举例用Python爬取科目四考试题库的详细方法
Posted yunyun云芸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了举例用Python爬取科目四考试题库的详细方法相关的知识,希望对你有一定的参考价值。
这篇文章仅提供参考
考驾驶证这是多少人的噩梦,小编就惧怕考证,不敢想象“马路女杀手”在我这里会不会升级成“上手车没人没”,我的父亲大人,他用他坚强的毅力连续报考了六次,这中间的过程我不知道是有多残忍,就在去年度过劫难考到证,就差摆一桌庆祝了,啊~艰难的考证之路,进入主题
1、环境
PyCharm

Python 3.6
谷歌浏览器
pip安装的依赖包包括:requests 2.25.0、urllib3 1.26.2、docx 0.2.4、python-docx 0.8.10、lxml 4.6.2

2、目标网站及请求分析
驾驶员考试网站
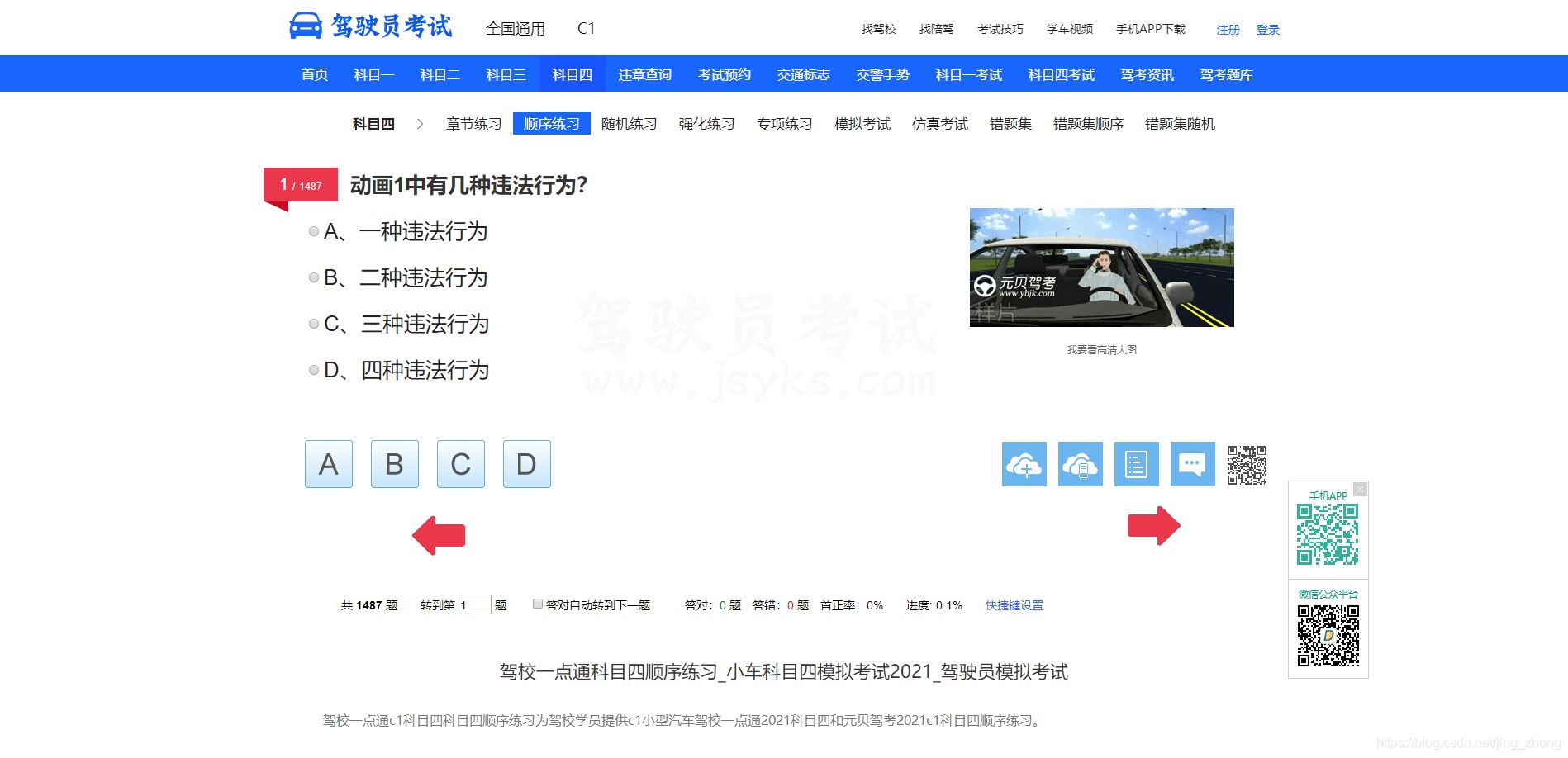
从上图中,可以看到科目四共有1487道题目,为了将所有的题目汇总到一个Word文档中,需要获取到每道题的文本和图片。
