一文掌握 Linux 内存管理
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文掌握 Linux 内存管理相关的知识,希望对你有一定的参考价值。

作者:dengxuanshi,腾讯 IEG 后台开发工程师
以下源代码来自 linux-5.10.3 内核代码,主要以 x86-32 为例。
Linux 内存管理是一个很复杂的“工程”,它不仅仅是对物理内存的管理,也涉及到虚拟内存管理、内存交换和内存回收等
物理内存的探测
Linux 内核通过 detect_memory()函数实现对物理内存的探测
void detect_memory(void)
{
detect_memory_e820();
detect_memory_e801();
detect_memory_88();
}
这里主要介绍一下 detect_memory_e820(),detect_memory_e801()和 detect_memory_88()是针对较老的电脑进行兼容而保留的
static void detect_memory_e820(void)
{
int count = 0;
struct biosregs ireg, oreg;
struct boot_e820_entry *desc = boot_params.e820_table;
static struct boot_e820_entry buf; /* static so it is zeroed */
initregs(&ireg);
ireg.ax = 0xe820;
ireg.cx = sizeof(buf);
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
do {
intcall(0x15, &ireg, &oreg);
ireg.ebx = oreg.ebx; /* for next iteration... */
if (oreg.eflags & X86_EFLAGS_CF)
break;
if (oreg.eax != SMAP) {
count = 0;
break;
}
*desc++ = buf;
count++;
} while (ireg.ebx && count < ARRAY_SIZE(boot_params.e820_table));
boot_params.e820_entries = count;
}
detect_memory_e820()实现内核从 BIOS 那里获取到内存的基础布局,之所以叫 e820 是因为内核是通过 0x15 中断向量,并在 AX 寄存器中指定 0xE820,中断调用后将会返回被 BIOS 保留的内存地址范围以及系统可以使用的内存地址范围,所有通过中断获取的数据将会填充在 boot_params.e820_table 中,具体 0xE820 的详细用法感兴趣的话可以上网查……这里获取到的 e820_table 里的数据是未经过整理,linux 会通过 setup_memory_map 去整理这些数据
start_kernel() -> setup_arch() -> setup_memory_map()
void __init e820__memory_setup(void)
{
char *who;
BUILD_BUG_ON(sizeof(struct boot_e820_entry) != 20);
who = x86_init.resources.memory_setup();
memcpy(e820_table_kexec, e820_table, sizeof(*e820_table_kexec));
memcpy(e820_table_firmware, e820_table, sizeof(*e820_table_firmware));
pr_info("BIOS-provided physical RAM map:\\n");
e820__print_table(who);
}
x86_init.resources.memory_setup()指向了 e820__memory_setup_default(),会将 boot_params.e820_table 转换为内核自己使用的 e820_table,转换之后的e820 表记录着所有物理内存的起始地址、长度以及类型,然后通过 memcpy 将 e820_table 复制到 e820_table_kexec、e820_table_firmware
struct x86_init_ops x86_init __initdata = {
.resources = {
.probe_roms = probe_roms,
.reserve_resources = reserve_standard_io_resources,
.memory_setup = e820__memory_setup_default,
},
......
}
char *__init e820__memory_setup_default(void)
{
char *who = "BIOS-e820";
/*
* Try to copy the BIOS-supplied E820-map.
*
* Otherwise fake a memory map; one p from 0k->640k,
* the next p from 1mb->appropriate_mem_k
*/
if (append_e820_table(boot_params.e820_table, boot_params.e820_entries) < 0) {
u64 mem_size;
/* Compare results from other methods and take the one that gives more RAM: */
if (boot_params.alt_mem_k < boot_params.screen_info.ext_mem_k) {
mem_size = boot_params.screen_info.ext_mem_k;
who = "BIOS-88";
} else {
mem_size = boot_params.alt_mem_k;
who = "BIOS-e801";
}
e820_table->nr_entries = 0;
e820__range_add(0, LOWMEMSIZE(), E820_TYPE_RAM);
e820__range_add(HIGH_MEMORY, mem_size << 10, E820_TYPE_RAM);
}
/* We just appended a lot of ranges, sanitize the table: */
e820__update_table(e820_table);
return who;
}
内核使用的e820_table 结构描述如下:
enum e820_type {
E820_TYPE_RAM = 1,
E820_TYPE_RESERVED = 2,
E820_TYPE_ACPI = 3,
E820_TYPE_NVS = 4,
E820_TYPE_UNUSABLE = 5,
E820_TYPE_PMEM = 7,
E820_TYPE_PRAM = 12,
E820_TYPE_SOFT_RESERVED = 0xefffffff,
E820_TYPE_RESERVED_KERN = 128,
};
struct e820_entry {
u64 addr;
u64 size;
enum e820_type type;
} __attribute__((packed));
struct e820_table {
__u32 nr_entries;
struct e820_entry entries[E820_MAX_ENTRIES];
};
memblock 内存分配器
linux x86 内存映射主要存在两种方式:段式映射和页式映射。linux 首次进入保护模式时会用到段式映射(加电时,运行在实模式,任意内存地址都能执行代码,可以被读写,这非常不安全,CPU 为了提供限制/禁止的手段,提出了保护模式),根据段寄存器(以 8086 为例,段寄存器有 CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器)查找到对应的段描述符(这里其实就是用到了段描述符表,即段表),段描述符指明了此时的环境可以通过段访问到内存基地址、空间大小和访问权限。访问权限则点明了哪些内存可读、哪些内存可写。
typedef struct Descriptor{
unsigned int base; // 段基址
unsigned int limit; // 段大小
unsigned short attribute; // 段属性、权限
}
linux 在段描述符表准备完成之后会通过汇编跳转到保护模式
事实上,在上面这个过程中,linux 并没有明显地去区分每个段,所以这里并没有很好地起到保护作用,linux 最终使用的还是内存分页管理(开启页式映射可以参考/arch/x86/kernel/head_32.S)
memblock 算法
memblock 是 linux 内核初始化阶段使用的一个内存分配器,实现较为简单,负责页分配器初始化之前的内存管理和分配请求,memblock 的结构如下
struct memblock_region {
phys_addr_t base;
phys_addr_t size;
enum memblock_flags flags;
#ifdef CONFIG_NEED_MULTIPLE_NODES
int nid;
#endif
};
struct memblock_type {
unsigned long cnt;
unsigned long max;
phys_addr_t total_size;
struct memblock_region *regions;
char *name;
};
struct memblock {
bool bottom_up; /* is bottom up direction? */
phys_addr_t current_limit;
struct memblock_type memory;
