Tomcat框架和Servlet在Tomcat中执行原理
Posted 恒哥的爸爸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tomcat框架和Servlet在Tomcat中执行原理相关的知识,希望对你有一定的参考价值。
1. 概要介绍
Tomat是一个Servlet容器,不过它也内部也放置了Web应用服务。先上一张Tomcat静态的结构简图
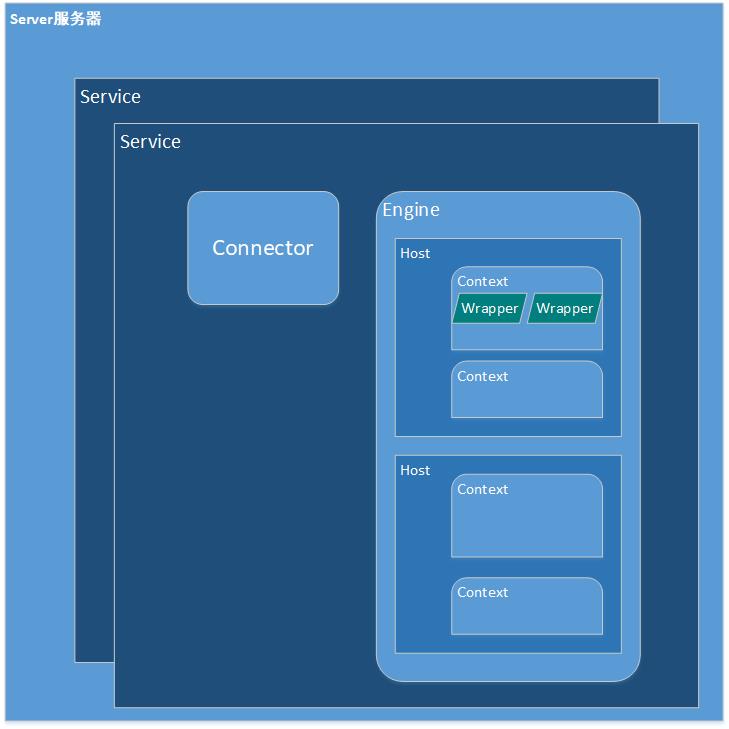
从上图可以看出,在Tomcat中,Service,Host,Context,Wrapper四个相邻的容器之间的关系都是1对n的关系。其中,Service还包含了一个Connector,对应服务连接端口;一个Executor,用来维护内部Servlet的执行线程;一个 Engine,一个Engine可以配置多个Host,也就是站点,站点的概念,可以理解为子域名,基地址,例如ris.xxxxx.com、emr.xxxxx.com;每个Host可以对应多个Context,这个和含有WEB-INF(Web.xml)文件夹相对应,可以理解为一级目录,例如xxxxx.com/risManager、xxxxx.com/emrManager;每个Wrapper都对应一个Servlet。
这些概念其实都是很具体的,我们从Server.xml配置文件中,就很容易理解这些概念;我绘制了一张图,首先可以从部署的位置就直接能判断的是,含有WEB-INF(Web.xml)文件夹中的内容,也就是我们自己开发的应用,就和上边介绍的Context概念相对应,在Web.xml中,<servlet>标签和Wrapper的概念相对应。
另外,Service和Host概念,应用开发工程师可能比较陌生,属于Tomcat自己管理和部署概念,这些概念同样可以在Server.xml配置文件中能得到进行体现。例如还是下图中,如果要求在一个ip地址的多个端口上分别部署多开发的应用,就可以通过以下的示例配置实现。这种方式,很适合做SaaS的2B企业,将按照业务拆分好的云化的子服务应用,私有化部署到客户小规模的单台或者有限的几台实体服务器上,同时,这种方式还可以针对特定的子业务服务去分配适合的线程数量(Executor),以最大的限度的为客户解决成本。
