webpack 源码分析系列 ——loader
Posted 茂树24
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了webpack 源码分析系列 ——loader相关的知识,希望对你有一定的参考价值。
想要更好的格式阅读体验,请查看原文:webpack 源码分析系列 ——loader
为什么需要 loader
webpack是一个用于现代 javascript 应用程序的静态模块打包工具。内部通过构建依赖图管理模块之间的依赖关系,生成一个或多个 bundle 静态资源。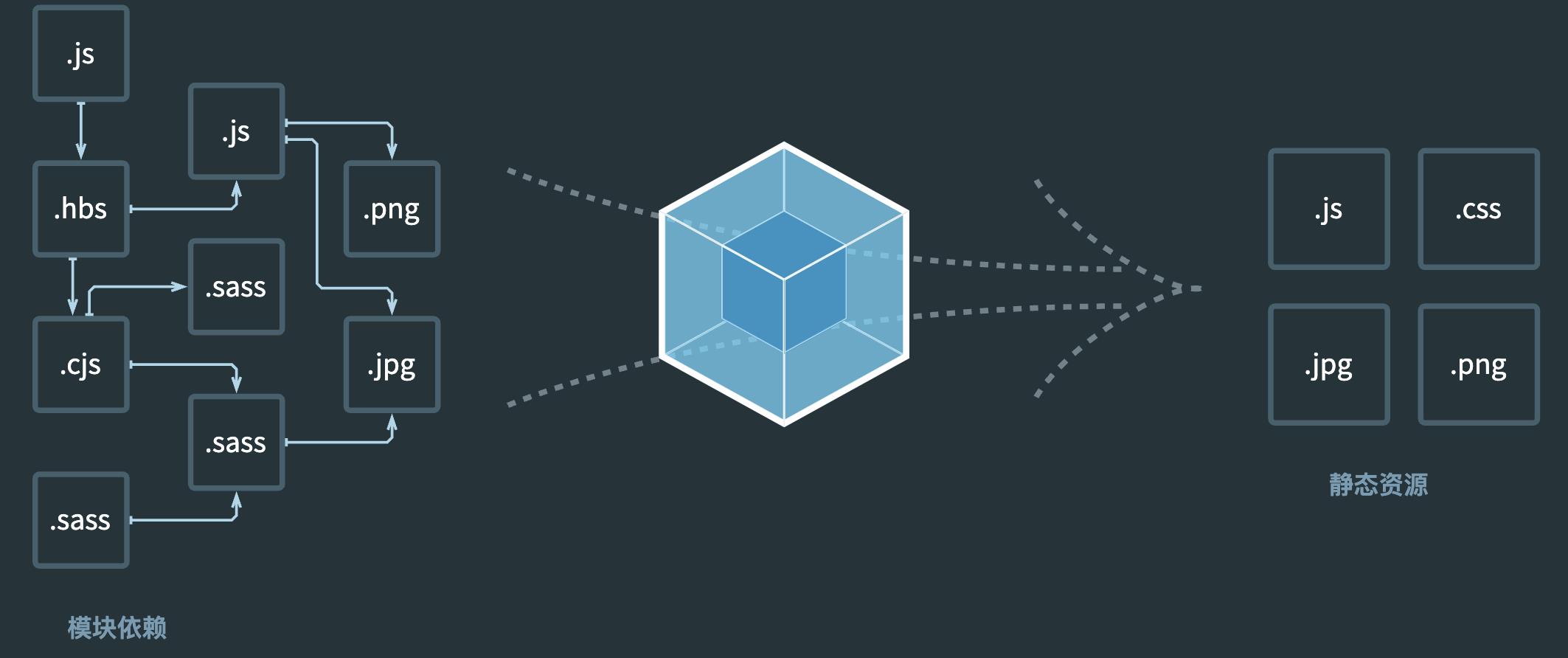
但是 webpack 只能处理 JavaScript 、Json 模块。应用程序除了JavaScript 、Json 模块以外还有图片、音频、字体等媒体资源、less、sass 等样式文件等非 js 代码的模块。所以需要一种能力,将非 js 资源模块解析成能够被 webpack 管理的模块。这也就是 loader 的作用。
举个例子,比如对于 less 样式文件来说,在 webpack 配置文件中如果处理 index.less 文件会经过 less-loader、css-loader、style-loader 处理,如下代码所示:
module.exports = {
module: {
rules: [
{
test: /\\.less$/,
use: ['style-loader', 'css-loader', 'less-loader']
}
]
}
};
webpack 解析到 index.less 模块的时候,首先会使用类似于 fs.readFile 去读取文件并且获取到文件内的源代码文本 source;拿到的 source 是需要去经过 js parser 转成 ast 的,但是在这之前会去 webpack 配置的 loader 中看看是否有处理该文件的 loader,发现有 [‘style-loader’, ‘css-loader’, ‘less-loader’] 三个 loader 按照顺序去处理的,所以 webpack 会将 source 源码以及 loader 处理器 交给 loader-runner 这个 loader 处理库,处理库会对源文件按照一定的规则经过层层 loader 进行加工处理,最终得到 webpack 可以识别的模块;然后转成 ast 进行进一步的处理,比如分析 ast ,收集模块的依赖,直到将依赖链路分析完毕为止。
到此为止应该知道 index.less 源文件会经过 三个 loader 按照一定的规则处理后得到 js 模块。那三个 loader 都是干了什么事情使得可以从样式文件转成 js 文件呢?
首先会将 source 作为入参经过 less-loader 处理,less-loader 能够将 less 代码经过 less 解析生成器 转化成 css 代码。当然转化后的 css 代码也是不能直接使用的,因为在 css 中会存在 import 依赖其他的 css 文件。
将 less-loader 解析后的 css 代码传入到 css-loader 中,在 css-loader 中会使用 css parser 解析也就是 postcss 解析 css,比如会将 import 解析成 js 中 require 的形式来引用其他的样式资源,同时还会将 css 代码转化成字符串, 通过 module.exports 抛出,此时已经将 css 文件转成了 js 模块,webpack 能够处理了。但是还不能使用,因为并没有作为 style 标签中被引用。所以需要经过 style-loader 处理。
将 css-loader 解析后的 js 代码 传入到 style-loader 中,经过 loader-utils 中路径转化函数对 require 路径处理,添加创建 style 标签, 以及将 require 引用的代码赋值给 innerhtml 中,这样,得到一段 js 代码,代码中包含了经过 style-loader 添加的 创建 style 标签内容,标签的内容是经过 css-loader 处理的将 css 解析成 js 代码, 同时 less-loader 将 less 文件解析成了 css。然后就将 less 模块解析成了 js 模块,webpack 就会后续的统一管理了。
这就是 webpack 处理 less 文件成 js 文件的过程, 但是这才是一小部分,如果能够真的可以使用还需要很多的路要走,不过不是这篇文章的重点了。到此应该大概的了解了 webpack 中 loader 是什么作用以及为什么需要 laoder 了。简单的来说,loader 就是处理module(模块、文件)的,能够将 module 处理成 webpack 能够解析的样子,同时还可以对解析的文件做一些再加工。