struct memblock_type reserved;
};
bottom_up:用来表示分配器分配内存是自低地址向高地址还是自高地址向低地址
current_limit:用来表示用来限制 memblock_alloc()和 memblock_alloc_base()的内存申请
memory:用于指向系统可用物理内存区,这个内存区维护着系统所有可用的物理内存,即系统 DRAM 对应的物理内存
reserved:用于指向系统预留区,也就是这个内存区的内存已经分配,在释放之前不能再次分配这个区内的内存区块
memblock_type中的cnt用于描述该类型内存区中的内存区块数,这有利于 MEMBLOCK 内存分配器动态地知道某种类型的内存区还有多少个内存区块
memblock_type 中的max用于描述该类型内存区最大可以含有多少个内存区块,当往某种类型的内存区添加 内存区块的时候,如果内存区的内存区块数超过 max 成员,那么 memblock 内存分配器就会增加内存区的容量,以此维护更多的内存区块
memblock_type 中的total_size用于统计内存区总共含有的物理内存数
memblock_type 中的regions是一个内存区块链表,用于维护属于这类型的所有内存区块(包括基址、大小和内存块标记等),
name :用于指明这个内存区的名字,MEMBLOCK 分配器目前支持的内存区名字有:“memory”, “reserved”, “physmem”
具体关系可以参考下图:

内核启动后会为 MEMBLOCK 内存分配器创建了一些私有的 p,这些 p 用于存放于 MEMBLOCK 分配器有关的函数和数据,即 init_memblock 和 initdata_memblock。在创建完 init_memblock p 和 initdata_memblock p 之后,memblock 分配器会开始创建 struct memblock 实例,这个实例此时作为最原始的 MEMBLOCK 分配器,描述了系统的物理内存的初始值
#define MEMBLOCK_ALLOC_ANYWHERE (~(phys_addr_t)0) //即0xFFFFFFFF
#define INIT_MEMBLOCK_REGIONS 128
#ifndef INIT_MEMBLOCK_RESERVED_REGIONS
# define INIT_MEMBLOCK_RESERVED_REGIONS INIT_MEMBLOCK_REGIONS
#endif
static struct memblock_region memblock_memory_init_regions[INIT_MEMBLOCK_REGIONS] __initdata_memblock;
static struct memblock_region memblock_reserved_init_regions[INIT_MEMBLOCK_RESERVED_REGIONS] __initdata_memblock;
struct memblock memblock __initdata_memblock = {
.memory.regions = memblock_memory_init_regions,
.memory.cnt = 1, /* empty dummy entry */
.memory.max = INIT_MEMBLOCK_REGIONS,
.memory.name = "memory",
.reserved.regions = memblock_reserved_init_regions,
.reserved.cnt = 1, /* empty dummy entry */
.reserved.max = INIT_MEMBLOCK_RESERVED_REGIONS,
.reserved.name = "reserved",
.bottom_up = false,
.current_limit = MEMBLOCK_ALLOC_ANYWHERE,
};
内核在 setup_arch(char **cmdline_p)中会调用e820__memblock_setup()对 MEMBLOCK 内存分配器进行初始化启动
void __init e820__memblock_setup(void)
{
int i;
u64 end;
memblock_allow_resize();
for (i = 0; i < e820_table->nr_entries; i++) {
struct e820_entry *entry = &e820_table->entries[i];
end = entry->addr + entry->size;
if (end != (resource_size_t)end)
continue;
if (entry->type == E820_TYPE_SOFT_RESERVED)
memblock_reserve(entry->addr, entry->size);
if (entry->type != E820_TYPE_RAM && entry->type != E820_TYPE_RESERVED_KERN)
continue;
memblock_add(entry->addr, entry->size);
}
/* Throw away partial pages: */
memblock_trim_memory(PAGE_SIZE);
memblock_dump_all();
}
memblock_allow_resize() 仅是用于置 memblock_can_resize 的值,里面的 for 则是用于循环遍历 e820 的内存布局信息,然后进行 memblock_add 的操作
int __init_memblock memblock_add(phys_addr_t base, phys_addr_t size)
{
phys_addr_t end = base + size - 1;
memblock_dbg("%s: [%pa-%pa] %pS\\n", __func__,
&base, &end, (void *)_RET_IP_);
return memblock_add_range(&memblock.memory, base, size, MAX_NUMNODES, 0);
}
memblock_add()主要封装了 memblock_add_region(),且它操作对象是 memblock.memory,即系统可用物理内存区。
static int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, enum memblock_flags flags)
{
bool insert = false;
phys_addr_t obase = base;
//调整size大小,确保不会越过边界
phys_addr_t end = base + memblock_cap_size(base, &size);
int idx, nr_new;
struct memblock_region *rgn;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 1 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
return 0;
}
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accommodate the new area. The second actually inserts them.
*/
base = obase;
nr_new = 0;
for_each_memblock_type(idx, type, rgn) {
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
/*
* @rgn overlaps. If it separates the lower part of new
* area, insert that portion.
*/
if (rbase > base) {
#ifdef CONFIG_NEED_MULTIPLE_NODES
WARN_ON(nid != memblock_get_region_node(rgn));
#endif
WARN_ON(flags != rgn->flags);
nr_new++;
if (insert)
memblock_insert_region(type, idx++, base,
rbase - base, nid,
flags);
}
/* area below @rend is dealt with, forget about it */
base = min(rend, end);
}
/* insert the remaining portion */
if (base < end) {
nr_new++;
if (insert)
memblock_insert_region(type, idx, base, end - base,
nid, flags);
}
if (!nr_new)
return 0;
/*
* If this was the first round, resize array and repeat for actual
* insertions; otherwise, merge and return.
*/
if (!insert) {
while (type->cnt + nr_new > type->max)
if (memblock_double_array(type, obase, size) < 0)
return -ENOMEM;
insert = true;
goto repeat;
} else {
memblock_merge_regions(type);
return 0;
}
}
如果 memblock 算法管理的内存为空时,将当前空间添加进去
