使用Python+OpenCV+Keras创建自己的图像分类模型
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python+OpenCV+Keras创建自己的图像分类模型相关的知识,希望对你有一定的参考价值。
介绍
你是否曾经偶然发现一个数据集或图像,并想知道是否可以创建一个能够区分或识别图像的系统?
图像分类的概念将帮助我们解决这个问题。图像分类是计算机视觉最热门的应用之一,是任何想在这个领域工作的人都必须知道的概念。
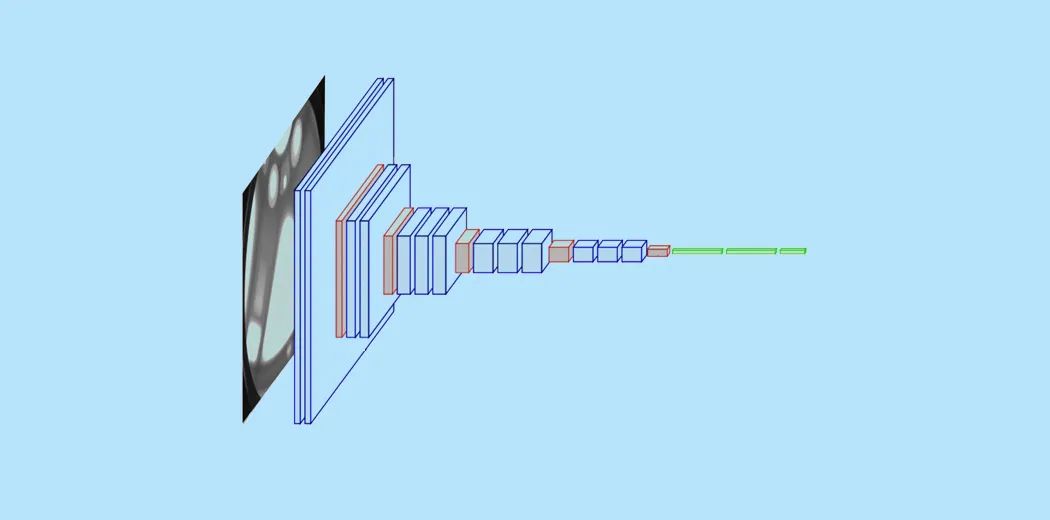
在本文中,我们将看到一个非常简单但使用频率很高的应用程序,那就是图像分类。我们不仅将看到如何使一个简单和有效的模型分类数据,而且还将学习如何实现一个预先训练的模型,并比较两者的性能。
在本文结束时,你将能够找到自己的数据集并轻松实现图像分类。
先决条件:
Python编程
Keras及其模块
基本了解图像分类
卷积神经网络及其实现
迁移学习的基本认识
听起来有趣吗?准备创建你自己的图像分类器吧!
目录
图像分类
理解问题陈述
设置图像数据
让我们构建我们的图像分类模型
数据预处理
数据扩充
模型定义和训练
评估结果
迁移学习的艺术
导入基础MobileNetV2模型
微调
训练
评估结果
下一步是什么?
什么是图像分类?
图像分类是分配输入图像(一组固定类别中的一个标签)的任务。这是计算机视觉的核心问题之一,尽管它很简单,却有各种各样的实际应用。
让我们举个例子来更好地理解。当我们进行图像分类时,我们的系统将接收图像作为输入,例如,一只猫。现在,系统将已知一组类别,它的目标是为图像分配一个类别。
这个问题似乎很简单,但对于计算机来说却是一个很难解决的问题。你可能知道,电脑看到的是一组数字,而不是我们看到的猫的图像。图像是由0到255的整数组成的三维数组,大小为宽x高x 3。3代表红色、绿色、蓝色三个颜色通道。
那么我们的系统如何学习识别这幅图像呢?通过卷积神经网络。卷积神经网络(CNN)是深度学习神经网络的一种,是图像识别领域的巨大突破。到目前为止,你可能已经对CNN有了一个基本的了解,我们知道CNN由卷积层、Relu层、池化层和全连接层组成。
要阅读关于图像分类和CNN的详细信息,你可以查看以下资源:
https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
现在我们已经理解了这些概念,让我们深入了解如何构建和实现图像分类模型。
理解问题陈述
考虑下面的图像:

一个精通体育运动的人可以认出橄榄球的形象。图像的不同方面可以帮助你识别它是橄榄球,它可以是球的形状或球员的服装。但你有没有注意到,这张照片很可能是一个足球形象?
