在 Swift 里安全管理指针
Posted SwiftGG翻译组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在 Swift 里安全管理指针相关的知识,希望对你有一定的参考价值。
Session:https://developer.apple.com/videos/play/wwdc2020/10167/
在 Swift 中,我们通过 Unsafe 前缀来标识那些输入后可能发生未定义行为的操作,详情可以回顾 WWDC20 - Unsafe Swift[1]。而本文则会更深入地探讨在非安全范围内编写 Swift 的一些细节,日常开发中比较少接触到的部分。
想要更安全地管理指针,意味着需要了解各种导致不安全的方式。指针的安全性可以分为不同级别来讨论,越往底层,程序员越需要为代码的正确性负责。所以日常开发中建议尽量使用顶层的 API 编写代码。
安全级别
安全性可以被分为四个级别。
-
最顶层的是安全级别,Swift 的主要目标之一就是无需任何不安全的数据结构就能编写代码。Swift 拥有健壮的类型系统,提供了强大的灵活性和性能。完全不使用指针对于代码安全来说是一个很好的选择。
-
但是 Swift 另一个重要目标是和不安全语言的高性能互操性。所以在第二层 Swift 提供了前缀为 Unsafe 的类型或函数。
UnsafePointer<T>可以在不用担心类型安全的情况下使用指针。 -
如果需要使用原始内存作为字节序处理,那么就要使用第三层的
UnsafeRawPointer,使用它来加载和存储值到原始内存中,需要熟悉类型的内存布局。 -
在最底层中,Swift 提供了绑定内存类型的内存绑定 API,只有在这一层才需要完全保证指针的类型安全。
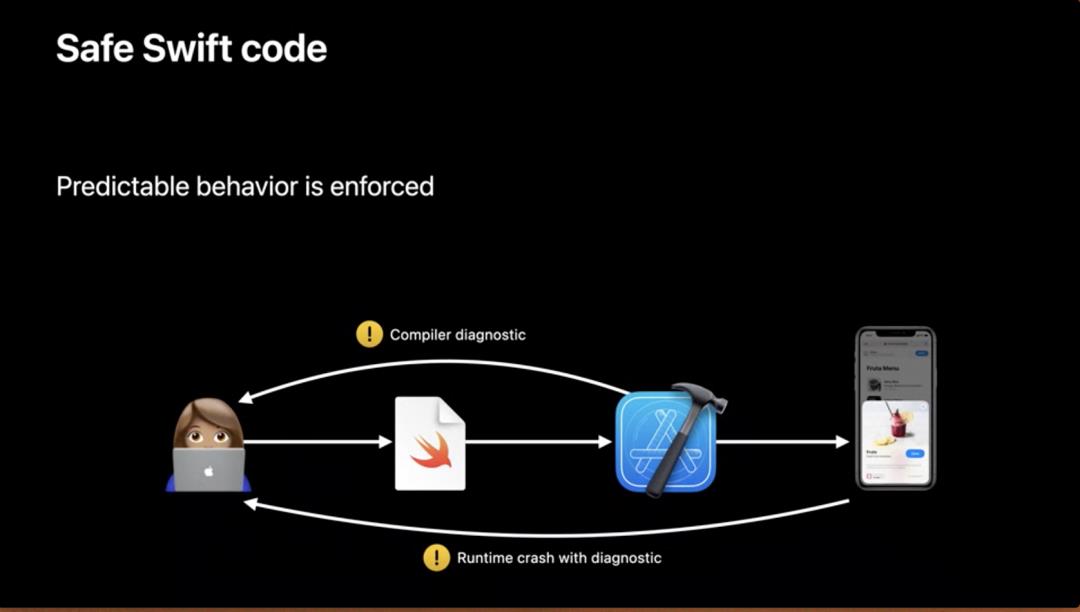
