多轮检索式对话——WSDM 2019MRFN
Posted 卓寿杰_SoulJoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多轮检索式对话——WSDM 2019MRFN相关的知识,希望对你有一定的参考价值。
《Multi-Representation Fusion Network for Multi-turn Response Selection in Retrieval-based Chatbots》
本文的Motivation是建立在最近几年多轮检索式对话基于的面向交互的思想是。回想一下从Multi-view引入交互,到SMN完全基于交互,再到DAM多层交互。交互的粒度越多越work已经是大家的共识了。但如何更好的设计各个粒度之间的层次关系,减少不必要的性能浪费呢?作者提出把粒度划分为word, short-term, long-term三个粒度6种表示:
-
Word
- character Embedding: 利用字符级别的CNN(n-gram)解决typos/OOV的问题
- Word2Vec: 这里很简单的用了word2Vec。很显然用ELMo、Bert等会有更好的效果,当然效率上面就不太划算
-
Contextual
- Sequential: 借用GRU的结构实现句子中间子串信息的获取,RNN能保留短距离词之间的关系
- Local: 利用CNN获取N-gram的信息,CNN中卷积和池化,相对于获取中心词周围N-gram的信息
-
Attention-based(和DAM一样)
- self-Attention
- cross-Attention
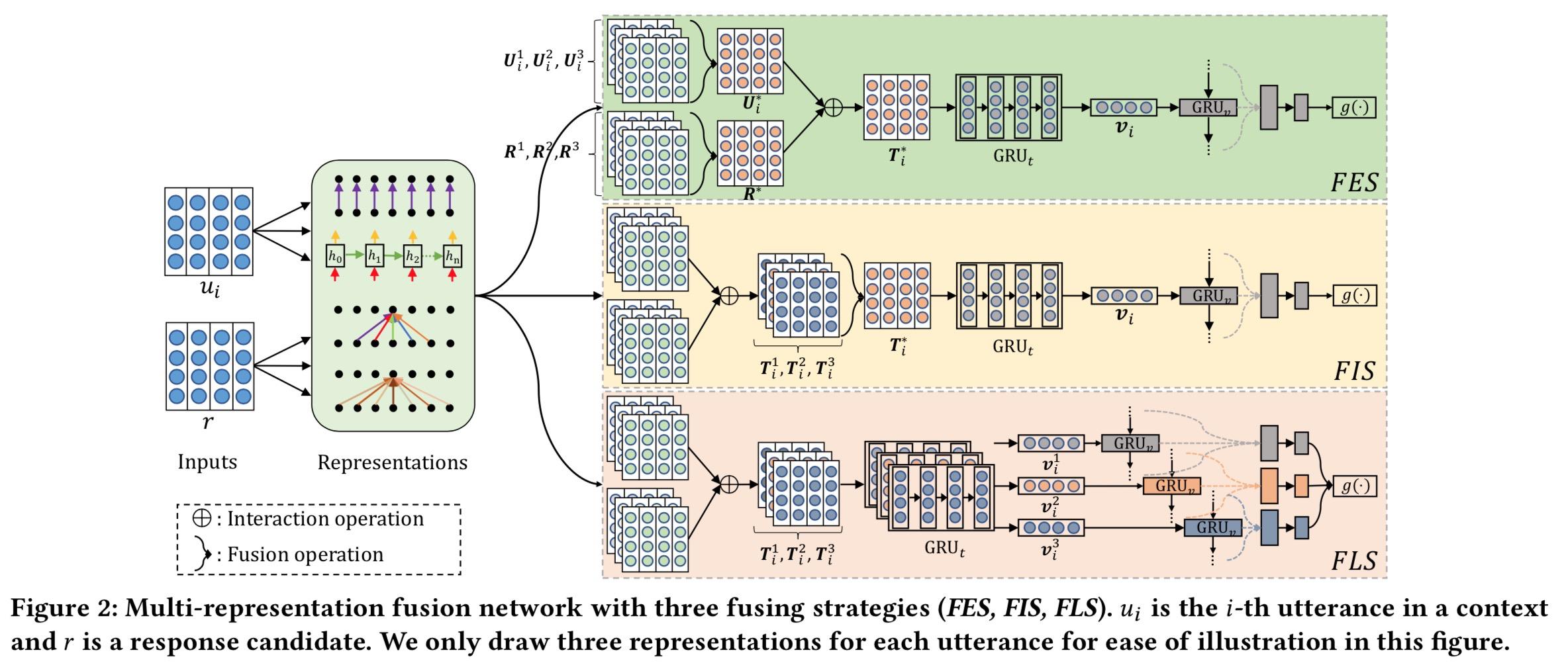
fusion操作其实就是把这6种representation进线融合,融合方式很简单,就是把6个矩阵连接成1个矩阵。根据fusion操作所在阶段位置的早、中、晚,可分为3个策略:
-
FES
- 第1到2列,就是在做fusion
- 第2列3列,做U、R 交互特征,
T
i
∗
T_i^*
Ti∗ 矩阵中的的各个向量为:
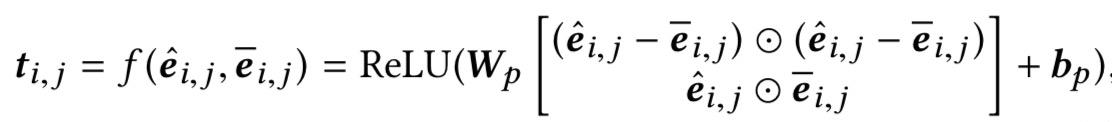
其中:
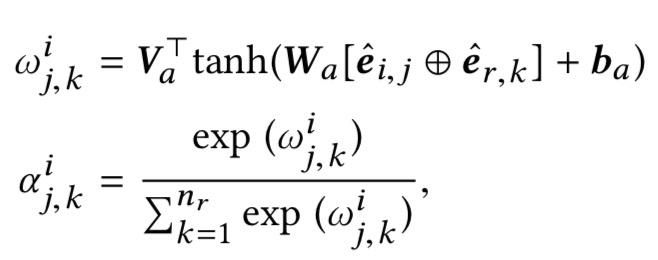
- 后续进行词粒度的GRU得到v,再进行utterance粒度的GRU,最后接MLP预测匹配分数
-
FIE
- 先做各个representation U、R交互特征,再fusion,之后的和FES一样