接下来主要介绍在 webpack 中如何配置 loader;从宏观层面上聊一聊 loader 的工作原理是什么样的;同时带着一起实现一下 loader 中关键的模块 loader-runner。最后带领导大家一起手动编写上述讲到的 style-loader, css-loader, less-loader。
如何配置 loader
如下是 webpack 中对于 loader 的基本配置:
module.exports = {
resolveLoader: {
// 从根目录下那个文件中寻找 loader
modules: ['node_modules', path.join(__dirname, 'loaders')],
},
module: {
rules: [{
enforce: 'normal',
test: /\\.js$/,
use: [{
loader: 'babel-loader',
options: {
presets: [
"@babel/preset-env"
]
}
}]
},
{
enforce: 'pre',
test: /\\.css$/,
use: ['style-loader', 'css-loader']
}
]
}
};
具体可以参考 https://webpack.docschina.org/configuration/module/#rule 对于 rule 的文档详细介绍。其中比较重要的字段是 enforce。将 loader分为了: post(后置)、normal(普通)、pre(前置)类型。
除了可以在配置文件中设置 loader 之外,由于 loader 是对任意一个文件或者模块的处理。所以也可以在引用每一个模块的地方引用 loader,比如说:
import style from 'style-loader!css-loader?modules!less-loader!./index.less'
在文件地址 ./index.less 前可以添加 loader 多个 loader 使用 !分割, 同时再每个 loader 中后面可以添加 ?作为 loader 的 options。这种添加 loader 的方式是 inline(内联)类型的 loader。同时还可以加上特殊标记前缀,来表示某个特定的 model 要使用什么类型的 loader,分别为如下:
| 符号 | 变量 | 含义 |
|---|---|---|
| -! | noPreAutoLoaders | 不要前置和普通 loader |
| ! | noAutoLoaders | 不要普通 loader |
| !! | noPrePostAutoLoaders | 不要前后置和普通 loader,只要内联 loader |
比如说对于如下:
import style from '-!style-loader!css-loader?modules!less-loader!./index.less'
对于 ./index.less 这个模块来说,不能使用配置文件中配置的前置普通的 loader,只能使用后置的以及内联的 loader 处理本模块。
所以说对于处理模块的 loader 来说,一共有四种类型: post(后置)、normal(普通)、inline(内联)、 pre(前置)。一共有三种标记可以标记某个特定模块具体使用什么类型的 loader, 接下来通过源码的角度来看看具体是怎么实现的。
loader 怎么工作
假设有如下文件和 rules:
const request = 'inline-loader1!inline-loader2!./src/index.js';
const rules = [
{
enforce: 'pre',
test: /\\.js$/,
use: ['pre-loader1', 'pre-loader2'],
},
{
enforce: 'normal',
test: /\\.js$/,
use: ['normal-loader1', 'normal-loader2'],
},
{
enforce: 'post',
test: /\\.js$/,
use: ['post-loader1', 'post-loader2'],
}
];
这里 request 也就是模块为./src/index.js, 同时该模块被 async-loader1 以及 async-loader2 这两个内联的 loader 处理。 同时还有一个 webpack 配置文件中的 rules,其中有 前置 loader pre-loader1、pre-loader2,普通的 loader normal-loader1、normal-loader2,当然对于 enforce 没有被赋值的情况下就是默认的 normal。还有 post 后置 loader post-loader1、post-loader2。
首先我们需要获取出这四种 loader:
const preLoaders = [];
const normalLoaders = [];
const postLoaders = [];
