Spark Sql源码详细分析
Posted 郭朝阳@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Sql源码详细分析相关的知识,希望对你有一定的参考价值。
Spark Sql 源码分析
文章目录
一、SparkSQL架构设计
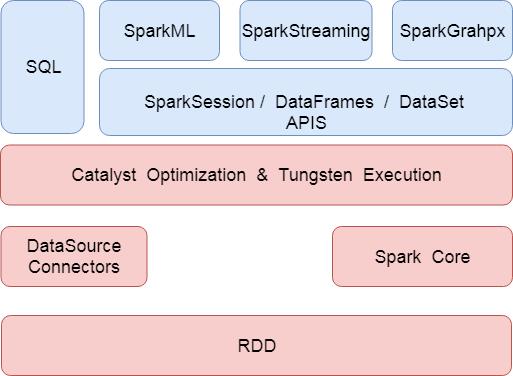
SparkSQL是spark技术栈当中又一非常出彩的模块,通过引入SQL的支持,大大降低了开发人员和学习人员的使用成本,让我们开发人员直接使用SQL的方式就能够实现大数据的开发,它同时支持DSL以及SQL的语法风格,目前在spark的整个架构设计当中,所有的spark模块,例如SQL,SparkML,sparkGrahpx以及Structed Streaming等都是基于 Catalyst Optimization & Tungsten Execution模块之上运行,如下图所示就显示了spark的整体架构模块设计。
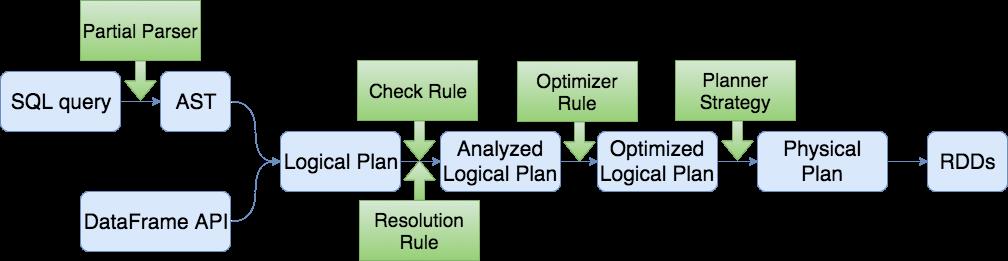
SparkSQL 执行先会经过 SQL Parser 解析 SQL,然后经过 Catalyst 优化器处理,最后到 Spark 执行。而 Catalyst 的过程又分为很多个过程,其中包括:
-
Analysis:主要利用 Catalog 信息将 Unresolved Logical Plan 解析成 Analyzed
logical plan; -
Logical Optimizations:利用一些 Rule (规则)将 Analyzed logical plan 解析成
Optimized Logical Plan; -
Physical Planning:前面的 logical plan 不能被 Spark 执行,而这个过程是把 logical plan
转换成多个 physical plans,然后利用代价模型(cost model)选择最佳的 physical plan; -
Code Generation:这个过程会把 SQL 查询生成 Java 字 节码。
Spark Sql 其整体的执行流程如下:

本文将介绍整体流程中的各个步骤的实现,为我们后续扩展Spark Sql,实现我们自己的语法检查、性能优化提供可能,其预期可以扩展的部分如下:
(上一篇文章中的优化实现就是优化了Optimizer)
二、代码分析
1、 Demo
接下来我们通过一段实例来简单介绍下Spark Sql的整体实现。
例如执行以下SQL语句::
select temp1.class,sum(temp1.degree),avg(temp1.degree) from (SELECT students.sno AS ssno,students.sname,students.ssex,students.sbirthday,students.class, scores.sno,scores.degree,scores.cno FROM students LEFT JOIN scores ON students.sno = scores.sno ) temp1 group by temp1.class
代码如下(示例):
package learn
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* GuoZhaoYang
* 2020/12/01
*/
object DataFrommysqlPlan {
def main(args: Array[String]): Unit = {
//1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("DataFromMysql").setMaster("local[2]")
//sparkConf.set("spark.sql.codegen.wholeStage","true")
//2、创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//3、读取mysql表的数据
//3.1 指定mysql连接地址
val url="jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8&serverTimezone=UTC"
//3.2 指定要加载的表名
val student="students"
val score="scores"
// 3.3 配置连接数据库的相关属性
val properties = new Properties()
//用户名
properties.setProperty("user","root")
