二数据集与数据类型R与统计
Posted 是璇子鸭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二数据集与数据类型R与统计相关的知识,希望对你有一定的参考价值。
引言
按照要求格式来创建含有研究信息的数据集是任何数据分析的第一步。在R中,这个任务包括以下两步:
选择一种数据结构来存储数据;
将数据输入或导入到该数据结构中
因此,本文将先叙述了R中用于存储数据的多种结构,具体为向量、因子、矩阵、数据框以及列表的用法。熟悉这些数据结构和访问其中元素的表述方法将十分有助于了解R的工作方式,便于后续的编程。
我将在下一篇博客介绍一些在R中导入数据的可行方法。手工输入数据当然可以,除此之外,我们也可以从外部源导入数据。数据源可以是文本文件、电子表格、统计软件和各类数据库管理系统。就我自己的日常使用来说,我更倾向于直接利用文本文件导入数据,虽然这样有些粗暴,但就小规模数据,可以说十分简单快捷了。
文章主要参考了《R语言实战.第2版》、B站系列课程《R语言入门与数据分析》 并结合自己的经验总结而成。
注:强烈推荐想要系统性学习R的朋友购买《R语言实战》,这本书可以说是很经典了
数据集的概念
在数据分析中,数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。下面提供了一个美国犯罪相关统计的数据集(state.x77)
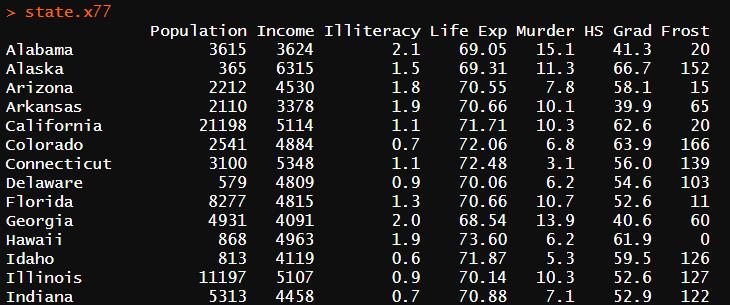
由图我们可以清楚地看到此数据集的结构, Alabama、Alaska等是行/实例标识符,Population、Income等为相关变量。
R中有许多用于储存数据的结构,包括标量、向量、数组、数据框和列表。图中所示实际上对应着R中的矩阵。多样化的数据结构赋予了R及其灵活的数据处理能力。
同时,R可以处理的数据类型(模式)包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节)。而在分组分析中很实用的就是对因子(factors)的应用,这个也将在本文后半截提到。
数据结构
在上面我们提到R拥有许多用于储存数据的对象类型,它们在存储数据的类型、创建方式、结构复杂度,以及用于定位和访问其中个别元素的标记等方面均有所不同。这里借用《R语言实战.第二版》中的示意图:
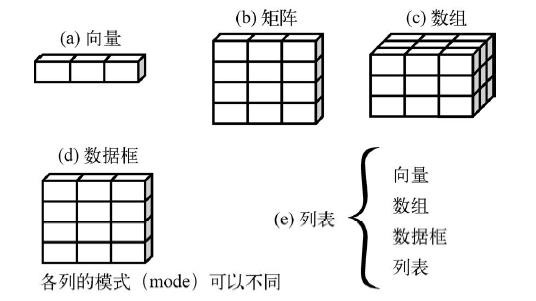
下面,就让我们从向量开始,逐个探究每一个数据结构。
黑底部分代码为最基础用法,其他为相关补充,可根据目录选择性查看
1 向量
向量是用于存储数值型、字符型或逻辑型数据的一维数据。执行组合功能的函数c()可用来创建向量。示例如下:
> a <- c(3, 1, 4, 0, 7, 9)
> b <- c("h", "e", "y")
> c <- c(TRUE, FALSE, TRUE , FALSE)
这里,a为数值型向量,b是字符型向量,而c是逻辑型向量。
- 单个向量中的数据必须拥有相同的类型或模式,同一向量中无法混杂不同模式的数据。
- 标量是只含一个元素的向量(如:f <- 520)
- 注意区分大小写,使用小写c()来创建向量
- 在R中注释符为"#"
通过在方括号中给定元素所处位置的数值即可访问向量中的元素。例如:
基本用法:
>a
[1] 3 1 4 0 7 9
> a[4:6] #使用冒号用于生成数值序列(第4个到第6个)
[1] 0 7 9
> a[-1] #去掉第一个元素后的结果,并不改变原数据
[1] 1 4 0 7 9
> a[1]
[1] 3 #与python不同,R的索引是从1开始的

