
作者 | Ben Hoyt 译者 | 弯月
出处 | https://benhoyt.com/writings/count-words/
出品 | CSDN(ID:CSDNnews)
最近几年,我经常担任编程面试的面试官,而我经常给应聘者出的一道题目是:
编写一个程序,计算标准输入中每个单词的出现频率,然后按照频率从高到低输出频率。例如,给定下列输入:
The foo the foo the
defenestration the
程序应当输出:
the 4
foo 2
defenestration 1
我认为这是一个非常好的面试题,它比 FizzBuzz 要难一点,但并不像“在白板上翻转二叉树”那般折磨人。而且在真实世界中,程序员也可能会编写类似的程序,它还能考察程序员对于文件 I/O、哈希表(映射)以及相应语言的排序函数的的掌握情况。排序部分有一点难度,因为大多数语言的哈希表是无序的,即使有序,也是按照键的顺序或插入顺序,而不是按照值的顺序排列。
在应聘者给出基本的解决方案后,我还会进一步追问:首字母大写的情况怎么处理?标点怎么处理?出现频率相同的单词怎样排序?性能瓶颈可能出现在哪里?算法时间复杂度是多少?内存使用率是多少?处理 1GB 的文件大概需要多长时间?对于 1TB 的文件是否能正常运行?等等。或者你可以从“软件工程”的方面来追问,询问诸如错误处理、可测试性、将其转换成命令行工具等问题。
最基本的解决方案就是逐行读取文件,转换成小写,将每一行分割成单词,然后利用哈希表统计频率。统计完成后,将哈希表转换成单词和个数组成的列表,按照个数排序(从大到小),然后输出。
对于 Python,最简单的方案就是使用 dict,如下所示(省略了 import 等):
counts = {}
for line in sys.stdin:
words = line.lower().split()
for word in words:
counts[word] = counts.get(word, 0) + 1
pairs = sorted(counts.items(), key=lambda kv: kv[1], reverse=True)
for word, count in pairs:
print(word, count)
如果应聘者非常熟悉 Python,他们可能会使用 collections.defaultdict 甚至 collections.Counter(后面的代码就用到了 Counter)。遇到这种情况,我就会询问这个类的工作原理是什么,或者要求他们使用普通的字典来解决。
巧合的是,几十年前两名计算机科学家曾经就这个问题进行了一场决斗。
1986 年,Jon Bentley 要求 Donald Knuth 编写一段程序解决该问题,演示“文学编程”,然后 Knuth 写了一篇 10 页长的论文来解决这个问题(https://www.cs.tufts.edu/~nr/cs257/archive/don-knuth/pearls-2.pdf)。然后 Doug McIlroy(Unix 流水线的发明者)仅用了一行 Unix shell 程序,利用 tr、sort 和 uniq 解决了这个问题。
这个问题我也研究了一段时间,我想看看用各种语言写出来会是什么样子,以及每种语言的简单版本与优化后版本的运行速度分别是多少。
注意:本文包含大量的代码,源代码 GitHub 地址(https://github.com/benhoyt/countwords)。或者你也可以跳至性能评测结果。

问题描述和约束条件
每个程序必须读取标准输入,然后按照频率从高到低的顺序,输出由空格分隔的单词的出现频率。为了简单一致起见,下面是我附加的一些约束条件:
-
大小写:程序必须统一将单词转换成小写,也就是说 “The the THE” 在输出中应当显示为 “the 3”。
-
单词:任何由空白分隔的部分都算单词,忽略标点符号。这样做的确会降低程序的可用性,但我不想把这个问题变成一个分词问题。
-
ASCII:在空白处理和大小写操作方面,可以仅考虑 ASCII 字符。绝大多数优化版本都会使用这个条件。
-
排序:如果两个单词的频率一样,那么它们在输出中的顺序无关紧要。我通过一个规范化脚本来检查输出结果的正确性。
-
多线程:程序应当在单台机器的单个线程上运行(尽管面试时我经常会问多线程的问题)。
-
内存:不要将整个文件读入内存。逐行缓冲是允许的,也可以按块读入,最大缓冲为 64KB。但是,将整个单词计数的哈希表放到内存中是允许的(我们假设输入是真实的语言,而不是完全由随机字符组成的单词)。
-
文本:假设输入文件为文本文件,每一行的长度很合理,每行的长度小于缓冲大小。
-
安全性:即使是优化的版本,也尽量不要使用不安全的语言特性,不要使用汇编。
-
哈希表:不要自己实现哈希表(除了优化的 C语言版本之外)。
-
标准库:仅使用语言的标准库函数。
测试输入文件为重复了十次的詹姆士王译本的圣经。源文件可以从 Gutenberg.org 获得,但将其中的智能双引号替换成了 ASCII 的双引号字符,并使用 cat 重复了十次,最终获得了一个 43MB 大小的输入文件。
下面开始写代码!代码的顺序为我编写的先后顺序。

Python
Python 的简单版使用了 collections.Counter。Python 的 collections 库非常好用。这可以说是最简单的一个实现:
simple.py
counts = collections.Counter()
for line in sys.stdin:
words = line.lower().split()
counts.update(words)
for word, count in counts.most_common():
print(word, count)
这个版本能处理 Unicode,在实际工作中我多半会这样写。实际上这个解决方案效率非常高,因为所有底层的东西都是由 C 语言完成的,包括读取文件、转换成小写、按照空白分割、更新计数器,以及 Counter.most_common 实现的排序。
但是我们来试着优化一下!Python 自带了性能评测模块,名为 cProfile。使用非常简单,只需用 python3 -m cProfile 运行程序即可。我注释掉了最后的 print 语句,避免输出干扰程序的性能。下面是输出结果(添加了 -s tottime 选项按照每个函数的总执行时间排序):
$ python3 -m cProfile -s tottime simple.py <kjvbible_x10.txt
6997799 function calls (6997787 primitive calls) in 3.872 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
998170 1.361 0.000 1.361 0.000 {built-in method _collections._count_elements}
1 0.911 0.911 3.872 3.872 simple.py:1(<module>)
998170 0.415 0.000 0.415 0.000 {method 'split' of 'str' objects}
998171 0.405 0.000 2.388 0.000 __init__.py:608(update)
998170 0.270 0.000 0.622 0.000 {built-in method builtins.isinstance}
998170 0.182 0.000 0.351 0.000 abc.py:96(__instancecheck__)
998170 0.170 0.000 0.170 0.000 {built-in method _abc._abc_instancecheck}
998170 0.134 0.000 0.134 0.000 {method 'lower' of 'str' objects}
5290 0.009 0.000 0.018 0.000 codecs.py:319(decode)
5290 0.009 0.000 0.009 0.000 {built-in method _codecs.utf_8_decode}
1 0.007 0.007 0.007 0.007 {built-in method builtins.sorted}
7/1 0.000 0.000 0.000 0.000 {built-in method _abc._abc_subclasscheck}
1 0.000 0.000 0.007 0.007 __init__.py:559(most_common)