const inlineLoaders = request.replace(/^-?!+/, "").replace(/!!+/g, '!').split('!');
for(let i = 0; i < rules.length; i++) {
let rule = rules[i];
if(rule.test.test(resource)) {
if(rule.enforce === 'pre') {
preLoaders.push(...rule.use);
} else if(rule.enforce === 'post') {
postLoaders.push(...rule.use);
} else { // normal
normalLoaders.push(...rule.use);
}
}
}
为了获取 内联的 loader,需要将引用的地址用 !分割获取, 但是在这之前,需要将 -?! 特殊标记前缀置位空,同时对于连续的 !也需要置为空避免出现空的 loader。这样就能获取到 [ ‘async-loader1’, ‘async-loader2’, ‘./src/index.js’ ], 已经能够获取到内联的 loader 了,同时通过循环遍历 rules 能够获取到其他的 loader。到此我们已经拿到四种 loader 了。值得注意的是, 在引用地址中和 rules 中 loader 的顺序就是定义的顺序内有发生改变的。
接下来我们需要获取 loader 执行的顺序列表 loaders 了。默认情况下也就是没有特殊标记的情况下,loaders 会是如下的顺序生成:
loaders = [
...postLoaders,
...inlineLoaders,
...normalLoaders,
...preLoaders,
];
默认情况下,分别按照 post inline normal pre 的顺序以及每一种 loader 定义的顺序排列生成 loaders。
对于带有特殊标记的引用来说也会影响到 loaders 中的内容:
if(request.startsWith('!')) { // 不要 normal
loaders = [
...postLoaders,
...inlineLoaders,
...preLoaders,
];
} else if(request.startsWith('-!')) { // 不要 normal、pre
loaders = [
...postLoaders,
...inlineLoaders
];
} else if(request.startsWith('!!')) { // 不要 post、normal、pre
loaders = [
...inlineLoaders,
];
} else { // post、inline、normal、pre
loaders = [
...postLoaders,
...inlineLoaders,
...normalLoaders,
...preLoaders,
];
}
对于 引用地址 request 仅仅是以 ! 开头 是不需要 normal 类型的 loader 的, 但是其他的类型的 loader 顺序依然保持。同理,-! 不需要 normal、pre loader, !! 不需要 post、normal、pre loader。
到此,对于引用文件 request 的 loader处理列表 loaders 已经拿到了,接下来需要经过 loader-runner 对 loader 列表中的 loader 按照一定的规则对 资源文件进行加工处理。
runLoaders({
resource: path.join(__dirname, resource),
loaders
}, (err, data) => {
console.log(data);
});
loader 获取 loaders 列表的完整代码如下:
const { runLoaders } = require('loader-runner');
const fs = require('fs');
const path = require('path');
const loadDir = path.resolve(__dirname,'loaders', 'runner');
const request = 'inline-loader1!inline-loader2!./src/index.js';
let preLoaders = [];
let normalLoaders = [];
let postLoaders = [];
let inlineLoaders = request.replace(/^-?!+/, "").replace(/!!+/g, '!').split('!');
const resource = inlineLoaders.pop();
const resolveLoader = loader => path.resolve(loadDir, loader);
const rules = [
{
enforce: 'pre',