注意,安全代码并不一定意味着正确代码,但它的行为是可预测的。大多数情况下,编译器会捕获代码导致的不可预测行为。对于编译时无法捕获的错误,运行时会检查并让程序立刻崩溃并给出诊断。安全代码实际上增强了错误的表现。在线程安全且不使用 Unsafe 前缀 API 的情况下,代码会强制产生可预测行为。
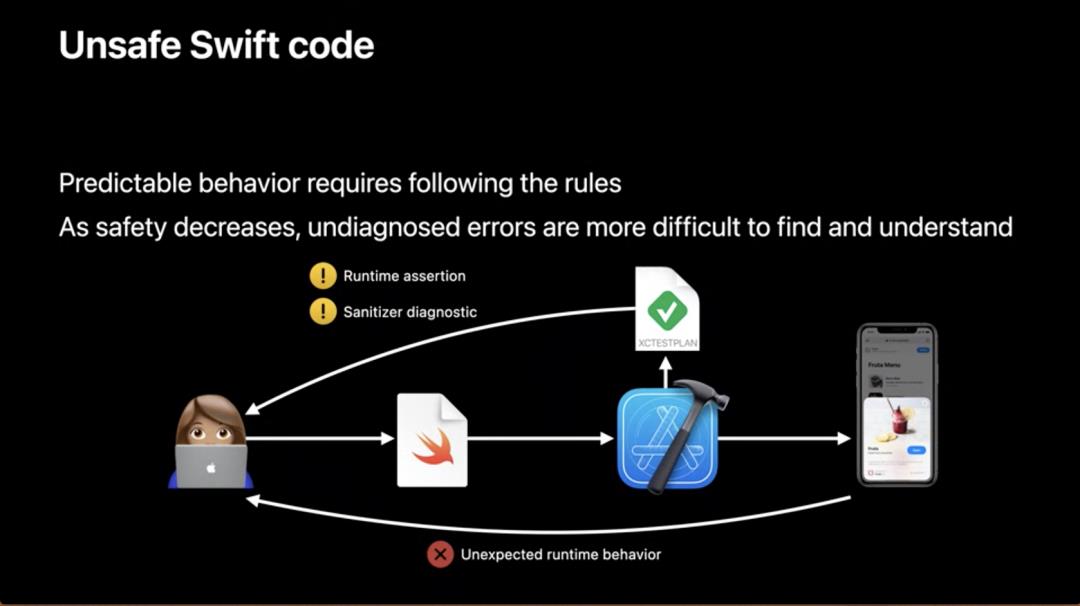
反之,在不安全的 Swift 代码中,可预测行为并不是完全强制的,所以需要程序员承担额外的风险。Xcode 的测试提供了一些有用的诊断,但诊断的级别取决于选择的安全级别。标准库中的不安全 API 可以通过断言和调试编译来捕获一些无效输入。添加先决条件来验证不安全的假设也是一个不错的实践。还可以通过 Xcode 的 Address Sanitizer[2] 在运行时检查,但它也无法捕获所有的未定义行为。如果测试期间没有发现错误,则可能在运行时发生难以调试的崩溃,或者更可怕的是执行错误行为导致用户数据被破坏。
指针安全
Swift 设计上是无须指针的编程语言,了解指针的安全性能更清楚为何应该避免使用它们。同时,如果确实需要使用底层 API 来访问内存,这块知识也是值得掌握的。
生命周期
在需要指向变量的存储空间、数组元素或者直接分配的内存时,需要稳定的内存位置。但这块稳定的存储空间生命周期是有限的。可能因为它超出了作用域,也可能你需要直接分配内存,就会导致超出了生命周期。然而,你使用的指针有着自己的生命周期,当你的指针的生命周期超过对应存储空间的生命周期时,指针访问就会变成未定义行为。这是指针不安全的主要原因,但不是唯一原因。
对象边界
指针类型
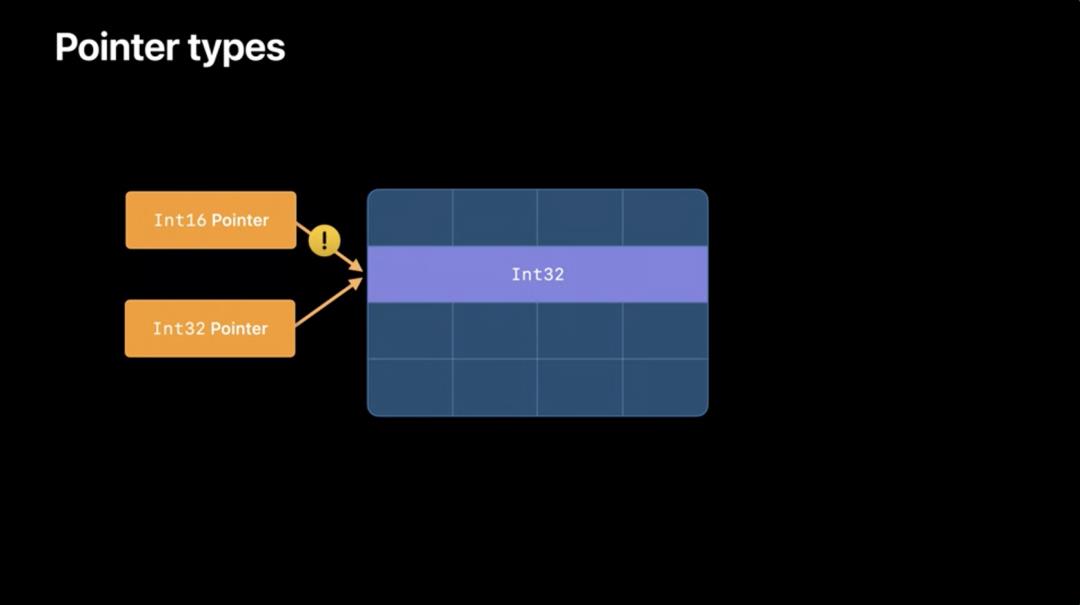
还有一个方面的安全问题容易被忽视,指针本身的类型和内存里的值类型不一致。比如本来有一个指向 Int16 的指针,当内存区域被覆盖为 Int32 时,访问 Int16 旧指针就会产生未定义行为。
下面有一个非常不安全的例子,你可能会被从 C 移植而来的 Swift 代码调用部分旧 C 代码的样子吓到。
struct Image {
// ...