让我们考虑另一张图片:

你认为这个图像代表什么?很难猜对吧?对于没有受过训练的人来说,这幅图像很容易被误认为是足球,但实际上,这是橄榄球的图像,因为我们可以看到后面的球门柱不是网,而且尺寸更大。现在的问题是,我们能否建立一个能够正确分类图像的系统。
这就是我们项目背后的想法,我们想要建立一个系统能够识别图像中所代表的运动。这里分为橄榄球和足球两大类。问题陈述可能有点棘手,因为体育运动有很多共同的方面,尽管如此,我们将学习如何解决问题,并创建一个良好的表现系统。
设置我们的图像数据
由于我们正在处理一个图像分类问题,我使用了两个最大的图像数据源,即ImageNet和谷歌OpenImages。我实现了两个python脚本,我们可以轻松地下载图像。一共下载了3058张图片,分为train和test两部分。我用训练文件夹有2448张图片,测试文件夹有610张图片,进行了80-20的分割。橄榄球和足球两个类别各有1224张图片。
我们的数据结构如下:
输入 3058
橄榄球 - 310
足球 - 310
橄榄球 - 1224
足球 - 1224
训练 - 2048
测试 - 610
我们来建立我们的图像分类模型!
步骤1: 导入所需的库
这里,我们将使用Keras库来创建模型并对其进行训练。我们还使用Matplotlib和Seaborn来可视化我们的数据集,以便更好地理解我们将要处理的图像。另一个处理图像数据的重要库是Opencv。
import matplotlib.pyplot as plt
import seaborn as sns
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D , MaxPool2D , Flatten , Dropout
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from sklearn.metrics import classification_report,confusion_matrix
import tensorflow as tf
import cv2
import os
import numpy as np
步骤2: 加载数据
接下来,让我们定义数据的路径。让我们定义一个名为get_data()的函数,它使我们更容易创建我们的训练和验证数据集。我们定义了我们将要使用的两个标签“Rugby”和“Soccer”。我们使用Opencv imread函数读取RGB格式的图像,并将图像大小调整到我们想要的宽度和高度(在本例中都是224)。
labels = ['rugby', 'soccer']
img_size = 224
def get_data(data_dir):
data = []
for label in labels:
path = os.path.join(data_dir, label)
class_num = labels.index(label)
for img in os.listdir(path):
try:
img_arr = cv2.imread(os.path.join(path, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([resized_arr, class_num])
except Exception as e:
print(e)
return np.array(data)
Now we can easily fetch our train and validation data.
train = get_data('../input/traintestsports/Main/train')
val = get_data('../input/traintestsports/Main/test')
步骤3: 可视化数据
让我们可视化我们的数据,看看我们到底在使用什么。我们使用seaborn来绘制这两个类中的图像数量,你可以看到输出是什么样的。
l = []
for i in train:
if(i[1] == 0):
l.append("rugby")
else
l.append("soccer")
sns.set_style('darkgrid')
sns.countplot(l)
输出:

让我们可视化来自橄榄球和足球的随机图像:
plt.figure(figsize = (5,5))
plt.imshow(train[1][0])
plt.title(labels[train[0][1]])
输出:
足球图片也应用相同操作:
plt.figure(figsize = (5,5))