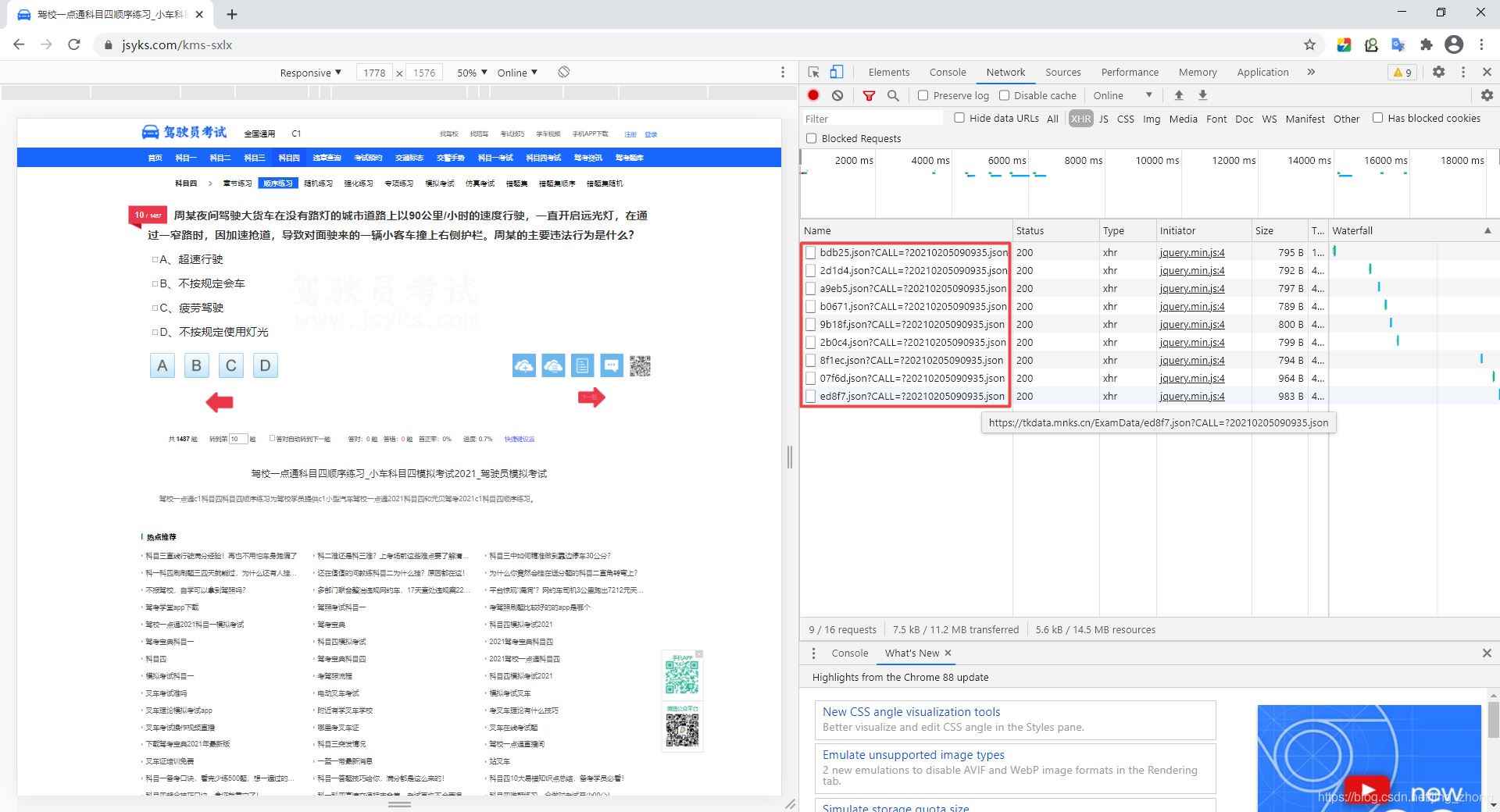
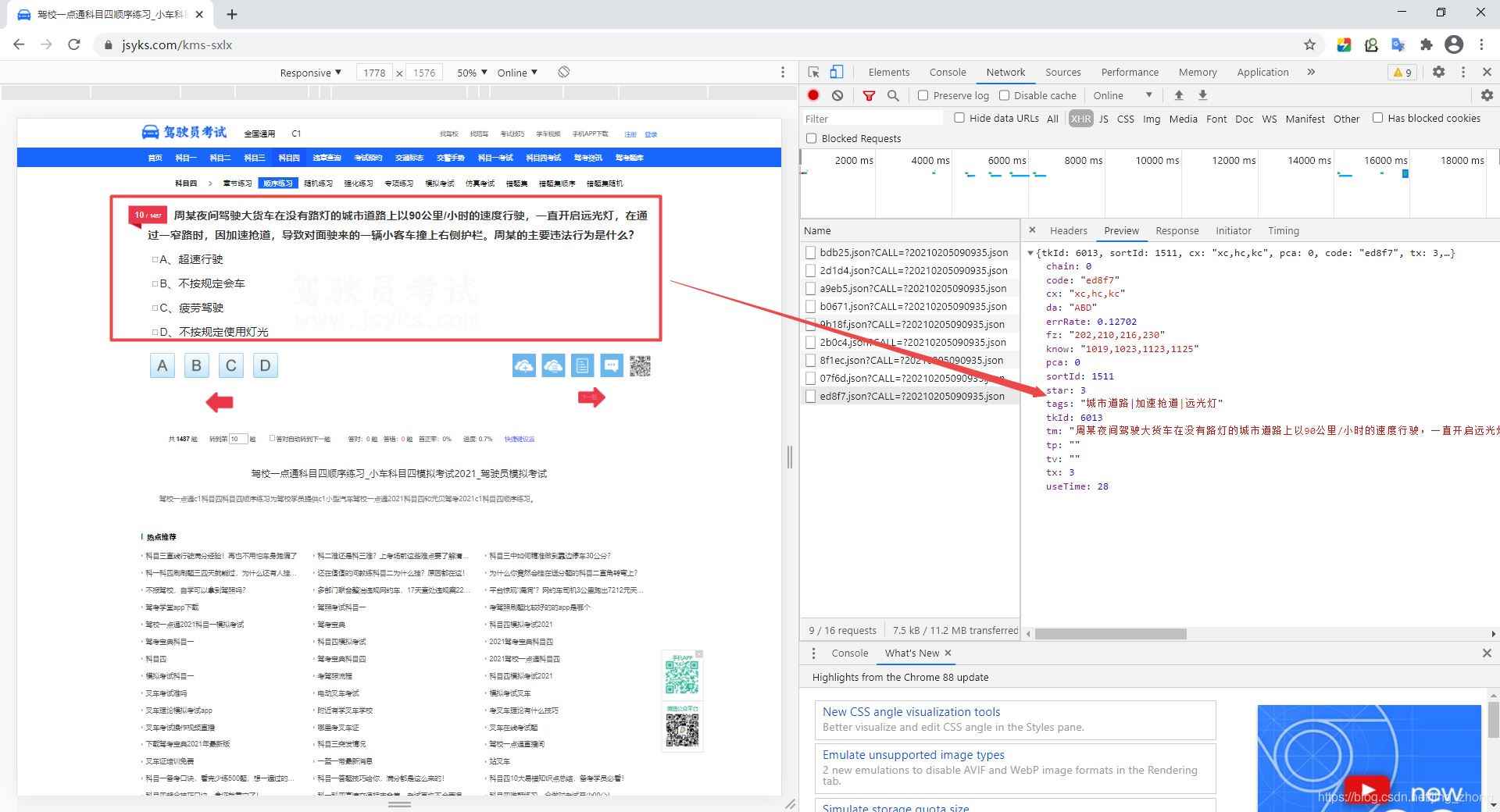
首先,打开谷歌浏览器访问上述网站,键盘按F12,点击Network,点击左侧题目中的向右箭头,一直点击下一道题,不断发起请求,在右侧可以看到每个题目的请求链接中只有五位字符的考试码不一样,所以我们要想办法获取每道题目的考试码。
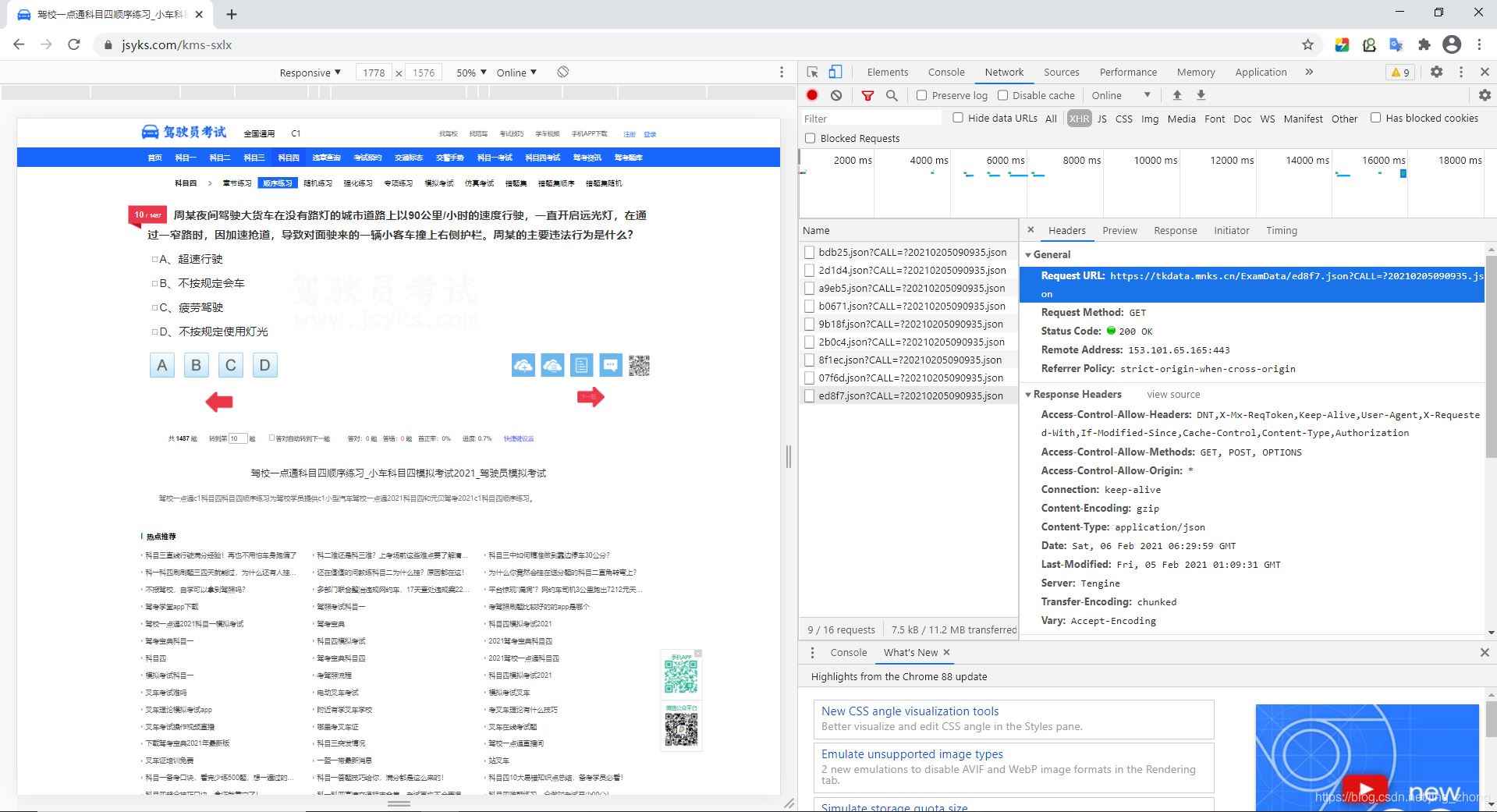
点击其中的一个请求,在Headers中可以看到题目请求的url网址和状态,在Preview中可以看到题目的相关信息。
然后用谷歌浏览器打开上述网站,然后键盘按F12,点击sources,点击左侧Page下tk.mnks.cn下的lianxitix下的文件夹,可以看到Exam的相关变量信息,其中ExamCodes就是1487道题所对应的考试码。
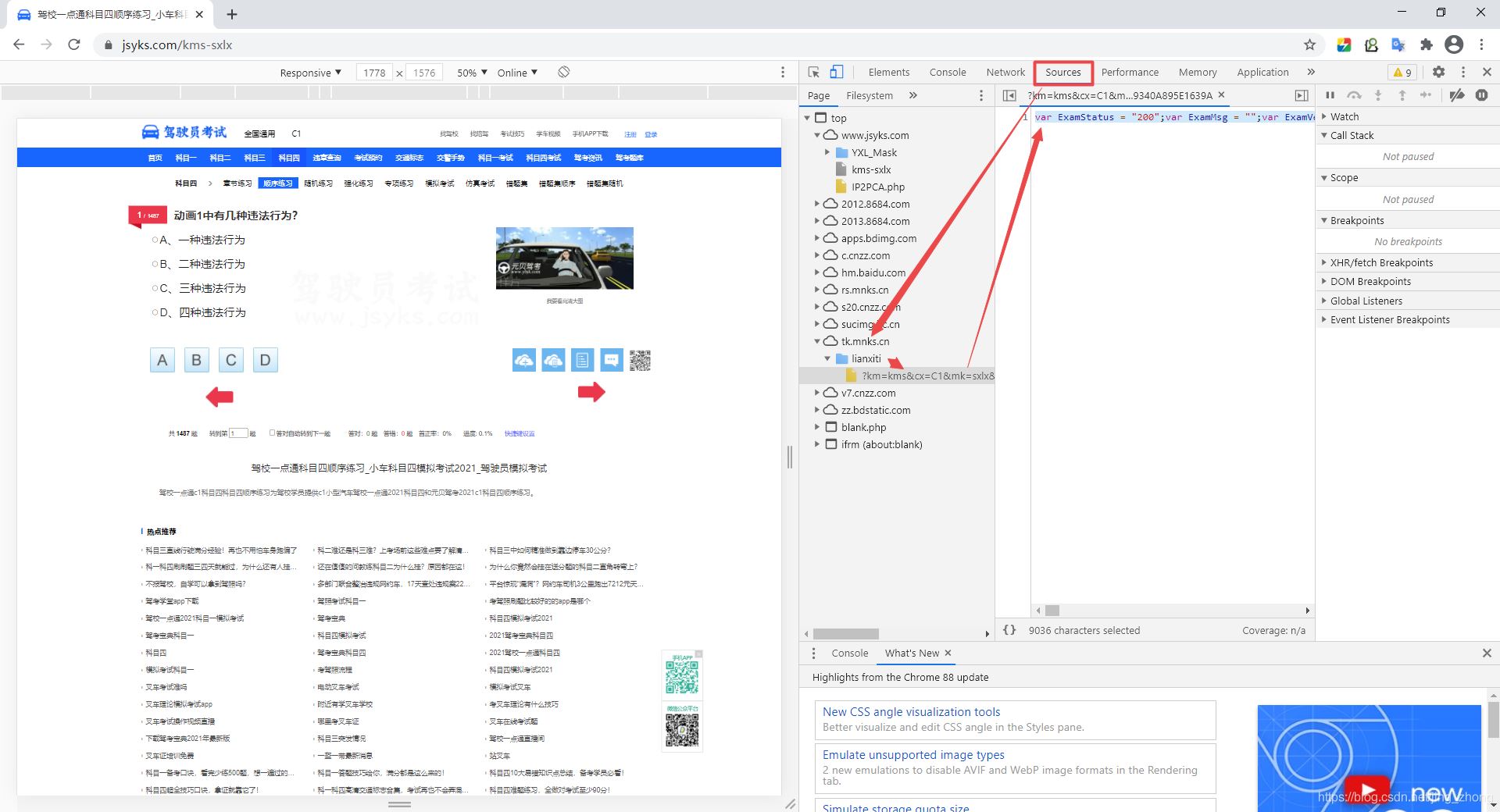
var ExamStatus = "200";
var ExamMsg = "";