}
// 未定义行为可能导致数据丢失
struct Collage {
var imageData: UnsafeMutablePointer<Image>?
var imageCount: Int = 0
}
// C 风格的 API 需要 Int 的指针传入
func addImages(_ countPtr: UnsafeMutablePointer<UInt32>) -> UnsafeMutablePointer<Image> {
// ...
let imageData = UnsafeMutablePointer<Image>.allocate(capacity: 1)
imageData[0] = Image()
countPtr.pointee += 1
return imageData
}
func saveImages(_ imageData: UnsafeMutablePointer<Image>, _ count: Int) {
// 随便执行些什么
print(count)
}
var collage = Collage()
collage.imageData = withUnsafeMutablePointer(to: &collage.imageCount) {
// 注意这行,创建了指针,但类型不匹配
addImages(UnsafeMutableRawPointer($0).assumingMemoryBound(to: UInt32.self))
}
saveImages(collage.imageData!, collage.imageCount) // 可能发生 imageCount == 0
addImages(:) 调用时将图像数据写入并更新图像数量,Collage 结构中的 imageCount 是 Int,但 addImages(:) 实参需要的是 UInt32。安全的做法是创建匹配的新变量并使用 Swift 的整数转换。然而这里直接创建了指向结构体的指针,那么在之后运行时读取这个数量时,就可能为 0。这里的不同类型告诉了编译器这两个值会属于不同的内存对象中,所以编译器不会更新 Int 的值。也就是说编译器会根据类型信息进行假设,一旦假设有误,会蔓延到编译管道中,最后可能产生意料之外的结果。不同版本的编译器也可能导致不同的结果。
指针类型导致的 Bug:
-
可能导致意料之外的行为 -
可能长时间难以被发现 -
可能在意外的时间爆发 -
在看起来无害的源码改动后 -
编译器升级后
C 指针有着 [严格别名](https://zh.wikipedia.org/wiki/别名_(计算 "严格别名")) 和 类型双关[3] 规则。幸运的是,不需要了解这些规则也能在 Swift 中安全地使用指针。Swift 指针因为需要传递到 C,所以至少和 C 一样严格以便安全地互操作。
类型指针
UnsafePointer<T> 是类型指针,提供了 C 指针大部分底层功能,且不需要担心指针类型安全问题,只需要管理对象的生命周期和对象边界就好。
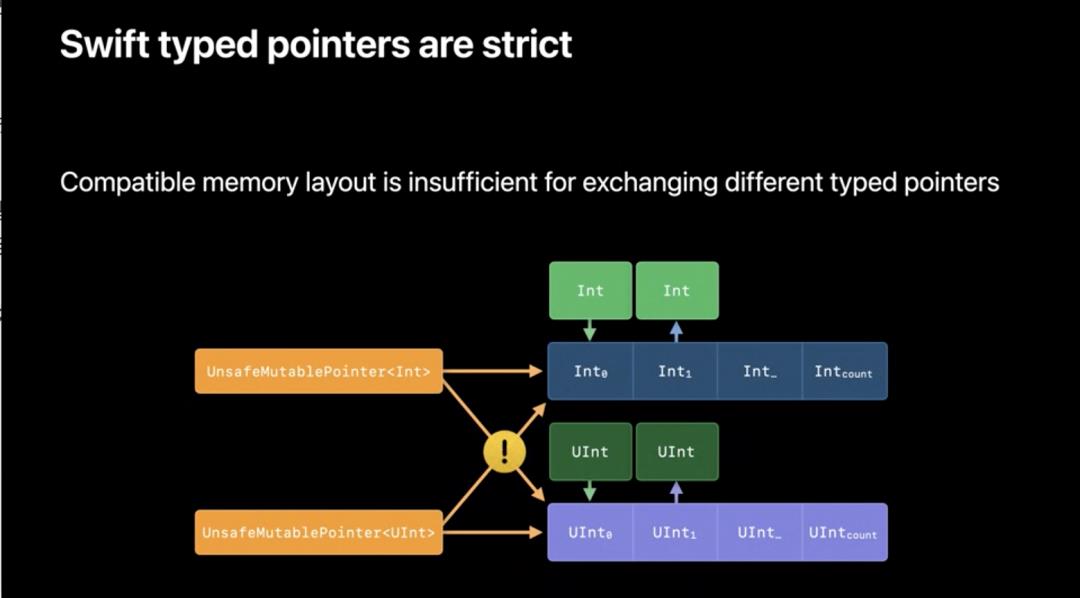
复合类型也是类似的,里面的结构以正确的类型绑定。
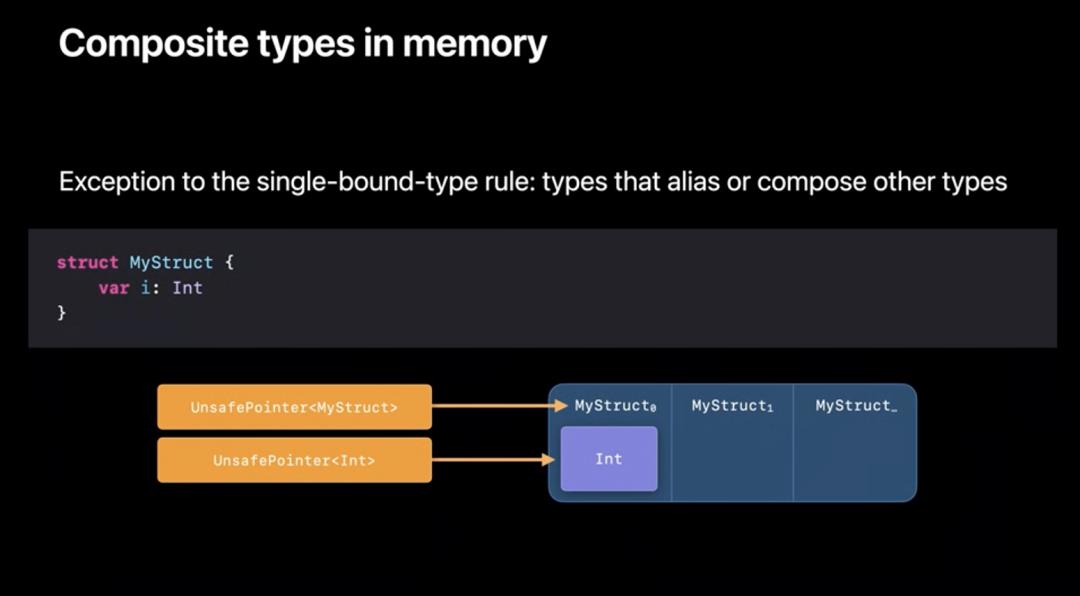
获取 UnsafePointer<T> 的方式有两种。
1. 通过已有变量获取
let i: Int
withUnsafePointer(to: i) { (intPtr: UnsafePointer<Int>) in
// ...