plt.imshow(train[-1][0])
plt.title(labels[train[-1][1]])
输出:

步骤4: 数据预处理和数据增强
接下来,在继续构建模型之前,我们执行一些数据预处理和数据增强。
x_train = []
y_train = []
x_val = []
y_val = []
for feature, label in train:
x_train.append(feature)
y_train.append(label)
for feature, label in val:
x_val.append(feature)
y_val.append(label)
# Normalize the data
x_train = np.array(x_train) / 255
x_val = np.array(x_val) / 255
x_train.reshape(-1, img_size, img_size, 1)
y_train = np.array(y_train)
x_val.reshape(-1, img_size, img_size, 1)
y_val = np.array(y_val)
对训练数据的数据增强:
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range = 30, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip = True, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(x_train)
步骤5: 定义模型
让我们定义一个简单的CNN模型,有3个卷积层,然后是max-pooling层。在第3次maxpool操作后添加一个dropout层,以避免过度拟合。
model = Sequential()
model.add(Conv2D(32,3,padding="same", activation="relu", input_shape=(224,224,3)))
model.add(MaxPool2D())
model.add(Conv2D(32, 3, padding="same", activation="relu"))
model.add(MaxPool2D())
model.add(Conv2D(64, 3, padding="same", activation="relu"))
model.add(MaxPool2D())
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128,activation="relu"))
model.add(Dense(2, activation="softmax"))
model.summary()
现在让我们使用Adam作为优化器,SparseCategoricalCrossentropy作为损失函数来编译模型。我们使用较低的学习率0.000001来获得更平滑的曲线。
opt = Adam(lr=0.000001)
model.compile(optimizer = opt , loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) , metrics = ['accuracy'])
现在,让我们训练我们的模型500个epochs,因为我们的学习速率非常小。
history = model.fit(x_train,y_train,epochs = 500 , validation_data = (x_val, y_val))
步骤6: 评估结果
我们将绘制我们的训练和验证的准确性以及训练和验证的损失。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
让我们看看曲线是怎样的-

我们可以打印出分类报告,看看精度和准确性。
predictions = model.predict_classes(x_val)
predictions = predictions.reshape(1,-1)[0]
print(classification_report(y_val, predictions, target_names = ['Rugby (Class 0)','Soccer (Class 1)']))
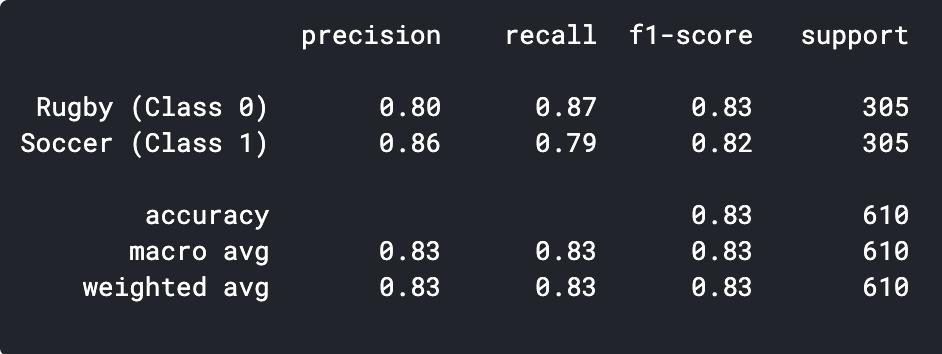
我们可以看到,我们简单的CNN模型能够达到83%的准确率。通过一些超参数调整,我们或许可以提高2-3%的精度。
