一文入魂!聊透分布式系统一致性!
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文入魂!聊透分布式系统一致性!相关的知识,希望对你有一定的参考价值。
一、强一致性
一致性大家庭中,虽然细分种类很多,但是实际上只有两大类,其中之一就是强一致性,其具体包含了严格一致性(也叫原子一致性或者线性一致性)和顺序一致性。
-
严格(原子/线性)一致性
严格一致性代表着,当数据更新后,所有Client的读写都是在数据更新的基础上。如下图所示,我们假设每份数据有三个副本,分别落到三个节点上。当Client1尝试将X的值置为1时,严格一致性要求当Client1完成更新操作以后,所有Client都要在最新值的基础上进行读写,这里的Client10读取到的值是x=1,在同一时刻Client100的更新操作也是在x=1的基础上进行x+=1操作,在下一个时刻Client1000读到的任意一个副本,X的值都会是2。
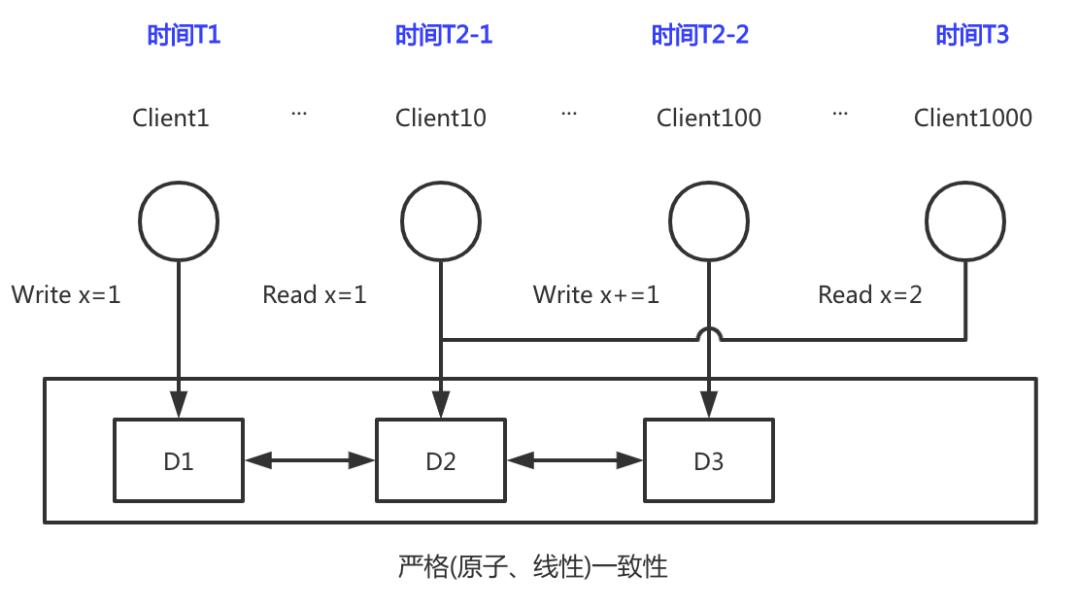
此时你会发现一切似乎都是很完美的。但是仔细想想,严格一致性的背后有什么潜台词呢?
1)数据同步复制
严格一致性代表着,所有数据在写入操作的时候是同步复制的,即写多副本都成功,才算写入成功,HDFS是不是就是最好的例子。并且具有原子性,对于写入操作来说,结果要么写成功,要么写失败,不存在中间状态。这也是为什么称为原子一致性的原因。
2)严格一致性不考虑客户端
在网上有很多人在解释一致性时,尝试从客户端和服务端分别解析;但是在上一篇我们分析CAP的时候,也有提到不要带Client玩,那么究竟谁对谁错呢?
这里我们再来看下,在考虑分布式系统的一致性时我们更关注什么?是多个Client发送读写请求到达后端的时间和先后顺序嘛?不,我们真正关注的是每个请求,对应服务端完成时间点的先后顺序。还是参考上面的例子,Client1000读取到x=2这个结果,实际上是以Client100这个写操作完成为基础的,如果Client100写操作一直不完成,那么强一致性要求Client1000读取到的X是1而不是2。因此我们更需要关注的是完成操作的具体时间点,而不是操作发起的时间点,对于一致性来说考虑Client的意义就不大了。当然在同一时刻多个Client操作的幂等性还是一定要保证的。
换个角度,Client才是一致性需求的甲方,不是嘛。而分布式系统端作为乙方,只能满足甲方需求,或者拒绝甲方需求,而不是要求甲方作出任何改变!