1 0.000 0.000 0.000 0.000 __init__.py:540(__init__)
1 0.000 0.000 3.872 3.872 {built-in method builtins.exec}
7/1 0.000 0.000 0.000 0.000 abc.py:100(__subclasscheck__)
7 0.000 0.000 0.000 0.000 _collections_abc.py:392(__subclasshook__)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
可以看出:
-
998,170 是输入的总行数,因为我们逐行读入,因此 Python 循环和函数调用都执行了这么多次。
-
大部分时间花在了 simple.py 本身上,说明 Python 字节码的执行(相对来说)非常慢。主循环完全是用 Python 写的,也执行了 998,170 次。
-
str.split 相对较慢,可能是因为它需要分配内存并复制很多字符串。
-
Counter.update 调用了 isinstance,加起来也花了许多时间。我考虑过直接调用 C 函数 _count_elements,但这属于实现细节,我认为应当算作“不安全”的操作。
我们能做的主要就是减少 Python 主循环的执行次数,从而减少调用那些函数的次数。我们以 64KB 的块为单位来读入:
optimized.py
counts = collections.Counter()
remaining = ''
while True:
chunk = remaining + sys.stdin.read(64*1024)
if not chunk:
break
last_lf = chunk.rfind('\\n') # process to last LF character
if last_lf == -1:
remaining = ''
else:
remaining = chunk[last_lf+1:]
chunk = chunk[:last_lf]
counts.update(chunk.lower().split())
for word, count in counts.most_common():
print(word, count)
之前的版本主循环每次处理 42 个字符(平均行长度),而这段程序每次处理 65536 个字符(去掉末尾不完整的行)。读取和处理的字节数是相同的,但现在绝大多数处理都在C语言中进行,而不是在 Python 循环中进行。许多优化方案都采取了这种方式,即一次性处理大量数据。
性能评测结果看起来好多了。_count_elements和str.split 函数依然花费了最长的时间,但与之前的 998170 次相比,它们现在被调用了 662 次(因为每次大概处理 64KB 数据,而不是先前的 42 字节):
$ python3 -m cProfile -s tottime optimized.py <kjvbible_x10.txt
7980 function calls (7968 primitive calls) in 1.280 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
662 0.870 0.001 0.870 0.001 {built-in method _collections._count_elements}
662 0.278 0.000 0.278 0.000 {method 'split' of 'str' objects}
1 0.080 0.080 1.280 1.280 optimized.py:1(<module>)
662 0.028 0.000 0.028 0.000 {method 'lower' of 'str' objects}
663 0.010 0.000 0.016 0.000 {method 'read' of '_io.TextIOWrapper' objects}
1 0.007 0.007 0.007 0.007 {built-in method builtins.sorted}
664 0.004 0.000 0.004 0.000 {built-in method _codecs.utf_8_decode}
663 0.001 0.000 0.872 0.001 __init__.py:608(update)
664 0.001 0.000 0.005 0.000 codecs.py:319(decode)
662 0.001 0.000 0.001 0.000 {built-in method builtins.isinstance}
662 0.000 0.000 0.001 0.000 {built-in method _abc._abc_instancecheck}
662 0.000 0.000 0.000 0.000 {method 'rfind' of 'str' objects}
664 0.000 0.000 0.000 0.000 codecs.py:331(getstate)
662 0.000 0.000 0.001 0.000 abc.py:96(__instancecheck__)
7/1 0.000 0.000 0.000 0.000 {built-in method _abc._abc_subclasscheck}
1 0.000 0.000 0.007 0.007 __init__.py:559(most_common)
1 0.000 0.000 0.000 0.000 __init__.py:540(__init__)
7/1 0.000 0.000 0.000 0.000 abc.py:100(__subclasscheck__)
1 0.000 0.000 1.280 1.280 {built-in method builtins.exec}
7 0.000 0.000 0.000 0.000 _collections_abc.py:392(__subclasshook__)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
我还发现,在 Python 程序中,读取和处理 bytes 和 str 的性能并没有显著区别(utf_8_decode 在上面的列表中位于非常靠下的位置)。此外,只要缓冲区大小超过 2KB,速度就不会比 64KB 缓冲区慢。我注意到许多系统的默认缓冲区大小是 4KB,可能就是由于这个原因。
我尝试了许多其他方法来提高性能,但这是我用标准Python能达到的最好结果。(我尝试用 PyPy 优化编译器运行,但由于某种原因,它非常慢。)Python不适合在字节层面进行优化(反而会导致 10 倍至 100 倍的速度下降),任何字符处理都应该在 C 层面进行。

Go
简单的 Go 版本可以使用 buffio.Scanner,并使用 ScanWords 来分割单词。Go 没有 Python 的 collections.Counter,但使用 map[string] 进行计数也非常简单,然后通过单词和计数组成的切片进行排序操作:
simple.go
func main() {
scanner := bufio.NewScanner(os.Stdin)
scanner.Split(bufio.ScanWords)
counts := make(map[string]int)
for scanner.Scan() {
word := strings.ToLower(scanner.Text())
counts[word]++
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
var ordered []Count
for word, count := range counts {
ordered = append(ordered, Count{word, count})
}
sort.Slice(ordered, func(i, j int) bool {
return ordered[i].Count > ordered[j].Count
})
for _, count := range ordered {
fmt.Println(string(count.Word), count.Count)
}
}
type Count struct {
Word string
Count int
}