不为空的情况下,for_each_memblock_type(idx, type, rgn)这个循环会检查是否存在内存重叠的情况,如果有的话,则剔除重叠部分,然后将其余非重叠的部分插入 memblock。内存块的添加主要分为四种情况(其余情况与这几种类似),可以参考下图:
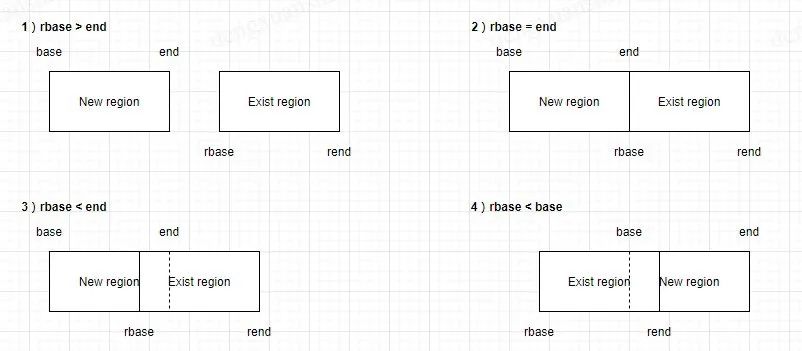
如果 region 空间不够,则通过 memblock_double_array()添加新的空间,然后重试。
最后 memblock_merge_regions()会将紧挨着的内存进行合并(节点号、flag 等必须一致,节点号后面再进行介绍)。
memblock 内存分配与回收
到这里,memblock 内存管理的初始化基本完成,后面还有一些关于 memblock.memory 的修正,这里就不做介绍了,最后也简单介绍一下memblock 的内存分配和回收,即 memblock_alloc()和 memblock_free()。
//size即分配区块的大小,align用于字节对齐,表示分配区块的对齐大小
//这里NUMA_NO_NODE指任何节点(没有节点),关于节点后面会介绍,这里节点还没初始化
//MEMBLOCK_ALLOC_ACCESSIBLE指分配内存块时仅受memblock.current_limit的限制
#define NUMA_NO_NODE (-1)
#define MEMBLOCK_LOW_LIMIT 0
#define MEMBLOCK_ALLOC_ACCESSIBLE 0
static inline void * __init memblock_alloc(phys_addr_t size, phys_addr_t align)
{
return memblock_alloc_try_nid(size, align, MEMBLOCK_LOW_LIMIT,
MEMBLOCK_ALLOC_ACCESSIBLE, NUMA_NO_NODE);
}
void * __init memblock_alloc_try_nid(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid)
{
void *ptr;
memblock_dbg("%s: %llu bytes align=0x%llx nid=%d from=%pa max_addr=%pa %pS\\n",
__func__, (u64)size, (u64)align, nid, &min_addr,
&max_addr, (void *)_RET_IP_);
ptr = memblock_alloc_internal(size, align,
min_addr, max_addr, nid, false);
if (ptr)
memset(ptr, 0, size);
return ptr;
}
static void * __init memblock_alloc_internal(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid, bool exact_nid)
{
phys_addr_t alloc;
/*
* Detect any accidental use of these APIs after slab is ready, as at
* this moment memblock may be deinitialized already and its
* internal data may be destroyed (after execution of memblock_free_all)
*/
if (WARN_ON_ONCE(slab_is_available()))
return kzalloc_node(size, GFP_NOWAIT, nid);
if (max_addr > memblock.current_limit)
max_addr = memblock.current_limit;
alloc = memblock_alloc_range_nid(size, align, min_addr, max_addr, nid,
exact_nid);
/* retry allocation without lower limit */
if (!alloc && min_addr)
alloc = memblock_alloc_range_nid(size, align, 0, max_addr, nid,
exact_nid);
if (!alloc)
return NULL;
return phys_to_virt(alloc);
}
memblock_alloc_internal 返回的是分配到的内存块的虚拟地址,为 NULL 表示分配失败,关于 phys_to_virt 的实现后面再介绍,这里主要看 memblock_alloc_range_nid 的实现。
phys_addr_t __init memblock_alloc_range_nid(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid,
bool exact_nid)
{
enum memblock_flags flags = choose_memblock_flags();
phys_addr_t found;
if (WARN_ONCE(nid == MAX_NUMNODES, "Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\\n"))
nid = NUMA_NO_NODE;
if (!align) {
/* Can't use WARNs this early in boot on powerpc */
dump_stack();
align = SMP_CACHE_BYTES;
}
again:
found = memblock_find_in_range_node(size, align, start, end, nid,
flags);
if (found && !memblock_reserve(found, size))
goto done;
if (nid != NUMA_NO_NODE && !exact_nid) {
found = memblock_find_in_range_node(size, align, start,
end, NUMA_NO_NODE,
flags);
if (found && !memblock_reserve(found, size))
goto done;
}
if (flags & MEMBLOCK_MIRROR) {
flags &= ~MEMBLOCK_MIRROR;
pr_warn("Could not allocate %pap bytes of mirrored memory\\n",
&size);
goto again;
}
return 0;
done:
if (end != MEMBLOCK_ALLOC_KASAN)
kmemleak_alloc_phys(found, size, 0, 0);
return found;
}
kmemleak 是一个检查内存泄漏的工具,这里就不做介绍了。
memblock_alloc_range_nid()首先对 align 参数进行检测,如果为零,则警告。接着函数调用 memblock_find_in_range_node() 函数从可用内存区中找一块大小为 size 的物理内存区块, 然后调用 memblock_reseve() 函数在找到的情况下,将这块物理内存区块加入到预留区内。
static phys_addr_t __init_memblock memblock_find_in_range_node(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid,
enum memblock_flags flags)
{
phys_addr_t kernel_end, ret;
/* pump up @end */
if (end == MEMBLOCK_ALLOC_ACCESSIBLE ||
end == MEMBLOCK_ALLOC_KASAN)
end = memblock.current_limit;
/* avoid allocating the first page */
start = max_t(phys_addr_t, start, PAGE_SIZE);
end = max(start, end);
kernel_end = __pa_symbol(_end);
if (memblock_bottom_up() && end > kernel_end) {
phys_addr_t bottom_up_start;
/* make sure we will allocate above the kernel */
bottom_up_start = max(start, kernel_end);
/* ok, try bottom-up allocation first */
ret = __memblock_find_range_bottom_up(bottom_up_start, end,
size, align, nid, flags);
if (ret)
return ret;
WARN_ONCE(IS_ENABLED(CONFIG_MEMORY_HOTREMOVE),
"memblock: bottom-up allocation failed, memory hotremove may be affected\\n");
}
return __memblock_find_range_top_down(start, end, size, align, nid,
flags);
}
memblock 分配器分配内存是支持自低地址向高地址和自高地址向低地址的,如果 memblock_bottom_up() 函数返回 true,表示 MEMBLOCK 从低向上分配,而前面初始化的时候这个返回值其实是 false(某些情况下不一定),所以这里主要看__memblock_find_range_top_down 的实现(__memblock_find_range_bottom_up 的实现是类似的)。