//密码
properties.setProperty("password","123456")
val studentFrame: DataFrame = spark.read.jdbc(url,student,properties)
val scoreFrame: DataFrame = spark.read.jdbc(url,score,properties)
//把dataFrame注册成表
studentFrame.createTempView("students")
scoreFrame.createOrReplaceTempView("scores")
val resultFrame: DataFrame = spark.sql(
"""
|SELECT
| temp1.class,
| SUM(temp1.degree),
| AVG(temp1.degree)
|FROM
| (
| SELECT
| students.sno AS ssno,
| students.sname,
| students.ssex,
| students.sbirthday,
| students.class,
| scores.sno,
| scores.degree,
| scores.cno
| FROM
| students
| LEFT JOIN scores ON
| students.sno = scores.sno
| WHERE
| degree > 60
| AND sbirthday > '1973-01-01 00:00:00' ) temp1
|GROUP BY
| temp1.class
|
|""".stripMargin)
resultFrame.explain(true)
resultFrame.show()
Thread.sleep(Integer.MAX_VALUE)
spark.stop()
}
通过explain方法来查看sql的执行计划,得到以下信息。
== Parsed Logical Plan ==
'Aggregate ['temp1.class], ['temp1.class, unresolvedalias('SUM('temp1.degree), None), unresolvedalias('AVG('temp1.degree), None)]
+- 'SubqueryAlias temp1
+- 'Project ['students.sno AS ssno#16, 'students.sname, 'students.ssex, 'students.sbirthday, 'students.class, 'scores.sno, 'scores.degree, 'scores.cno]
+- 'Filter (('degree > 60) && ('sbirthday > 1973-01-01 00:00:00))
+- 'Join LeftOuter, ('students.sno = 'scores.sno)
:- 'UnresolvedRelation `students`
+- 'UnresolvedRelation `scores`
== Analyzed Logical Plan ==
class: string, sum(degree): decimal(20,1), avg(degree): decimal(14,5)
Aggregate [class#4], [class#4, sum(degree#12) AS sum(degree)#27, avg(degree#12) AS avg(degree)#28]
+- SubqueryAlias temp1
+- Project [sno#0 AS ssno#16, sname#1, ssex#2, sbirthday#3, class#4, sno#10, degree#12, cno#11]
+- Filter ((cast(degree#12 as decimal(10,1)) > cast(cast(60 as decimal(2,0)) as decimal(10,1))) && (cast(sbirthday#3 as string) > 1973-01-01 00:00:00))
+- Join LeftOuter, (sno#0 = sno#10)
:- SubqueryAlias students
: +- Relation[sno#0,sname#1,ssex#2,sbirthday#3,class#4] JDBCRelation(students) [numPartitions=1]
+- SubqueryAlias scores
