分布式系统的时间问题
Posted 喔家ArchiSelf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统的时间问题相关的知识,希望对你有一定的参考价值。
序
一些技术点仿佛俯拾皆是,但很少有时间有精力把他们串起来形成体系,进而系统性地理解它们。象多人共著《深入分布式缓存》那样多角度认识缓存技术并不多见,“临渊羡鱼,不如退而结网”,石头兄弟的这篇关于时间的文字成于去年,历久反而弥新。
目录
1 什么是时间?
2 物理时间:墙上时钟
3 逻辑时钟:为事件定序
4 Turetime:物理时钟回归
5 区块链:重新定义时间
6 其他影响
6.1 NTP的时间同步
6.2 有限时间内的不可能性
6.3 延迟
6.4 租约
7 总结
8 参考文献

1 什么是时间?
时间是困扰了无数哲人的一个很抽象的概念。
伟人牛顿的绝对时空原理,可能代表了多数人的观点——时间在整个宇宙中是一个不变常量:
在牛顿的时空观念中,时间和空间是各自独立的,没有关联的两个事物。
绝对空间就像一间空房子,它区分物理事件发生的地点,用3维坐标来描述。
绝对时间就像一个滴答作响的秒表,它区别物理事件发生的先后次序,用不可逆转的1维坐标来描述。
“牛顿以为他知道时间是什么”——有人调侃说。在牛顿的绝对时空里,时间的概念是恒定的,在整个宇宙中是一致的,时间是度量事件先后的依据。这非常像我们的一个单一计算机或者紧耦合的计算机集群里,时间是明确的,事件进行的顺序也是明确的。在计算机科学最初的几十年里,我们从来没有想过计算机之间的时间问题。

另一位科学巨匠爱因斯坦,在他的狭义相对论中,主要有两点:
• 物理定律,包括时间,对所有的观察者来说是相同的。
• 光速不变。
而广义相对论说,整个时空都是一个引力场,时间和空间都不是连续的。
狭义相对论的主要意义是没有概念上的同时性,同时的概念相对于观察者,时间的推移也相对于观察者。同时,这一理论也说明了当事情发生在遥远的地方,我们需要时间去发现事情是否真的发生了。这个等待的时间可能很长。

分布式系统可能比爱因斯坦的宇宙还要糟糕。在分布式系统中,信息传播所需要的时间范围是不可预知的,可能远超过了阳光到达地球的8分钟。在这段时间内,无法知道网络另一端的计算机发生了什么。就算你可以通过发送消息来询问或探测,消息的投递和反馈总是要花费时间的。因此,系统延迟时间和超时值的设置是分布式系统的重要设计点之一。
“一切抽象都是数学,一切结论都是概率”,我们可以获得一个信息传播的统计结果,但无法知道每一次消息投递的准确时间。从这个角度上理解,分布式系统的正确运行都是运气很好的概率上,概率小到我们认为是高可靠的。
关于时间的本质,马赫(Ernst Mach)说:我们根本沒有能力以时间來测量事物的变化,相反的,我们是透过事物的变化因而产生时间流动的抽象概念。
在《七堂极简物理课》中,作者指出:只有存在热量的时候,过去和未来才有区别。能将过去和未来区分开来的基本现象就是热量总是从热的物体跑到冷的物体上。
所以,爱因斯坦说时间是幻像。从文学意义上说,不是时间定义了我们的生命,而是我们的生命定义了时间。
或许,这就是我们放弃物理时钟,使用逻辑时钟的背景吧!