var ExamVersion = "20210205090935";
var ExamCount = 1487;
var ExamCodes =
3、Python代码
完整代码如下:
import requests
import time
import urllib.request
import docx
#创建内存中的word文档对象
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
def download_img(img_url,imgname):
request = urllib.request.Request(img_url)
try:
response = urllib.request.urlopen(request)
img_name = imgname+'.gif'
filename = "D:\\\\Program Files (x86)\\\\PyCharm Community Edition 2020.1.1\\\\PaQukemu4tiku\\\\folder\\\\imgpath\\\\" + img_name
if (response.getcode() == 200):
with open(filename, "wb") as f:
f.write(response.read()) # 将内容写入图片
return filename
except:
return "failed"
file = docx.Document()
headers ={
'Connection': 'close'
}
for i in range(0, ExamCount):
ExamCodei=ExamCodes[i]
urlselecti = 'https://tkdata.mnks.cn/ExamData/'+ ExamCodei +'.json?CALL=?20201231143735.json' #选择题
responsei = requests.get(urlselecti, headers=headers,timeout=50,verify=False)
resulti = responsei.json()
ExamTi = resulti['tm'].split('<br/>')
if(len(ExamTi) > 1):
print(str(i+1)+'、'+ExamTi[0] + ' 答案:' + resulti['da'] + '\\n ' + ExamTi[1] + ' ' + ExamTi[2] + ' ' + ExamTi[3] + ' ' + ExamTi[4])
file.add_paragraph(str(i+1)+'、'+ExamTi[0] + ' 答案:' + resulti['da'])
if (resulti['tv'] != ''):
ExamTiimg = resulti['tv'].split('/')
ExamTiimgurl = 'https://sucimg.itc.cn/sblog/' + ExamTiimg[2]
print(ExamTiimgurl)
download_img(ExamTiimgurl, ExamTiimg[2])
paragraph = file.add_paragraph() # 图片居中设置
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
run = paragraph.add_run("")