}
let array: [T]
array.withUnsafeBufferPointer { (elmentPtr: UnsafeBufferPointer<T>) in
//...
}
这样获取的指针类型就和原来变量的类型一致。数组则返回数组元素类型的指针。
2. 直接分配内存
let tPtr = UnsafeMutablePointer<T>.allocate(capacity: count)
tPtr.initialize(repeating: t, count: count)
tPtr.assign(repeating: t, count: count)
tPtr.deinitialize(count: count)
tPtr.deallocate()
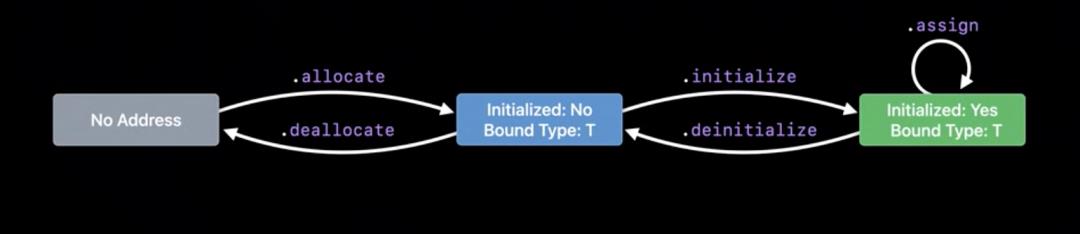
直接分配内存将绑定类型,返回一个类型指针,但这时还未构造,可以通过 initalzize 进行构造,assgin 进行重新分配,deinitialize 进行析构。Swift 会保证这一过程的指针类型安全,而内存构造状态由程序员来管理。
原始指针
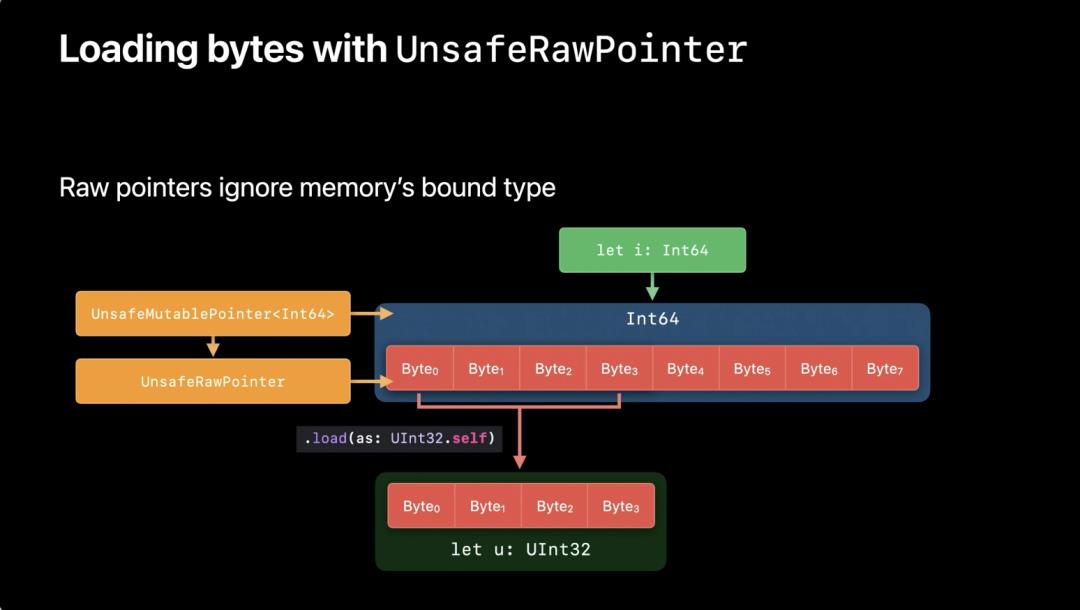
如果需要将内存里的字节转换成其他类型,则需要使用无类型的 UnsafeRawPointer。原始指针会忽略内存绑定类型。
获取 UnsafeRawPointer 的方式有两种。
1. 通过已有 UnsafePointer<T> 获取
可以传入 UnsafePointer<T> 来构造 UnsafeRawPointer。
let p: UnsafePointer<T>
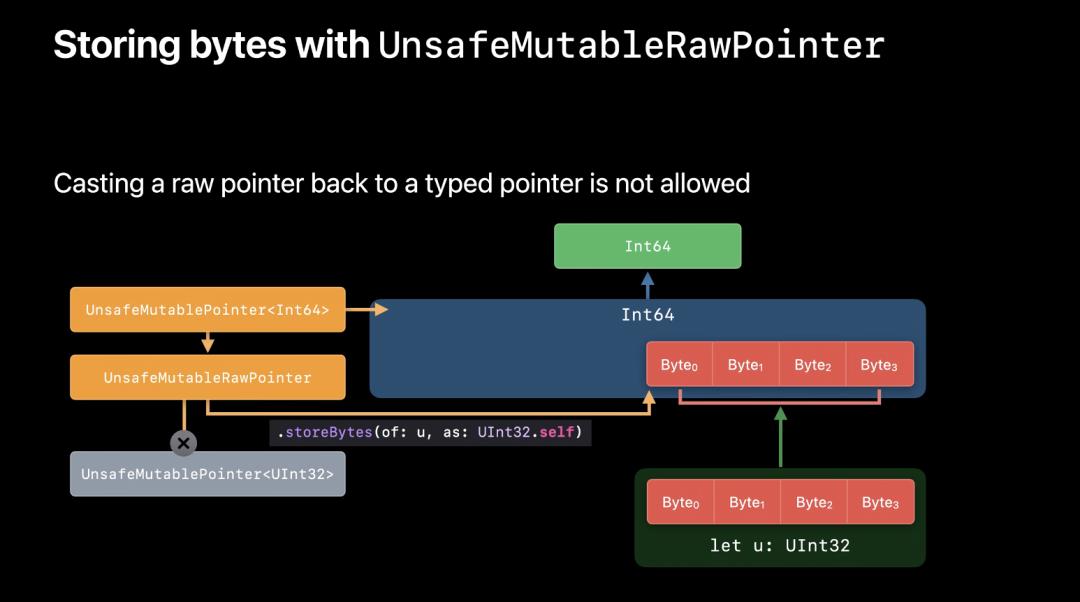
let r = UnsafeRawPointer(p)
写入通过 storeBytes(of:as:) 并指定类型。和类型指针不一样,原始指针不会析构先前在内存里的值。所以之前的引用依旧有效。比如给 Int64 内存区域的写入 UInt32 字节,写入后依旧是 Int64 绑定类型。因此原来的类型指针依旧可以访问,而不会被自动转换。
2. 通过已有变量获取
var i: Int
withUnsafeBytes(of: i) { (iBytes: UnsafeRawBufferPointer) in
//...
}
withUnsafeMutableBytes(of: &i) { (xBytes: UnsafeMutableRawBufferPointer) in
//...
}
let array: [T]
array.withUnsafeBytes { (elementBytes: UnsafeRawBufferPointer) in
//...
