Zookeeper- 总结
Posted ☞精◈彩◈猿◈笔◈记☜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper- 总结相关的知识,希望对你有一定的参考价值。
Zookeeper- 总结
如想了解更多更全面的Java必备内容可以阅读:所有JAVA必备知识点面试题文章目录:
文章目录
- Zookeeper- 总结
- 1、Http和RPC的区别?
- 2、Google的GFS(google file system)集群中是怎么进行master选举的?
- 3、说说zookeeper是什么?
- 4、Zookeeper提供了哪些常用的功能?
- 5、什么是leader选举和原子广播?
- 6、说说你对Zookeeper节点和节点状态信息的理解?
- 7、说说Zookeeper中Watcher作用?
- 8、Zookeeper是如何实现服务的注册与发现?
- 9、Zookeeper中watcher机制的特性是什么?
- 10、Zookeeper原生提供了哪些监听事件?
- 11、Curator提供了几种Watcher来监听节点的变化?
- 12、Zookeeper分布式锁的实现原理?
- 13、curator提供了哪些常用的Zookeeper分布式锁的封装?
- 14、leader节点和各个follower节点如何保证数据一致性?
- 15、各个follower在收到COMMIT命令前leader就挂了,导致数据不一致情况,Zookeeper是怎么处理的?
- 16、Zookeeper是如何保证事务的顺序一致性的?
- 17、什么情况下会进行leader选举?
- 18、Zookeeper下Server 工作状态?
- 19、Zookeeper服务器角色有哪些?
- 20、服务器启动时的leader选举实现原理?
- 21、运行过程中leader节点宕机,整个集群无法处理写请求,如何快速从其他节点里面选举出新的leader呢?
- 22、什么是ACL权限控制机制?
- 23、Chroot特性是什么?
- 24、zookeeper负载均衡和nginx负载均衡区别?
- 25、集群最少要几台机器,集群规则是怎样的?
- 26、集群支持动态添加机器吗?
- 27、chubby是什么?
- 28、ZAB和Paxos算法的联系与区别?
- 29、Zookeeper的典型应用场景?
1、Http和RPC的区别?
RPC(Remote Produce Call 远程过程调用):自定义数据格式,基于原生TCP通信,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型。
Http:网络传输协议:基于TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议。也可以用来进行远程服务调用。缺点是消息封装臃肿。
相同点:底层通讯都是基于socket,都可以实现远程调用,都可以实现服务调用服务
不同点:
- RPC:当使用RPC框架实现服务间调用的时候,要求服务提供方和服务消费方 都必须使用统一的RPC框架,要么都dubbo,要么都cxf
跨操作系统在同一编程语言内使用
优势:调用快、处理快
应用:dubbo、cxf、(RMI远程方法调用)Hessian - http:当使用http进行服务间调用的时候,无需关注服务提供方使用的编程语言,也无需关注服务消费方使用的编程语言,服务提供方只需要提供restful风格的接口,服务消费方按照restful的原则请求服务即可。
跨系统跨编程语言的远程调用框架
优势:通用性强
应用:httpClient
2、Google的GFS(google file system)集群中是怎么进行master选举的?
在Google有一个文件系统GFS(google file system),需要从多个gfs server中选出一个master server。
GFS就是使用Google Chubby来解决这个问题的。【Google Chubby 不开源】
所有的server通过Paxos协议到Chubby server上的一个节点上创建同一个文件,当然,最终只有一个server能够成功创建这个文件,这个server就成为了master,它会在这个文件中写入自己的地址,这样其它的server通过读取这个文件就能知道被选出的master的地址。
3、说说zookeeper是什么?
ZooKeeper:是一个高可靠的分布式协调中间件。它是Google Chubby的一个开源实现。
ZooKeeper分为服务器端(Server)和客户端(Client)客户端,客户端可以连接到整个ZooKeeper的任意服务器上(除非参数zookeeper.leaderServes=no,leader不允许接受客户端连接)
客户端使用并维护一个TCP连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将自动尝试连接到另外的ZooKeeper服务器。
ZooKeeper服务端启动时,将从实例中选举一个leader,Leader负责处理事务请求、数据同步等操作,一个更新操作成功的标志是当且仅当超过半数以上Server在内存中成功修改数据。
Zookeeper集群间通过Zab协议(Zookeeper Atomic Broadcast)来保持数据的一致性。Zab协议包含两个阶段:leader选举/崩溃恢复(leader election)阶段 和 原子广播(Atomic Brodcast)阶段。
4、Zookeeper提供了哪些常用的功能?