run.add_picture("D:\\\\Program Files (x86)\\\\PyCharm Community Edition 2020.1.1\\\\PaQukemu4tiku\\\\folder\\\\imgpath\\\\" + ExamTiimg[2] + '.gif')
file.add_paragraph(' '+ExamTi[1] + ' ' + ExamTi[2] + ' ' + ExamTi[3] + ' ' + ExamTi[4])
else:
print(str(i+1)+'、'+resulti['tm'] + ' 答案:' + resulti['da'])
file.add_paragraph(str(i+1)+'、'+resulti['tm'] + ' 答案:' + resulti['da'])
if (resulti['tv'] != ''):
ExamTiimg = resulti['tv'].split('/')
ExamTiimgurl = 'https://sucimg.itc.cn/sblog/' + ExamTiimg[2]
print(ExamTiimgurl)
download_img(ExamTiimgurl, ExamTiimg[2])
paragraph = file.add_paragraph() # 图片居中设置
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
run = paragraph.add_run("")
run.add_picture("D:\\\\Program Files (x86)\\\\PyCharm Community Edition 2020.1.1\\\\PaQukemu4tiku\\\\folder\\\\imgpath\\\\" + ExamTiimg[2] + '.gif')
#time.sleep(1)
file.save("D:\\\\Program Files (x86)\\\\PyCharm Community Edition 2020.1.1\\\\PaQukemu4tiku\\\\folder\\\\C1科目四1487题.docx") #保存
4、运行结果