}
获取到的 UnsafeRawBufferPointer 和 UnsafeBufferPointer<T> 类似,都是字节的集合。count 是变量类型的内存大小,索引是字节的偏移量,索引的值是对应字节的 UInt 值。
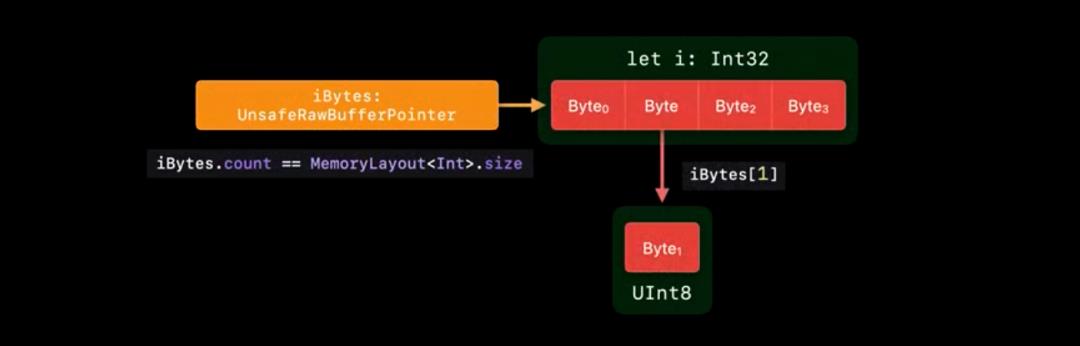
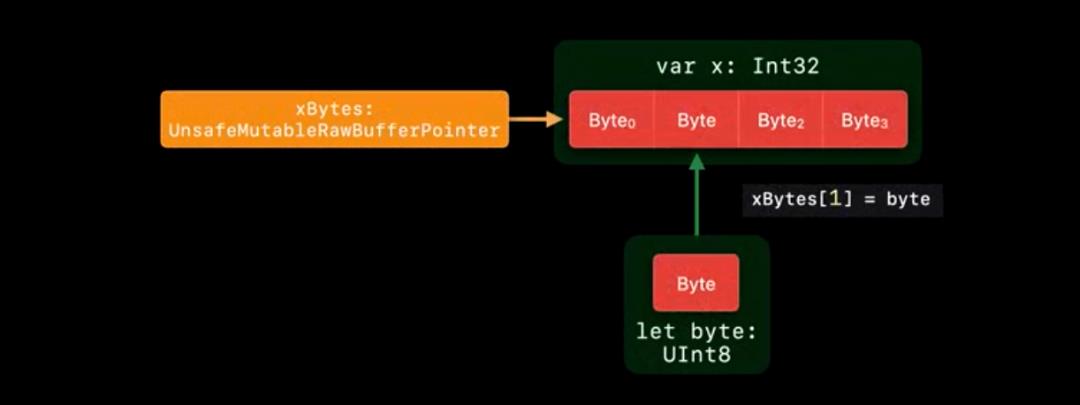
修改可以通过 withUnsafeMutableBytes 的方式获取 UnsafeMutableRawBufferPointer 进行修改。
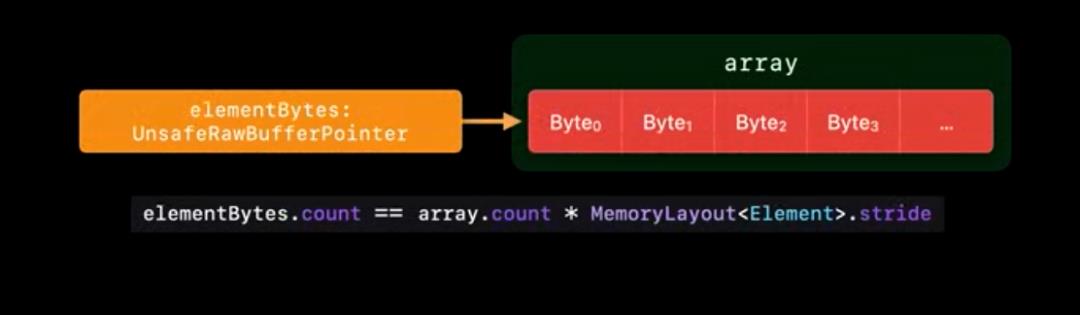
数组也有类似的方法,count 对应的是数组数量x元素 跨步[4]。其中一些字节会被填充用于元素对齐。
3. 从 Data 中获取
Foundation 中的 Data 有 withUnsafeBytes 方法,通过闭包返回原始指针。
import Foundation
func readUInt32(data: Data) -> UInt32 {
data.withUnsafeBytes { (buffer: UnsafeRawBufferPointer) in
buffer.load(fromByteOffset: 4, as: UInt32.self)
}
}
let data = Data(Array<UInt8>([0, 0, 0, 0, 1, 0, 0, 0]))
print(readUInt32(data: data))
4. 直接分配内存
let rawPtr = UnsafeMutableRawPointer.allocate(
byteCount: MemoryLayout<T>.stride * numValues,
alignment: MemoryLayout<T>.alignment)
let tPtr = rawPtr.initializeMemory(as: T.self, repeating: t, count: numValues)
// 必须使用类型指针 ‘tPtr’ 进行析构

直接分配内存需要负责计算内存大小和字节对齐方式。分配后和类型指针不一样,不会绑定类型,也没有进行构造。通过指定内存绑定的值和类型进行构造,就会返回类型指针。这个过程是单向的,所以没法使用原始指针进行析构,而要通过类型指针。而使用原始指针释放时需要保证它处于未构造的状态。

一般来说,类型指针更安全和方便,所以应该优先选用。某些情况下需要原始指针,比如将不相关的类型存储在同一连续的可变长度内存区域里。可以通过构造一部分内存为头部,偏移头部后的指针就指向里面的元素,这种内存分配方式非常适合实现标准库类型例如 Set 和 Dictionary,但日常较少用到。原始指针是一种实现高性能数据结构的利器,但要注意的是,字节偏移和数据对齐并不是一件简单的事情。