实用命令补充(非必须):


关于运算

2 矩阵
矩阵是一个二维数组,只是每个元素拥有相同的模式。可通过函数matrix()创建矩阵
myymatrix <- matrix(data, nrow=number_of_rows, ncol=number_of_columns,
byrow=logical_value, dimnames=list(
char_vector_rownames, char_vector_colnames))
注:
data-矩阵中的所有元素
nrow\\ncol-指定行\\列的维数
dimnames-可选、以字符型向量表示的行名和列名
byrow-矩阵按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认为按列填充
创建矩阵
>y <- matrix(1:20, nrow = 4, ncol = 5) #创建一个4*5的矩阵
> y
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
>data <- c(101, 202, 303, 404)
> rnames <- c("R1","R2") #行命名
> cnames <- c("C1","C2") #列命名
> mymatrix <- matrix(data, nrow = 2, ncol=2, byrow = TRUE, dimnames = list(rnames, cnames)) #按行填充
> mymatrix
C1 C2
R1 101 202
R2 303 404
>mymatrix <- matrix(data, nrow = 2, ncol=2, byrow = FALSE, dimnames = list(rnames, cnames)) #按列填充
> mymatrix
C1 C2
R1 101 303
R2 202 404
矩阵下标的使用 #这部分与python十分相似
> x <- matrix(1:9, 3, 3, byrow = TRUE)
> x
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> x[2,] #第二行
[1] 4 5 6
> x[,2] #第二列
[1] 2 5 8
> x[1, c(1,3)] #第一行的第一列与第一行的第三列
[1] 1 3
矩阵都是二维的,和向量类似,仅能包含一种数据类型。但维度超过2维时,不妨试用数组。当有多种模式的数据时,即可使用数据框。
3 数组
数组(array)与矩阵类似,但维度可大于2数组可通过array函数创建,形式如下:
myarray <- array(data, dimensions, dimnames)
注:
data-数组中的数据
dimensions-数值型向量,给出每个维度下标的最大值
dimnames-可选的、各维度名称标签的列表
示例:
> dim1 <- c("A1", "A2")
> dim2 <- c("B1", "B2", "B3")
> dim3 <- c("C1", "C2", "C3", "C4")
> z <- array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3)) #4个2行3列的矩阵,个人认为也可理解成数据立方体
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24

4 数据框
与矩阵不同,数据框不同的列可以包含不同模式的数据,它与我们通常在SAS、SPSS和Stata中看到的数据集类似,是在R中最常处理的数据结构。
数据框可通过data.frame()创建:
mydata <- data.frame(col1, col2, col3,…)
其中的列向量col1、col2、col3等可以是任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数names指定。
示例
ID <- c(1, 2, 3, 4)
> age <- c(17, 34, 28, 35)
> diabetes <- c('type1', "type2", "type1", "type1")
> status <- c("poor", "improves", "excellent", "poor")
> patientdata <- data.frame(ID, age, diabetes, status)> patientdata
ID age diabetes status
1 1 17 type1 poor
2 2 34 type2 improves
3 3 28 type1 excellent
4 4 35 type1 poor
数据框每一列数据的模式必须唯一,每一行可以不同,可以理解为比较规则的矩阵。
元素选取
patientdata[1:2] #选取前两列
ID age
1 1 17
2 2 34
3 3 28
4 4 35
> patientdata[c("ID", "status")] #选取特定列
ID status
1 1 poor
2 2 improves
3 3 excellent
4 4 poor
> patientdata$status #利用美元符获取特定变量信息
[1] "poor" "improves" "excellent" "poor"
当需要多次访问数据集的变量数据,频繁使用美元符可能让人生厌,故可以联合使用函数attach()和detach来简化代码。
attach()和detach()
函数attach可将数据框添加到R的搜索路径中,在遇到变量名后,将检查搜索路径中的数据框。而detach则是其反向操作,将数据框从搜索路径中移除,但并不会对数据框本身做任何处理。
summary(mtcars$mpg)
plot(mtcars$mpg, mtcars$disp)
plot(mtcars$mpg, mtcars$wt)
以上代码也可写成:
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars)