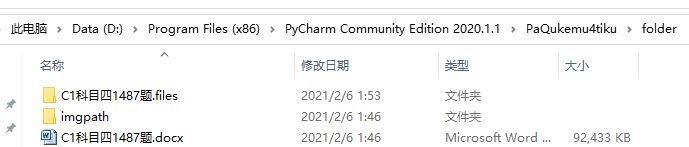
在项目文件夹下folder中imgpath保存所有题目的图片,C1科目四1487题.docx就是运行结果。
打开Word文档进行查看:
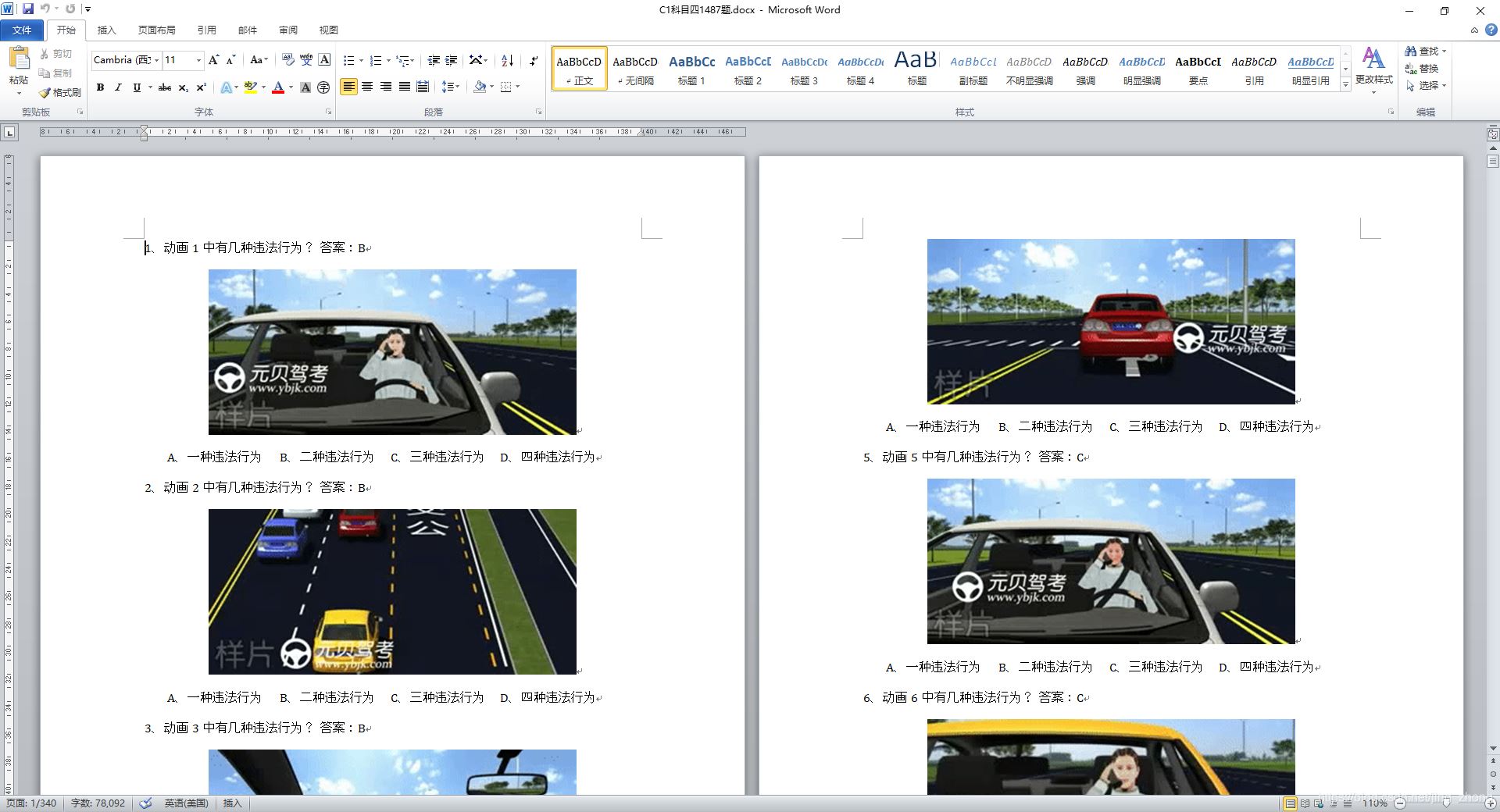
word文档可另存为pdf


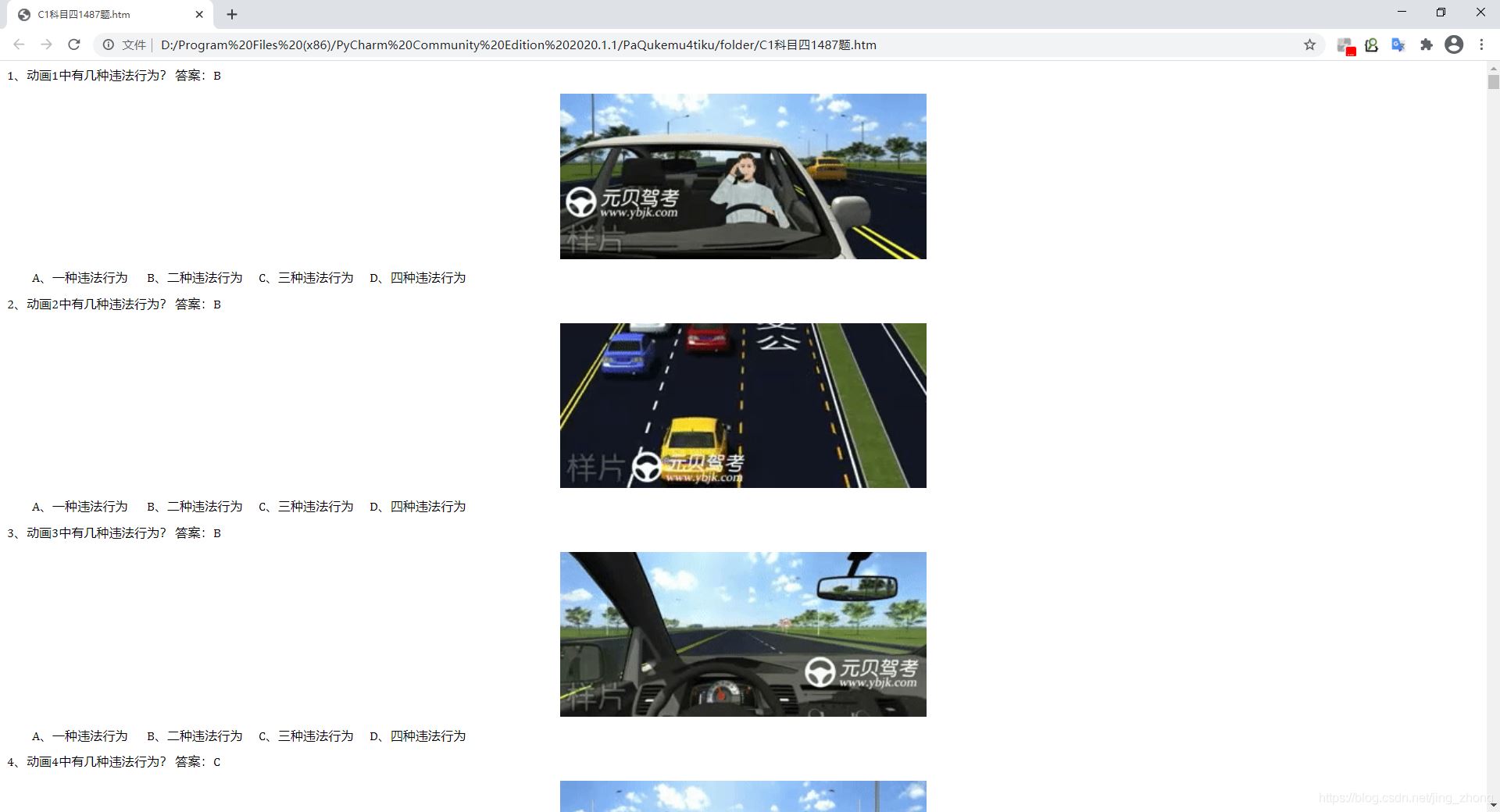
与科目一不同的是,科目四里很多选择题中的图片是动态的GIF图,而不是静态的png,所以题目保存到Word中后图片并不会动态显示,因此,考虑将Word文档另存为网页文件(.html)
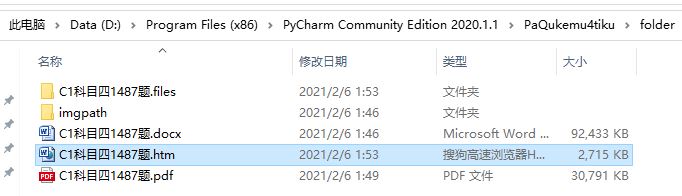
结果(包含动画)如下图所示:

免费:Python资源共享+视频课堂+电子书籍点一下有惊喜
到此这篇关于Python爬取科目四考试题库的方法实现的文章就介绍到这了,祝现在就在考证的朋友们一次就能过关,更多相关Python基础学习资源分享可以看小编主页关注小编。
以上是关于举例用Python爬取科目四考试题库的详细方法的主要内容,如果未能解决你的问题,请参考以下文章