同样,也可以在一台服务器上的一个端口上,部署多个Host站点的方式,部署多个开发应用。这种方式比较适合在服务器前没有负载,直接用域名解析后端服务器的时候,使用子域名直接访问后端服务的情况。这种方式,我在实际工作不怎么用,在云端部署时,我们还是要在后端服务前加上SLB的,这样,域名解析就直接关联负载了,也就不存在上边这个需求。

2 ServletContext和Servlet
先说下Servlet和ServletContext中的概念
1 Servlet的生命周期,如下图所示
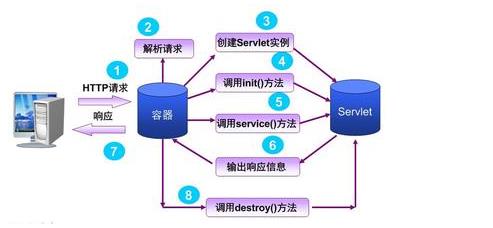
2 Servlet是单例的,所以,线程是不安全的,所有请求线程都使用同一个Servlet实例。如果需要线程安全,需要实现STM(single thread mothod)
而ServletContext是对这些Servlet的生命周期和使用时机进行管理,主要的职责有
1 对Servlet进行创建,销毁,调用
2 分配线程,每次http的请求都会生成或者从线程池获取一个可用线程,service调用结束后,将线程返还给线程池
3 针对网络访问端口的监听,特定协议的解析,字符流或者字节流的解析和编码(自己写过这种编解码,真的很不健壮)
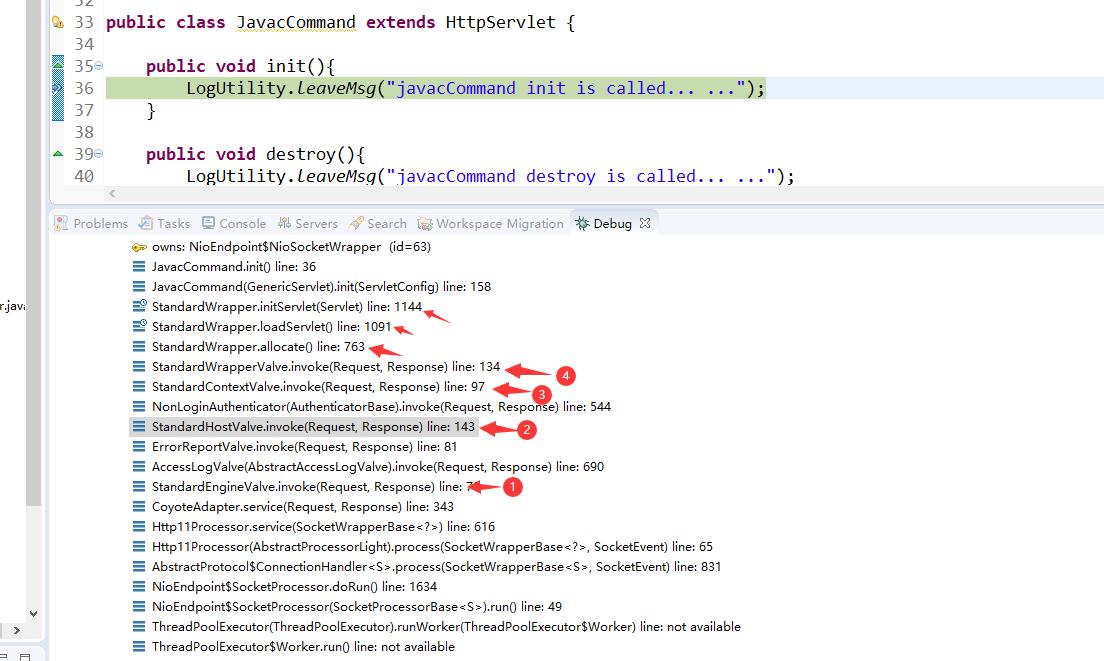
下面就从源码解读上,去窥视下整个Servlet工作的动态过程。首先,自定义一个Servlet类JavacCommand,并在Web.xml中,进行配置
3 Tomcat中Service,Host,Context,Wrapper四容器原理和源码解读
public class StandardPipeline{
private Valve first = null;
private Valve basic = null;
public void addValve(Valve valve) {
if (first == null) {
first = valve;
valve.setNext(basic);
} else {
Valve current = first;
while (current != null) {
if (current.getNext() == basic) { //插入到队列的倒数第二位置,最后一个位置一直都是basic