2 物理时间:墙上时钟
物理时间,在英文文献中也称为wall clock。wall time,也称为真实世界的时间或挂钟时间,是指由钟表或挂钟等计时器确定的经过时间。(“wall”一词最初得名于对挂钟的引用。)

在计算机的世界里,中心化系统的时间是明确的。例如进程A和B分别在t1,t2时刻向系统的内核发起获得时间的系统调用,得到时间必然是t1<t2。这个简单的机制既是人类常规是时间思维,也是系统中各种功能正常运行所依赖的基础,可以说是常识或者共识。
单机系统中的时间依赖于石英钟,并且具有极小的时钟漂移。
3 逻辑时钟:为事件定序
分布式系统中的同步和异步都是对物理时间做的假设,但是,逻辑时钟第一次摆脱了物理时钟的限制。
逻辑时钟认为分布式系统中的机器可以无法对时间达成一致,但是对时间发生顺序是一致认同的。一个消息不能在被发送之前收到,这样,如果一个进程A向进程B发送了消息,我们可以认为A发生在B之前。
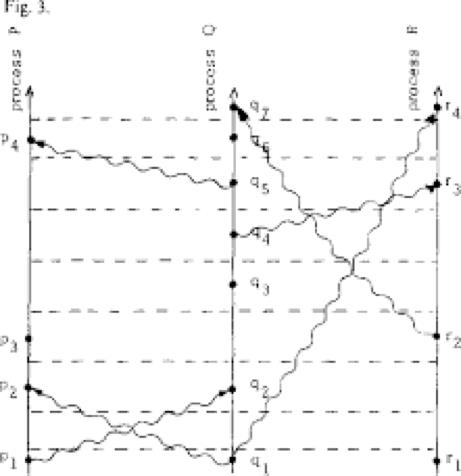
这样就定义了分布式系统中不同节点上不同事件之间的因果关系,后来衍生的向量时钟也是同样的道理。
本质上来说,逻辑时钟定义了事件到整数值的映射。所以很多逻辑时钟的实现都采用单调递增的软件计数器,这个计数器的值与任何物理时钟都没有关系。分布式系统中的节点和进程在使用逻辑时钟时,为事件加上逻辑时钟的时间戳,比如文件读写和数据库更新等。
逻辑时钟的贡献来自于Leslie Lamport在1978年发表的一篇论文《Time, Clocks, and the Ordering of Events in a Distributed System》。

4 Truetime:物理时钟回归
Google的Spanner提出了一种新的思路,在不进行通信的情况下,利用高精度和可观测误差的本地时钟 (TrueTime API)给事件打上时间戳,并且以此比较分布式系统中两个事件的先后顺序。利用这个方法,Spanner实现了事务之间的外部一致性(external consistency,如下图所示)。
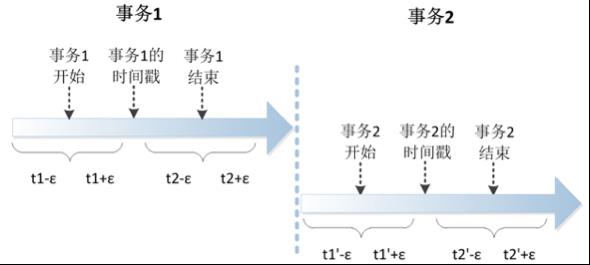
也就是说,一个事务结束后另一个事务才开始,Spanner可以保证第一个事务的时间戳比第二个事务的时间戳要早,从而两个事务被序列化后也一定能保持正确的顺序。
TrueTime API是一个提供本地时间的接口,但与Linux上gettimeofday接口不一样,它除了可以返回一个时间戳t,还会给出一个误差ε。例如,返 回的时间戳是1分30秒350毫秒,而误差是5毫秒,那么真实的时间在1分30秒345毫秒到355毫秒之间。真实的系统中ε平均下来是4毫秒。