static phys_addr_t __init_memblock
__memblock_find_range_top_down(phys_addr_t start, phys_addr_t end,
phys_addr_t size, phys_addr_t align, int nid,
enum memblock_flags flags)
{
phys_addr_t this_start, this_end, cand;
u64 i;
for_each_free_mem_range_reverse(i, nid, flags, &this_start, &this_end,
NULL) {
this_start = clamp(this_start, start, end);
this_end = clamp(this_end, start, end);
if (this_end < size)
continue;
cand = round_down(this_end - size, align);
if (cand >= this_start)
return cand;
}
return 0;
}
Clamp 函数可以将随机变化的数值限制在一个给定的区间[min, max]内。
__memblock_find_range_top_down()通过使用 for_each_free_mem_range_reverse 宏封装调用__next_free_mem_range_rev()函数,该函数逐一将 memblock.memory 里面的内存块信息提取出来与 memblock.reserved 的各项信息进行检验,确保返回的 this_start 和 this_end 不会与 reserved 的内存存在交叉重叠的情况。判断大小是否满足,满足的情况下,将自末端向前(因为这是 top-down 申请方式)的 size 大小的空间的起始地址(前提该地址不会超出 this_start)返回回去,至此满足要求的内存块找到了。
最后看一下memblock_free的实现:
int __init_memblock memblock_free(phys_addr_t base, phys_addr_t size)
{
phys_addr_t end = base + size - 1;
memblock_dbg("%s: [%pa-%pa] %pS\\n", __func__,
&base, &end, (void *)_RET_IP_);
kmemleak_free_part_phys(base, size);
return memblock_remove_range(&memblock.reserved, base, size);
}
这里直接看最核心的部分:
static int __init_memblock memblock_remove_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size)
{
int start_rgn, end_rgn;
int i, ret;
ret = memblock_isolate_range(type, base, size, &start_rgn, &end_rgn);
if (ret)
return ret;
for (i = end_rgn - 1; i >= start_rgn; i--)
memblock_remove_region(type, i);
return 0;
}
static void __init_memblock memblock_remove_region(struct memblock_type *type, unsigned long r)
{
type->total_size -= type->regions[r].size;
memmove(&type->regions[r], &type->regions[r + 1],
(type->cnt - (r + 1)) * sizeof(type->regions[r]));
type->cnt--;
/* Special case for empty arrays */
if (type->cnt == 0) {
WARN_ON(type->total_size != 0);
type->cnt = 1;
type->regions[0].base = 0;
type->regions[0].size = 0;
type->regions[0].flags = 0;
memblock_set_region_node(&type->regions[0], MAX_NUMNODES);
}
}
其主要功能是将指定下标索引的内存项从 memblock.reserved 中移除。
在__memblock_remove()里面,memblock_isolate_range()主要作用是将要移除的物理内存区从 reserved 内存区中分离出来,将 start_rgn 和 end_rgn(该内存区块的起始、结束索引号)返回回去。
memblock_isolate_range()返回后,接着调用 memblock_remove_region() 函数将这些索引对应的内存区块从内存区中移除,这里具体做法为调用 memmove 函数将 r 索引之后的内存区块全部往前挪一个位置,这样 r 索引对应的内存区块就被移除了,如果移除之后,内存区不含有任何内存区块,那么就初始化该内存区。
memblock 内存管理总结
memblock 内存区管理算法将可用可分配的内存用 memblock.memory 进行管理,已分配的内存用 memblock.reserved 进行管理,只要内存块加入到 memblock.reserved 里面就表示该内存被申请占用了,另外,在内存申请的时候,memblock 仅是把被申请到的内存加入到 memblock.reserved 中,而没有对 memblock.memory 进行任何删除或改动操作,因此申请和释放的操作都集中在 memblock.reserved。这个算法效率不高,但是却是合理的,因为在内核初始化阶段并没有太多复杂的内存操作场景,而且很多地方都是申请的内存都是永久使用的。

内核页表
上面有提到,内核会通过/arch/x86/kernel/head_32.S 开启页式映射,不过这里建立的页表只是临时页表,而内核真正需要建立的是内核页表。
内核虚拟地址空间与用户虚拟地址空间
为了合理地利用 4G 的内存空间,Linux 采用了 3:1 的策略,即内核占用 1G 的线性地址空间,用户占用 3G 的线性地址空间,由于历史原因,用户进程的地址范围从 0~3G,内核地址范围从 3G~4G,而内核的那 1GB 地址空间又称为内核虚拟地址(逻辑地址)空间,虽然内核在虚拟地址中是在高地址的,但是在物理地址中是从 0 开始的。
内核虚拟地址与用户虚拟地址,这两者都是虚拟地址,都需要经过 MMU 的翻译转换为物理地址,从硬件层面上来看,所谓的内核虚拟地址和用户虚拟地址只是权限不一样而已,但在软件层面上看,就大不相同了,当进程需要知道一个用户空间虚拟地址对应的物理地址时,linux 内核需要通过页表来得到它的物理地址,而内核空间虚拟地址是所有进程共享的,也就是说,内核在初始化时,就可以创建内核虚拟地址空间的映射,并且这里的映射就是线性映射,它基本等同于物理地址,只是它们之间有一个固定的偏移,当内核需要获取该物理地址时,可以绕开页表翻译直接通过偏移计算拿到,当然这是从软件层面上来看的,当内核去访问该页时, 硬件层面仍然走的是 MMU 翻译的全过程。
至于为什么用户虚拟地址空间不能也像内核虚拟地址空间这么做,原因是用户地址空间是随进程创建才产生的,无法事先给它分配一块连续的内存
内核通过内核虚拟地址可以直接访问到对应的物理地址,那内核如何使用其它的用户虚拟地址(0~3G)?
Linux 采用的一种折中方案是只对 1G 内核空间的前 896 MB 按线性映射, 剩下的 128 MB 采用动态映射,即走多级页表翻译,这样,内核态能访问空间就更多了。这里 linux 内核把这 896M 的空间称为 NORMAL 内存,剩下的 128M 称为高端内存,即 highmem。在 64 位处理器上,内核空间大大增加,所以也就不需要高端内存了,但是仍然保留了动态映射。
动态映射不全是为了内核空间可以访问更多的物理内存,还有一个重要原因:如果内核空间全线性映射,那么很可能就会出现内核空间碎片化而满足不了很多连续页面分配的需求(这类似于内存分段与内存分页)。因此内核空间也必须有一部分是非线性映射,从而在这碎片化物理地址空间上,用页表构造出连续虚拟地址空间(虚拟地址连续、物理地址不连续),这就是所谓的 vmalloc 空间。
到这里,可以大致知道linux 虚拟内存的构造:
linux 内存分页
linux 内核主要是通过内存分页来管理内存的,这里先介绍两个重要的变量:max_pfn 和 max_low_pfn。max_pfn 为最大物理内存页面帧号,max_low_pfn 为低端内存区的最大可用页帧号,它们的初始化如下:
void __init setup_arch(char **cmdline_p)
{
......
max_pfn = e820__end_of_ram_pfn();
.....
#ifdef CONFIG_X86_32
/* max_low_pfn get updated here */
find_low_pfn_range();
#else
check_x2apic();
/* How many end-of-memory variables you have, grandma! */
/* need this before calling reserve_initrd */
if (max_pfn > (1UL<<(32 - PAGE_SHIFT)))
max_low_pfn = e820__end_of_low_ram_pfn();
else
max_low_pfn = max_pfn;
high_memory = (void *)__va(max_pfn * PAGE_SIZE - 1) + 1;
#endif
......
e820__memblock_setup();
......