Go 的简单版本比 Python 的简单版本要快很多,但只比优化过的 Python 版本快一点点(而且代码行数几乎是两倍,因为Go 有很多样板代码,还要考虑很多底层处理)。
Go 的性能评测工具需要在程序开始处添加几行代码(import "runtime/pprof" 略过):
f, err := os.Create("cpuprofile")
if err != nil {
fmt.Fprintf(os.Stderr, "could not create CPU profile: %v\\n", err)
os.Exit(1)
}
if err := pprof.StartCPUProfile(f); err != nil {
fmt.Fprintf(os.Stderr, "could not start CPU profile: %v\\n", err)
os.Exit(1)
}
defer pprof.StopCPUProfile()
运行程序后就可以通过下述命令查看 CPU 的使用情况:
$ go tool pprof -http=:7777 cpuprofile
Serving web UI on http://localhost:7777
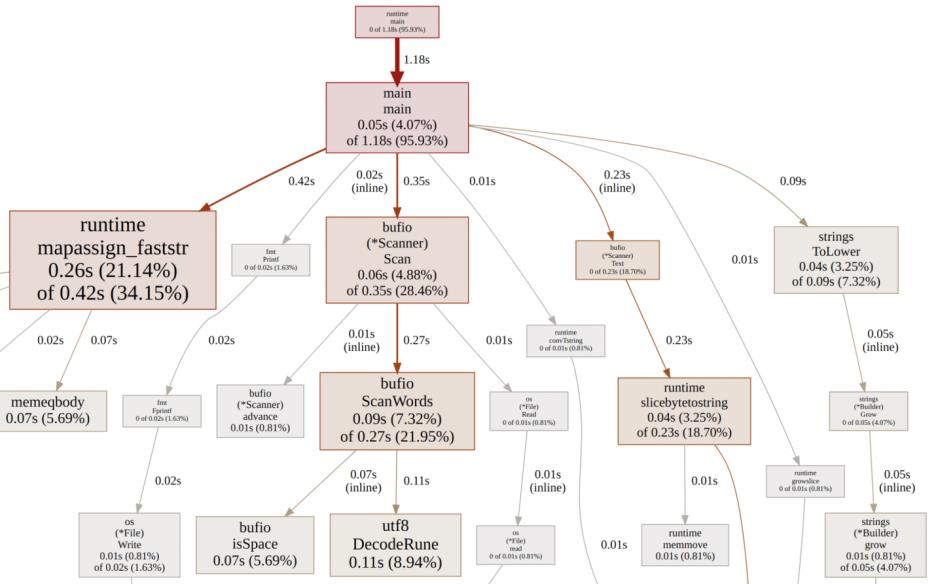
结果很有意思,尽管并不是完全出乎意料,处理每个单词的循环占据了几乎所有时间。还有相当多的时间花在了扫描器上,而向map中插入字符串所需的内存分配也花了不少时间。我们来优化一下这几个方面。
为了改善扫描过程,我们在读取文件的同时进行扫描和大小写转换。为了减少内存分配,我们采用map[string]*int 来替代 map[string]int,这样每个单词只需要分配一次内存,而不是在每次增量的时候都要分配。
我尝试了几次后才得到了这个结果。中间的一个步骤是依然使用 bufio.Scanner,但采用自定义的分割函数 scanWordsASCII。但是,尽管的确快了一些,但去掉 bufio.Scanner 也并不难。我做的另一个尝试是使用自定义的哈希表,但我认为这已经超出了本问题的范围,而且也并不比map[string]*int 快多少。
optimized.go
func main() {
var word []byte
buf := make([]byte, 64*1024)
counts := make(map[string]*int)
for {
// Read input in 64KB blocks till EOF.
n, err := os.Stdin.Read(buf)
if err != nil && err != io.EOF {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
if n == 0 {
break
}
// Count words in the buffer.
for i := 0; i < n; i++ {
c := buf[i]
// Found a whitespace char, count last word.
if c <= ' ' {
if len(word) > 0 {
increment(counts, word)
word = word[:0] // reset word buffer
}
continue
}
// Convert to ASCII lowercase as we go.
if c >= 'A' && c <= 'Z' {
c = c + ('a' - 'A')
}
// Add non-space char to word buffer.
word = append(word, c)
}
}
// Count last word, if any.
if len(word) > 0 {
increment(counts, word)
}
// Convert to slice of Count, sort by count descending, print.
ordered := make([]Count, 0, len(counts))
for word, count := range counts {
ordered = append(ordered, Count{word, *count})
}
sort.Slice(ordered, func(i, j int) bool {
return ordered[i].Count > ordered[j].Count
})
for _, count := range ordered {
fmt.Println(count.Word, count.Count)
}
}
func increment(counts map[string]*int, word []byte) {
if p, ok := counts[string(word)]; ok {
// Word already in map, increment existing int via pointer.
*p++
return
}
// Word not in map, insert new int.
n := 1
counts[string(word)] = &n
}
现在评测结果非常扁平,几乎所有时间都花在了主循环或 map 访问中:
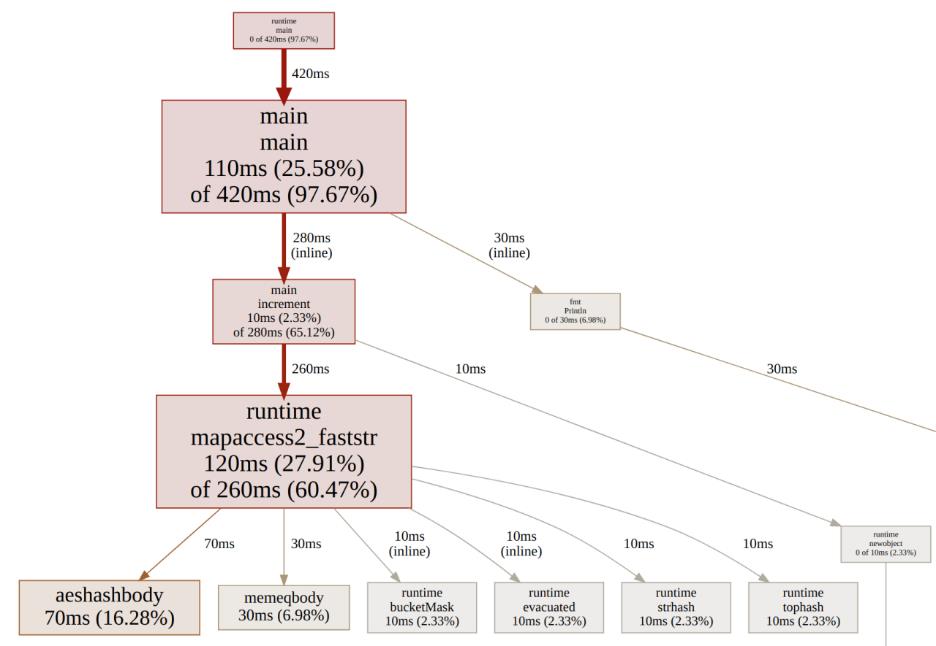
Go 能提供更接近底层的控制(而且你可以更加深入,比如将I/O映射到内存,自定义哈希表等)。但是,程序员的时间也非常宝贵,所以需要取舍。在实际工作中,我会依然使用 bufio.scanner 和 ScanWords、bytes.ToLower,以及优化方案中的 map[string]*int。

C++
自从我最后一次使用 C++ 以来,它有了很多的改进:C++11 添加了许多优秀的功能,然后 C++14、17和20又添加了更多功能。现在的 C++ 比旧时的 C++ 更加复杂了,尽管错误信息依然很乱。下面是我写的一个简单版本:
simple.cpp
int main() {
std::string word;
std::unordered_map<std::string, int> counts;
while (std::cin >> word) {
std::transform(word.begin(), word.end(), word.begin(),
[](unsigned char c){ return std::tolower(c); });
++counts[word];
}
if (std::cin.bad()) {
std::cerr << "error reading stdin\\n";
return 1;
}
std::vector<std::pair<std::string, int>> ordered(counts.begin(),
counts.end());
std::sort(ordered.begin(), ordered.end(),
[](auto const& a, auto const& b) { return a.second>b.second; });
for (auto const& count : ordered) {
std::cout << count.first << " " << count.second << "\\n";
}
}
在进行优化时,我做的第一件事情就是启用了编译优化(g++ -O2)。我喜欢 Go 的原因之一就是你不需要操心这些,因为优化是永远启用的。
我注意到 I/O 比较慢。有一行魔法代码,只要加到程序开头,禁止在每次 I/O 操作之后与 C 标准库的函数进行同步,就能提高性能。这行代码几乎可以将速度提高到两倍:
ios::sync_with_stdio(false);
GCC可以使用gprof生成性能评测报告。下面是部分结果:
index % time self children called name
13 frame_dummy [1]
[1] 100.0 0.01 0.00 0+13 frame_dummy [1]
13 frame_dummy [1]
-----------------------------------------------
0.00 0.00 32187/32187 std::vector<std::pair\\
<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocat\\
or<char> >, int>, std::allocator<std::pair<std::__cxx11::basic_string<\\