-
FLE
- 先做各个representation U、R交互特征,再做各个representation 词粒度的GRU 、utterance粒度的GRU,然后在MLP最后进行fusion。
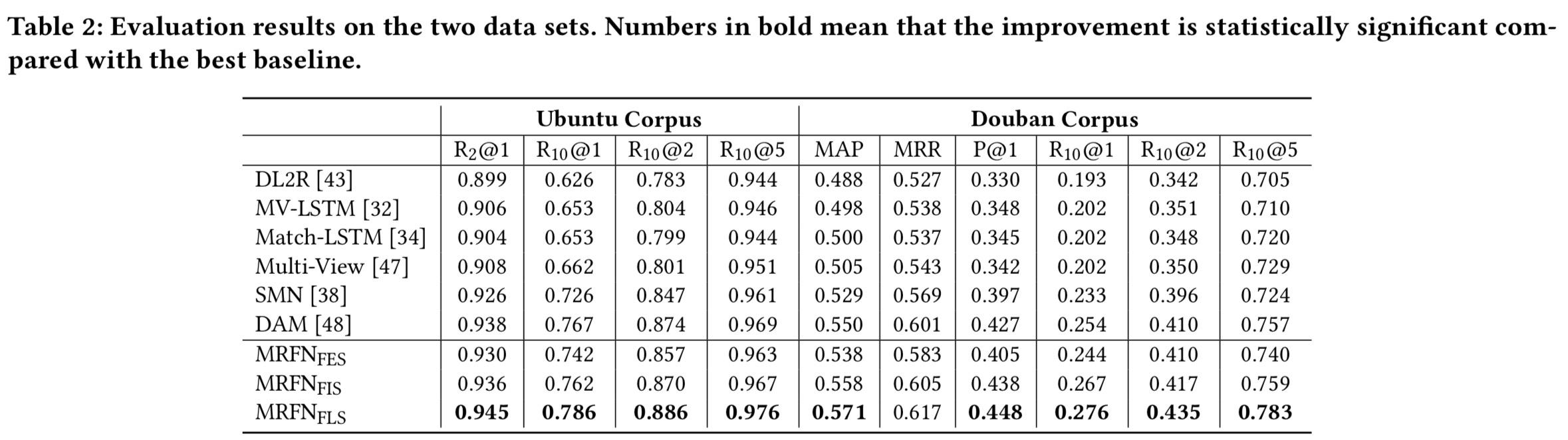
实验证明了FLE效果最好:
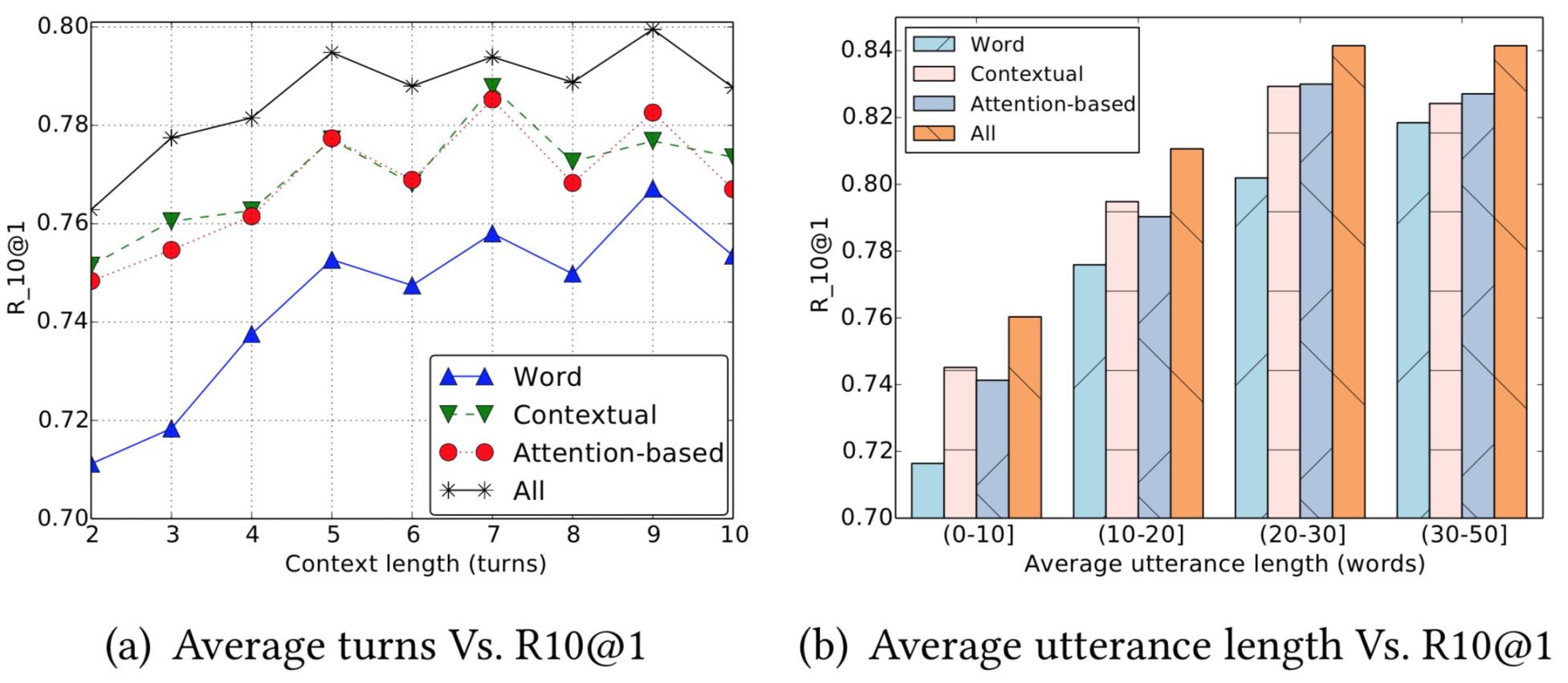
思考
首先我们发现utterance越长attention的优势被证明更明显。
其次作者认为结论是Contextual贡献最大,轮次少和很多的时候Contextual比Attention效果更好。个人看实验结果,不觉得能很明显的得出这样的结论。
作者认为,轮次少的时候可能RNN系列性能的确可以和attention相抗衡,轮次多的时候可以理解为当前的回复其实更多与附近的对话相关,与较远的对话关系反而远了,所以对于局部前文信息把握更多的Contextual可能会更好。可是个人理解,类似“对于局部前文信息把握更多”等多轮上下文位置与长度信息是由对v向量输入到GRU后表达出来的,应该与表示层、交互粒度没有太大关系。
以上是关于多轮检索式对话——WSDM 2019MRFN的主要内容,如果未能解决你的问题,请参考以下文章