+- Relation[sno#10,cno#11,degree#12] JDBCRelation(scores) [numPartitions=1]
== Optimized Logical Plan ==
Aggregate [class#4], [class#4, sum(degree#12) AS sum(degree)#27, cast((avg(UnscaledValue(degree#12)) / 10.0) as decimal(14,5)) AS avg(degree)#28]
+- Project [class#4, degree#12]
+- Join Inner, (sno#0 = sno#10)
:- Project [sno#0, class#4]
: +- Filter ((isnotnull(sbirthday#3) && (cast(sbirthday#3 as string) > 1973-01-01 00:00:00)) && isnotnull(sno#0))
: +- Relation[sno#0,sname#1,ssex#2,sbirthday#3,class#4] JDBCRelation(students) [numPartitions=1]
+- Project [sno#10, degree#12]
+- Filter ((isnotnull(degree#12) && (degree#12 > 60.0)) && isnotnull(sno#10))
+- Relation[sno#10,cno#11,degree#12] JDBCRelation(scores) [numPartitions=1]
== Physical Plan ==
*(6) HashAggregate(keys=[class#4], functions=[sum(degree#12), avg(UnscaledValue(degree#12))], output=[class#4, sum(degree)#27, avg(degree)#28])
+- Exchange hashpartitioning(class#4, 200)
+- *(5) HashAggregate(keys=[class#4], functions=[partial_sum(degree#12), partial_avg(UnscaledValue(degree#12))], output=[class#4, sum#32, sum#33, count#34L])
+- *(5) Project [class#4, degree#12]
+- *(5) SortMergeJoin [sno#0], [sno#10], Inner
:- *(2) Sort [sno#0 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(sno#0, 200)
: +- *(1) Project [sno#0, class#4]
: +- *(1) Filter (cast(sbirthday#3 as string) > 1973-01-01 00:00:00)
: +- *(1) Scan JDBCRelation(students) [numPartitions=1] [sno#0,class#4,sbirthday#3] PushedFilters: [*IsNotNull(sbirthday), *IsNotNull(sno)], ReadSchema: struct<sno:string,class:string,sbirthday:timestamp>
+- *(4) Sort [sno#10 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(sno#10, 200)
+- *(3) Scan JDBCRelation(scores) [numPartitions=1] [sno#10,degree#12] PushedFilters: [*IsNotNull(degree), *GreaterThan(degree,60.0), *IsNotNull(sno)], ReadSchema: struct<sno:string,degree:decimal(10,1)>
2、 Catalyst执行过程
从上面的查询计划我们可以看得出来,我们编写的sql语句,经过多次转换,最终进行编译成为字节码文件进行执行,这一整个过程经过了好多个步骤,其中包括以下几个重要步骤
1.sql解析阶段 parse
2.生成逻辑计划 Analyzer
3.sql语句调优阶段 Optimizer
4.生成物理查询计划 planner