}
其中 e820__end_of_ram_pfn 的实现如下,其中 E820_TYPE_RAM 代表可用物理内存类型
#define PAGE_SHIFT 12
#ifdef CONFIG_X86_32
# ifdef CONFIG_X86_PAE
# define MAX_ARCH_PFN (1ULL<<(36-PAGE_SHIFT))
# else
//32位系统,1<<20,即0x100000,代表4G物理内存的最大页面帧号
# define MAX_ARCH_PFN (1ULL<<(32-PAGE_SHIFT))
# endif
#else /* CONFIG_X86_32 */
# define MAX_ARCH_PFN MAXMEM>>PAGE_SHIFT
#endif
unsigned long __init e820__end_of_ram_pfn(void)
{
return e820_end_pfn(MAX_ARCH_PFN, E820_TYPE_RAM);
}
/*
* Find the highest page frame number we have available
*/
static unsigned long __init e820_end_pfn(unsigned long limit_pfn, enum e820_type type)
{
int i;
unsigned long last_pfn = 0;
unsigned long max_arch_pfn = MAX_ARCH_PFN;
for (i = 0; i < e820_table->nr_entries; i++) {
struct e820_entry *entry = &e820_table->entries[i];
unsigned long start_pfn;
unsigned long end_pfn;
if (entry->type != type)
continue;
start_pfn = entry->addr >> PAGE_SHIFT;
end_pfn = (entry->addr + entry->size) >> PAGE_SHIFT;
if (start_pfn >= limit_pfn)
continue;
if (end_pfn > limit_pfn) {
last_pfn = limit_pfn;
break;
}
if (end_pfn > last_pfn)
last_pfn = end_pfn;
}
if (last_pfn > max_arch_pfn)
last_pfn = max_arch_pfn;
pr_info("last_pfn = %#lx max_arch_pfn = %#lx\\n",
last_pfn, max_arch_pfn);
return last_pfn;
}
e820__end_of_ram_pfn其实就是遍历e820_table,得到内存块的起始地址以及内存块大小,将起始地址右移 PAGE_SHIFT,算出其起始地址对应的页面帧号,同时根据内存块大小可以算出结束地址的页号,如果结束页号大于 limit_pfn,则设置该页号为为 limit_pfn,然后通过比较得到一个 last_pfn,即系统真正的最大物理页号。
max_low_pfn的计算则调用到了find_low_pfn_range:
#define PFN_UP(x) (((x) + PAGE_SIZE-1) >> PAGE_SHIFT)
#define PFN_DOWN(x) ((x) >> PAGE_SHIFT)
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
#ifndef __pa
#define __pa(x) __phys_addr((unsigned long)(x))
#endif
#define VMALLOC_RESERVE SZ_128M
#define VMALLOC_END (CONSISTENT_BASE - PAGE_SIZE)
#define VMALLOC_START ((VMALLOC_END) - VMALLOC_RESERVE)
#define VMALLOC_VMADDR(x) ((unsigned long)(x))
#define MAXMEM __pa(VMALLOC_START)
#define MAXMEM_PFN PFN_DOWN(MAXMEM)
void __init find_low_pfn_range(void)
{
/* it could update max_pfn */
if (max_pfn <= MAXMEM_PFN)
lowmem_pfn_init();
else
highmem_pfn_init();
}
PFN_DOWN(x)是用来返回小于 x 的最后一个物理页号,PFN_UP(x)是用来返回大于 x 的第一个物理页号,这里 x 即物理地址,而 PFN_PHYS(x)返回的是物理页号 x 对应的物理地址。
__pa 其实就是通过虚拟地址计算出物理地址,这一块后面再做讲解。
将 MAXMEM 展开一下可得
#ifdef CONFIG_HIGHMEM
#define CONSISTENT_BASE ((PKMAP_BASE) - (SZ_2M))
#define CONSISTENT_END (PKMAP_BASE)
#else
#define CONSISTENT_BASE (FIXADDR_START - SZ_2M)
#define CONSISTENT_END (FIXADDR_START)
#endif
#define SZ_2M 0x00200000
#define SZ_128M 0x08000000
#define MAXMEM __pa(VMALLOC_END – PAGE_OFFSET – __VMALLOC_RESERVE)
//进一步展开
#define MAXMEM __pa(CONSISTENT_BASE - PAGE_SIZE – PAGE_OFFSET – SZ_128M)
//再进一步展开
#define MAXMEM __pa((PKMAP_BASE) - (SZ_2M) - PAGE_SIZE – PAGE_OFFSET – SZ_128M)
下面这一部分就涉及到高端内存的构成了,其中PKMAP_BASE 是持久映射空间(KMAP 空间,持久映射区)的起始地址,LAST_PKMAP 则是持久映射空间的映射页面数,而 FIXADDR_TOP 是固定映射区(临时内核映射区)的末尾,FIXADDR_START 是固定映射区起始地址,其中的__end_of_permanent_fixed_addresses 是固定映射的一个标志(一个枚举值,具体可以参考\\arch\\x86\\include\\asm\\fixmap.h 里的 enum fixed_addresses)。最后的 VMALLOC_END 即为动态映射区的末尾。
//临时映射
//-4096(4KB) -> 0xfffff000
#define __FIXADDR_TOP (-PAGE_SIZE)
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
#define FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT)
#define FIXADDR_START (FIXADDR_TOP - FIXADDR_SIZE)
#define FIXADDR_TOT_SIZE (__end_of_fixed_addresses << PAGE_SHIFT)
#define FIXADDR_TOT_START (FIXADDR_TOP - FIXADDR_TOT_SIZE)
//持久内核映射
#ifdef CONFIG_X86_PAE
#define LAST_PKMAP 512
#else
#define LAST_PKMAP 1024
#endif
#define CPU_ENTRY_AREA_BASE \\
((FIXADDR_TOT_START - PAGE_SIZE*(CPU_ENTRY_AREA_PAGES+1)) & PMD_MASK)
#define LDT_BASE_ADDR \\
((CPU_ENTRY_AREA_BASE - PAGE_SIZE) & PMD_MASK)
#define LDT_END_ADDR (LDT_BASE_ADDR + PMD_SIZE)
#define PKMAP_BASE \\
((LDT_BASE_ADDR - PAGE_SIZE) & PMD_MASK)
//动态映射
//0xffffff80<<20 -> 0xf8000000 -> 4,160,749,568 -> 3948MB -> 3GB+896MB 与上述一致
#define high_memory (-128UL << 20)
//8MB
#define VMALLOC_OFFSET (8 * 1024 * 1024)
#define VMALLOC_START ((unsigned long)high_memory + VMALLOC_OFFSET)
#ifdef CONFIG_HIGHMEM
# define VMALLOC_END (PKMAP_BASE - 2 * PAGE_SIZE)
#else
# define VMALLOC_END (LDT_BASE_ADDR - 2 * PAGE_SIZE)
#endif
直接看图~

PAGE_OFFSET 代表的是内核空间和用户空间对虚拟地址空间的划分,对不同的体系结构不同。比如在 32 位系统中 3G-4G 属于内核使用的内存空间,所以 PAGE_OFFSET = 0xC0000000
内核空间如上图,可分为直接内存映射区和高端内存映射区,其中直接内存映射区是指 3G 到 3G+896M 的线性空间,直接对应物理地址就是 0 到 896M(前提是有超过 896M 的物理内存),其中 896M 是 high_memory 值,使用 kmalloc()/kfree()接口申请释放内存;而高端内存映射区则是超过 896M 物理内存的空间,它又分为动态映射区、持久映射区和固定映射区。
动态内存映射区,又称之为 vmalloc 映射区或非连续映射区,是指 VMALLOC_START 到 VMALLOC_END 的地址空间,申请释放内存的接口是 vmalloc()/vfree(),通常用于将非连续的物理内存映射为连续的线性地址内存空间;
而持久映射区,又称之为 KMAP 区或永久映射区,是指自 PKMAP_BASE 开始共 LAST_PKMAP 个页面大小的空间,操作接口是 kmap()/kunmap(),用于将高端内存长久映射到内存虚拟地址空间中;
最后的固定映射区,有时候也称为临时映射区,是指 FIXADDR_START 到 FIXADDR_TOP 的地址空间,操作接口是 kmap_atomic()/kummap_atomic(),用于解决持久映射不能用于中断处理程序而增加的临时内核映射。
上面的MAXMEM_PFN 其实就是用来判断是否初始化(启用)高端内存,当内存物理页数本来就小于低端内存的最大物理页数时,就没有高端地址映射。
这里接着看 max_low_pfn 的初始化,进入 highmem_pfn_init(void)。
static void __init highmem_pfn_init(void)
{
max_low_pfn = MAXMEM_PFN;
if (highmem_pages == -1)
highmem_pages = max_pfn - MAXMEM_PFN;
if (highmem_pages + MAXMEM_PFN < max_pfn)
max_pfn = MAXMEM_PFN + highmem_pages;
if (highmem_pages + MAXMEM_PFN > max_pfn) {
printk(KERN_WARNING MSG_HIGHMEM_TOO_SMALL,
pages_to_mb(max_pfn - MAXMEM_PFN),
pages_to_mb(highmem_pages));
highmem_pages = 0;
}
#ifndef CONFIG_HIGHMEM
/* Maximum memory usable is what is directly addressable */
printk(KERN_WARNING "Warning only %ldMB will be used.\\n", MAXMEM>>20);
if (max_pfn > MAX_NONPAE_PFN)
printk(KERN_WARNING "Use a HIGHMEM64G enabled kernel.\\n");
else
printk(KERN_WARNING "Use a HIGHMEM enabled kernel.\\n");
max_pfn = MAXMEM_PFN;
#else /* !CONFIG_HIGHMEM */
#ifndef CONFIG_HIGHMEM64G
if (max_pfn > MAX_NONPAE_PFN) {
max_pfn = MAX_NONPAE_PFN;
printk(KERN_WARNING MSG_HIGHMEM_TRIMMED);
}
#endif /* !CONFIG_HIGHMEM64G */
#endif /* !CONFIG_HIGHMEM */
}
highmem_pfn_init 的主要工作其实就是把 max_low_pfn 设置为 MAXMEM_PFN,将 highmem_pages 设置为 max_pfn – MAXMEM_PFN,至此,max_pfn 和 max_low_pfn 初始化完毕。
低端内存初始化
回到 setup_arch 函数:
void __init setup_arch(char **cmdline_p)
{
......
