《大秦赋》最近有点火!于是我用Python抓取了“相关数据”,发现了这些秘密......
Posted 数据分析与统计学之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大秦赋》最近有点火!于是我用Python抓取了“相关数据”,发现了这些秘密......相关的知识,希望对你有一定的参考价值。
前言
去年,最火的电视剧莫过于《大秦赋了》,自12月1日开播后,收获了不错的口碑。然而随着电视剧的跟新,该剧在网上引起了激烈的讨论,不仅口碑急剧下滑,颇有高开低走的趋势,同时该剧的评分也由最初的8.9分,下降到了现在的6.5分。

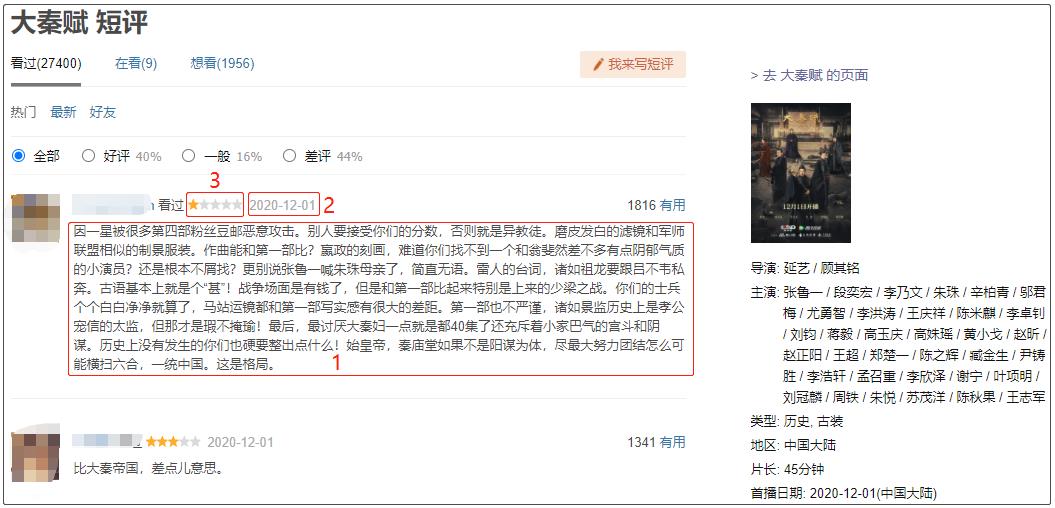
虽然我还没有看过这个新剧,但是对于小伙伴们讨论的内容,却颇有兴趣(主要还是大家老是讨论这个剧)。因此,我用Python爬取了《大秦赋》的相关数据,进行了一波分析。
数据爬取
巧妇难为无米之炊,做数据分析之前最重要的就是“数据获取”。于是,我准备用Python爬取豆瓣上的短评数据以及一些评论时间信息、评价星级信息。
关于数据的爬取主要说以下几个内容:
1)关于翻页操作
第一页:
https://movie.douban.com/subject/26413293/comments?status=P
第二页:
https://movie.douban.com/subject/26413293/comments?start=20&limit=20&status=P&sort=new_score
第三页:
https://movie.douban.com/subject/26413293/comments?start=40&limit=20&status=P&sort=new_score
上面我们分别展示了第1-3页的页面链接,我们主要是观察其中的规律,其中start是获取评论的起始位置,limit代表获取多少条评论数据。观察结果:3个链接的不同在于这个start的不同,在后续翻页时,我们只需要修改start参数即可。
2)关于反扒说明
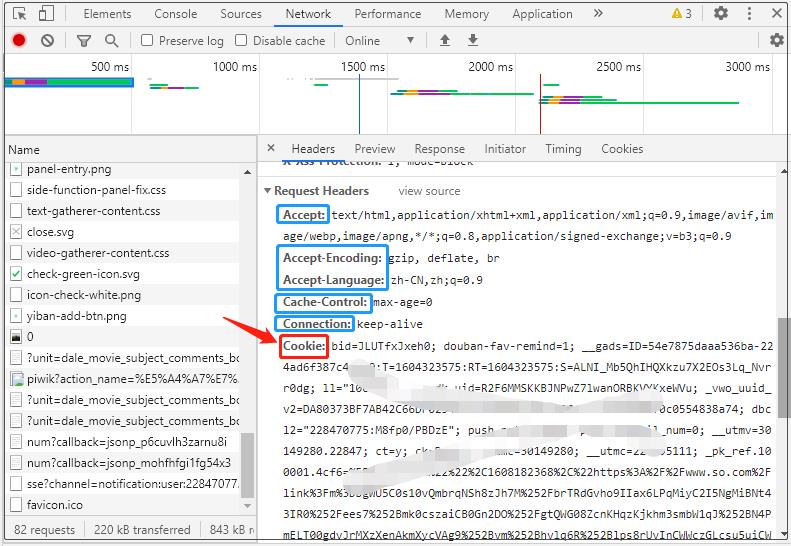
对于豆瓣的爬取,其实找到真实的短评链接,是极其容易的。但是这里有一点我必须说明,你可以不登陆爬取数据,但是只能是操作一段时间,过一段时间,会检测到你是爬虫。因此,你一定要登陆后,携带cookie去进行数据的爬取。如果你有时候不知道请求头中,该放一些什么,那么就请都加上,等有空再慢慢总结。
headers = {