test: /\\.js$/,
use: ['pre-loader1', 'pre-loader2'],
},
{
enforce: 'normal',
test: /\\.js$/,
use: ['normal-loader1', 'normal-loader2'],
},
{
enforce: 'post',
test: /\\.js$/,
use: ['post-loader1', 'post-loader2'],
}
];
for(let i = 0; i < rules.length; i++) {
let rule = rules[i];
if(rule.test.test(resource)) {
if(rule.enforce === 'pre') {
preLoaders.push(...rule.use);
} else if(rule.enforce === 'post') {
postLoaders.push(...rule.use);
} else {
normalLoaders.push(...rule.use);
}
}
}
preLoaders = preLoaders.map(resolveLoader);
normalLoaders = normalLoaders.map(resolveLoader);
inlineLoaders = inlineLoaders.map(resolveLoader);
postLoaders = postLoaders.map(resolveLoader);
let loaders = [];
if(request.startsWith('!')) { // 不要 normal
loaders = [
...postLoaders,
...inlineLoaders,
...preLoaders,
];
} else if(request.startsWith('-!')) { // 不要 normal、pre
loaders = [
...postLoaders,
...inlineLoaders
];
} else if(request.startsWith('!!')) { // 不要 post、normal、pre
loaders = [
...inlineLoaders,
];
} else { // post、inline、normal、pre
loaders = [
...postLoaders,
...inlineLoaders,
...normalLoaders,
...preLoaders,
];
}
runLoaders({
resource: path.join(__dirname, resource),
loaders,
readResource:fs.readFile.bind(fs)
}, (err, data) => {
console.log(data);
});
总结一下,webpack 拿到模块文件的引用地址 request 后,其中有一步需要经过 loader 处理,首先或取出四种 loader 并且的分别按照 post inline normal pre 组装成 loader 执行列表 loaders, 同时其中可以通过特殊标记对 loader 类型进行过滤。但是 loader 顺序依然保持。得到 laoders 后会交给 loader-runner 对按照一定的规则对源文件做进一步的加工处理。 接下来详细介绍下比较重要的 loader-runner,先从基本的原理概念讲解,然后一起实现一个 loader-runner。
loader-runner 基本规则
有没有考虑过一个问题,为什么在配置文件中配置的 loader 都是从右向左的处理源文件而不是从左到右呢?这是由于 loader-runner 在处理每一个 loader 的时候,会先从左到右的执行 loader pitch 方法,然后再执行本身的 loader 方法称为 normal。如下图所示: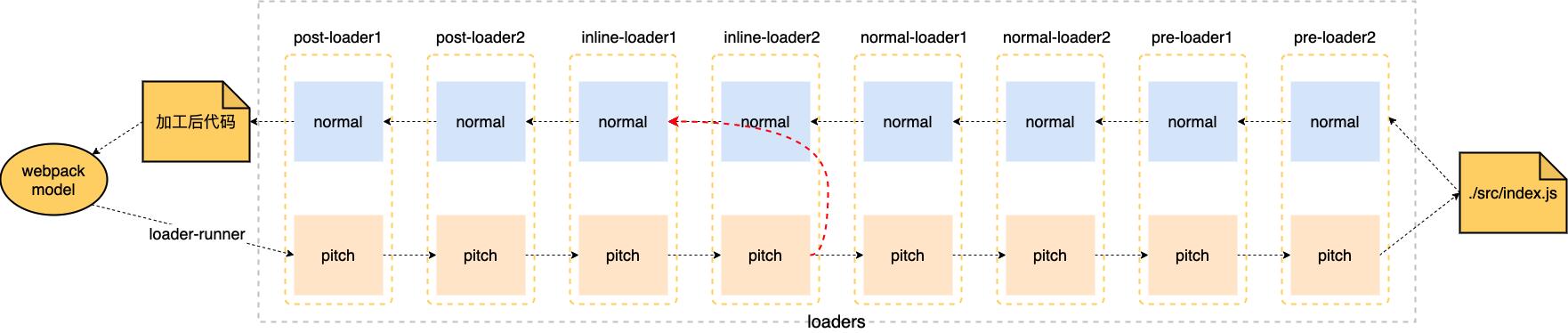
上一节已经介绍了 loaders 里面有一定顺序的 loader,然后会交给 laoder-runner 执行,有如下 post-loader1 代码所示,loader 可以添加一个 pitch 方法:
function loader(source){
console.log('post-loader1 normal');
return source+"【post-loader1】";
}
loader.pitch = function(){
console.log('post-pitch1 pitch');
}
module.exports = loader;
loader 方法可以称为 normal 方法,该方法主要接受 源文件内容作为参数,然后返回加工后的源文件,例子中的 loader 主要就是为 source 字符串后追加 【post-loader1】字符串,然后交给一下个 loader 的 normal 作为入参执行。同时 normal 方法中也可以添加一个 pitch 方法, 该方法主要是为执行 loader 之前做一些预处理或者拦截的工作。