char, std::char_traits<char>, std::allocator<char> >, int> > >::vector\\
<std::__detail::_Node_iterator<std::pair<std::__cxx11::basic_string<ch\\
ar, std::char_traits<char>, std::allocator<char> > const, int>, false,\\
true>, void>(std::__detail::_Node_iterator<std::pair<std::__cxx11::ba\\
sic_string<char, std::char_traits<char>, std::allocator<char> > const,\\
int>, false, true>, std::__detail::_Node_iterator<std::pair<std::__cx\\
x11::basic_string<char, std::char_traits<char>, std::allocator<char> >\\
const, int>, false, true>, std::allocator<std::pair<std::__cxx11::bas\\
ic_string<char, std::char_traits<char>, std::allocator<char> >, int> >\\
const&) [11]
[8] 0.0 0.00 0.00 32187 void std::__cxx11::basic_\\
string<char, std::char_traits<char>, std::allocator<char> >::_M_constr\\
uct<char*>(char*, char*, std::forward_iterator_tag) [8]
-----------------------------------------------
0.00 0.00 1/1 __libc_csu_init [17]
[9] 0.0 0.00 0.00 1 _GLOBAL__sub_I_main [9]
...
这里出现了 C++ 模板。可能我比较古板,与 std::basic_istream<char, std::char_traits<char> >& std::operator>><char, std::char_traits<char>, std::allocator<char> >(std::basic_istream<char, std::char_traits<char> >&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&)相比,我更喜欢 malloc 和 scanf。
我很不喜欢分析这些结果,所以我直接去编写优化后的 C 版本了。当然 C++ 版本依然有许多可以改进的地方,但我认为最后肯定会越来越底层,越来越像C(至少以我相当有限的现代 C++ 知识而言会这样),所以你可以直接看下面的 C 版本那就好了。
在 C 版本中我使用了 Valgrind 的评测工具(Callgrind),参见下面一节的注释。其实我还可以使用 Linux 的 perf 工具(具体来说是 perf record 和 perf report 命令),它的结果要比 gprof 好一些。

C
C 是一门永不过时的语言:快速、不安全、简单。我依然很喜欢 C,因为它不像 C++ 那样难懂,而且我可以随便深入底层。C 语言非常通用(Linux 内核、Redis、PostgreSQL、SQLite 等许多许多库都是用 C 写的),而且永远不会消亡。所以我们来编写一个 C 语言版本。
不幸的是,C 的标准库并没有哈希表数据结构。但是我们还有 libc,它提供了 hcreate 和 hsearch 哈希表函数,所以这里我们破例允许使用非标准库的 libc 函数。在优化版本中我们会编写自己的哈希表。
hcreate 有一个不方便的地方是,你必须提前指定哈希表的最大尺寸。我知道唯一的单词数量不会超过 30000,所以这里我们暂时选择 60000。
simple.c
#define MAX_UNIQUES 60000
typedef struct {
char* word;
int count;
} count;
// Comparison function for qsort() ordering by count descending.
int cmp_count(const void* p1, const void* p2) {
int c1 = ((count*)p1)->count;
int c2 = ((count*)p2)->count;
if (c1 == c2) return 0;
if (c1 < c2) return 1;
return -1;
}
int main() {
// The hcreate hash table doesn't provide a way to iterate, so
// store the words in an array too (also used for sorting).
count* words = calloc(MAX_UNIQUES, sizeof(count));
int num_words = 0;
// Allocate hash table.
if (hcreate(MAX_UNIQUES) == 0) {
fprintf(stderr, "error creating hash table\\n");
return 1;
}
char word[101]; // 100-char word plus NUL byte
while (scanf("%100s", word) != EOF) {
// Convert word to lower case in place.
for (char* p = word; *p; p++) {
*p = tolower(*p);
}
// Search for word in hash table.
ENTRY item = {word, NULL};
ENTRY* found = hsearch(item, FIND);
if (found != NULL) {
// Word already in table, increment count.
int* pn = (int*)found->data;
(*pn)++;
} else {
// Word not in table, insert it with count 1.
item.key = strdup(word); // need to copy word
if (item.key == NULL) {
fprintf(stderr, "out of memory in strdup\\n");
return 1;
}
int* pn = malloc(sizeof(int));
if (pn == NULL) {
fprintf(stderr, "out of memory in malloc\\n");
return 1;
}
*pn = 1;
item.data = pn;
ENTRY* entered = hsearch(item, ENTER);
if (entered == NULL) {
fprintf(stderr, "table full, increase MAX_UNIQUES\\n");
return 1;
}
// And add to words list for iterating.
words[num_words].word = item.key;
num_words++;
}
}
// Iterate once to add counts to words list, then sort.
for (int i = 0; i < num_words; i++) {
ENTRY item = {words[i].word, NULL};
ENTRY* found = hsearch(item, FIND);
if (found == NULL) { // shouldn't happen
fprintf(stderr, "key not found: %s\\n", item.key);
return 1;
}
words[i].count = *(int*)found->data;
}
qsort(&words[0], num_words, sizeof(count), cmp_count);
// Iterate again to print output.