max_pfn = e820__end_of_ram_pfn();
.....
#ifdef CONFIG_X86_32
/* max_low_pfn get updated here */
find_low_pfn_range();
#else
check_x2apic();
/* How many end-of-memory variables you have, grandma! */
/* need this before calling reserve_initrd */
if (max_pfn > (1UL<<(32 - PAGE_SHIFT)))
max_low_pfn = e820__end_of_low_ram_pfn();
else
max_low_pfn = max_pfn;
high_memory = (void *)__va(max_pfn * PAGE_SIZE - 1) + 1;
#endif
......
early_alloc_pgt_buf(); //<-------------------------------------
/*
* Need to conclude brk, before e820__memblock_setup()
* it could use memblock_find_in_range, could overlap with
* brk area.
*/
reserve_brk(); //<-------------------------------------------
......
e820__memblock_setup();
......
}
early_alloc_pgt_buf()即申请页表缓冲区
#define INIT_PGD_PAGE_COUNT 6
#define INIT_PGT_BUF_SIZE (INIT_PGD_PAGE_COUNT * PAGE_SIZE)
RESERVE_BRK(early_pgt_alloc, INIT_PGT_BUF_SIZE);
void __init early_alloc_pgt_buf(void)
{
unsigned long tables = INIT_PGT_BUF_SIZE;
phys_addr_t base;
base = __pa(extend_brk(tables, PAGE_SIZE));
pgt_buf_start = base >> PAGE_SHIFT;
pgt_buf_end = pgt_buf_start;
pgt_buf_top = pgt_buf_start + (tables >> PAGE_SHIFT);
}
pgt_buf_start:标识该缓冲空间的起始物理内存页框号;
pgt_buf_end:初始化时和 pgt_buf_start 是同一个值,但是它是用于表示该空间未被申请使用的空间起始页框号;
pgt_buf_top:则是用来表示缓冲空间的末尾,存放的是该末尾的页框号
INIT_PGT_BUF_SIZE 即 24KB,这里直接看最关键的部分:extend_brk
unsigned long _brk_start = (unsigned long)__brk_base;
unsigned long _brk_end = (unsigned long)__brk_base;
void * __init extend_brk(size_t size, size_t align)
{
size_t mask = align - 1;
void *ret;
BUG_ON(_brk_start == 0);
BUG_ON(align & mask);
_brk_end = (_brk_end + mask) & ~mask;
BUG_ON((char *)(_brk_end + size) > __brk_limit);
ret = (void *)_brk_end;
_brk_end += size;
memset(ret, 0, size);
return ret;
}
BUG_ON()函数是内核标记 bug、提供断言并输出信息的常用手段
__brk_base 相关的初始化可以参考 arch\\x86\\kernel\\vmlinux.lds.S
在 setup_arch()中,紧接着 early_alloc_pgt_buf()还有 reserve_brk()函数
static void __init reserve_brk(void)
{
if (_brk_end > _brk_start)
memblock_reserve(__pa_symbol(_brk_start),
_brk_end - _brk_start);
/* Mark brk area as locked down and no longer taking any
new allocations */
_brk_start = 0;
}
这个地方主要是将 early_alloc_pgt_buf()申请的空间在 membloc 中做 reserved 保留操作,避免被其它地方申请使用而引发异常
回到 setup_arch 函数:
void __init setup_arch(char **cmdline_p)
{
......
max_pfn = e820__end_of_ram_pfn(); //max_pfn初始化
......
find_low_pfn_range(); //max_low_pfn、高端内存初始化
......
......
early_alloc_pgt_buf(); //页表缓冲区分配
reserve_brk(); //缓冲区加入memblock.reserve
......
e820__memblock_setup(); //memblock.memory空间初始化 启动
......
init_mem_mapping(); //<-----------------------------
......
}
init_mem_mapping()即低端内存内核页表初始化的关键函数
#define ISA_END_ADDRESS 0x00100000 //1MB
void __init init_mem_mapping(void)
{
unsigned long end;
pti_check_boottime_disable();
probe_page_size_mask();
setup_pcid();
#ifdef CONFIG_X86_64
end = max_pfn << PAGE_SHIFT;
#else
end = max_low_pfn << PAGE_SHIFT;
#endif
/* the ISA range is always mapped regardless of memory holes */
init_memory_mapping(0, ISA_END_ADDRESS, PAGE_KERNEL);
/* Init the trampoline, possibly with KASLR memory offset */
init_trampoline();
/*
* If the allocation is in bottom-up direction, we setup direct mapping
* in bottom-up, otherwise we setup direct mapping in top-down.
