第十一篇:转载-mysql源码分析书籍_MySQL8的代码分析方法
Posted 范先生415
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十一篇:转载-mysql源码分析书籍_MySQL8的代码分析方法相关的知识,希望对你有一定的参考价值。
代码的阅读和分析,可能是程序员日常工作中最高频的工作。从经验上看,我们认为软件代码的分析工作,存在一个普适常用的方法。但对于mysql这种大规模的软件,该方法并不高效。针对该问题,我们团队做了一些思考和调整,提出了新的思路并形成了一个更有效的方法。
在本文第一节,我们先为大家梳理上述普适常用的代码分析方法。随后讨论该方法存在的问题,并介绍linux带给我们的启发,最后介绍我们团队提出的MySQL8代码分析方法。
本文和下一篇文章(MySQL总体架构和运行机制的系统性分析)并不输出MySQL代码的分析结果,而是讨论MySQL代码分析过程中的方法和思路,可以说是MySQL代码分析的分析。之所以有这两篇文章,主要是我们发现MySQL社区有一个令人忧虑的事实,那就是迄今为止对MySQL内核代码的分析好像并没有一个习惯法,而是八仙过海各显神通。从某种意义上说,我们采用的方法也属于过海术中的一种。出于这个专栏定位的考虑(系统性最强,用户体验最好的专栏),我们真诚地把我们的方法整理并分享出来,希望能够引发大家的思考,对大家的内核代码分析起到帮助。
代码分析的常用方法
代码分析的常用方法,具体来说就是从main函数切入,先观其主干,了解每个分支模块的作用、定位和交互,再逐个分支进入,递归梳理子分支最终细读每一行代码,形成对软件代码从全局到局部的全面认识,最后在源码基础上尝试修改、调试和测试,如此反复最终形成熟练掌握,自由修改代码的能力。
相信大部分读者对这个方法都感同身受,我们平时在阅读陌生源码或文献时,或许都会自觉不自觉地使用该方法。该方法的特点是直截了当。它直接将软件源码处理为理解软件运行和修改软件的大型说明书,在只需要一些帮助文档甚至没有任何文档的情况下, 程序员即可展开对软件代码的全面分析,最终吃透和改造代码。
我们认为,这个方法体现了人脑提取信息和知识的一般规律。管理学领域中有一个DIKW金字塔模型,阐述了从 分析文献数据到 获得知识和智慧 的一般过程(下图左)。该模型和我们上述方法有暗合的地方。为了更好的理解这一点,我们参考DIKW金字塔模型,把上述代码分析的常用方法,整理为下图右所示模型:
该模型强调的是从下往上分层次对数据和信息进行提炼,最终实现对代码的掌握。总共分4个层次:
代码(Code):原始的代码,在未被程序员分析之前,只是存储在磁盘的,冷冰冰的一堆数据。结构(Structure):程序员根据自己的经验和能力,从原始代码中提取的结构化信息,包括:软件的总体架构(子模块的组成结构)、子模块间的接口和交互流程、各模块的核心数据结构、核心算法和主要流程等。思路和方案(Ideas&Solutions):对结构化信息做进一步梳理,重点是发现信息之间的相关性,建立信息和信息之间的联系,最终搞清楚软件设计师在软件架构设计上的思路和方案,以及各模块编程人员在模块实现上的思路和方案,达到透彻理解软件作者面对的问题、解决思路和解决方案的目的。能力(Ability):在理解软件作者面对的问题、思路和方案的基础上,通过改造、调试和测试代码,修复软件bug和添加新功能,最终将软件作者的思路和方案内化为程序员自己的能力,能够熟练掌握、自如修改软件源码。
常用方法的问题
对于小规模的代码,比如Haproxy、ProxySQL等,常用方法是有效的, 但对于MySQL8这样大规模的软件,该方法便不再可行。