current.setNext(valve);
valve.setNext(basic);
break;
}
current = current.getNext();
}
}
}
}public class StandardHost {
protected Pipeline pipeline = new StandardPipeline(this);
public StandardHost() {
super();
pipeline.setBasic(new StandardHostValve());
}
}接下来,我们开始讲整个动态调用到Servlet实例的过程;我们直接看StandardHostValve的invoke函数
final class StandardHostValve extends ValveBase {
public final void invoke(Request request, Response response) {
// 1 选择对应的Context容器
Context context = request.getContext();
// 2 在容器的阀链中,找到第一个阀类,执行invoke
context.getPipeline().getFirst().invoke(request, response);
}
}大概画了一张面条图,这些容器和阀类,通过设计的一个职责链模式的模式组织到一起,进行工作。
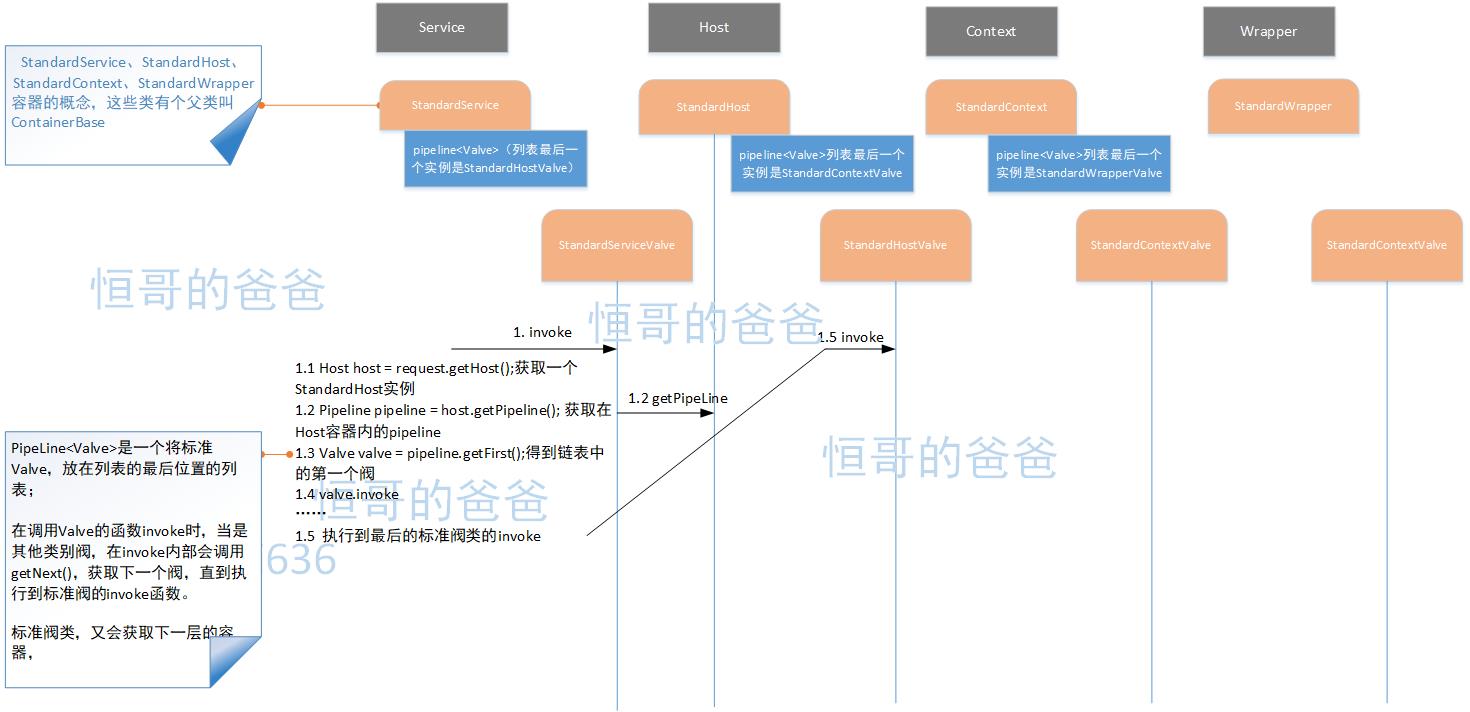
在网上找到这张图,感觉比我做的好,很能说明整个执行的过程。大家注意,这的StandardHost容器中,有个AccessLogValve阀,就是在平时的配置中常常使用的阀类,大家可以看上文中的一个Tomcat部署结构的图中的server.xml中的配置。
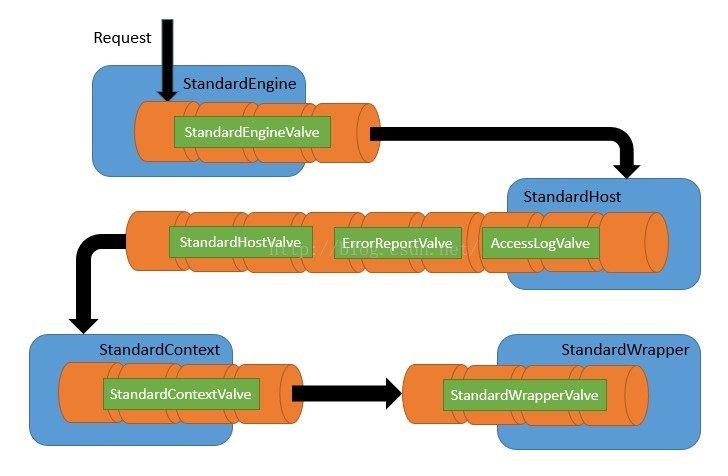
最后,还有一个问题没有解决,就是在各个标准阀类中查找对应的容器的过程。
3 针对当前request容器类的创建和查询
大家看上边的图“自定义Servlet堆栈调用“,CoyoteAdapter在执行Service之前,首先找到当前uri对应的各级容器,是通过CoyoteAdapter.postParseRequest获取的,
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res)
throws Exception {
//这个地方,是我省略掉一堆代码,直接也是new出来的
Request request = new Request();
Response response = new Response();
//查找到合适的容器并且附加到request上
postParseSuccess = postParseRequest(req, request, res, response);
//就是2小节中描述的过程
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
}postParseRequest函数更长,直接吧我能看懂的代码段贴上来
protected boolean postParseRequest(org.apache.coyote.Request req, Request request,
org.apache.coyote.Response res, Response response) throws IOException, ServletException {
//通过一个Mapper类来实现的,最后将request.mappingData给填充完毕
connector.getService().getMapper().map(serverName, decodedURI,
version, request.getMappingData());
return true;
}下面看Mapper.java类
public void map(MessageBytes host, MessageBytes uri, String version,
MappingData mappingData) throws IOException {
internalMap(host.getCharChunk(), uri.getCharChunk(), version, mappingData);
}
通过内部的结构将,需要的各级容器查询到。
这篇文章的篇幅太大,下一篇,详细将这个Mapper的创建和查询介绍下。
以上是关于Tomcat框架和Servlet在Tomcat中执行原理的主要内容,如果未能解决你的问题,请参考以下文章