"Accept":"application/json, text/plain, */*",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Host":"movie.douban.com",
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
"Cookie":'这里是你自己的cookie'
}
cookie有些人可能又不知道在哪里,还是告诉你一下吧!好多参数都在下面呢,如果你想学好爬虫,那么这些参数代表什么,你总应该需要知道吧。
最终再补充一点:我本来打算把豆瓣上的《大秦赋》短评,全部爬下来作为分析的素材。然而并没有成功爬取到所有的短评,一波三折,最终只爬到了500条,当然我觉得这也是豆瓣的一种反扒措施,最大可见短评数就500条,多的不给你看。(有大神的话,可以下去研究一下)
数据处理
爬取后的数据,再怎么规整,也和用于分析的数据之间,有一定的差距。因此再分析之前,一定的数据清洗是很有必要的。在数据清洗之前,我们简单看看数据是什么样子的。
df = pd.read_csv("final_all_comment.csv",index_col=0)
df.head(10)
结果如下: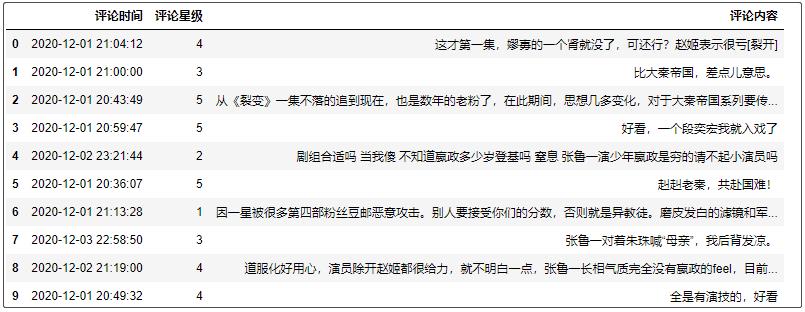
其实数据还是挺漂亮的,但是我们还是需要做如下处理:
1)剔除重复值
我们认为:如果’评论时间’和’评论内容’完全一致的话,就认为他是同一条评论,需要将其剔除。
print("删除之前的记录数:",df.shape)
df.drop_duplicates(subset=['评论时间','评论内容'],inplace=True,keep='first')
print("删除之前的记录数:",df.shape)
2)评论时间处理
因为《大秦赋》是2020年12月1号开播的,现在是12月16号晚,因此所有的评论数据肯定都是2020年12月开始有的,因此我们只保留有用的“日期”数据(哪一天)。而对于时分秒来说,我们只保留“小时”数据。
df["评论天数"] = df["评论时间"].str[8:-9].astype(int)
df["小时"] = df["评论时间"].str[11:-6].astype(int)
3)评论星级说明
观察原页面的评论星级,可以看到所有的星级并不是以数字展示的,而是用星星进行前端渲染出来的,但是页面的源代码,却展示的是星级数。
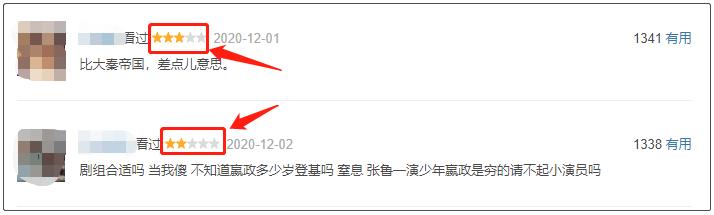
对应到页面源代码中,我们看看又是怎么样子的呢?