原始指针通常还会用于将外部生成的字节缓冲区(比如网络的流)解码为 Swift 类型。通过读取前面字节里的值来确定后续需要读取的类型信息和大小。
原始指针依旧是类型安全的,虽然使用时需要保证内存布局,但其他方面并不会比类型指针更危险。
内存绑定 API
在最底层,Swift 给 UnsafeRawPointer 提供了内存绑定类型的 API。在使用它之前,再三考虑是否能尽量使用上层 API,因为需要对指针的类型安全完全负责。
func assumingMemoryBound<T>(to: T.Type) -> UnsafePointer<T>
func bindMemory<T>(to type: T.Type, capacity count: Int) -> UnsafePointer<T>
func withMemoryRebound<T, Result>(to type: T.Type, capacity count: Int, _ body: (UnsafePointer<T>) throws -> Result) rethrows -> Result
显式调用内存绑定相关的 API 时,你将会清晰地知道绕过指针类型安全的时机。这样做的危险之处在于,代码很容易在执行已有的类型指针时导致未定义行为。唯一需要遵循的规则是:使用类型指针访问时需要和内存绑定的类型匹配。虽然这个规则很简单,但是遵循起来并不容易,因为不同的代码在内存类型上只是口头约定,而编译器并不会给出指引。
下面介绍了使用一些必须使用如此危险的 API 的例子,注意这些用法是如何保证安全的。
assumingMemoryBound(to:)
极少数情况下,代码没有保留类型指针,只有原始指针,但明确知道内存绑定的类型,这时候就需要assmuingMemoryBound(to:) 来告诉编译器预期类型,转换成对应的类型指针(注意:这里的转换只是让编译器绕过类型检查,并没有实际发生转换)。
func takesIntPointer(_: UnsafePointer<Int>) { /* elided */ }
struct RawContainer {
var rawPtr: UnsafeRawPointer
var pointsToInt: Bool
}
func testContainer(numValues: Int) {
let intPtr = UnsafeMutablePointer<Int>.allocate(capacity: numValues)
let rc = RawContainer(rawPtr: intPtr, pointsToInt: true)
// ...