- Watcher监听
- 心跳监测
- 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程。
- 分布式锁:提供两种锁:独占锁、共享锁。
- 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
- ACL对节点权限控制
5、什么是leader选举和原子广播?
- 集群启动,在集群中将选举出一个leader,其他的机器则称为follower,所有的写操作都被传送给leader,并通过广播将所有的更新告诉给follower。
- 当leader崩溃或者leader失去大多数的follower时,需要重新选举出一个新的leader,让所有的服务器都恢复到高可用状态。
- 当leader被选举出来,且大多数服务器完成了和leader的状态同步后,leader选举的过程就结束了,就将会进入到原子广播的过程。
- 原子广播是同步leader和follower之间的信息,保证数据在集群中各个节点的一致性。
6、说说你对Zookeeper节点和节点状态信息的理解?
Zookeeper每一个节点称之为ZNode,是Zookeeper的最小单元。每个ZNode上都可以保存数据以及挂载子节点。构成一个层次化的树形结构。
ZNode节点类型:
#### zookeeper-3.5.3 CreateMode类源码如下:
public enum CreateMode {
//【持久化节点】:创建后会一直存在 zookeeper 服务器上,直到主动删除
PERSISTENT (0, false, false, false, false),
//【持久化有序节点】:每个节点都会为它的一级子节点维护一个顺序
PERSISTENT_SEQUENTIAL (2, false, true, false, false),
//【短暂的临时节点】:临时节点的生命周期和客户端的会话绑定在一起,当客户端会话失效该节点自动清理
EPHEMERAL (1, true, false, false, false),
//【短暂的临时有序节点】:在临时节点的基础上多了一个顺序性
EPHEMERAL_SEQUENTIAL (3, true, true, false, false),
//容器节点:是特殊用途的节点,用于leader、lock等方法。当容器的最后一个子元素被删除时,该容器将成为将来某个时候服务器删除的候选对象。
CONTAINER (4, false, false, true, false),
//客户端断开连接后不会自动删除Znode,如果该Znode没有子节点且在给定TTL时间内无修改,该Znode将会被删除;TTL单位是毫秒,必须大于0且小于或等于EphemeralType.MAX_TTL。
PERSISTENT_WITH_TTL(5, false, false, false, true),
//有序的PERSISTENT_WITH_TTL
PERSISTENT_SEQUENTIAL_WITH_TTL(6, false, true, false, true);
···
}
「注意」有序性:创建ZNode时设置顺序标识,ZNode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。
每个ZNode节点除了存储数据内容以外,还存储了数据节点本身的一些状态信息,通过get 命令可以获得状态信息的详细内容。
#### zookeeper-3.5.3 Stat类源码如下:
public class Stat implements Record {
private long czxid;//即Created ZXID,表示该数据节点被创建时的事务ID
private long mzxid;//即Modified ZXID,表示该节点最后一次被更新时的事务ID
private long ctime;//即Created Time,表示节点被创建的时间
private long mtime;//即Modified Time,表示该节点最后一次被更新的时间
private int version;//当前节点被改动的次数(数据节点的版本号)
private int cversion;//当前节点的子节点改动的次数(数据节点的版本号)
private int aversion;//当前节点的ACL改动次数(数据节点的版本号)
private long ephemeralOwner;//创建该临时节点的会话的sessionID。如果该节点是持久节点,那么这个属性值为0
private int dataLength;//当前节点的数据长度
private int numChildren;//当前节点子节点的个数
private long pzxid;//表示该节点的子节点列表最后一次被修改时的事务ID。注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid
···
}
7、说说Zookeeper中Watcher作用?