利用TrueTime API,Spanner可以保证给出事务标记的时间戳介于事务开始的真实时间和事务结束的真实时间之间。假如事务开始时TrueTime API返回的时间是{t1, ε1},此时真实时间在 t1-ε1到t1+ε1之间;事务结束时TrueTime API返回的时间是{t2, ε2},此时真实时间在t2-ε2到t2+ε2之间。Spanner会在t1+ε1和t2-ε2之间选择一个时间点作为事务的时间戳,但这需要保证 t1+ε1小于t2-ε2,为了保证这点,Spanner会在事务执行过程中等待,直到t2-ε2大于t1+ε1时才提交事务。由此可以推导出,Spanner中一个事务至少需要2ε的时间(平均8毫秒)才能完成。
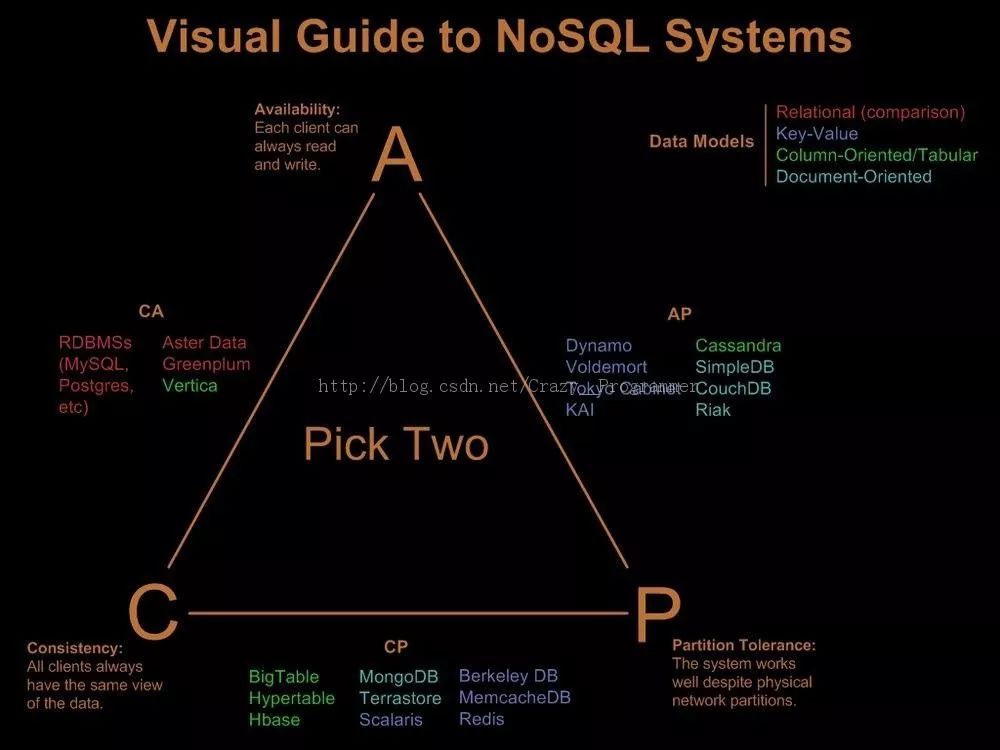
由此可见,这种新方法虽然避免了通信开销,却引入了等待时间。为了保证外部一致性,写延迟是不可避免的,这也印证了CAP定理所揭示的法则,一致性与延迟之间是需要权衡的。
为什么Google要采用这样设计呢?
Truetime根本上解决了什么问题?
Spanner是要解决全球规模分布式系统中关于时间的两大难题:
在数据中心之间同步时间是超级困难和不确定的
在全球规模范围内序列化请求是不可能的
解决这些问题的办法是接受不确定性,使用GPS和原子时钟,把不确定性减低到最小。对于 Spanner这样全球部署或者跨地域部署的系统,如何来为事务分配 timestamp, 才能保证系统的响应时间在可接受的范围内? 如果整个系统采用一个中心节点来分配时间戳, 那么系统的响应时间就变得非常不可控,对于离中心节点隔了半圈地球的用户来说, 响应时间估计会是100ms 级别。
如何理解turetime 呢?要弄明白truetime在事务操作中作用,首先看一下Spanner支持的几种事务类型:
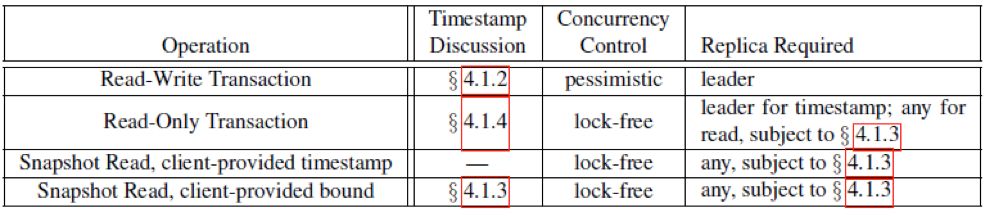
简单只读事务。Spanner设计的只读事务有以下要求:
客户程序自己实现重试动作
读操作要显式的声明没有写(例如只读打开一个文件)
系统无需获得锁,不阻塞读过程中进来的写操作
系统自己选择一个时间戳,用来确定读取副本的时间戳
任何一个满足时间戳的副本都可以用作读操作
当然,快照读就更简单了,无锁的读取过去的快照,客户可以指定时间戳,也可以让系统选择一个时间戳,无需赘述。
读写事务则使用两阶段锁,来保证外部一致性:

Spanner 利用truetime机制,把系统中的操作按照发生的先后顺序,构造一个 Linearizability 的运行记录。所以,我们说Spanner是实现Linearizability的系统。