三、执行计划分析
1、sql解析阶段 Parser
在spark2.x的版本当中,为了解析sparkSQL的sql语句,引入了Antlr。Antlr 是一款强大的语法生成器工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件,是当前 Java 语言中使用最为广泛的语法生成器工具,我们常见的大数据 SQL 解析都用到了这个工具,包括 Hive、Cassandra、Phoenix、Pig 以及 presto 等。目前最新版本的 Spark 使用的是ANTLR4,通过这个对 SQL 进行词法分析并构建语法树。
我们可以通过github去查看spark的源码,具体路径如下:
查看得到sparkSQL支持的SQL语法,所有sparkSQL支持的语法都定义在了这个文件当中。如果我们需要重构sparkSQL的语法,那么我们只需要重新定义好相关语法,然后使用Antlr4对SqlBase.g4进行语法解析,生成相关的java类,其中就包含重要的词法解析器SqlBaseLexer.java和语法解析器SqlBaseParser.java。在我们运行上面的java的时候,第一步就是通过SqlBaseLexer来解析关键词以及各种标识符,然后使用SqlBaseParser来构建语法树。
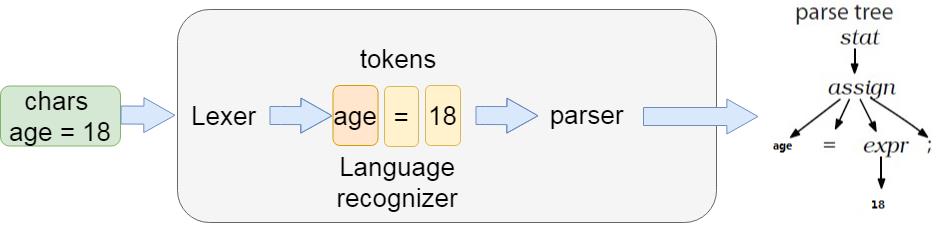
最终通过Lexer以及parse解析之后,生成语法树,生成语法树之后,使用AstBuilder将语法树转换成为LogicalPlan,这个LogicalPlan也被称为Unresolved LogicalPlan。解析之后的逻辑计划如下
== Parsed Logical Plan ==
'Aggregate ['temp1.class], ['temp1.class, unresolvedalias('SUM('temp1.degree), None), unresolvedalias('AVG('temp1.degree), None)]
+- 'SubqueryAlias temp1
+- 'Project ['students.sno AS ssno#16, 'students.sname, 'students.ssex, 'students.sbirthday, 'students.class, 'scores.sno, 'scores.degree, 'scores.cno]
+- 'Filter (('degree > 60) && ('sbirthday > 1973-01-01 00:00:00))
+- 'Join LeftOuter, ('students.sno = 'scores.sno)
:- 'UnresolvedRelation `students`
+- 'UnresolvedRelation `scores`
如图:
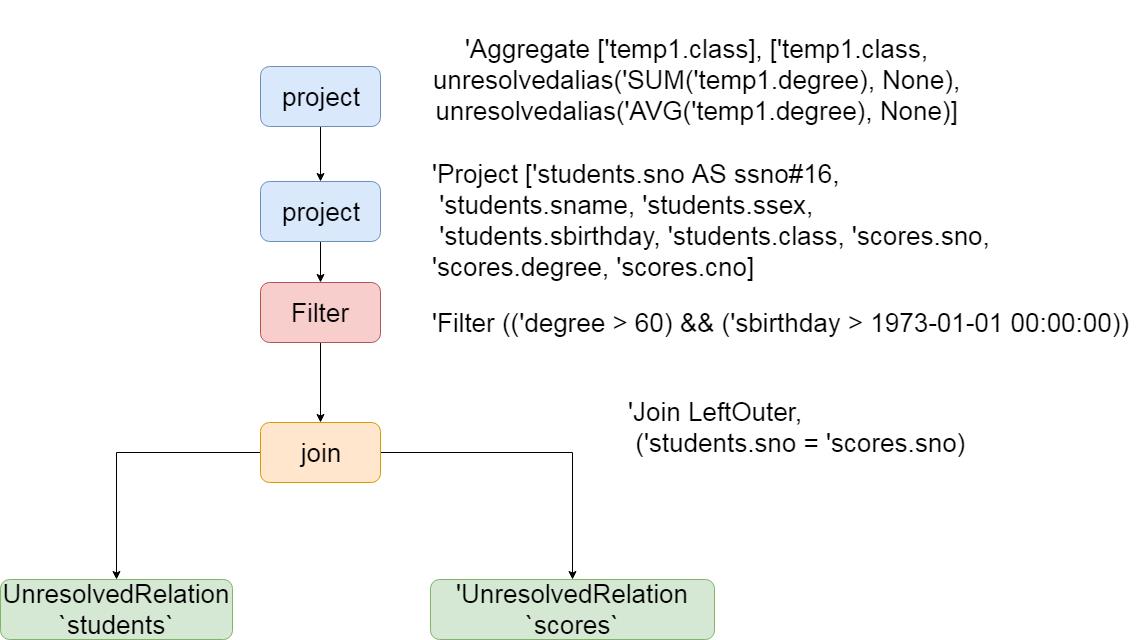
从上图可以看得到,两个表被join之后生成了UnresolvedRelation,选择的列以及聚合的字段都有了,sql解析的第一个阶段就已经完成,接着准备进入到第二个阶段
2、绑定逻辑计划Analyzer
在sql解析parse阶段,生成了很多的unresolvedalias , UnresolvedRelation等很多未解析出来的有些关键字,这些都是属于 Unresolved LogicalPlan解析的部分。 Unresolved LogicalPlan仅仅是一种数据结构,不包含任何数据信息,例如不知道数据源,数据类型,不同的列来自哪张表等等。。Analyzer 阶段会使用事先定义好的 Rule 以及 SessionCatalog 等信息对 Unresolved LogicalPlan 进行 transform。SessionCatalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。而Rule 是定义在 Analyzer 里面的,具体的类的路径如下:
org.apache.spark.sql.catalyst.analysis.Analyzer
具体的rule规则定义如下:
lazy val batches: Seq[Batch] = Seq(
Batch("Hints", fixedPoint,
new ResolveHints.ResolveBroadcastHints(conf),
ResolveHints.RemoveAllHints),
Batch("Simple Sanity Check", Once,
LookupFunctions),