if rc.pointsToInt {
takesIntPointer(rc.rawPtr.assumingMemoryBound(to: Int.self))
}
}
比如这个例子中已知放在 RawContainer 容器里类型指针一定是绑定 Int 类型,那么就可以通过 assumingMemoryBound(to:) 来转换成类型指针。使用它的前提是它的确已经被绑定为该类型了,运行时并不会进行检查,所以正确性由使用者来保证。
import Darwin
struct ThreadContext {
// ...
}
let contextPtr = UnsafeMutablePointer<ThreadContext>.allocate(capacity: 1)
contextPtr.initialize(to: ThreadContext())
var pthread: pthread_t?
let result = pthread_create(
&pthread, nil,
{ (ptr: UnsafeMutableRawPointer) in
let contextPtr = ptr.assumingMemoryBound(to: ThreadContext.self)
// ...
return nil
},
contextPtr)
}
比如在调用 C API phread_create 时,构造了自定义线程上下文类型的 contextPtr。但是闭包里返回的是抹去类型信息的原始指针(该指针就是传入的指针),这时也需要进行转换。这是因为 C 函数声明里它是一个 void* 类型的实参,在 Swift 中被转换为 UnsafeMutableRawPointer。这种情况在使用 C 的 API 时偶尔会出现,因为没有办法确保类型安全。
func takesIntPointer(_: UnsafePointer<Int>) {
// ...
}
let tuple = (0, 1, 2)
withUnsafePointer(to: tuple) { (tuplePtr: UnsafePointer<(Int, Int, Int)>) in
takesIntPointer(UnsafeRawPointer(tuplePtr).assumingMemoryBound(to: Int.self))
}
比如在使用元组获取类型指针时,类型是元组的类型。Swift 实现上确保了元组内存绑定的类型实际上是其元素的类型(元组元素相同的情况下),并在元素跨度的基础上按照元素顺序排列。所以如果需要使用元组中元素的类型指针,就可以通过手动类型擦除再转换得到匹配的类型指针。
func takesIntPointer(_: UnsafePointer<Int>) {
// ...
}
struct MyStruct {
var status: Bool
var value: Int
}
let myStruct = MyStruct(status: true, value: 0)
withUnsafePointer(to: myStruct) { (ptr: UnsafePointer<MyStruct>) in
let rawValuePtr = (UnsafeRawPointer(ptr) + MemoryLayout<MyStruct>.offset(of: MyStruct.value)!)
takesIntPointer(rawValuePtr.assumingMemoryBound(to: Int.self))
}
结构体也是类似的,获取的类型指针时,类型是结构体的类型。这个时候就可以通过转换为原始指针并加上该属性在结构体中的偏移量(通过 MemoryLayout 的 offset(of:) )来获得属性的原始指针,然后再转换得到匹配的类型指针。通常,结构体属性的内存布局是不确定的,所以获取的指针只能使用于该属性。由于指向结构体属性比较常用,所以 Swift 提供了一种更简单的做法来避免使用不安全的 API。只需要将结构体的属性作为 inout 实参传入,编译器会隐式转换为该函数实参所声明的不安全指针类型。
let myStruct = MyStruct(status: true, value: 0)
// 下面两种用法是等效的
// 1
withUnsafePointer(to: myStruct) { (ptr: UnsafePointer<MyStruct>) in
let rawValuePtr = (UnsafeRawPointer(ptr) + MemoryLayout<MyStruct>.offset(of: MyStruct.value)!)
takesIntPointer(rawValuePtr.assumingMemoryBound(to: Int.self))
}
// 2
takesIntPointer(&myStruct.value)
bindMemory(to:capacity:)
bindMemory(to:capacity:) 可以用于更改内存绑定的类型。如果内存还没有类型绑定,则将首次绑定为该类型。如果内存已经进行类型绑定,则将重新绑定为该类型,并且内存里所有值都会变成该类型。
let uint16Ptr = UnsafeMutablePointer<UInt16>.allocate(capacity: 2)
uint16Ptr.initialize(repeating: 0, count: 2)
let int32Ptr = UnsafeMutableRawPointer(uint16Ptr).bindMemory(to: Int32.self, capacity: 1)
// uint16Ptr 的访问现在是未定义行为
int32Ptr.deallocate()
假设分配了一块容纳两个 UInt16 的内存,通过原始指针调用 bindMemory(to:capacity:) 来改变为单个 UInt32。这时只发生了按位转换,并没有任何普通的类型转换的安全检查,在运行时也没有做任何事情。这实际上只是向编译器声明该内存位置更改了类型。返回的新指针用于访问内存,旧指针访问时将会产生未定义行为,因为每个内存位置只能绑定到一种类型上。
更改内存绑定的类型并不会在物理上修改内存,但需要把它当作改变内存的全局状态来考虑。
其中一种 bindMemory(to:capacity:) 的常见错误用法是将它从内存中读取不同类型的值,这样可能会影响其他已有指针。
// 错误用法
return rawPtr.bindMemory(to: UInt32.self).pointee
// 正确用法
return rawPtr.load(as: UInt32.self)
withMemoryRebound(to:capacity:body:)
当有几个外部的 API 的实参类型有数据类型上的差异,但又想避免来回复制数据时,就可以使用 withMemoryRebound(to:capacity:body) 来临时更改内存绑定类型。这种情况在使用 C 的 API 时经常出现。
func takesUInt8Pointer(_: UnsafePointer<UInt8>) {
// ...