总结来说,Spanner 是采用全球同步(有一定误差)的物理时间truttime戳作为系统的时间戳,并且作为系统内各种操作的版本号。
5 区块链:重新定义时间
中本聪在比特币一文——《Bitcoin: A Peer-to-Peer Electronic Cash System》中提出了时间戳服务器模型,并奠定了区块链的基础。为了解决双花问题,中本聪设想了一个去中心化的自验证体系:
在基于铸币的模型中,铸币方知道所有的交易并决定哪个先到达。要在没有可信方的情况下完成此任务,必须公开宣布交易,并且我们需要一个系统,让参与者就接收它们的顺序的单一历史记录达成共识。收款人需要一个证明:对于一个交易,大多数节点都同意该交易是第一个收到的。
我们建议的解决方案是从时间戳服务器开始的。时间戳服务器的工作方式是获取要加盖时间戳的数据块的散列,并广泛地发布散列,就像在报纸或Usenet post上发布一样。显然,时间戳证明了数据必须在那个时候存在,以便进入散列。每个时间戳散列包含前一个时间戳的散列,由此形成一个链,每个后续的时间戳都会增强前一个时间戳的有效性。

这样,区块链作为时间机器的滴答机制就形成了,一个区块高度对应一个时间窗口,这是为什么区块链也被称为时间机器的原因。为了让时钟跳动均匀,POW区块链会自动调整算法难度,维持滴答周期在一个平均的物理时间范围内,比如比特币是在10分钟左右,以太坊在15秒左右。非POW的区块链也维护这样的时钟滴答,比如filecoin测试网维护在45秒左右。
进一步,非POW的区块链维护固定的时钟滴答是很难的,再以filecoin为例,采用在全网采用UTC时间戳(类似前面谷歌的做法)来实现固定的物理时间间隔,这要求全网的服务器都和NTP服务器同步,并限制了严格的时钟飘移范围(1s)。因为区块链这样的时间机器特性,才让链上的数据在没有分叉的情况下无法篡改。也正因为这样,区块链才让人联想到物理时间的消逝,熵的增加,能量的耗散,以及“青春散场、昨日不再”。
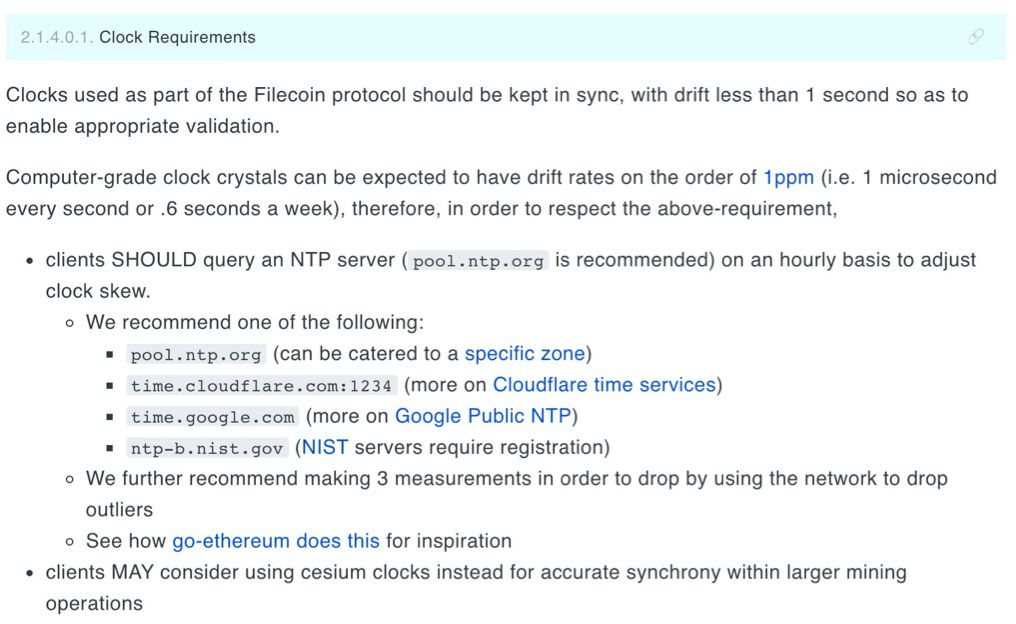
由区块链的本质引申开来,研究者试图找到替代的解决方案。其中一个非常有吸引力的方案是VDF。VDF是 Verifiable Delay Function的缩写,可验证延迟函数VDF的概念是斯坦福大学计算机科学和电子工程教授、计算机安全实验室联合主任Dan Boneh在Crypto 2018大会发布的《Verifiable Delay Functions》论文中首次提出的。Function说明了VDF是一个函数,对每一个输入都有一个唯一的输出。Delay 可以用一个时间T(wall time)来表示,延迟函数在时间T完成计算,但不能通过并行加速在小于时间T完成计算。Verifiable 要求延迟函数的输出非常容易验证。详细请阅读《》一文。