究其原因,在于MySQL8代码的规模上来了,代码的信息量突破了人脑所能处理的极限。上述模型的核心思路是通过人脑自然的梳理,先从上往下识别子模块得到总体架构,然后以子模块为单位逐层提炼信息(所谓先把书读厚,再把书读薄)。小规模的代码信息量少,较容易通过程序员自然的阅读理解,从原始代码中提炼出总体架构和子模块内部的数据结构、算法、主要流程等结构化信息, 也较容易发结构化现信息之间的相关性和联系,进而提炼出软件作者的思路和方案,最终获得自如修改代码的能。
但是对于大规模软件,由于代码量巨大, 要从 main 函数入手,在没有文档的帮助下梳理出软件总体架构就很难。假如程序员想尽一切办法把总体架构搞明白了, 众多子模块包括巨大的信息量,提炼子模块内部的结构化信息(数据结构、算法、主要流程等)又将耗费大量时间。即使程序员把各子模块信息给梳理清楚后,得出的信息也是海量的。由于信息的海量,通过人脑来把这些信息读薄,最终领悟软件作者在设计和编码时的面对的问题、思路和解决方案,也变得很难。
综上我们得出的结论是,依靠自然的阅读理解去吃透MySQL代码是不可行的(这好像是一句正确的废话)。
linux的启发
同样作为大型基础软件,隔壁linux是什么情况呢?相比我们学习MySQL内核时的苦哈哈,linux提供给新人的学习路线要好得多。最主要的优点,是社区文档的齐全(甚至是奢侈)。比如多年前就已经出版的linux kernel 四库全书这样的经典书籍, 而且这些书籍还随着linux版本的升级不断迭代,最近几年甚至出现了付费的视频课程和技术专栏,妥妥地把原本枯燥硬核的linux内核知识,捣碎锤烂然后直接喂给程序员的节奏。在这些资料的帮助下,程序员可逐渐理解和吃透linux总体架构和核心运行机制, 最后根据工作需要选择性掌握某些子模块的代码,锻炼出自如改造的能力。
我们不妨来看下,程序员在拥有了linux社区豪华配置的内核文档后,可以怎么循序渐进来掌握linux内核代码。下图是某linux内核学习专栏提供的linux内核学习路线图:
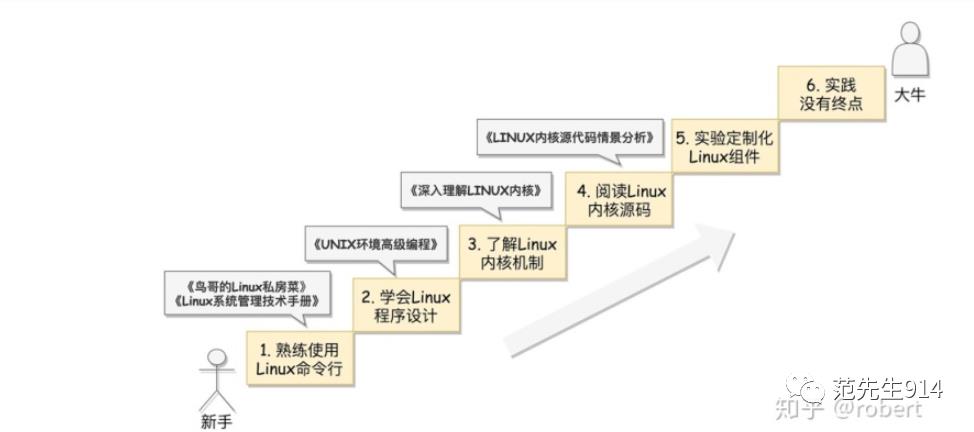
所以,得益于linux社区的系统性文档,程序员在学习linux内核时不仅有代码之外更多的参考,更重要的是众多的,在不同层次和问题各有侧重的文档铺就了从熟悉linux使用 -> 理解linux总体架构和运行机制 -> 深入掌握某个子模块代码 -> 子模块定制化开发 这一条升级之路。
但MySQL内核代码的学习不存在这一条路线。主要原因并不是MySQL社区的内核分析文档少了,而是系统性不够,特别是缺少对总体架构和运行机制做系统性分析的文档。过去二十年来,业界有很多内核开发和DBA同学,都在认真地编写和输出内核分析文档,其中不少具有很高的质量。但这些文档大都是以某一个功能点或者子模块的深度分析为主,MySQL系统性的总体架构梳理和运行机制分析目前还没有。
如果存在一份对MySQL总体架构和运行机制做系统性分析的文档,我们就可以干两件事情:
1.以这些文档为指南,可以根据源码去深入分析某个子模块,吃透并掌握子模块代码;
2.以这些文档为抓手,可以更系统地索引MySQL社区现有的,针对子模块/子功能的源码分析文档。
有了这个文档就补齐了MySQL社区在内核文档上的短板,新人学习MySQL的路线图,就能够和linux一样循序渐进:
我们的MySQL8代码分析方法
虽然目标我们是清楚了,但要真正执行时依然需要解决很多问题。第一个问题是:MySQL总体架构和运行机制的系统性分析到底该怎么界定?分析文档里面需要包含什么内容,才能上承我们在日常基于做MySQL开发和运维云数据库产品时积累的MySQL使用知识,下接MySQL社区的专业子模块/子功能分析文档?