3) 基于严格的全局时钟
上面我们提到操作行为完成时间点的顺序是十分重要的。再仔细看一下上面举例的内容,相信你会发现一切的行为都在时间这个维度上,行为顺序是:Client1更新x=1 -> Client10读取x=1/Client100在x=1的基础上更新x+=1 -> Client1000读取x=2。所以每个操作都是在前一个操作完成的基础上进行的,在分布式服务中,需要有一个基准时间来衡量每个操作行为的顺序。此时你会问了,机器上不是都有NTP做时间校准嘛?现在的问题就是无法保证每一台机器的时间都是绝对相同的。
举个例子,数据D2所在的节点相比D1节点时间提前了几秒,当Client1的更新请求完成后(用时500ms),Client10的请求开始执行并完成,如果将机器时间作为基准就会发现Client10的读取操作竟然在Client1的更新操作之前,这显然是违背强一致性的。
我们一般我们会如何保证全局时钟?这里简单聊聊三种种常见解法。
-
混合逻辑时钟 Hybrid Logic Clock
在混合逻辑时钟中同时比较了节点本地的物理时间、逻辑时间和其他节点发送消息中的物理时间。kudu和Cockroachdb也都是使用的这个方法,HLC虽然加上了物理时间,但是仍然强依赖于机器的NTP,并不是严格意义上精确的时钟,在HLC中需要为时钟定义一个边界,比如kudu中定义了maximum check error(最大时钟错误),如果本地NTP没启动,kudu在启动的时候就直接失败了;如果误差超过了maximum check error,依旧会报错,这也就意味着当超过HLC所设定的偏差边界,HLC就不能正常工作了。
在看HLC的实现逻辑时,发现步骤比较多,逻辑时间存在的意义就是在时间比对时,当作中间值或者备份值。这里由于不是本篇重点,不再赘述了,感兴趣的小伙伴可以看下论文:https://cse.buffalo.edu/tech-reports/2014-04.pdf。
-
True Time
上一篇文章中也有讲到,谷歌依赖强大的基建实力降低了网络分区发生的概率,而面全局时钟问题,Google的Spanner采用的是GPS + Atomic Clock(原子时钟的含义可以百度一下)这种纯硬件方式来对集群的机器进行校时,其精度在ms级别,这里我们用ε来表示时间精度的误差,时间的精度误差的范围也就是[t-ε,t+ε]这个范围之间。此时回到上面的操作中,按照此种方式Client10的机器时间相比Client1的机器时间最多提前或者滞后2个ε的时间,因此Spanner引入了commit wait time这个方案,说白了就是操作执行完成后多等一会,等过了这个精度误差的范围自然就全局有序了,Google将精度误差控制在几ms级别,当然对于Spanner这种全球性、跨地域的分布式系统来说,多等个几ms问题也不大。
但很遗憾,Google的这套硬件解决方案,并没有开源出来,适用性有限,我们就望梅止渴吧。
-
授时中心 TimeStamp Oracle
在生活中也有”授时中心“的存在,貌似在陕西,具体位置可以查查,他的作用是什么呢?为中国各种基建、系统提供了一个准确的时间,避免误差。(个人YY:万一打起仗,总不能因为其他国家干扰了基准时间,咱们所有基建就瘫痪吧,因此授时中心的意义巨大。)
在分布式服务中,实际上也有类似的方案。这里以Tidb举例,Tidb为了校准时间,就是采用了TSO这个方案,对于Tidb来说所有行为事件统一由PD节点分配时间,虽然这种方案会产生非常高频的互相调用,但是按照Tidb官方介绍,在同IDC网络环境下网络传输开销非常低,只有0.xms。当然如果面对跨IDC的网络,就可以尝试将PD节点和Tidb节点混部(Tikv依然需要独立部署,为的是存储计算分离)。这就不需要走网络的开销了,当然如果是Client端跨IDC的话,还是没有太好的方法。
-
顺序一致性
上面我们说到了严格一致性(线性/原子),想做到全局时钟下的全局绝对有序是有难度的,HLC实现比较复杂,谷歌的原子钟+GPS又没有开源出来,TSO又增加了系统的复杂度。想实现全局时钟好难!
这里我们是否可以退一步,舍弃“时间”这个有序的计数器,尝试构造一个更好维护的计数器,不保证全局行为绝对有序,只保证分布式服务全局相对有序?
如下图所示,D1先后更新了x=1,x=2,D3先后更新了a=1,a=2。当Client读取到D2节点时,按照顺序一致性要求,所有节点的操作相对顺序都是相同的,一定是x=1在x=2之前,a=1在a=2之前,下图举例的是顺序一致性的其中一种情况。
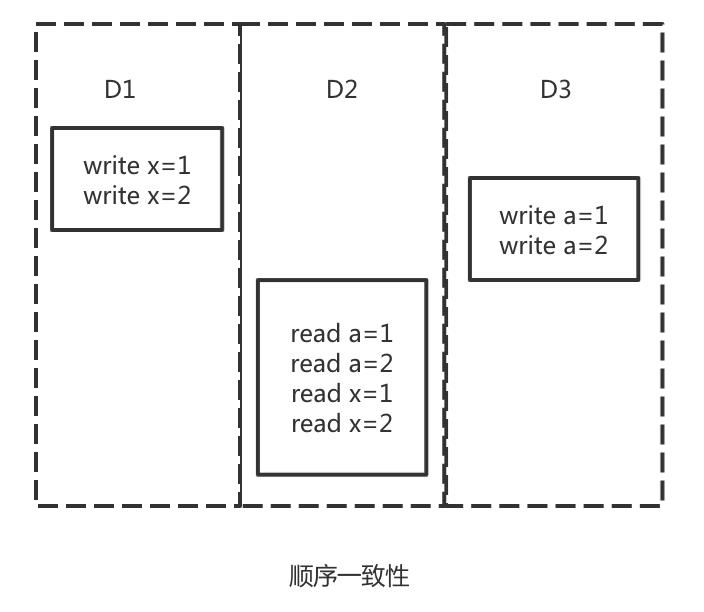
1)逻辑时钟 Logic Clock
逻辑时钟Logic Clock,这个名字你陌生的话,或许他的另一个名字Lamport Timestamp会让你浮想连连,如果你还是没啥印象的话,那么Paxos你是否知道呢?(如果做大数据的你不知道paxos,那你需要好好补习下基础了
以上是关于一文入魂!聊透分布式系统一致性!的主要内容,如果未能解决你的问题,请参考以下文章