Function:
§ unique output for everyinput
Delay:
§ can be evaluated in time T
§ can not be evaluated intime <T on parallel
Verifiable:
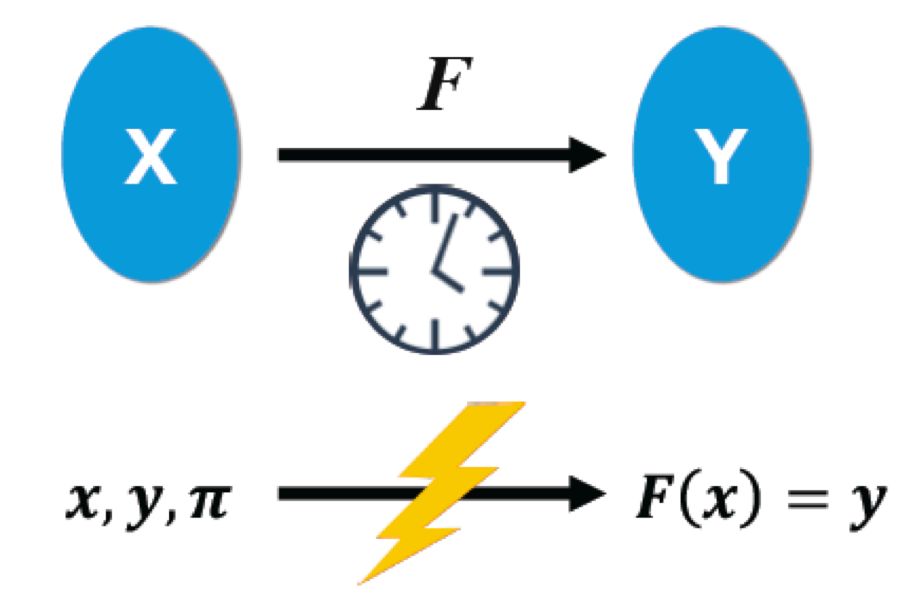
VDF计算过程最重要的一点是:在计算时要求大量计算资源,但验证时只需花费相对少的计算资源。这样的计算和验证的非对称关系乍看起来有点像工作量证明(PoW)。于是,批评接踵而至:“ 听起来我们又回到了工作量证明 ”,“ 不再烧一轮 CPU 我们就干不了这事是吗 ?”——文献《VDF不是工作量证明》一文指出:虽然 VDF 和传统的 PoW 算法都拥有“难以计算”且“易于验证”这样的属性,最核心的区别在于,区块链工作量证明的共识算法是可并行化的工作量证明,并且只是有概率会成功,不是一种函数。相反,VDF 是连续工作量证明,是确定的函数。

关于VDF和PoW的区别,已有很多争论。总体来说,PoW 直接作为随机数的来源是有缺陷的,同时,VDF 也无法直接替代 PoW。但是,这并不能说明 VDF 不可以被用到共识协议里。原因如下:
• PoW 不抵抗并行计算加速而 VDF 是抵抗的。实际上,PoW 不抗并行计算加速是符合中本聪关于“一个 CPU 一票”的设想的,而抗并行加速的性质只会与这个目的背道而驰。VDF 会使得多 CPU 的计算者和单 CPU 的计算者相比几乎没有什么优势。
• 对于固定的难度设定 d,PoW 可以有很多合法的解,这也是保证 PoW 共识网络拥有稳定的吞吐量以及刺激矿工进行竞争的前提。而对于给定输入 x,VDF 拥有唯一的输出(这也是为什么它被称作函数)。
总体来说,VDF很好的刻画了区块链对于时间滴答机制的本质需求。在一些非PoW区块链和非区块链的领域,都有大量研究和探索,比如协议实验室和以太坊联合成立的实验室,以及大量对VDF感兴趣的项目。
注:filecoin的协议实现也在考虑VDF:
Future versions of the Filecoin protocol may use Verifiable Delay Functions (VDFs) to strongly enforce block time and fulfill this leader election requirement; we choose to explicitly assume clock synchrony until hardware VDF security has been proven more extensively.