for (int i = 0; i < num_words; i++) {
printf("%s %d\\n", words[i].word, words[i].count);
}
return 0;
}
里面有相当一部分样板代码(大部分是内存分配和错误检查),但由于 C 非常底层,我认为这并不是问题。有难度的地方基本上都被隐藏起来了,例如 scanf会进行分词,hsearch 会进行哈希表操作。这段程序本身也非常快,而且非常小(在 Linux 上的可执行文件只有 17KB)。
我试着用 gprof 进行性能评测,但没有得到任何有用的结果(也许采样不够频繁?),所以我采用了 Valgrind 的评测工具 Callgrind。这是我第一次使用该工具,但看起来它非常强大。
在使用 gcc -g 编译后,运行下面的命令生成评测报告:
valgrind --tool=callgrind ./simple-c <kjvbible_x10.txt >/dev/null
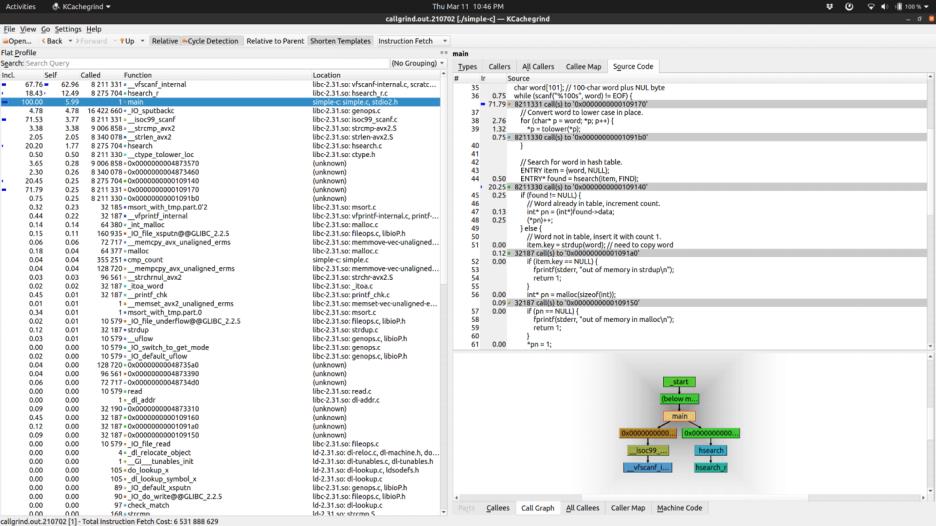
不出所料,scanf 是最慢的,接下来是 hsearch。所以我们接下来的优化会激进一些。我主要做了三件事情:
-
分块读取文件,像 Go 和 Python 一样,这样可以避免 scanf 的额外开销。
-
字节仅处理一次,或者尽量减少次数。在进行分词的同时进行大小写转换并计算哈希。
-
使用 FNV-1 哈希函数实现自己的哈希表。
optimized.c
#define BUF_SIZE 65536
#define HASH_LEN 65536 // must be a power of 2
#define FNV_OFFSET 14695981039346656037UL
#define FNV_PRIME 1099511628211UL
// Used both for hash table buckets and array for sorting.
typedef struct {
char* word;
int word_len;
int count;
} count;
// Comparison function for qsort() ordering by count descending.
int cmp_count(const void* p1, const void* p2) {
int c1 = ((count*)p1)->count;
int c2 = ((count*)p2)->count;
if (c1 == c2) return 0;
if (c1 < c2) return 1;
return -1;
}
count* table;
int num_unique = 0;
// Increment count of word in hash table (or insert new word).
void increment(char* word, int word_len, uint64_t hash) {
// Make 64-bit hash in range for items slice.
int index = (int)(hash & (uint64_t)(HASH_LEN-1));
// Look up key, using direct match and linear probing if not found.
while (1) {
if (table[index].word == NULL) {
// Found empty slot, add new item (copying key).
char* word_copy = malloc(word_len);
if (word_copy == NULL) {
fprintf(stderr, "out of memory\\n");
exit(1);
}
memmove(word_copy, word, word_len);
table[index].word = word_copy;
table[index].word_len = word_len;
table[index].count = 1;
num_unique++;
return;
}
if (table[index].word_len == word_len &&
memcmp(table[index].word, word, word_len) == 0) {
// Found matching slot, increment existing count.
table[index].count++;
return;
}
// Slot already holds another key, try next slot (linear probe).
index++;
if (index >= HASH_LEN) {
index = 0;
}
}
}
int main() {
// Allocate hash table buckets.
table = calloc(HASH_LEN, sizeof(count));
if (table == NULL) {
fprintf(stderr, "out of memory\\n");
return 1;
}
char buf[BUF_SIZE];
int offset = 0;
while (1) {
// Read file in chunks, processing one chunk at a time.
size_t num_read = fread(buf+offset, 1, BUF_SIZE-offset, stdin);
if (num_read+offset == 0) {
break;
}
// Find last space or linefeed in buf and process up to there.
int space;
for (space = offset+num_read-1; space>=0; space--) {
char c = buf[space];
if (c <= ' ') {
break;
}
}
int num_process = (space >= 0) ? space : (int)num_read+offset;
// Scan chars to process: tokenize, lowercase, and hash as we go.
int i = 0;
while (1) {
// Skip whitespace before word.
for (; i < num_process; i++) {
char c = buf[i];
if (c > ' ') {
break;
}
}
// Look for end of word, lowercase and hash as we go.
uint64_t hash = FNV_OFFSET;
int start = i;
for (; i < num_process; i++) {
char c = buf[i];
if (c <= ' ') {
break;
}
if (c >= 'A' && c <= 'Z') {
c += ('a' - 'A');
buf[i] = c;
}
hash *= FNV_PRIME;
hash ^= (uint64_t)c;
}
if (i <= start) {
break;
}
// Got a word, increment count in hash table.
increment(buf+start, i-start, hash);
}
// Move down remaining partial word.
if (space >= 0) {
offset = (offset+num_read-1) - space;
memmove(buf, buf+space+1, offset);
} else {
offset = 0;
}
}
count* ordered = calloc(num_unique, sizeof(count));
for (int i=0, i_unique=0; i<HASH_LEN; i++) {
if (table[i].word != NULL) {
ordered[i_unique++] = table[i];
}
}
qsort(ordered, num_unique, sizeof(count), cmp_count);
for (int i=0; i<num_unique; i++) {
printf("%.*s %d\\n",
ordered[i].word_len, ordered[i].word, ordered[i].count);
}
return 0;
}
上面大约是 150 行代码(包括空行和注释),绝对是最长的程序,但是还好!你可以看到,利用线性扫描编写自己的哈希表并没有使用太多代码。固定表大小并不好,但是动态改变表大小会增加许多工作量,而且固定表大小并不会显著减慢运行速度,所以我将动态表大小留给读者作为练习。
可执行文件依然是 17KB(这是我喜欢C的原因)。而且,不出所料,这个版本是最快的,比优化后的 Go 版本还要快一些,因为我们编写了自己的哈希表,而且处理的字节数更少。
但是,这段代码比 GNU grep 要慢。GNU grep 最初的作者 Mike Haertel 在2010年写过一篇非常著名的文章解释为什么GNU grep这么快(https://lists.freebsd.org/pipermail/freebsd-current/2010-August/019310.html)。但是有人认为,那篇文章有些过时了。Mike 的一般性建议非常好,但是今天 GNU grep 很快的原因并不是它使用 Boyer-Moore 算法跳过了一些字节,而是因为它使用了 glibc 中速度极快的向量化版本的 memchr。
我相信这 个C 版本还能进一步优化,比如 I/O 内存映射,避免一次处理一个字节,使用更好的数据结构进行计数等等。但暂时就这样吧!