我们还可以将一些预测错误的图像可视化,看看我们的分类器哪里出错了。
迁移学习的艺术
我们先来看看迁移学习是什么。迁移学习是一种机器学习技术,在一个任务上训练的模型被重新用于第二个相关的任务。迁移学习的另一个关键应用是当数据集很小的时候,通过在相似的图像上使用预先训练过的模型,我们可以很容易地提高性能。既然我们的问题陈述很适合迁移学习,那么让我们看看我们可以如何执行一个预先训练好的模型,以及我们能够达到什么样的精度。
步骤1: 导入模型
我们将从MobileNetV2模型创建一个基本模型。这是在ImageNet数据集上预先训练的,ImageNet数据集是一个包含1.4M图像和1000个类的大型数据集。这个知识库将帮助我们从特定数据集中对橄榄球和足球进行分类。
通过指定参数 include_top=False,可以加载一个不包含顶部分类层的网络。
base_model = tf.keras.applications.MobileNetV2(input_shape = (224, 224, 3), include_top = False, weights = "imagenet")
在编译和训练模型之前冻结基础模型是很重要的。冻结后将防止我们的基础模型中的权重在训练期间被更新。
base_model.trainable = False
接下来,我们使用base_model定义模型,然后使用GlobalAveragePooling函数将每个图像的特征转换为单个矢量。我们添加0.2的dropout和最终的全连接层,有2个神经元和softmax激活。
model = tf.keras.Sequential([base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(2, activation="softmax")
])
接下来,让我们编译模型并开始训练它。
base_learning_rate = 0.00001
model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(x_train,y_train,epochs = 500 , validation_data = (x_val, y_val))
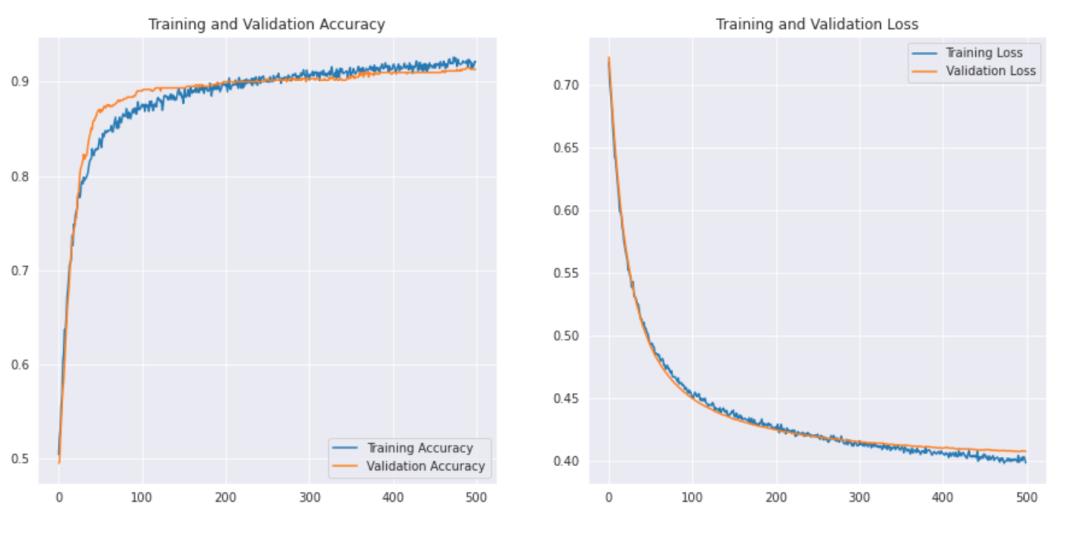
步骤2: 评估结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(500)
plt.figure(figsize=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
让我们看看曲线是怎样的-
我们也打印一下分类报告,以便得到更详细的结果。
predictions = model.predict_classes(x_val)
predictions = predictions.reshape(1,-1)[0]
print(classification_report(y_val, predictions, target_names = ['Rugby (Class 0)','Soccer (Class 1)']))
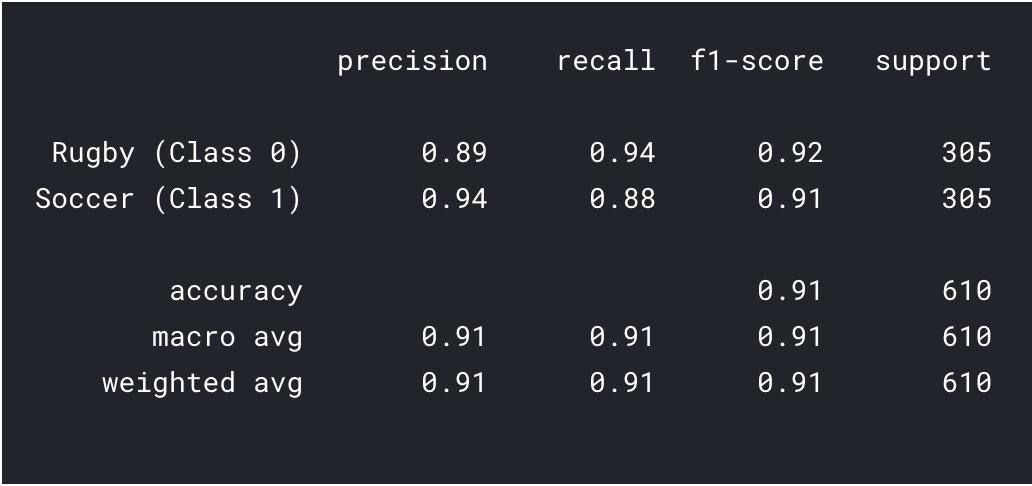
我们可以看到,通过迁移学习,我们可以得到更好的结果。橄榄球和足球的精度都高于我们的CNN模型,而且总体精度达到了91%,这对于这样一个小数据集来说是非常好的。通过一些超参数调优和更改参数,我们也可以获得更好的性能!
下一步是什么?
这只是计算机视觉领域的起点。事实上,试着改进你的基础CNN模型来匹配或超过基准性能。
你可以从VGG16等的架构中学习超参数调优的一些线索。
你可以使用相同的ImageDataGenerator来增强图像并增加数据集的大小。
此外,你还可以尝试实现更新和更好的架构,如DenseNet和XceptionNet。
你也可以移动到其他的计算机视觉任务,如目标检测和分割,你将意识到这些任务也可以简化为图像分类。
总结
祝贺你已经学习了如何创建自己的数据集、创建CNN模型或执行迁移学习来解决问题。我们在这篇文章中学到了很多,从学习寻找图像数据到创建能够实现合理性能的简单CNN模型。我们还学习了迁移学习的应用,进一步提高了我们的绩效。
这还没有结束,我们看到我们的模型错误分类了很多图像,这意味着仍然有改进的空间。我们可以从寻找更多的数据开始,甚至实现更好的、最新的架构,以便更好地识别特性。
觉得还不错就给我一个小小的鼓励吧!
以上是关于使用Python+OpenCV+Keras创建自己的图像分类模型的主要内容,如果未能解决你的问题,请参考以下文章