爬虫学习 ----- 第二章 爬取静态网站 ---------- 02 . re 模块学习 ---- 爬取豆瓣top250
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习 ----- 第二章 爬取静态网站 ---------- 02 . re 模块学习 ---- 爬取豆瓣top250相关的知识,希望对你有一定的参考价值。
1. 【案例】re来爬取 豆瓣top250
信息在 页面源代码中,直接用 re 拿 就行了。
拿着四了数据。


建议找到关键作为起始位置。。之后,往前找一下根目录,



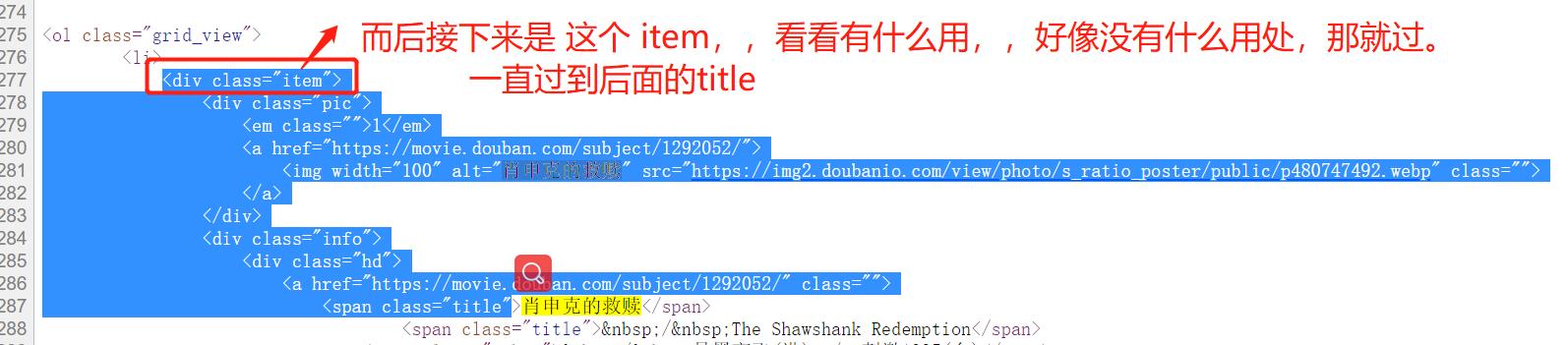

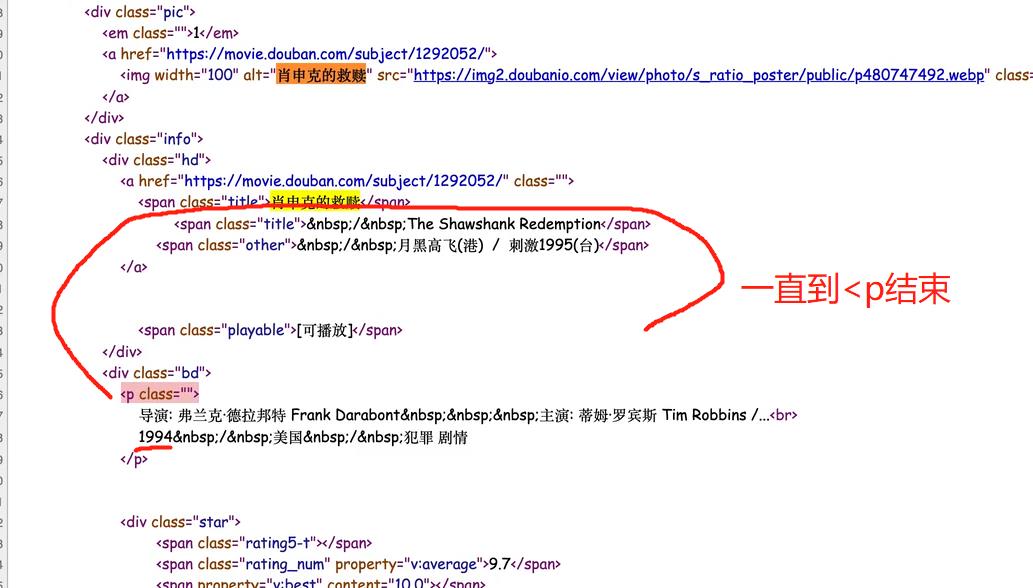
然后再找年份
# -*- coding: utf-8 -*-
# @Time: 2021/5/5 14:05
# @Author: adam
# @File: demo2.py
import re
import requests
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url='https://movie.douban.com/top250'
res = requests.get(url=url,headers=header)
page_content = res.text
# 解析数据 re.S ,使得. 能够匹配包括换行在内的所有字符。
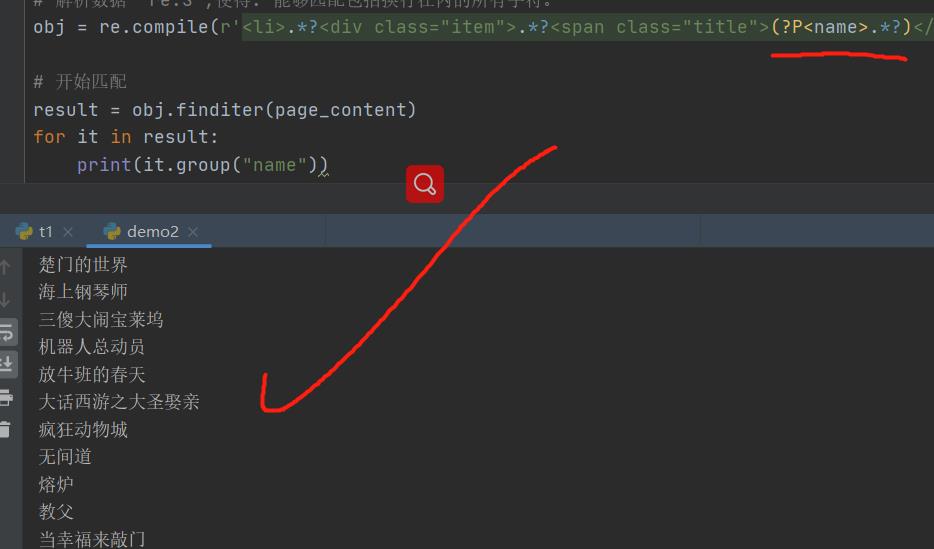
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?(?P<year>\\d+).*?</p>'
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<people>\\d+)人评价</span>',re.S)
# 开始匹配
result = obj.finditer(page_content)
for it in result:
print(it.group("name"),end=' ')
print(it.group("year").strip(),end=' ') # string.strip()
print(it.group('score'),end=' ')
print(it.group("people"))
然后是写入文件中去。
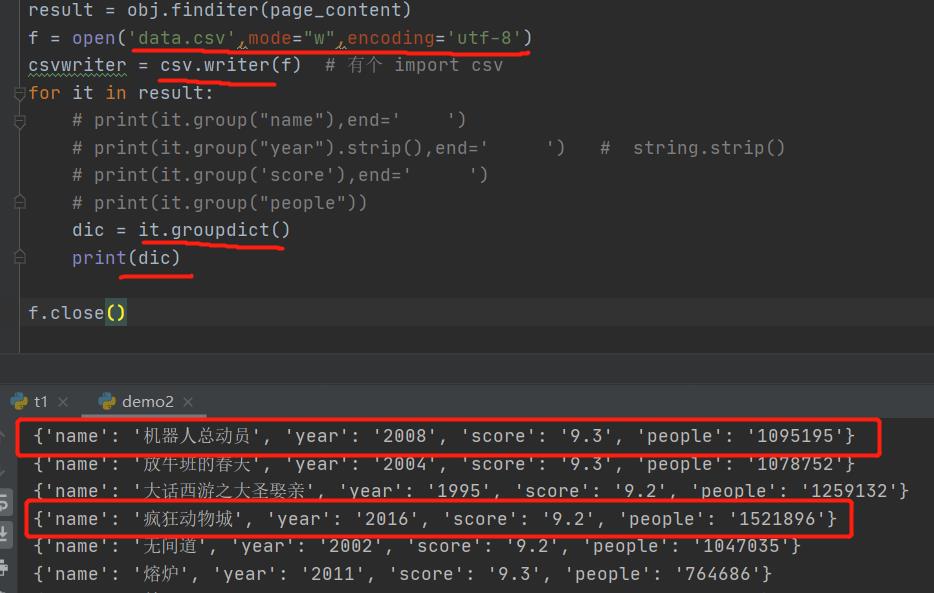
这个迭代器的it的groupdict就是每一个的以字典的形式返回。
然后
# 开始匹配
result = obj.finditer(page_content)
f = open('data.csv',mode="w",encoding='utf-8')
csvwriter = csv.writer(f) # 有个 import csv
for it in result:
# print(it.group("name"),end=' ')
# print(it.group("year").strip(),end=' ') # string.strip()
# print(it.group('score'),end=' ')
# print(it.group("people"))
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values()) # 输出所有value,因为key没用,是我们随便写的
f.close() # 养成好习惯!!
print('over!')
然后,如果某一个数值需要去掉括号的化,可以拿出来然后strip一下就好了。然后看一下data.csv,这个csv自动以逗号为分隔
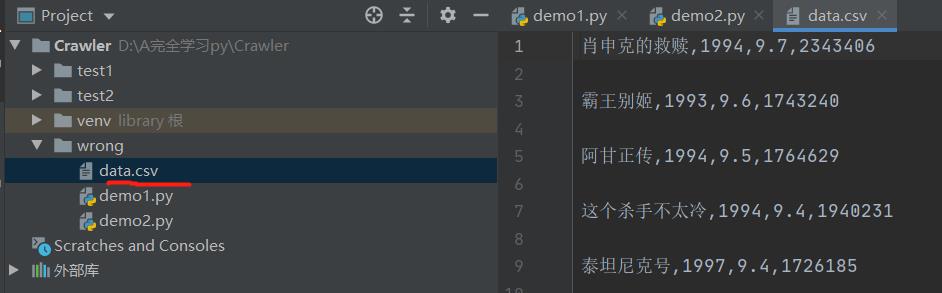
但是25条只是这一片的。然后要换页。
调整参数就可以了

就是换url的参数。
最终的代码:
# -*- coding: utf-8 -*-
# @Time: 2021/5/5 14:05
# @Author: adam
# @File: demo2.py
import csv
import re
import requests
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url='https://movie.douban.com/top250'
res = requests.get(url=url,headers=header)
page_content = res.text
# 解析数据 re.S ,使得. 能够匹配包括换行在内的所有字符。
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?(?P<year>\\d+).*?</p>'
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<people>\\d+)人评价</span>',re.S)
# 开始匹配
result = obj.finditer(page_content)
f = open('data.csv',mode="w",encoding='utf-8')
csvwriter = csv.writer(f) # 有个 import csv
for it in result:
# print(it.group("name"),end=' ')
# print(it.group("year").strip(),end=' ') # string.strip()
# print(it.group('score'),end=' ')
# print(it.group("people"))
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values()) # 输出所有value,因为key没用,是我们随便写的
f.close() # 养成好习惯!!
print('over!')
以上是关于爬虫学习 ----- 第二章 爬取静态网站 ---------- 02 . re 模块学习 ---- 爬取豆瓣top250的主要内容,如果未能解决你的问题,请参考以下文章