这看似是一个宏大难解的问题,但必然能够在现实中寻找到答案。如果把把软件的源码分析流程,作为软件开发流程的逆过程。那么在经典的瀑布式软件开发模型中,软件开发流程分为需求分析、概要设计、详细设计、编码共四个阶段:

当然,真实的软件开发过程,大部分情况下绝不是瀑布式开发模型所描绘的那么简单。正如Frederick Brooks在《设计原本》(The Design of Design: Essays from a Computer Scientist) 一书中所批评的(第3章,第4章)。但当我们面对一个凝固的软件代码做分析时,仍然可以将软件产生的过程简化为这4个简单阶段,进而反推出代码分析需要经过的4个阶段:
由此我们的 MySQL总体架构和运行机制的系统性分析 工作目标就更加明确了:其实就是逆向求解MySQL在概要设计阶段的输出。为了更系统性地说明这一点,我们尝试定义了上述4个阶段每个阶段的工作内容,从而更方便读者理解 MySQL总体架构和运行机制的系统性分析 这个工作:
1.功能和概念熟悉:是软件开发流程需求分析的逆过程。在这个阶段,我们主要是站在用户角度去深度使用MySQL,并吃透MySQL中的核心概念,深入了解每个概念的含义。
2.总体架构梳理和核心运行机制分析:是软件开发流程概要设计的逆过程。在这个阶段,我们在独立思考的基础上, 通过阅读社区内核分析文档、源码、动手调试等方法,大胆假设小心求证, 最终梳理出MySQL的总体架构,并对MySQL的核心运行机制达成透彻理解。通过总体架构的梳理和核心运行机制分析,我们勾勒出了MySQL的各模块组成,明确了模块的定位和模块间的接口,为后续分模块的详细架构分析打下基础;通过核心运行机制的分析,我们掌握了MySQL中主要的数据对象、内存组织和磁盘文件组织,以及处理主要的几种SQL语句时,如何分别操作内存和磁盘文件中这些数据对象。运行机制的分析让我们能够拆开MySQL这个黑盒,像观察水流运行一样,观察MySQL的数据流动和各处理逻辑。
我们找到了较好一个隐喻,就是把MySQL理解为长江流域水系。总体架构的梳理能够刻画出MySQL的静态结构,运行机制分析就是沿着各干流的做一次次漂流过程。两者动静结合,深刻揭示了MySQL的内部构成和运行机制。为后面以子模块单位做详细分析打下基础。
3.各子模块的详细结构分析:是软件开发流程的详细设计的逆过程。在这个阶段,我们以第二阶段得出的总体架构和运行机制为基础,深入到各子模块,提炼该模块的数据结构、算法、主干流程等,然后深度理解作者当时面对的问题、解决思路和方案。
4.掌握和改造子模块代码:是软件开发流程编码和测试阶段的逆过程。该阶段将详细梳理和吃透子模块的每一行代码,并通过不断实践(改造、调试和测试代码,修复软件bug和添加新功能),实现熟练掌握,自如修改子模块代码的能力。
通过对代码分析4个流程的介绍,相信帮助读者加深了 MySQL总体架构和运行机制的系统性分析 这一工作的内容。但对这个工作的介绍才刚刚开始。我们在下一篇文章中,将详细介绍在这个工作中,我们面对浩瀚的MySQL源码和社区不系统的内核分析文档,做了哪些思考,解决了哪些问题。随后将推出一系列文档,详细介绍MySQL的总体架构和运行机制。希望对读者的MySQL内核分析工作有所帮助。
两种方法的结合
本文介绍了两种代码的分析方法,分别是小规模软件的自然阅读方法(常用方法),和我们受linux启发的MySQL8代码分析方法。其实两种方法并不是天然对立,而是结合在一起。在上一节对我们方法的4阶段的介绍中,或许你已经看出,第3、4阶段合在一起, 其实就是一个采用常用方法来分析子模块代码的完整过程。至此,两个方法(我们的方法和第一节所述的代码分析常用方法)实现了完美的对接。而到此,我们也可以再做一番审视和思考:
1.程序员日常工作中常用的代码分析方法,是一个自下而上的归纳法。代码分析过程是不断归纳和提炼信息的过程(从原始代码 -> 结构化信息 -> 高阶信息或知识->能力)。
2.我们的MySQL8代码分析方法,是一个自上而下的演绎法。其中最重要的是大胆假设,小心求证。MySQL8的总体架构要梳理到什么粒度,子模块和子模块的边界怎么确定,运行时机制要了解哪些以及了解到什么程度,MySQL社区之前并没有人做过系统性的梳理,每迈出一步,都需要先做大胆假设,然后小心求证,并不断调整。但是总体架构和运行时机制一旦确定和明确,则后面对各子模块的分析,就可以采用常用的代码分析方法,因为复杂度已经下降了。
总结一下就是:由于MySQL8代码的大规模,单纯采用常用方法并不可行。所以先采用演绎法,自上而下得推导出一个总体架构,并基于该架构的指导分析MySQL的核心运行机制,然后以子模块为单位,采用归纳法梳理和提炼,最终根据研发需求分子模块吃透代码并改造,对于不需要改造的子模块,则只需要了解其定位,以及和其他子模块的接口即可。
以上是关于第十一篇:转载-mysql源码分析书籍_MySQL8的代码分析方法的主要内容,如果未能解决你的问题,请参考以下文章
第十一篇:Spark SQL 源码分析之 External DataSource外部数据源