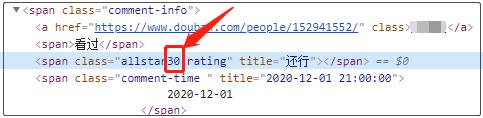
可以看到:3星的数字是30,其它的以此类推,1星的数字是10,2星的数字是20…我看着就是很不爽,因此我在爬取数据的时候,已经将这些数字,全都除以10后计算。
4)评论内容机械压缩去重
对于一条评论来说,有些人可能手误,或者凑字数,会出现将某个字或者词语,重复说多次,因此在进行分词之前,需要做“机械压缩去重”操作。下面是我很早之前写的一段代码,大家可以去看我的CSDN博客,里面有很好的解释。
def func(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
st = "我爱你我爱你我爱你好你好你好哈哈哈哈哈"
func(st)
结果如下:

利用上述函数,我们可以对爬取到的数据,应用此操作。
def func(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
df["评论内容"] = df["评论内容"].apply(func)
数据可视化操作
俗话说:“字不如表,表不如图”。爬取到的数据,最终做可视化的呈现,才能够让大家对数据背后的规律,有一个清晰的认识。下面我们从以下几个方面来进行数据可视化分析。
- 评论数随时间的变化趋势
- 二十四小时内的评论数的变化趋势
- 星级评分的饼图
- 大家主要都在评论一些啥
关于数据可视化工具,我就不用pyecharts了,我还是回归原始,用最原始的matplotlib库进行数据可视化的展示。毕竟我们没有什么复杂的展示,代码越简短越好。
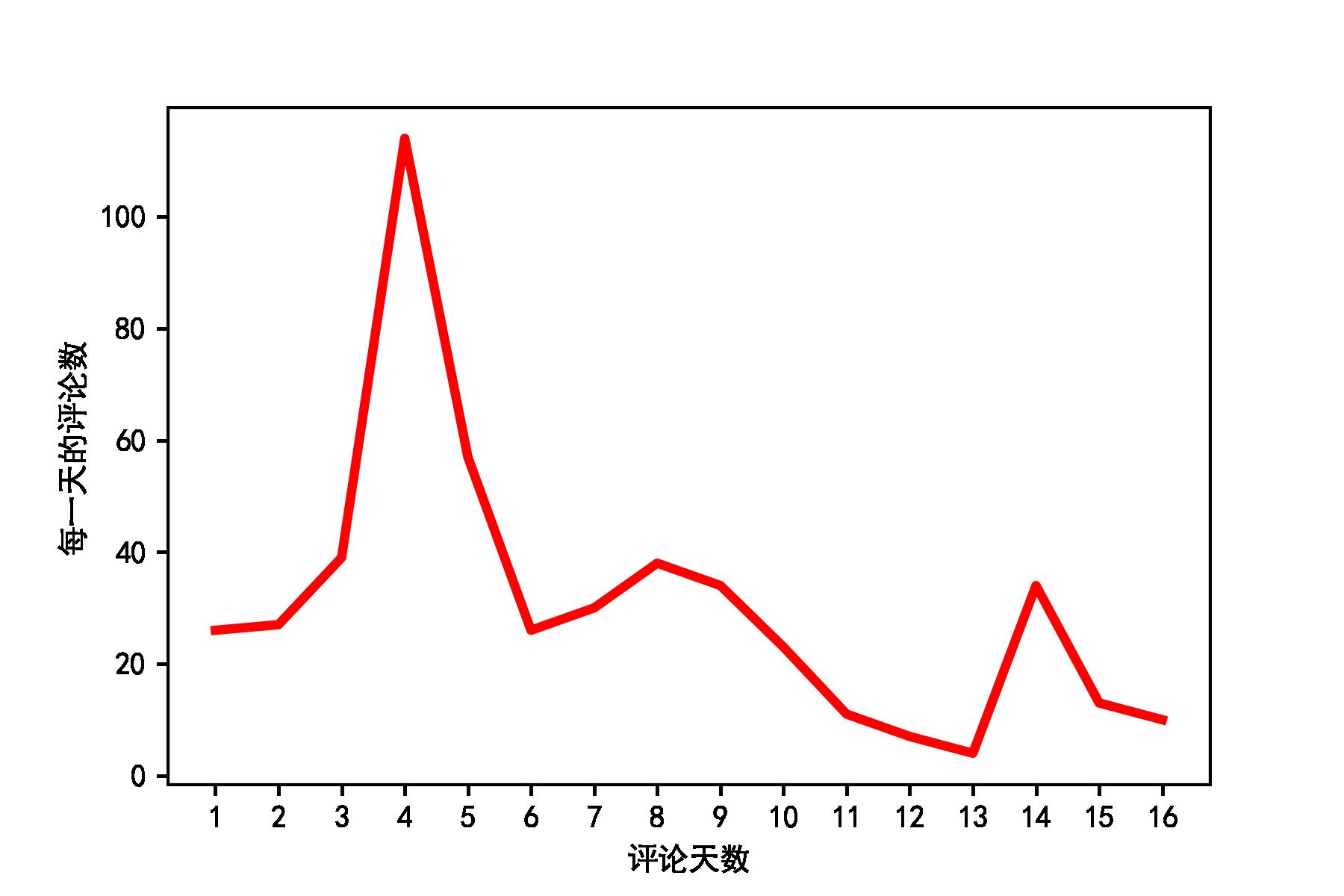
1)评论数随时间的变化趋势
从图中可以看出:短评数量在12月4日之前,一直处于上升趋势,在12月4日达到顶峰。和文章最开始的说明一致,前面几天观众对于该剧的期待值较高,但是在12月4日后,突然出现断崖式下降,说明随着该剧的更新,大家有所失望了。
