流数据分析平台Storm简介
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流数据分析平台Storm简介相关的知识,希望对你有一定的参考价值。
流数据分析平台Storm简介
Storm是一个分布式的、容错的实时流计算系统,可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm之于实时处理,就好比Hadoop之于批处理。Storm保证每个消息都会得到处理,而且它的处理速度很快,在一个小集群中,每秒可以处理数以百万计的消息,而且可以使用任意编程语言来开发。
Storm的集群表面上看和Hadoop的集群非常相似。但是在Hadoop上运行的是MapReduce的Job, 而在Storm上运行的是Topology。它们根本的区别就是,一个MapReduce Job最终会结束, 而一个Topology永远不会结束(除非显式的终止)。Storm作为典型的流处理引擎,它的应用场景有实时分析、在线机器学习、连续计算、分布式RPC、分布式ETL等。
Storm 采用的是主从系统架构,如图1所示。在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。在控制节点上面运行一个后台程序: Nimbus, 它的作用类似Hadoop里面的JobTracker。Nimbus负责全局的资源分配、任务调度、状态监控和故障检测等。每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor负责监听分配给它的那台机器的工作,根据需要启动或者关闭工作进程。每一个工作进程执行一个Topology的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程组成。Nimbus和Supervisor都能快速失败,因为它们是无状态的,系统的状态信息保存在Zookeeper或者磁盘设备上,这样一来它们就变得十分健壮,两者的协调工作是由Zookeeper来完成的,ZooKeeper用于管理集群中的不同组件。

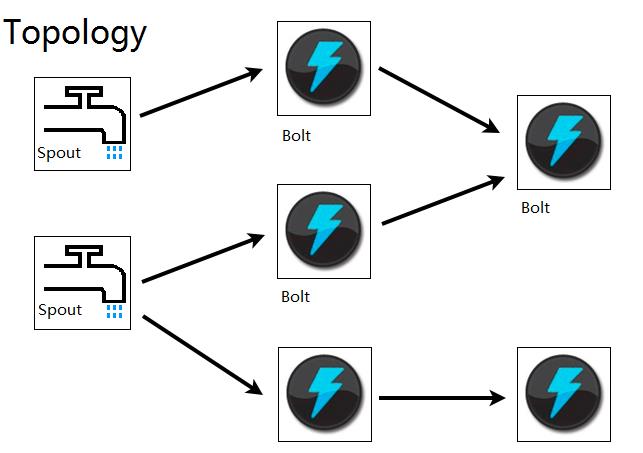
Topology是Storm 的逻辑单元,所有组件的排列(Spouts 和Bolts)及它们的连接被称为Topology。Storm中一个实时应用的计算任务打包为Topology后发布,Topology一旦提交永远运行,除非显式地去终止。一个Topology是由一系列Spout 和Bolt 构成的有向无环图,通过数据流(stream)实现Spout 和Bolt 之间的关联,如图2 所示。其中,Spout 负责从外部数据源不间断地读取流数据,并以Tuple 元组的形式发送给相应的Bolt。Bolt 负责对接收到的数据流进行计算,实现过滤、聚合、查询等具体功能,可以级联,也可以向外发送数据流。
以上是关于流数据分析平台Storm简介的主要内容,如果未能解决你的问题,请参考以下文章