开始解释下这个图,整个处理过程类似于 DOM 的事件冒泡机制,开始调用 loader-runner,会按照 laoders 中的顺序依次执行,先执行 loader 中的 pitch 方法,如果方法没有返回值则继续执行下一个 pitch 直到执行完毕后开始执行最后一个 loader 的 normal。然后从右向左的执行 loader 的 normal方法,你并且前一个 loader 的返回值作为后一个 normal 的入参。但是如果在中途有 loader 的 pitch 返回值 如图红色虚线, 那么则直接将返回值作为前一个 loader normal 的入参然后继续执行,这样子就不会去解析源代码了,比如缓存中会使用到这个场景。
对于 loader 来说无论是 normal 还是 pitch 都可以写同步代码和异步代码的,对于同步代码可以直接返回一个值就可以作为下一个 loader 的入参。但是异步的会有一点点差别具体代码如下:
function loader(source) {
const callback = this.async();
setTimeout(() => {
callback(null, source + "【async-loader1】");
}, 3000);
}
loader.pitch = function () {
const callback = this.async();
console.log('async-loader1-pitch');
callback(null);
}
module.exports = loader;
首先需要调用 this.async 函数来声明这是个异步的方法,返回一个回调的句柄,用来异步执行完毕后执行后续的流程。callback 提供 err、和下一个 normal 的入参。同时 pitch 也是一样也可以 daioyong this.async 讲一个同步的方法改成异步。
到此,loader 执行流程和同步异步 loader 介绍完了,接下来我们用源码角度去进一步的了解 loader-runner,以及了解基于职责链模式的设计。
让我们实现 loader-runner
loader-runner 上一节也介绍了整体的流程和DOM 事件冒泡机制、作用域链、原型链、react 事件机制、koa 洋葱模型等都是差不多的,他们核心都是基于 职责链模式 这一设计模式的。具体关于职责链模式可以参考 https://www.yuque.com/wmaoshu/blog/rcf95o 对于职责链模式是使多个对象可以统一的处理,避免了请求方因为可能类型多种多样导致和接受处理方的耦合,为了保证请求可以经过多个接受按照规则处理,需要有一套机制将接收方行程一条链,然后请求方就会按照这个链路进行执行。所以职责链来说重要的是:一点为了保证请求的函数职责单一,需要具备通用性也就是函数签名和返回值应该保持一致,并且具备通知链条开始执行下一个的能力;二点为了保证请求的函数式开放封闭的,需要一个链条将这个过程串联起来。
开始执行的 loader 代码中会提供 options 参数:
runLoaders({
resource: path.join(__dirname, resource),
loaders,
readResource:fs.readFile.bind(fs)
}, (err, data) => {
console.log(data);
});
runLoaders 第一个参数 options 值为:
{
resource: '/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/src/index.js',
loaders: [
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/post-loader1',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/post-loader2',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/inline-loader1',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/inline-loader2',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/normal-loader1',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/normal-loader2',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/pre-loader1',