AWK
AWK 实际上非常适合这个任务:读取每一行并按空格分割单词,对于它来说是小菜一碟。AWK 做不到的事情之一就是排序(如果不使用 Gawk 特有的排序功能的话),所以我用 AWK 的管道运算符将输出发送给 sort。下面是简单版的代码:
simple.awk
{
for (i = 1; i <= NF; i++)
counts[tolower($i)]++
}
END {
for (k in counts)
print k, counts[k] | "sort -nr -k2"
}
我不知道有什么简单的办法可以在底层进行性能评测(Gawk 有一个评测模式,但只是输出每一行执行了多少次)。我也不知道怎样用 AWK 或 Gawk 按块读取输入。
优化版本的一个小改动就是针对每一行调用 tolower,而不是针对每个单词。主循环变成这样:
optimized.awk
{
$0 = tolower($0)
for (i = 1; i <= NF; i++)
counts[$i]++
}
...
可以使用 gawk -b 命令运行该程序,这样可以将 Gawk 设置为“字节”模式,如此一来,它就会使用 ASCII,而不是 UTF-8。这个“优化”过的版本在 gawk -b下运行时,比直接使用 gawk 运行简单版本大约快 1.6 倍。
有意思的是,Gawk 的手册有一页正好介绍了这个词频统计问题,其示例使用 AWK 的 gsub 函数演示了如何去掉标点。

Forth
Forth 是我学习的第一门编程语言(它非常好,而且非常能拓展思维),所以我决定使用 Gforth 写一个 Forth 版本。我有很多年没使用过这个语言了。
simple.fs
200 constant max-line
create line max-line allot \\ Buffer for read-line
wordlist constant counts \\ Hash table of words to count
variable num-uniques 0 num-uniques !
\\ Convert character to lowercase.
: to-lower ( C -- c )
dup [char] A [ char Z 1+ ] literal within if
32 +
then ;
\\ Convert string to lowercase in place.
: lower-in-place ( addr u -- )
over + swap ?do
i c@ to-lower i c!
loop ;
\\ Count given word in hash table.
: count-word ( addr u -- )
2dup counts search-wordlist if
\\ Increment existing word
>body 1 swap +!
2drop
else
\\ Insert new word with count 1
2dup lower-in-place
['] create execute-parsing 1 ,
1 num-uniques +!
then ;
\\ Process text in the source buffer (one line).
: process-input ( -- )
begin
parse-name dup
while
count-word
repeat
2drop ;
\\ Less-than for words (true if count is *greater* for reverse sort).
: count< ( nt1 nt2 -- )
>r name>interpret >body @
r> name>interpret >body @
> ;
\\ ... Definition of "sort" elided ...
\\ Append word from wordlist to array at given offset.
: append-word ( addr offset nt -- addr offset+cell true )
>r 2dup + r> swap !
cell+ true ;
\\ Show "word count" line for each word, most frequent first.
: show-words ( -- )
num-uniques @ cells allocate throw
0 ['] append-word counts traverse-wordlist drop
dup num-uniques @ sort
num-uniques @ 0 ?do
dup i cells + @
dup name>string type space
name>interpret >body @ . cr
loop
drop ;
: main ( -- )
counts set-current \\ Define into counts wordlist
begin
line max-line stdin read-line throw
while
line swap ['] process-input execute-parsing
repeat
drop
show-words ;
Forth 被誉为“只能写不能读”的语言,这是有理由的。我曾经很喜欢没有局部变量的思想,但在实践中,这只会导致大量的 dup over swap rot。此外,即使是 Gforth(比标准的 Forth 强大很多)也不提供 to-lower 或 sort 等非常原始的工具,所以一切都要自己写。
幸运的是,哈希表可以通过 wordlist 实现。wordlist 的本来用途是定义新的 Forth 单词,但利用 Gforth 的 execute-parsing 扩展,把它当做哈希表使用也非常好。而 skip 和 scan 也很适合进行空白分词。
至于优化,似乎只需运行 gforth-fast 而不是 gforth,就能魔法般地提高运行速度,所以我的第一个优化版本就是这么简单(尽管在性能评测中两个版本都是使用 gforth-fast 运行的)。看起来 gforth-fast 能够避免调用的额外开销,但无法为错误生成友好的栈跟踪信息。
optimized.fs
\\ Start hash table at larger size
15 :noname to hashbits hashdouble ; execute
65536 constant buf-size
create buf buf-size allot \\ Buffer for read-file
wordlist constant counts \\ Hash table of words to count
variable num-uniques 0 num-uniques !
\\ Convert character to lowercase.
: to-lower ( C -- c )
dup [char] A [ char Z 1+ ] literal within if
32 +
then ;
\\ Convert string to lowercase in place.
: lower-in-place ( addr u -- )
over + swap ?do
i c@ to-lower i c!
loop ;
\\ Count given word in hash table.
: count-word ( c-addr u -- )
2dup counts find-name-in dup if
( name>interpret ) >body 1 swap +! 2drop
else
drop nextname create 1 ,
1 num-uniques +!
then ;
\\ Process text in the buffer.
: process-string ( -- )
begin
parse-name dup
while
count-word
repeat
2drop ;
\\ Less-than for words (true if count is *greater* for reverse sort).
: count< ( nt1 nt2 -- )
>r name>interpret >body @
r> name>interpret >body @
> ;
\\ ... Definition of "sort" elided ...
\\ Append word from wordlist to array at given offset.
: append-word ( addr offset nt -- addr offset+cell true )
dup name>string lower-in-place
>r 2dup + r> swap !
cell+ true ;
\\ Show "word count" line for each word, most frequent first.
: show-words ( -- )
num-uniques @ cells allocate throw
0 ['] append-word counts traverse-wordlist drop
dup num-uniques @ sort
num-uniques @ 0 ?do
dup i cells + @
dup name>string type space
name>interpret >body @ . cr
loop
drop ;
\\ Find last LF character in string, or return -1.