*/
if (memblock_bottom_up()) {
unsigned long kernel_end = __pa_symbol(_end);
memory_map_bottom_up(kernel_end, end);
memory_map_bottom_up(ISA_END_ADDRESS, kernel_end);
} else {
memory_map_top_down(ISA_END_ADDRESS, end);
}
#ifdef CONFIG_X86_64
if (max_pfn > max_low_pfn) {
/* can we preseve max_low_pfn ?*/
max_low_pfn = max_pfn;
}
#else
early_ioremap_page_table_range_init();
#endif
load_cr3(swapper_pg_dir);
__flush_tlb_all();
x86_init.hyper.init_mem_mapping();
early_memtest(0, max_pfn_mapped << PAGE_SHIFT);
}
probe_page_size_mask()主要作用是初始化直接映射变量(直接映射区相关)以及根据配置来控制 CR4 寄存器的置位,用于后面分页时页面大小的判定。
上面 init_memory_mapping 的参数 ISA_END_ADDRESS 表示 ISA 总线上设备的末尾地址。
init_memory_mapping(0, ISA_END_ADDRESS, PAGE_KERNEL)初始化 0 ~ 1MB 的物理地址,一般内核启动时被安装在 1MB 开始处,这里初始化完成之后会调用到 memory_map_bottom_up 或者 memory_map_top_down,后面就是初始化 1MB ~ 内核结束地址 这块物理地址区域 ,最后也会回归到 init_memory_mapping 的调用,因此这里不做过多的介绍,直接看 init_memory_mapping():
#ifdef CONFIG_X86_32
#define NR_RANGE_MR 3
#else /* CONFIG_X86_64 */
#define NR_RANGE_MR 5
#endif
struct map_range {
unsigned long start;
unsigned long end;
unsigned page_size_mask;
};
unsigned long __ref init_memory_mapping(unsigned long start,
unsigned long end, pgprot_t prot)
{
struct map_range mr[NR_RANGE_MR];
unsigned long ret = 0;
int nr_range, i;
pr_debug("init_memory_mapping: [mem %#010lx-%#010lx]\\n",
start, end - 1);
memset(mr, 0, sizeof(mr));
nr_range = split_mem_range(mr, 0, start, end);
for (i = 0; i < nr_range; i++)
ret = kernel_physical_mapping_init(mr[i].start, mr[i].end,
mr[i].page_size_mask,
prot);
add_pfn_range_mapped(start >> PAGE_SHIFT, ret >> PAGE_SHIFT);
return ret >> PAGE_SHIFT;
}
struct map_range,该结构是用来保存内存段信息,其包含了一个段的起始地址、结束地址,以及该段是按多大的页面进行分页(4K、2M、1G,1G 是 64 位的,所以这里不提及)。
static int __meminit split_mem_range(struct map_range *mr, int nr_range,
unsigned long start,
unsigned long end)
{
unsigned long start_pfn, end_pfn, limit_pfn;
unsigned long pfn;
int i;
//返回小于...的最后一个物理页号
limit_pfn = PFN_DOWN(end);
pfn = start_pfn = PFN_DOWN(start);
if (pfn == 0)
end_pfn = PFN_DOWN(PMD_SIZE);
else
end_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
if (end_pfn > limit_pfn)
end_pfn = limit_pfn;
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, 0);
pfn = end_pfn;
}
/* big page (2M) range */
start_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask & (1<<PG_LEVEL_2M));
pfn = end_pfn;
}
/* tail is not big page (2M) alignment */
start_pfn = pfn;
end_pfn = limit_pfn;
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, 0);
if (!after_bootmem)
adjust_range_page_size_mask(mr, nr_range);
/* try to merge same page size and continuous */
for (i = 0; nr_range > 1 && i < nr_range - 1; i++) {
unsigned long old_start;
if (mr[i].end != mr[i+1].start ||
mr[i].page_size_mask != mr[i+1].page_size_mask)
continue;
/* move it */
old_start = mr[i].start;
memmove(&mr[i], &mr[i+1],
(nr_range - 1 - i) * sizeof(struct map_range));
mr[i--].start = old_start;
nr_range--;
}
for (i = 0; i < nr_range; i++)
pr_debug(" [mem %#010lx-%#010lx] page %s\\n",
mr[i].start, mr[i].end - 1,
page_size_string(&mr[i]));
return nr_range;
}
PMD_SIZE 用于计算由页中间目录的一个单独表项所映射的区域大小,也就是一个页表的大小。
split_mem_range()根据传入的内存 start 和 end 做四舍五入的对齐操作(即 round_up 和 round_down)
#define __round_mask(x, y) ((__typeof__(x))((y)-1))
#define round_up(x, y) ((((x)-1) | __round_mask(x, y))+1)
//可以理解为:#define round_up(x, y) (((x)+(y) - 1)/(y))*(y))
#define round_down(x, y) ((x) & ~__round_mask(x, y))
//可以理解为:#define round_down(x, y) ((x/y) * y)
round_up 宏依靠整数除法来完成这项工作,仅当两个参数均为整数时,它才有效,x 是需要四舍五入的数字,y 是应该四舍五入的间隔,也就是说,round_up(12,5)应返回 15,因为 15 是大于 12 的 5 的第一个间隔,而 round_down(12,5)应返回 10。
split_mem_range()会根据对齐的情况,把开始、末尾的不对齐部分及中间部分分成了三段,使用 save_mr()将其存放在 init_mem_mapping()的局部变量数组 mr 中。划分开来主要是为了让各部分可以映射到不同大小的页面,最后如果相邻两部分映射页面的大小是一致的,则将其合并。
可以通过 dmesg 得到划分的情况(以下是我私服的划分情况,不过是 64 位的……)

初始化完内存段信息 mr 之后,就行了进入到kernel_physical_mapping_init,这个函数是建立内核页表的最为关键的一步,负责处理物理内存的映射。
在 2.6.11 后,Linux 采用四级分页模型,这四级页目录分别为:
页全局目录(Page Global Directory)
页上级目录(Page Upper Directory)
页中间目录(Page Middle Directory)
页表(Page Table)
对于没有启动 PAE(物理地址扩展)的 32 位系统,Linux 虽然也采用四级分页模型,但本质上只用到了两级分页,Linux 通过将"页上级目录"位域和“页中间目录”位域全为 0 来达到使用两级分页的目的,但为了保证程序能 32 位和 64 系统上都能运行,内核保留了页上级目录和页中间目录在指针序列中的位置,它们的页目录数都被内核置为 1,并把这 2 个页目录项映射到适合的全局目录项。
开启 PAE 后,32 位系统寻址方式将大大改变,这时候使用的是三级页表,即页上级目录其实没有真正用到。
这里不考虑 PAE
PAGE_OFFSET 代表的是内核空间和用户空间对虚拟地址空间的划分,对不同的体系结构不同。比如在 32 位系统中 3G-4G 属于内核使用的内存空间,所以 PAGE_OFFSET = 0xC0000000
unsigned long __init
kernel_physical_mapping_init(unsigned long start,
unsigned long end,
unsigned long page_size_mask,
pgprot_t prot)
{
int use_pse = page_size_mask == (1<<PG_LEVEL_2M);
unsigned long last_map_addr = end;
unsigned long start_pfn, end_pfn;
pgd_t *pgd_base = swapper_pg_dir;
int pgd_idx, pmd_idx, pte_ofs;
unsigned long pfn;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte;
unsigned pages_2m, pages_4k;
int mapping_iter;
start_pfn = start >> PAGE_SHIFT;
end_pfn = end >> PAGE_SHIFT;
mapping_iter = 1;
if (!boot_cpu_has(X86_FEATURE_PSE))
use_pse = 0;
repeat:
pages_2m = pages_4k = 0;
pfn = start_pfn; //pfn保存起始页框号
pgd_idx = pgd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET); //低端内存的起始地址对应的pgd的偏移
pgd = pgd_base + pgd_idx; //得到起始页框对应的pgd
//由pgd开始遍历
for (; pgd_idx < PTRS_PER_PGD; pgd++, pgd_idx++) {
pmd = one_md_table_init(pgd);//申请得到一个pmd表
if (pfn >= end_pfn)
continue;
#ifdef CONFIG_X86_PAE
pmd_idx = pmd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pmd += pmd_idx;
#else
pmd_idx = 0;
#endif
//遍历pmd表,对于未激活PAE的32位系统,PTRS_PER_PMD为1,激活PAE则为512
for (; pmd_idx < PTRS_PER_PMD && pfn < end_pfn;
pmd++, pmd_idx++) {
unsigned int addr = pfn * PAGE_SIZE + PAGE_OFFSET;
/*
* Map with big pages if possible, otherwise
* create normal page tables:
*/
if (use_pse) {
unsigned int addr2;
pgprot_t prot = PAGE_KERNEL_LARGE;
/*
* first pass will use the same initial
* identity mapping attribute + _PAGE_PSE.