'/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/pre-loader2'
]
}
提供给 runLoader 方法的第一个参数 options 有资源的绝对地址路径 resource,以及 loader 绝对地址路径的 loaders 列表。
对于 runLoaders 方法而言,一部分是创建一个执行上下文环境,然后调用 iteratePitchingLoaders 方法开始进入 laoder 的执行。
exports.runLoaders = function (options, callback) {
createLoaderContext(options);
let processOptions = {
resourceBuffer: null, //最后我们会把loader执行的Buffer结果放在这里
readResource: options.readResource || readFile,
}
iteratePitchingLoaders(processOptions, loaderContext, function (err, result) {
if (err) {
return callback(err, {});
}
callback(null, {
result,
resourceBuffer: processOptions.resourceBuffer
});
});
};
接下来介绍一下 loader 执行上下文,以及 loader 对象。
function parsePathQueryFragment(resource) { //resource =./src/index.js?name=wms#1
let result = /^([^?#]*)(\\?[^#]*)?(#.*)?$/.exec(resource);
return {
path: result[1], //路径名 ./src/index.js
query: result[2], // ?name=wms
fragment: result[3] // #1
}
};
//loader绝对路径
// 比如:/Users/mt/Documents/my-lib-learn/webpack/5.webpack-loader/loaders/runner/post-loader1?{"presets":["/Users/anning/Desktop/webpack-demo/node_modules/@babel/preset-env"]}"
function createLoaderObject(loader) {
let obj = {
path: '', //当前loader的绝对路径
query: '', //当前loader的查询参数
fragment: '', //当前loader的片段
normal: null, //当前loader的normal函数,也就是loader本函数
pitch: null, //当前loader的pitch函数
raw: null, //是否是Buffer
data: {}, //自定义对象 每个loader都会有一个data自定义对象
pitchExecuted: false, //当前 loader的pitch函数已经执行过了,不需要再执行了
normalExecuted: false //当前loader的normal函数已经执行过了,不需要再执行
}
Object.defineProperty(obj, 'request', {
get() {
return obj.path + obj.query + obj.fragment;
},
set(value) {
let splittedRequest = parsePathQueryFragment(value);
obj.path = splittedRequest.path;
obj.query = splittedRequest.query;
obj.fragment = splittedRequest.fragment;
}
});
obj.request = loader;
return obj;
};
function loadLoader(loaderObject) {
let normal = require(loaderObject.path);
loaderObject.normal = normal;
loaderObject.pitch = normal.pitch;
loaderObject.raw = normal.raw;
};
function createLoaderContext(options) {
// 要加载的资源的绝对路径
const splittedResource = parsePathQueryFragment(options.resource || '');
// 准备loader对象数组
loaders =以上是关于webpack 源码分析系列 ——loader的主要内容,如果未能解决你的问题,请参考以下文章