}
int8Ptr.withMemoryRebound(to: UInt8.self, capacity: count) { (uint8Ptr: UnsafePointer<UInt8>) in
// int8Ptr 不能在闭包里使用
takesUInt8Pointer(uint8Ptr)
}
// uint8Ptr 不能在闭包外使用
比如 Int8 的类型指针无法直接调用实参为 UInt8 的函数,这里虽然可以重新分配一块匹配类型的内存并复制数据,但是这样速度比较慢。只需要在调用时临时转换一下就好了,这时候就可以使用 withMemoryRebound(to:capacity:body) 临时绑定为对应类型的指针,它的作用域只在闭包内。闭包返回时,将会重新绑定为原始类型。这可以将临时类型指针的访问和其他代码的作用域分开。
但是它有一些严格的限制:
-
需要有原始的指针 -
转换的类型和原始的类型需要有相同的跨度
因此,无法使用 withMemoryRebound(to:capacity:body) 的情况下,不得不使用 bindMemory(to:capacity:) 时,请遵循类似的规范:
-
限制更改绑定后指针的作用域 -
在作用域结束时重新绑定回原始类型
总结
assmuingMemoryBound(to:):从原始指针恢复预期类型的方法,需要已知内存绑定的类型才可以使用。
bindMemory(to:capacity:):更改内存绑定类型的状态,是底层原语,会影响其他已有的类型指针。
withMemory(to:capacity:body):临时更改内存绑定类型的状态,在不得不更改内存绑定类型时优先考虑。在需要调用不匹配类型的 C 的 API 时可以避免额外复制。
从原始内存中区分类型
如果内存区域的底层存储只暴露了原始指针,但又想用作不同特定类型元素的序列,可以使用下面介绍的技术。
struct UnsafeBufferView<Element>: RandomAccessCollection {
let rawBytes: UnsafeRawBufferPointer
let count: Int
init(reinterpret rawBytes: UnsafeRawBufferPointer, as: Element.Type) {
self.rawBytes = rawBytes
self.count = rawBytes.count / MemoryLayout<Element>.stride
precondition(self.count * MemoryLayout<Element>.stride == rawBytes.count)
precondition(Int(bitPattern: rawBytes.baseAddress).isMultiple(of: MemoryLayout<Element>.alignment))
}
var startIndex: Int { 0 }
var endIndex: Int { count }
subscript(index: Int) -> Element {
rawBytes.load(fromByteOffset: index * MemoryLayout<Element>.stride, as: Element.self)
}
}
可以为该类型元素创建一个包装器,并引入内存边界来方便调试,构造时根据元素跨度来计算缓冲区中的元素数量,还添加了 precondition 来验证字节对齐的正确性。这样在使用索引读取时,就可以通过计算偏移量来从原始缓冲区加载对应类型的元素了。由于原始内存中加载对应指针类型的行为是安全的,所以不需要担心其他代码访问该内存。这是一种不需要使用类型指针的又能安全地转换字节序列的方式。
最后
总结一下在 Swift 中使用指针的最佳实践:
-
避免使用指针
-
不得不转换内存绑定的类型时,不要使用类型指针(而 C 经常使用转换指针类型的做法)
-
使用原始指针可以:
-
转换原始字节到不同的类型 -
把字节流解码成 Swift 类型 -
实现在连续内存里持有不同类型的容器
推荐阅读
关注我们
我们是「老司机技术周报」,每周会发布一份关于 ios 的周报,也会定期分享一些和 iOS 相关的技术。欢迎关注。
另外, 正式上线,欢迎大家前往订购~
支持作者
WWDC 内参 系列是由老司机周报、知识小集合以及 SwiftGG 几个技术组织发起的。已经做了几年了,口碑一直不错。 主要是针对每年的 WWDC 的内容,做一次精选,并号召一群一线互联网的 iOS 开发者,结合自己的实际开发经验、苹果文档和视频内容做二次创作。
参考资料
WWDC20 - Unsafe Swift: https://developer.apple.com/videos/play/wwdc2020/10648
[2]Address Sanitizer: https://developer.apple.com/videos/play/wwdc2015/413/
[3]类型双关: https://zh.wikipedia.org/wiki/类型双关
[4]跨步: https://en.wikipedia.org/wiki/Stride_of_an_array
[5]原语: https://en.wikipedia.org/wiki/Language_primitive
以上是关于在 Swift 里安全管理指针的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 Swift 使用此代码片段为 iOS 应用程序初始化 SDK?