: find-eol ( addr u -- eol-offset|-1 )
begin
1- dup 0>=
while
2dup + c@ 10 = if
nip exit
then
repeat
nip ;
: main ( -- )
counts set-current \\ Define into counts wordlist
0 >r \\ offset after remaining bytes
begin
\\ Read from remaining bytes till end of buffer
buf r@ + buf-size r@ - stdin read-file throw dup
while
\\ Process till last LF
buf over r@ + find-eol
dup buf swap ['] process-string execute-parsing
\\ Move leftover bytes to start of buf, update offset
dup buf + -rot buf -rot - r@ +
r> drop dup >r move
repeat
drop r> drop
show-words ;
也许在非常小的嵌入式系统中我会考虑使用 Forth,但我不认为它有足够的函数库用于通用程序的编写。如果想使用更加现代化的类 Forth 语言,可以看看 Factor。

Rust
我经常使用 Andrew Gallant 的 ripgrep 代码搜索工具,我也知道他非常喜欢 Rust(及其优化),所以我在发表该文之前,询问了他是否愿意提供一个 Rust版本。
结果他不仅同意了,编写了简单版本和优化版本(类似于 Go 语言,速度也很相近),而且还提供了三个额外的版本(一些版本使用了外部依赖):
-
一个“额外奖励”版本:类似于简单版,但能够处理 Unicode 分词,而且还有一些其他的优点。Andrew 说,这个版本很适合作为通用版本。
-
一个自定义哈希表版本。基本上是我的 C 版本的移植,速度也几乎一样快。
-
一个 trie 版本,使用了 trie 数据结构替代哈希表。Andrew 认为这个数据结构能更快一些,但事实证明它慢了一点点。
他的简单版本没有使用任何外部依赖,与前面的 Go 和 C++ 的简单版本非常相似。
rust/simple/main.rs
fn main() {
// We don't return Result from main because it prints the debug
// representation of the error. The code below prints the "display"
// or human readable representation of the error.
if let Err(err) = try_main() {
eprintln!("{}", err);
std::process::exit(1);
}
}
fn try_main() -> Result<(), Box<dyn Error>> {
let stdin = io::stdin();
let stdin = io::BufReader::new(stdin.lock());
let mut counts: HashMap<String, u64> = HashMap::new();
for result in stdin.lines() {
let line = result?;
for word in line.split_whitespace() {
let canon = word.to_lowercase();
*counts.entry(canon).or_insert(0) += 1;
}
}
let mut ordered: Vec<(String, u64)> = counts.into_iter().collect();
ordered.sort_by(|&(_, cnt1), &(_, cnt2)| cnt1.cmp(&cnt2).reverse());
for (word, count) in ordered {
writeln!(io::stdout(), "{} {}", word, count)?;
}
Ok(())
}
下面是优化的版本。我引用了他的评论,代码只从 try_main 开始:
“这个版本基本上是优化过的 Go 版本低移植。它的缓冲区处理部分稍稍简单一些,我们不需要考虑最后一个换行字符的处理。(这样能节省一些工作量,但只能在每个 64KB 处理后节省,所以其实可以忽略不计。只是我认为稍稍简单一些。)
“这里只是用一个从加密角度来看,用不十分安全的哈希算法替换掉了 std 的默认哈希算法,此外并没有太多有趣的东西。
“std 默认使用了加密安全的哈希算法,速度略慢。在这段程序中,fxhash 和 fnv 的性能似乎相等,而 fxhash 在我的评测中略胜一筹。如果我们需要强制‘没有外部依赖’规则,我们也可以非常容易地自己编写fnv的实现。”
rust/optimized/main.rs
fn try_main() -> Result<(), Box<dyn Error>> {
let stdin = io::stdin();
let mut stdin = stdin.lock();
let mut counts: HashMap<Vec<u8>, u64> = HashMap::default();
let mut buf = vec![0; 64 * (1<<10)];
let mut offset = 0;
let mut start = None;
loop {
let nread = stdin.read(&mut buf[offset..])?;
if nread == 0 {
if offset > 0 {
increment(&mut counts, &buf[..offset+1]);
}
break;
}
let buf = &mut buf[..offset+nread];
for i in (0..buf.len()).skip(offset) {
let b = buf[i];
if b'A' <= b && b <= b'Z' {
buf[i] += b'a' - b'A';
}
if b == b' ' || b == b'\\n' {
if let Some(start) = start.take() {
increment(&mut counts, &buf[start..i]);
}
} else if start.is_none() {
start = Some(i);
}
}
if let Some(ref mut start) = start {
offset = buf.len() - *start;
buf.copy_within(*start.., 0);
*start = 0;
} else {
offset = 0;
}
}
let mut ordered: Vec<(Vec<u8>, u64)> = counts.into_iter().collect();
ordered.sort_by(|&(_, cnt1), &(_, cnt2)| cnt1.cmp(&cnt2).reverse());
for (word, count) in ordered {
writeln!(io::stdout(), "{} {}", std::str::from_utf8(&word)?,
count)?;
}
Ok(())
}
fn increment(counts: &mut HashMap<Vec<u8>, u64>, word: &[u8]) {
// using 'counts.entry' would be more idiomatic here, but doing so
// requires allocating a new Vec<u8> because of its API. Instead, we
// do two hash lookups, but in the exceptionally common case (we see
// a word we've already seen), we only do one and without any allocs.
if let Some(count) = counts.get_mut(word) {
*count += 1;
return;
}
counts.insert(word.to_vec(), 1);
}

Unix shell
我们尝试一下使用基本的 Unix 命令行工具,下面是 Doug McIloy 的版本:
tr 'A-Z' 'a-z' | tr -s ' ' '\\n' | sort | uniq -c | sort -nr
它非常慢,因为需要对整个文件排序,而不是使用哈希表进行计数(将整个文件读入内存实际上违反了我提出的约束条件)。但是让我惊讶的是,只要把第一个 sort 的地域选项设置为 C(即仅处理 ASCII),就能将速度提高5倍!比其他语言中更好的算法还要快!
而且如果使用 sort -S 2GB 提供更大的缓冲区,还能进一步提高其速度(这里又打破了约束条件)。有意思的是,sort 的 --parallen 选项在这个规模上并没有太大作用。所以优化后的版本如下:
tr 'A-Z' 'a-z' | tr -s ' ' '\\n' | LC_ALL=C sort -S 2G | uniq -c | \\
sort -nr
对于小型文件来说这样就足够了。如果我想处理巨型文件,没办法将整个文件读入内存进行排序,那么我会采用 AWK 或 Python 版本。
输出结果与其他语言不太一样,其格式是“空格-前缀-计数-单词”,而不是“单词-计数”,如下所示:
4 the
2 foo
1 defenestration
我们可以加上 awk '{ print $2, $1 }'来改正,但毕竟要使用 awk,而且 awk 有更有效的办法。

其他语言
许多读者给 benhoyt/countwords 代码库贡献了其他流行的语言。感谢你们!