- 最好在分析一个单独的数据框,并且不太可能有多个同名对象时使用上面两个函数。
- 同时,因为R严格区分大小写,在定义变量名时尽量避免与R内置函数或数据集名称相撞,这样不易混淆。
- 链接后直接访问,用完一定要记得取消链接
5 因子
变量可归结为名义型、有序型或连续型变量。
名义型变量是没有顺序之分的类型变量;
有序型变量表示一种顺序关系,而非数量关系(比如职称,我们知道其相对高低,却不能量化某两个职称间究竟差多少);
连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量(比如年龄)。
因子主用于分类与频数分析,类型为名义变量和次序变量。
函数factor()以一个整数向量的形式储存类别值,下面我们将通过示例来更直观了解因子的作用:
(factor主用于分组分析或绘图)
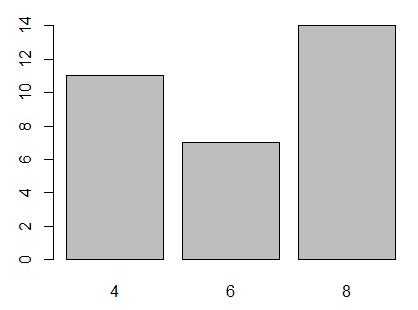
> mtcars$cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> table(mtcars$cyl)
4 6 8
11 7 14
> #cyl为因子,其level为4,6,8。
> f <- factor(c('red','red','green','blue')) #因子定义
> f
[1] red red green blue
Levels: blue green red
> class(f)
[1] "factor"
> week <- factor(c('Mon','Fri','Thu','Wed','Mon','Fri','Sun'))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Fri Mon Sun Thu Wed
#可以发现未体现出水平次序,故用ordered来对因子水平排序
> week <- factor(c('Mon','Fri','Thu','Wed','Mon','Fri','Sun'),ordered = T,levels = c('Mon','Tue','Wed','Thu','Fri','Sat','Sun'))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun
> fcyl <- factor(mtcars$cyl)
> fcyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
Levels: 4 6 8
> plot(mtcars$cyl)
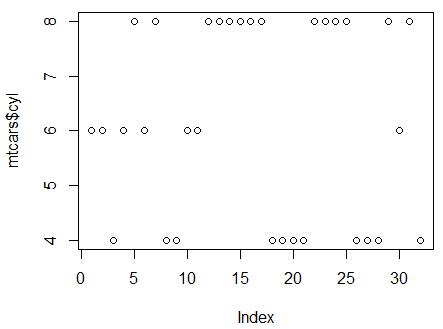
> plot(factor(mtcars$cyl)) #可以很直观地体会因子(cyl)的分类作用
6 列表
列表是R数据类型中最复杂的一种,因为它就像混合饮料一样,允许整合若干(可能无关的)对象到单个对象名下。例如,某个列表可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list()创建列表:
mylist <- list(object1, object2, …)
示例:
> a <- 1:20
> b <- matrix(1:20,4)
> c <- mtcars
> d <- 'this is a test list'
#相比于矩阵或向量,列表内的数据类型并不要求一致
> mlist <- list(a,b,c,d) #列表生成
> mlist
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[3]]
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
(列表第三个元素后半截略)
[[4]]
[1] "this is a test list"
> mlist <- list(first = a, second = b, third =c, forth=d)#元素命名
> mlist[1]#取元素
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> mlist['first']
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> mlist[c('first','forth')]
$first
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$forth
[1] "this is a test list"
> class(mlist[1])
[1] "list"
> class (mlist[[1]]) #两个中括号为元素本身
[1] "integer"

缺失数据






字符串





日期与时间
> ?ts
> sales <- round(runif(48,min=50,max=100))
> sales
[1] 78 62 81 90 62 97 69 76 63 82 50 71 96 94 71 79 86 70 71 55 73 95 70 77 87 56 59 75 70 74 57 84 97 80 76 97 53 75 68 96 80 66 86 51
[45] 55 63 51 66
> a <- ts(sales,start = 2010,end = 2014,frequency = 1)#按年
> a
Time Series:
Start = 2010
End = 2014
Frequency = 1
[1] 78 62 81 90 62
> ts(sales,start = c(2010,5),end = c(2014,4),frequency = 4)#按季度
Qtr1 Qtr2 Qtr3 Qtr4
2011 78 62 81 90
2012 62 97 69 76
2013 63 82 50 71
2014 96 94 71 79
> ts(sales,start = c(以上是关于二数据集与数据类型R与统计的主要内容,如果未能解决你的问题,请参考以下文章