6 其他影响
和影响人们的生活一样,时间更是影响了计算机系统的方方面面,也自然影响了我们。
6.1 NTP的时间同步
在分布式系统中,关于时间的共识是非常困难的。不同机器中石英钟的频率可能不一致,这会导致不同机器中时间并不一致。为了同步不同机器中的时间,人们提出了NTP协议。这样,一个机器的时间就会依赖于另外一个外部时钟。

NTP协议基于这样原理:网络通信延迟来回是相等的。基于此可以获得两台机器时间差值 。在NTP服务器(上)获得的时间再加上(时间落后本机)或减去(时间领先本机)这个延迟就可以设置为本地的时间,由此获得时间同步。
6.2 有限时间内的不可能性
1985年,Fischer,Lynch和Patterson发布了他们著名FLP成果(Impossibility of distributed consensus with one faulty process):在异步的系统中,如果存在进程故障,系统是不可能达成一致的。FLP表明,当至少有一个进程可能崩溃时,没有一种确定性地解决异步环境中共识问题的算法。在工程应用中,这个理论也可以理解为:在不稳定故障的异步系统中,不可能有一个完美的故障检测器。
根本的原因在于时间。FLP结果并不意味着共识是无法达到的,只是在有限的时间内并不总是可以达到的。同步系统在进程和进程计算之间为消息传递提供了一个已知的上限。异步系统没有固定的上限。
在《分布式系统:概念与设计》一书中,作者针对FLP指出:在分布式系统中,并不是说,如果有一个进程出现了故障,进程就永远不可能达到共识。它允许我们达到共识的概率大于0,这也是与实际情况相符合的。例如现在运行在广域网上的分布式系统,都是异步的,但是事务系统这么多年来一直都能达到共识。
所以,FLP表述为:在有限的时间内,不可能达成一致。系统可能或者极有可能达成一致,但这不是保证的。也就是说, 在异步的系统中,有限时间内达到一致性是不可能的。在分布式计算上,试图在异步系统和不可靠的通道上达到一致性是不可能的。
因此,一般的一致性前提都是要求保证:在这里我们不考虑拜占庭类型的错误,同时假设消息系统是可靠的。因此,对一致性的研究一般假设信道是可靠的,或不存在异步系统在运行。
概率,深刻的影响着分布式系统可靠性。世界的概率本质虽然不能让我们准确的推断未来,但是对于预测消息是否准确传递却绰绰有余。想一想,我们知道在有限时间内达到绝对的一致性是不可能的,那为什么程序员自信的设置超时值为5秒呢?