下面是完整的列表:
-
Bash: Jesse Hathaway - 不在评测范围内,因为运行时间超过了两分钟
-
C#: John Taylor, Yuriy Ostapenko 和Osman Turan
-
C# (LINQ): Osman Turan - 不评测
-
C++ optimized version: Jussi Pakkanen, Adev, Nathan Myers
-
Common Lisp: Brad Svercl
-
Crystal: Andrea Manzini
-
D: Ross Lonstein
-
F#: Yuriy Ostapenko
-
Go: Miguel Angel - 对 Go 的优化版本做了简化;Joshua Corbin - 添加了一个并行 Go 版本
-
Java: Iulian Pleșoianu
-
javascript: Dani Biró 和 Flo Hinze
-
Julia: Alessandro Melis
-
Kotlin: Kazik Pogoda
-
Lua: Flemming Madsen
-
Nim: csterritt 和 euantorano
-
OCaml: doesntgolf
-
Pascal: Osman Turan
-
Perl: Charles Randall
-
php: Max Semenik
-
Ruby: Bill Mill, 和Niklas
-
Rust: Andrew Gallant
-
Swift: Daniel Müllenborn
-
Tcl: William Ross
-
Zig: ifreund ,matu3ba 和ansingh

性能结果和经验
下面是在我的笔记本电脑(64位Linux+SSD)上运行程序的结果。每个测试运行5次,取最短时间作为结果。每次运行都使用如了下命令:
time $PROGRAM <kjvbible_x10.txt >/dev/null
时间单位为秒,所以越小越好。列表按照简单版本的执行时间排序,从快到慢。(注意 grep 和 wc 实际上并没有解决统计问题,只是列出作为比较。)
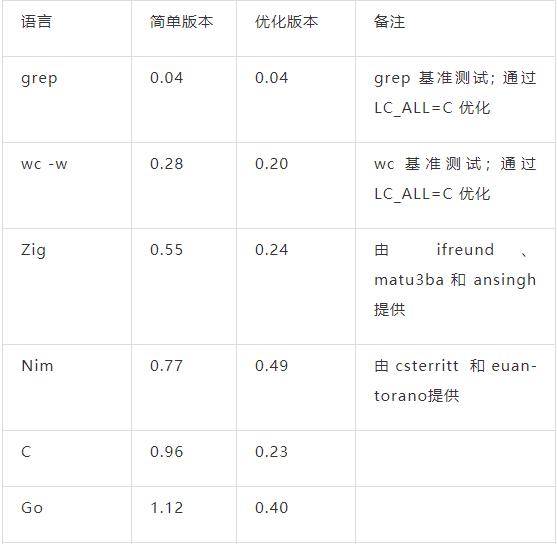
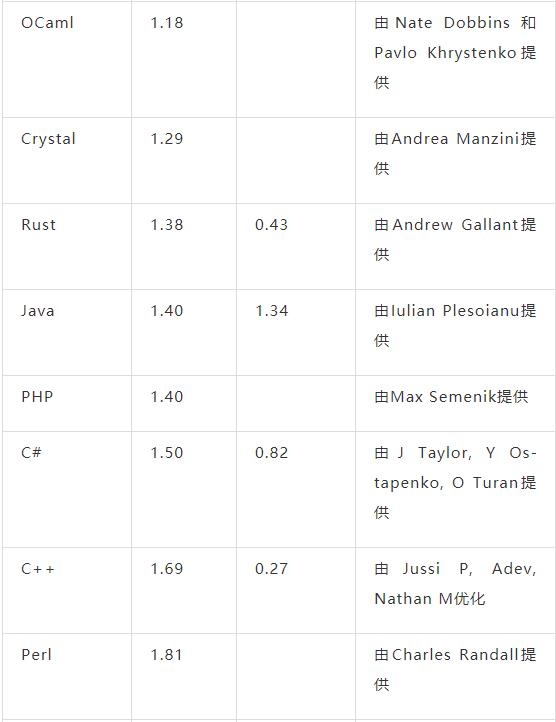
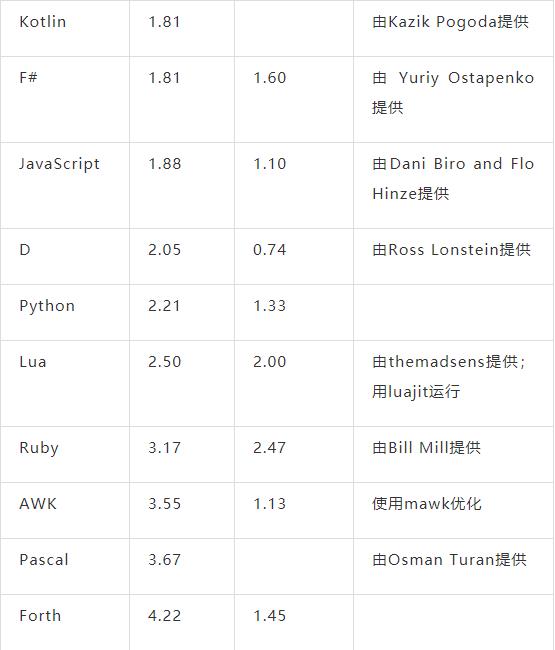
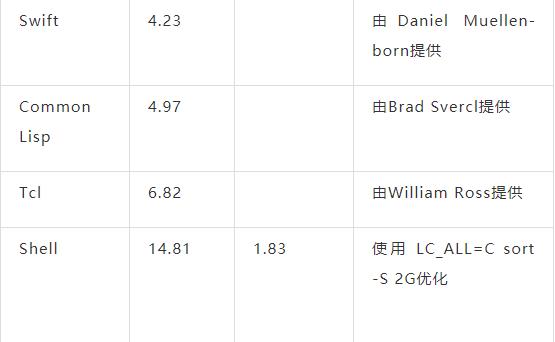
我认为, 简单版本是最合适的。在实际工作中基本上会选择这些版本。我们从中得到什么结论?下面是我的一些想法:
-
几乎没有人选择优化过的 C 版本,除非你想自己编写一个 GNU wordfreq 工具。因为太容易写错了。如果你想要安全的语言和更快的版本,我推荐选择 Go 或 Rust。
-
如果你只需要快速的解决方案(很多情况下如此),那么 Python 和 Awk 非常合适。
-
C++ 模板会产生大量可怕的错误信息,还会在评测报告中产生可怕的函数名,所以评测报告几乎无法阅读。
-
我依然认为这是一个非常好的面试题,尽管我不会期待候选人在白板上写出任何一个优化过的解决方案。
-
我们通常会认为 I/O 很昂贵,但这里的瓶颈并不在 I/O 上。从评测角度来看,文件很可能被缓存了,但即使并非如此,硬盘的读取速度也已经非常快了。真正的瓶颈在于分词和哈希表操作。
这个实验非常有趣!我学到了许多优化的知识,使用了 Valgrind 评测工具,还编写了久违的 Forth 代码。
原文链接:https://benhoyt.com/writings/count-words/
声明:本文由CSDN翻译,转载请注明来源。

60+专家,13个技术领域,CSDN 《IT 人才成长路线图》重磅来袭!
直接扫码或微信搜索「CSDN」公众号,后台回复关键词「路线图」,即可获取完整路线图!
以上是关于运行 JavaPythonGo 等 25 种代码后,发现性能最强的竟然是它!的主要内容,如果未能解决你的问题,请参考以下文章
excel中一共有31个sheet,用vb代码将其命名,在线等,急. 命名方式为:前六个sheet命名为26-31,后25个命