watch机制:客户端会对某个节点注册一个watcher事件,当该节点发生变化时,这些客户端会收到注册中心的通知,然后客户端可以根据节点变化来做出业务上的改变等。
watcher:是zooKeeper中一个非常核心功能 ,客户端watcher可以监控节点的数据变化以及它子节点的变化,一旦这些状态发生变化,zooKeeper服务端就会通知所有在这个节点上设置过watcher的客户端 ,从而每个客户端都很快感知。
应用场景:可以做 注册中心 和 配置中心 以及 分布式锁 动态感知变化随之做响应的逻辑处理。
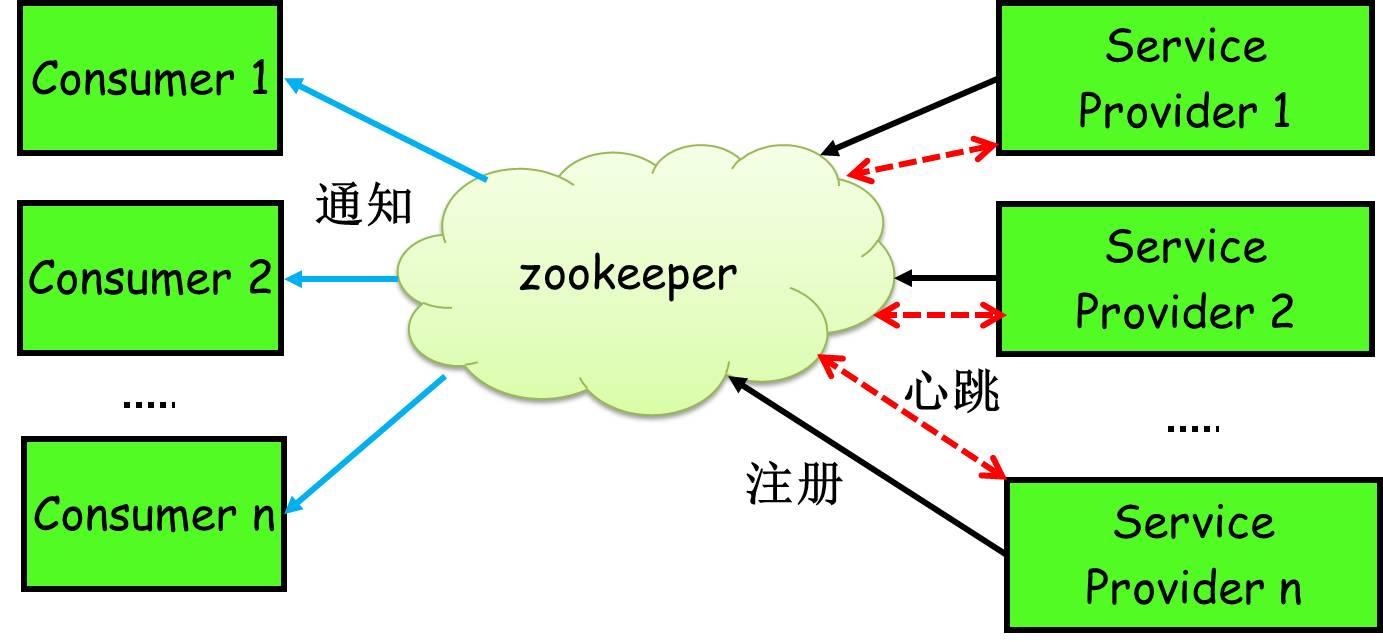
8、Zookeeper是如何实现服务的注册与发现?
Zookeeper的服务注册与发现:主要应用的是Zookeeper的ZNode节点数据模型和watcher机制,大致的流程如下:
-
服务提供者(Provider):启动时,会向服务注册中心(Zookeeper)注册服务信息,也就是创建一个节点。
-
服务消费者(Consumer):启动时,根据自身配置的依赖服务信息,向服务注册中心(Zookeeper)获取注册的服务信息并设置watch监听,获取到注册的服务信息之后,将服务提供者的信息缓存在本地。根据本地缓存中的服务注册信息构建服务调用请求,并根据负载均衡策略(随机负载均衡,Round-Robin负载均衡等)来转发请求。
当收到服务注册中心(Zookeeper)通知服务有更新时(通知只会收到一次,如果想继续监听可以通过循环注册来实现),会在本地缓存中更新服务信息。
-
服务注册中心(Zookeeper):主要提供所有服务注册信息存储;
通过心跳去监测服务服务提供者提供的服务信息是否有更新;
如果服务信息有更新,同时负责将更新信息实时通知给这个服务设置过watch监听的服务消费者。
9、Zookeeper中watcher机制的特性是什么?