*/
pgprot_t init_prot =
__pgprot(PTE_IDENT_ATTR |
_PAGE_PSE);
pfn &= PMD_MASK >> PAGE_SHIFT;
addr2 = (pfn + PTRS_PER_PTE-1) * PAGE_SIZE +
PAGE_OFFSET + PAGE_SIZE-1;
if (__is_kernel_text(addr) ||
__is_kernel_text(addr2))
prot = PAGE_KERNEL_LARGE_EXEC;
pages_2m++;
if (mapping_iter == 1)
set_pmd(pmd, pfn_pmd(pfn, init_prot));
else
set_pmd(pmd, pfn_pmd(pfn, prot));
pfn += PTRS_PER_PTE;
continue;
}
pte = one_page_table_init(pmd); //创建一个页表
//得到pfn在page table中的偏移并定位到具体的pte
pte_ofs = pte_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pte += pte_ofs;
//由pte开始遍历page table
for (; pte_ofs < PTRS_PER_PTE && pfn < end_pfn;
pte++, pfn++, pte_ofs++, addr += PAGE_SIZE) {
pgprot_t prot = PAGE_KERNEL;
/*
* first pass will use the same initial
* identity mapping attribute.
*/
pgprot_t init_prot = __pgprot(PTE_IDENT_ATTR);
if (__is_kernel_text(addr)) //如果处于内核代码段,权限设为可执行
prot = PAGE_KERNEL_EXEC;
pages_4k++;
//设置pte与pfn关联
if (mapping_iter == 1) {
set_pte(pte, pfn_pte(pfn, init_prot)); //第一次执行将权限位设为init_prot
last_map_addr = (pfn << PAGE_SHIFT) + PAGE_SIZE;
} else
set_pte(pte, pfn_pte(pfn, prot)); //之后的执行将权限位置为prot
}
}
}
if (mapping_iter == 1) {
/*
* update direct mapping page count only in the first
* iteration.
*/
update_page_count(PG_LEVEL_2M, pages_2m);
update_page_count(PG_LEVEL_4K, pages_4k);
/*
* local global flush tlb, which will flush the previous
* mappings present in both small and large page TLB's.
*/
__flush_tlb_all(); //TLB全部刷新
/*
* Second iteration will set the actual desired PTE attributes.
*/
mapping_iter = 2;
goto repeat;
}
return last_map_addr;
}
内核的内核页全局目录的基地址保存在 swapper_pg_dir 全局变量中,但需要使用主内核页表时系统会把这个变量的值放入 cr3 寄存器,详细可参考/arch/x86/kernel/head_32.s。
Linux 分别采用 pgd_t、pud_t、pmd_t 和 pte_t 四种数据结构来表示页全局目录项、页上级目录项、页中间目录项和页表项。这四种数据结构本质上都是无符号长整型,Linux 为了更严格数据类型检查,将无符号长整型分别封装成四种不同的页表项。如果不采用这种方法,那么一个无符号长整型数据可以传入任何一个与四种页表相关的函数或宏中,这将大大降低程序的健壮性。下面仅列出 pgd_t 类型的内核源码实现,其他类型与此类似
typedef unsigned long pgdval_t;
typedef struct { pgdval_t pgd; } pgd_t;
#define pgd_val(x) native_pgd_val(x)
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
这里需要区别指向页表项的指针和页表项所代表的数据,如果已知一个 pgd_t 类型的指针 pgd,那么通过 pgd_val(*pgd)即可获得该页表项(也就是一个无符号长整型数据)
PAGE_SHIFT,PMD_SHIFT,PUD_SHIFT,PGDIR_SHIFT,对应相应的页目录所能映射的区域大小的位数,如 PAGE_SHIFT 为 12,即页面大小为 4k。

PTRS_PER_PTE, PTRS_PER_PMD, PTRS_PER_PUD, PTRS_PER_PGD,对应相应页目录中的表项数。32 位系统下,当 PAE 被禁止时,他们的值分别为 1024,,1,1 和 1024,也就是说只使用两级分页
pgd_index(addr),pud_index,(addr),pmd_index(addr),pte_index(addr),取 addr 在该目录中的索引
pud_offset(pgd,addr), pmd_offset(pud,addr), pte_offset(pmd,addr),以 pmd_offset 为例,线性地址 addr 对应的 pmd 索引在在 pud 指定的 pmd 表的偏移地址。在两级或三级分页系统中,pmd_offset 和 pud_offset 都返回页全局目录的地址
至此,低端内存的物理地址和虚拟地址之间的映射关系已全部建立起来了
回到前面的 init_memory_mapping()函数,它的最后一个函数调用为 add_pfn_range_mapped()
struct range pfn_mapped[E820_MAX_ENTRIES];
int nr_pfn_mapped;
static void add_pfn_range_mapped(unsigned long start_pfn, unsigned long end_pfn)
{
nr_pfn_mapped = add_range_with_merge(pfn_mapped, E820_MAX_ENTRIES,
nr_pfn_mapped, start_pfn, end_pfn);
nr_pfn_mapped = clean_sort_range(pfn_mapped, E820_MAX_ENTRIES);
max_pfn_mapped = max(max_pfn_mapped, end_pfn);
if (start_pfn < (1UL<<(32-PAGE_SHIFT)))
max_low_pfn_mapped = max(max_low_pfn_mapped,
min(end_pfn, 1UL<<(32-PAGE_SHIFT)));
}
该函数主要是将前面完成内存映射的物理页框范围加入到全局数组pfn_mapped中,其中 nr_pfn_mapped 用于表示数组中的有效项数量,之后可以通过内核函数 pfn_range_is_mapped 来判断指定的物理内存是否被映射,避免重复映射的情况
固定映射区初始化
再回到更前面的 init_mem_mapping()函数,early_ioremap_page_table_range_init()用来建立高端内存的固定映射区页表,与低端内存的页表初始化不同的是,固定映射区的页表只是被分配,相应的 PTE 项并未初始化,这个工作交由后面的set_fixmap()函数将相关的固定映射区页表与物理内存进行关联
# define PMD_MASK (~(PMD_SIZE - 1))
void __init early_ioremap_page_table_range_init(void)
{
pgd_t *pgd_base = swapper_pg_dir;
unsigned long vaddr, end;
/*
* Fixed mappings, only the page table structure has to be
* created - mappings will be set by set_fixmap():
*/
vaddr = __fix_to_virt(__end_of_fixed_addresses - 1) & PMD_MASK;
end = (FIXADDR_TOP + PMD_SIZE - 1) & PMD_MASK;
page_table_range_init(vaddr, end, pgd_base);
early_ioremap_reset();
}
PUD_MASK、PMD_MASK、PGDIR_MASK,这些 MASK 的作用是:从给定地址中提取某些分量,用给定地址与对应的 MASK 位与操作之后即可获得各个分量,上面的操作为屏蔽低位
这里可以先具体看一下固定映射区的组成
每个固定映射区索引都以枚举类型的形式定义在 enum fixed_addresses 中
enum fixed_addresses {
#ifdef CONFIG_X86_32
FIX_HOLE,
#else
#ifdef CONFIG_X86_VSYSCALL_EMULATION
VSYSCALL_PAGE = (FIXADDR_TOP - VSYSCALL_ADDR) >> PAGE_SHIFT,
#endif
以上是关于一文掌握 Linux 内存管理的主要内容,如果未能解决你的问题,请参考以下文章