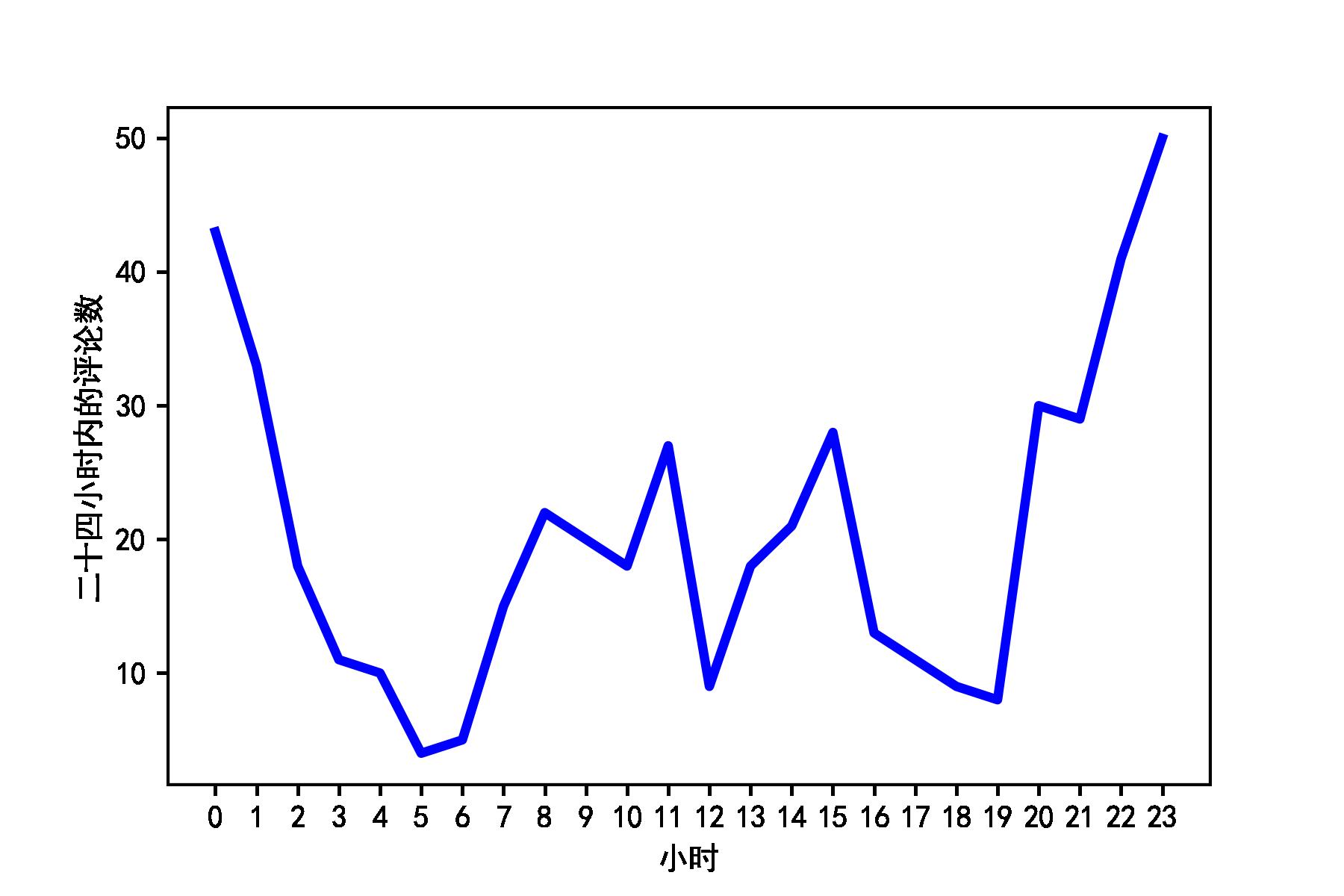
2)二十四小时内的评论数的变化趋势
最近总听到周围有人在讨论这部剧,下面就来看看大家都是在啥时候追剧呢?从24小时图中可以看出:晚上7-24点,评论急剧上升,大多数人都是6点下班,可能吃个饭到7点左右,或者直接在下班过程中,就开始了一天的追剧。这里还有一波早高峰5-8点,难道睡不着?早上还要起来刷刷据,然后上班。这里还有两个时间段:上午10-11点,中午12-15点,大家可以分析下,肯定有相当一部分小伙伴,正在摸鱼工作呀🤭
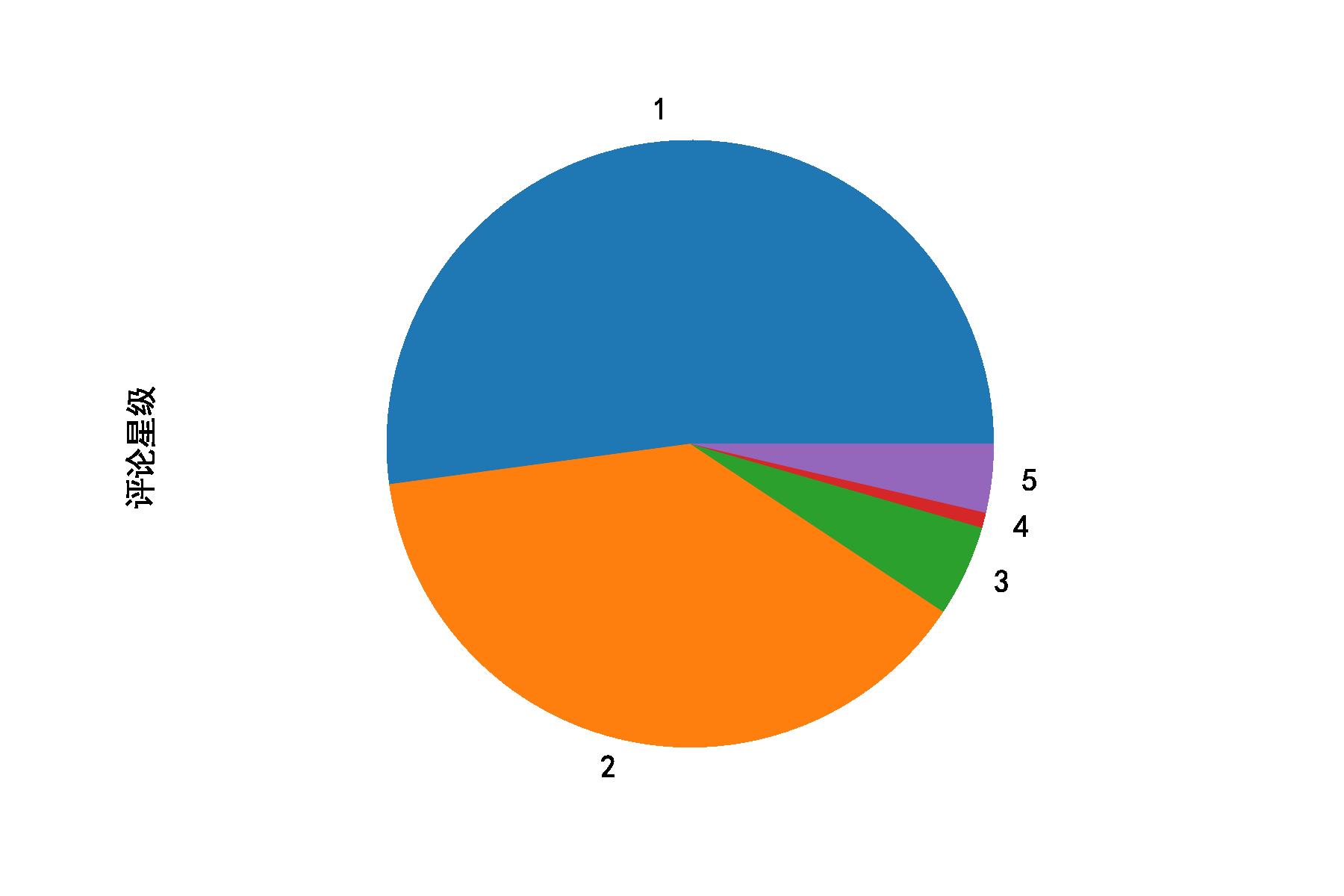
3)星级评分的饼图
剧究竟好不好,看看观众的评分少不了,这也是观众最直观的想法。
- 1星:很差
- 2星:较差
- 3星:还行
- 4星:推荐
- 1星:力荐
从下图中可以看出:大家对于该剧的哦=评价还是很低的,1星和2星基本占据了整个饼图,也就是说该剧并没有得到大家的认可。
4)大家主要都在评论一些啥
其实大家对于该剧最大的争论点,还是由张鲁一饰演的嬴政。40岁的张鲁一,竟然饰演13岁的少年嬴政,然后向36岁朱珠饰演的赵姬分享喜讯,这个角色显色很不协调。很多人支护:难道请不起小演员吗?
还有一部分人,对该剧的剧情和台词很是吐槽,嬴政称如果吕不韦是自己的生父,愿意跟他一起离开秦国浪迹天涯,这真的是少年老成的嬴政能说出来的话吗?
《大秦赋》是“大秦帝国”系列的第四部,原名为《大秦帝国之天下》,播出时改为了《大秦赋》。于是很多人将这部剧和2009年播出的《大秦帝国》作比较,以此来讽刺该剧。

好了,今天的分享就到此为止。如果你有更多的时间,更多的分析思路,可以下去拓展哦!
以上是关于《大秦赋》最近有点火!于是我用Python抓取了“相关数据”,发现了这些秘密......的主要内容,如果未能解决你的问题,请参考以下文章
耗时1年写出来的《原创手册》,知识点Excel+MySQL+Python全覆盖,限时免费下载!...