【一次性】 当数据发生改变的时候,那么zookeeper会产生一个watch事件并发送到客户端,但是客户端只会收到一次这样的通知,如果以后这个数据再发生变化,那么之前设置watch的客户端不会再次收到消息。因为他是一次性的;如果要实现永久监听,可以通过循环注册来实现。
10、Zookeeper原生提供了哪些监听事件?
| zookeeper事件 | 事件含义 |
|---|---|
| EventType.NodeCreated | 当 node-x 这个节点被创建时,该事件被触发。 |
| EventType.NodeDeleted | 当 node-x 这个节点被删除时,该事件被触发。 |
| EventType.NodeDataChanged | 当 node-x 这个节点的数据发生变更时,该事件被触发。 |
| EventType.NodeChildrenChanged | 当 node-x 这个节点的直接子节点被创建、被删除、子节点数据发生变更时,该事件被触发。 |
| EventType.None | 当 zookeeper 客户端的连接状态发生变更时,即 KeeperState.Expired、KeeperState.Disconnected、KeeperState.SyncConnected、KeeperState.AuthFailed 状态切换时,描述的事件类型为 EventType.None。 |
11、Curator提供了几种Watcher来监听节点的变化?
Curator:是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher、NodeExistsException异常等等。
####对zookeeper的底层api的一些封装
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
####封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式Barrier
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
- NodeCache:监视当前结点的创建、更新、删除,并将结点的数据缓存在本地。
- PathChildCache:监视一个路径下子结点的创建、删除、更新。
- TreeCache:PathChildCache 和 NodeCache 的“合体”,监视路径下的创建、更新、删除事件,并缓存路径下所有孩子结点的数据。
12、Zookeeper分布式锁的实现原理?
-
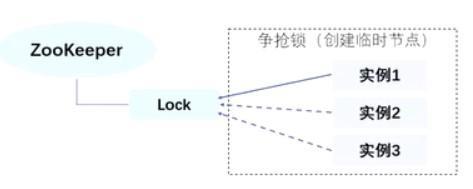
【方式一】:利用Zookeeper节点的特性(同级节点的唯一性)来实现独占锁
原理:多个进程往Zookeeper的指定节点下创建一个相同名称的节点,只有一个能成功(抢到锁),其他的都创建失败(未抢到锁);创建失败的节点全部通过Zookeeper的watcher机制,监听Zookeeper这个子节点的变化,一旦监听到子节点的删除事件,则再次触发所有进程去创建一个相同名称的节点,从而或者锁,不断重复这个过程。弊端:会产生“惊群效应”,简单来说,就是如果存在许多的客户端在等待获取锁,当成功获取到锁的进程释放该节点后,所有处于等待状态的客户端都会被唤醒,这个时候zookeeper在短时间内发送大量子节点变更事件给所有待获取锁的客户端,然后实际情况是只会有一个客户端获得锁。如果在集群规模比较大的情况下,会对 zookeeper 服务器的性能产生比较的影响。
-
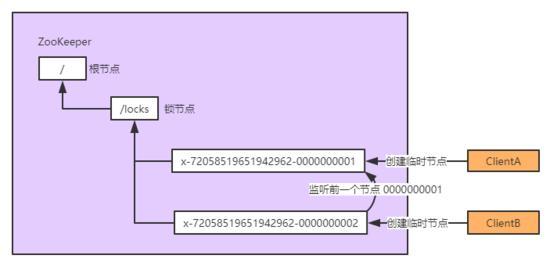
【方式二】:利用临时有序节点来实现分布式锁
原理:每个客户端都往指定的节点下,注册一个临时有序节点,越早创建的节点,节点的顺序编号就越小,那么我们可以判断子节点中最小的节点设置为获得锁。
如果自己的节点不是所有子节点中最小的,意味着还没有获得锁。每个节点只需要监听比自己小的节点,当比自己小的节点删除以后,客户端会收到watcher事件,此时再次判断自己的节点是不是所有子节点中最小的,如果是则获得锁,否则就不断重复这个过程,这样就不会导致惊群效应。
13、curator提供了哪些常用的Zookeeper分布式锁的封装?
提供了三个常用的分布式锁的实现,都实现了InterProcessLock接口。
public interface InterProcessLock
{
//获取锁
public void acquire() throws Exception;
//获取锁
public boolean acquire(long time, TimeUnit unit) throws Exception;
//释放锁
public void release() throws Exception;
//是否在在这个过程中获得的锁
boolean isAcquiredInThisProcess();
}
-
InterProcessMutex:分布式可重入排它锁,利用构造方法传入锁节点path,在path下创建临时顺序节点实现。通过ConcurrentMap<Thread, LockData>记录线程与锁信息的映射关系。
Zookeeper中一个临时顺序节点对应一个“锁”,但让锁生效激活需要排队(公平锁),激活条件:同级目录子节点,名称排序最小(排队,公平锁)。
每个节点会监听上一个节点,如果上一个节点释放锁,会唤醒当前线程继续竞争锁,正常情况下能直接获得锁,因为锁是公平的。
-
InterProcessSemaphoreMutex:分布式排它锁
-
InterProcessReadWriteLock:分布式读写锁
14、leader节点和各个follower节点如何保证数据一致性?