就像这个世界的概率本质一样,分布式系统同样构建在概率的基础之上。
6.3 延迟
很多人把延迟归类到网络延迟,指数据在传输介质中传输所用的时间,即从报文开始进入网络到它开始离开网络之间的时间。实际上,在计算机世界里,延迟无所不在。
除了VDF之外,程序员可能还要知道下面的这些时间数字:
L1 cache reference ......................... 0.5 ns
Branch mispredict ............................ 5 ns
L2 cache reference ........................... 7 ns
Mutex lock/unlock ........................... 25 ns
Main memory reference ...................... 100 ns
Compress 1K bytes with Zippy ............. 3,000 ns = 3 µs
Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs
SSD random read ........................ 150,000 ns = 150 µs
Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs
Round trip within same datacenter ...... 500,000 ns = 0.5 ms
Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms
Disk seek ........................... 10,000,000 ns = 10 ms
Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms
Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
......

6.4 租约
租约(lease)在分布式系统中的一般描述如下:
租约是由授权者授予的在一段时间内的承诺。
授权者一旦发出租约,则无论接受方是否收到,也无论后续接收方处于何种状态,只要租约 不过期,授权者一定遵守承诺,按承诺的时间、内容执行。
接收方在有效期内可以使用授权者的承诺,只要租约过期,接收方将放弃授权,不再继续执行,如果重新执行需要重新申请租约。
通过版本号、时间周期,或者到某个固定时间点认为租约的证书失效
租约可以说是分布式系统的心跳机制。在分布式系统中,像分布式锁,集群leader这样角色,可能随时变化。为了避免死锁,或者错误的leader认知,一般都要设计租约机制。
7 总结
本文主要回顾了计算机系统演进过程中的时间问题,特别是古典分布式系统的时间问题,以及由时间带来的顺序问题;探讨了最新支持拜占庭容错的区块链网络系统的时间本质,以及在可验证延迟函数方面的最新探索。
目前的分布式系统无法超越时空的限制来运行,系统的设计也受到时空考虑范围的约束。而未来,量子计算机将会在时空约束方面带来哪些改变,值得期待。
8 参考文献
http://physics.ucr.edu/~wudka/Physics7/Notes_www/node55.html
https://queue.acm.org/detail.cfm?id=2655736
http://history.programmer.com.cn/14015/
https://www.geekhub.cn/a/1681.html
http://muratbuffalo.blogspot.fi/2013/07/spanner-googles-globally-distributed4.html
http://blog.sina.com.cn/s/blogc35ad45b0102wa53.html
http://duanple.blog.163.com/blog/static/709717672012920101343237/
https://en.wikipedia.org/wiki/Lease(computerscience)
Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services Time, Clocks, and the Ordering of Events in a Distributed System
Viewstamped Replication: A New Primary Copy Method to Support Highly-Available Distributed Systems Probabilistic Accuracy Bounds for Fault-Tolerant Computations that Discard Tasks
https://quizlet.com/blog/quizlet-cloud-spanner
http://baike.baidu.com/link?url=upN85rlJXR69lDiYxYy_aFEecj1t3D5vTwIuUXPMN2rz9xKkYlPK-UEOMjA13PWwuuKXNPnE8YXlMJzluqHHpq
http://duanple.blog.163.com/blog/static/70971767201122011858775/
https://zh.wikipedia.org/wiki/%E6%8B%9C%E5%8D%A0%E5%BA%AD%E5%B0%86%E5%86%9B%E9%97%AE%E9%A2%98
https://people.eecs.berkeley.edu/~rcs/research/interactivelatency.html
http://highscalability.com/blog/2013/1/15/more-numbers-every-awesome-programmer-must-know.html
https://wondernetwork.com/pings/
https://gist.github.com/jboner/2841832
https://gist.github.com/hellerbarde/2843375
https://people.eecs.berkeley.edu/~rcs/research/interactivelatency.html
http://link.springer.com/article/10.1023/A:1019121024410
https://www.infoq.com/articles/pritchett-latency
http://highscalability.com/blog/2012/3/12/google-taming-the-long-latency-tail-when-more-machines-equal.html
https://github.com/colin-scott/interactive_latencies
http://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
以上是关于分布式系统的时间问题的主要内容,如果未能解决你的问题,请参考以下文章