Batch("Substitution", fixedPoint,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
new SubstituteUnresolvedOrdinals(conf)),
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions ::
ResolveRelations ::
ResolveReferences ::
ResolveCreateNamedStruct ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveAggAliasInGroupBy ::
ResolveMissingReferences ::
ExtractGenerator ::
ResolveGenerate ::
ResolveFunctions ::
ResolveAliases ::
ResolveSubquery ::
ResolveSubqueryColumnAliases ::
ResolveWindowOrder ::
ResolveWindowFrame ::
ResolveNaturalAndUsingJoin ::
ExtractWindowExpressions ::
GlobalAggregates ::
ResolveAggregateFunctions ::
TimeWindowing ::
ResolveInlineTables(conf) ::
ResolveTimeZone(conf) ::
ResolvedUuidExpressions ::
TypeCoercion.typeCoercionRules(conf) ++
extendedResolutionRules : _*),
Batch("Post-Hoc Resolution", Once, postHocResolutionRules: _*),
Batch("View", Once,
AliasViewChild(conf)),
Batch("Nondeterministic", Once,
PullOutNondeterministic),
Batch("UDF", Once,
HandleNullInputsForUDF),
Batch("FixNullability", Once,
FixNullability),
Batch("Subquery", Once,
UpdateOuterReferences),
Batch("Cleanup", fixedPoint,
CleanupAliases)
)
从上面代码可以看出,多个性质类似的 Rule 组成一个 Batch,比如上面名为 Hints 的 Batch就是由很多个 Hints Rule 组成;而多个 Batch 构成一个 batches。这些 batches 会由 RuleExecutor 执行,先按一个一个 Batch 顺序执行,然后对 Batch 里面的每个 Rule 顺序执行。每个 Batch 会执行一次(Once)或多次(FixedPoint,由
spark.sql.optimizer.maxIterations 参数决定),执行过程如下:
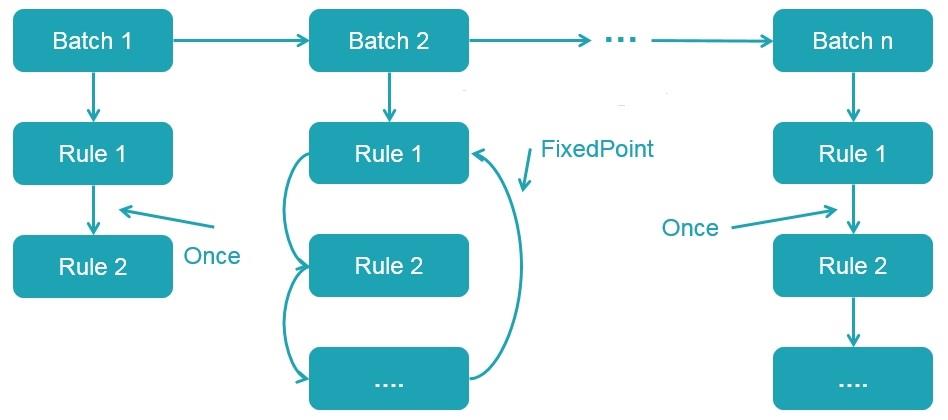
所以上面的 SQL 经过这个阶段生成的 Analyzed Logical Plan 如下:
== Analyzed Logical Plan ==
class: string, sum(degree): decimal(20,1), avg(degree): decimal(14,5)
Aggregate [class#4], [class#4, sum(degree#12) AS sum(degree)#27, avg(degree#12) AS avg(degree)#28]
+- SubqueryAlias temp1
+- Project [sno#0 AS ssno#16, sname#1, ssex#2, sbirthday#3, class#4, sno#10, degree#12, cno#11]
+- Filter ((cast(degree#12 as decimal(10,1)) > cast(cast(60 as decimal(2,0)) as decimal(10,1))) && 以上是关于Spark Sql源码详细分析的主要内容,如果未能解决你的问题,请参考以下文章
第五篇:Spark SQL Catalyst源码分析之Optimizer
可能是全网最详细的 Spark Sql Aggregate 源码剖析
Spark SQL 源代码分析之Physical Plan 到 RDD的详细实现