注意:leader 节点可以处理事务请求和非事务请求,follower 节点只能处理非事务请求,如果 follower 节点接收到非事务请求,会把这个请求转发给 Leader 服务器。
在ZooKeeper中,主要依赖ZAB协议来实现分布式数据一致性,基于该协议,ZooKeeper实现了一种广播机制来保持集群中各个副本之间的数据一致性。
ZAB 协议的消息广播机制是简化版本的2PC协议,这种协议只需要集群中过半的节点响应提交即可。
说明:消息广播机制和完整的2pc事务不一样的地方在于,zab协议不能终止事务,follower节点要么ACK给leader,要么抛弃leader,只需要保证过半数的节点响应这个消息并提交了即可,虽然在某一个时刻follower节点和leader节点的状态会不一致,但是也是这个特性提升了集群的整体性能。当然这种数据不一致的问题,zab协议提供了一种恢复模式来进行数据恢复。
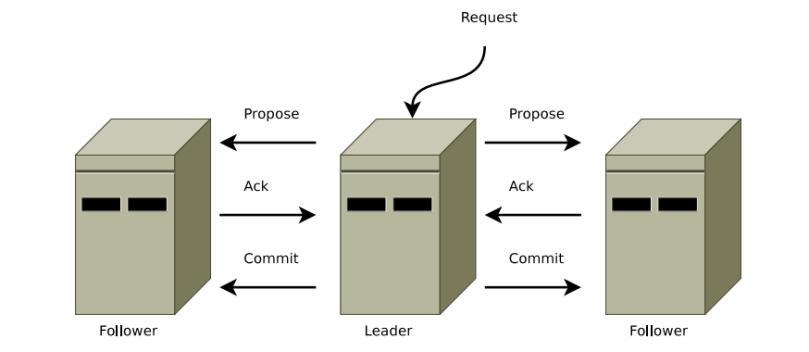
原子广播的实现数据一致性原理:
- leader接收到消息请求后,将消息赋予一个全局唯一的64位自增id,叫:zxid,通过zxid的大小比较既可以实现。
- leader为每个follower准备了一个FIFO队列(通过TCP协议来实现,以实现了全局有序这一个特点),将带有zxid的消息作为一个提案(proposal)分发给所有的follower。
- 当follower接收到proposal,先把proposal写到磁盘,写入成功以后再向leader回复一个 ack。
- 当leader接收到合法数量(超过半数节点)的ACK后,leader就会向这些follower发送commit命令,同时会在本地执行该消息。
- 当follower收到消息的commit命令以后,会提交该消息。
15、各个follower在收到COMMIT命令前leader就挂了,导致数据不一致情况,Zookeeper是怎么处理的?
进入崩溃恢复/leader选举模式,选举新的leader。
在旧的leader挂前,已经发出COMMIT命令的事务能够正确提交,还没来得及发出COMMIT命令的事务丢弃/删除。
16、Zookeeper是如何保证事务的顺序一致性的?
zxid(事务id):为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。
zxid是64位数字,
- 高32位是epoch编号,每经过一次Leader选举产生一个新的leader,新的leader会将epoch号+1;
- 低32位是消息计数器,每接收到一条消息这个值+1,新leader选举后这个值重置为0。
epoch:可以理解为当前集群所处的年代或者周期,每个leader就像皇帝,都有自己的年号,所以每次改朝换代,leader变更之后,都会在前一个年代的基础上加1。这样就算旧的leader崩溃恢复之后,也没有人听他的了,因为follower只听从当前年代的leader的命令。
17、什么情况下会进行leader选举?
- 服务器启动时;运行过程中leader节点宕机。
18、Zookeeper下Server 工作状态?
服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
- LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态。
- FOLLOWING:跟随者状态。表明当前服务器角色是Follower。
- LEADING:领导者状态。表明当前服务器角色是Leader。
- OBSERVING:观察者状态。表明当前服务器角色是Observer。
19、Zookeeper服务器角色有哪些?
Leader
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
Follower
- 处理客户端的非事务请求,转发事务请求给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
Observer
- 3.0版本以后,引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
- 处理客户端的非事务请求,转发事务请求给Leader服务器
- 不参与任何形式的投票
20、服务器启动时的leader选举实现原理?
每个节点启动的时候状态都是 LOOKING,处于观望状态,接下来就开始进行选主流程
【若进行 Leader 选举,则至少需要两台机器,一般设置集群个数为单数】
假设有三台服务器Server1、Server2、Server3。
在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。过程如下:
-
每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID、epoch,使用(myid,ZXID,epoch)来表示,此时Server1的投票为(1,0),Server2的投票为(2,0),然后各自将这个投票发给集群中其他机器。
-
接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING状态的服务器。
-
处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投
票进行PK,PK规则如下- 优先比较epoch
- 其次检查ZXID。ZXID比较大的服务器优先作为Leader
- 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1,0),接收Server2的投票为(2,0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2,0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
-
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2,0)的投票信息,此时便认为已经选出了Leader。
-
改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
21、运行过程中leader节点宕机,整个集群无法处理写请求,如何快速从其他节点里面选举出新的leader呢?
当leader失去与过半follower节点联系,可能是leader节点和follower节点之间产生了网络分区等等原因,那么此时的leader不再是合法的leader了,接着就会进入到崩溃恢复/leader选举模式:
崩溃恢复状态下zab协议需要做两件事:
- 选举出新的leader:
变更状态。Leader挂后,余下的非Observer服务器都会将自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
这时候的Leader选举和启动时期的Leader选举基本过程是一致的。 - 数据同步
22、什么是ACL权限控制机制?
Zookeeper作为一个分布式协调框架,内部存储了一些分布式系统运行时的状态的数据,比如leader选举、比如分布式锁。对这些数据的操作会直接影响到分布式系统的运行状态。
因此,为了保证zookeeper中的数据的安全性,避免误操作带来的影响,提供了一套ACL权限控制机制来保证数据的安全。
ACL(Access Control List)包括三个方面:
权限模式:
- IP:从IP地址粒度进行权限控制
- Digest:最常用,用类似于username:password的权限标识来进行权限配置,便于区分不同应用来进行权限控制
- World:最开放的权限控制方式,是一种特殊的digest模式,只有一个权限标识“world:anyone”
- Super:超级用户
授权对象:指权限赋予的用户或一个指定的实体,不同的权限模式下,授权对象不同

权限:指通过权限检查后可以被允许的操作
- Create:允许对子节点Create操作
- Read:允许对本节点GetChildren和GetData操作
- Write:允许对本节点SetData操作
- Delete:允许对子节点Delete操作
- Admin:允许对本节点setAcl操作
23、Chroot特性是什么?
3.2.0版本后,添加了Chroot特性,该特性允许每个客户端为自己设置一个命名空间。如果一个客户端设置了Chroot,那么该客户端对服务器的任何操作,都将会被限制在其自己的命名空间下。
24、zookeeper负载均衡和nginx负载均衡区别?
zookeeper的负载均衡是可以调控,nginx只是能调权重,其他需要可控的都需要自己写插件;但是nginx的吞吐量比zk大很多,应该说按业务选择用哪种方式。
25、集群最少要几台机器,集群规则是怎样的?
集群规则为2N+1台,N>0,即3台。
26、集群支持动态添加机器吗?
全部重启:关闭所有Zookeeper服务,修改配置之后启动。不影响之前客户端的会话。
逐个重启:在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
3.5版本开始支持动态扩容。
27、chubby是什么?
chubby是google的,完全实现paxos算法,不开源。
zookeeper是chubby的开源实现,使用zab协议,paxos算法的变种。
28、ZAB和Paxos算法的联系与区别?
相同点:
- 两者都存在一个类似于Leader进程的角色,由其负责协调多个Follower进程的运行
- Leader进程都会等待超过半数的Follower做出正确的反馈后,才会将一个提案进行提交
- ZAB协议中,每个Proposal中都包含一个epoch值来代表当前的Leader周期,Paxos中名字为Ballot
不同点:ZAB用来构建高可用的分布式数据主备系统(Zookeeper),Paxos是用来构建分布式一致性状态机系统。
29、Zookeeper的典型应用场景?
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master选举
- 分布式锁
- 分布式队列
·····
内容后续不断更新中~~~
====================================================================
······
帮助他人,快乐自己,最后,感谢您的阅读!
所以如有纰漏或者建议,还请读者朋友们在评论区不吝指出!
个人网站…知识是一种宝贵的资源和财富,益发掘,更益分享…
以上是关于Zookeeper- 总结的主要内容,如果未能解决你的问题,请参考以下文章