Hive基础知识 03
Posted Xiao Miao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive基础知识 03相关的知识,希望对你有一定的参考价值。
文章目录
Hive基础知识
一、Hive函数:多行转多列
1.创建表
#1.创建r2c1.txt文件
vim /export/data/r2c1.txt
#2.添加数据
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
#3.创建表
create table row2col1(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\\t';
#4.加载数据
load data local inpath '/export/data/r2c1.txt' into table row2col1;
2.case when
case when 语法:
#1.第一种
case 列名
when value1
then result1
else resultn
end
#2.第二种
case
when 列名= value1 then result1
when 列名=value2 then result2.......
else resultn
end
HQL语句:
select
col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from
row2col1
group by
col1;
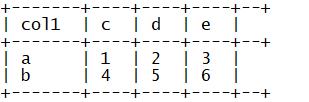
二、Hive函数:多行转单列
1.创建表
#1.创建r2c2.txt文件
vim /export/data/r2c2.txt
#2.添加数据
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
#3.创建表
create table row2col2(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\\t';
#4.加载数据
load data local inpath '/export/data/r2c2.txt' into table row2col2;
2.collect_list、collect_set和concat
collect_list、collect_set:聚合函数,将多行的内容合并为一行的内容
collect_list(col):不做去重
collect_set(col):做去重
concat 、concat_ws:字符串拼接
concat(str1,str2,str3……):不能指定分隔符,有一个为null,整个结果就为null
concat_ws(分隔符,str1,str2,str3……):可以指定分隔符,只要一个不为null,结果就不为null
HQL语句:
select
col1,
col2,
concat_ws(",",collect_set(cast(col3 as string))) as col3
from row2col2
group by col1,col2;
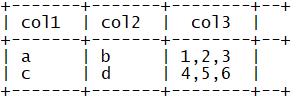
三、Hive函数:多列转多行
1.创建表
#1.创建c2r1.txt文件
vim /export/data/c2r1.txt
#2.添加数据
a 1 2 3
b 4 5 6
#3.创建表
create table col2row1(
col1 string,
col2 int,
col3 int,
col4 int
)row format delimited fields terminated by '\\t';
#4.加载数据
load data local inpath '/export/data/c2r1.txt' into table col2row1;
2.union all
union all:实现行的合并
select col1,'c' as col2,col2 as col3 from col2row1
union all
select col1,'d' as col2,col3 as col3 from col2row1
union all
select col1,'e' as col2,col4 as col3 from col2row1;

四、Hive函数:多列转单行
1.创建表
#1.创建c2r2.txt文件
vim /export/data/c2r2.txt
#2.添加数据
a b 1,2,3
c d 4,5,6
#3.创建表
create table col2row2(
col1 string,
col2 string,
col3 string
)row format delimited fields terminated by '\\t';
#4.加载数据
load data local inpath '/export/data/c2r2.txt' into table col2row2;
2.explode
explode:将一个集合类型的内容中的每一个元素变成一行
select
col1,
col2,
lv.col3 as col3
from
col2row2
lateral view
explode(split(col3, ',')) lv as col3;
五、Hive函数:反射函数
反射函数:用于在Hive中直接调用Java中类的方法
语法:
reflect(类,方法,参数)
测试:
select reflect("java.util.UUID", "randomUUID");
select reflect("java.lang.Math","max",20,30);
select reflect("org.apache.commons.lang.math.NumberUtils","isNumber","123");
六、Hive函数:JSON处理
常见的数据格式:结构化数据格式
csv:每一列都是用逗号分隔符
tsv:每一列都是用制表符分隔符
json:专有的JSON格式文件
properteies
xml
1.创建表
#1.创建hivedata.json文件
vim /export/data/hivedata.json
#2.添加数据
{"id": 1701439105,"ids": [2154137571,3889177061],"total_number": 493}
{"id": 1701439106,"ids": [2154137571,3889177061],"total_number": 494}
#3.创建表
create table tb_json_test1 (
json string
);
#4.加载数据
load data local inpath '/export/data/hivedata.json' into table tb_json_test1;
2.get_json_object
用于解析JSON字符串,指定取出JSON字符串中的某一个元素
select
get_json_object(t.json,'$.id'),
get_json_object(t.json,'$.total_number')
from
tb_json_test1 t ;
3.json_tuple
UDTF函数,一次性取出多个JSON字符串的元素
select
t1.json,
t2.*
from
tb_json_test1 t1
lateral view
json_tuple(t1.json, 'id', 'total_number') t2 as c1,c2;
JSONSerDe
功能:可以直接在加载数据文件的时候解析JSON格式
配置:修改hive-env.sh
export HIVE_AUX_JARS_PATH=/export/server/hive-2.1.0-bin/hcatalog/share/hcatalog/hive-hcatalog-core-2.1.0.jar


重启hiveserver2
创建表
#1.创建表
create table tb_json_test2 (
id string,
ids array<string>,
total_number int)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
#2.加载数据
load data local inpath '/export/data/hivedata.json' into table tb_json_test2;
查询数据
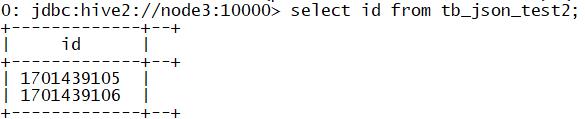
七、Hive函数:窗口聚合函数
1.窗口的基本语法
聚合函数(参数) over (partition by 列1[order by 列2] [window_szie])
window_szie:窗口大小,指定的是函数处理数据的范围
N preceding :前N行
N following :后N行
current row:当前行
unbounded preceding 表示从前面的起点,第一行
unbounded following:表示到后面的终点,最后一行
2.group by和partition by
分组:group by:一组返回一条
分区:窗口函数partition by:一组返回多条
3.窗口聚合函数
max、min、avg、count、sum
4.窗口大小示例
例:
sum(参数) over(partition by 列1 order by 列2)
指定了partition by和order by,没有指定窗口大小
默认窗口大小,分区的第一行到当前行
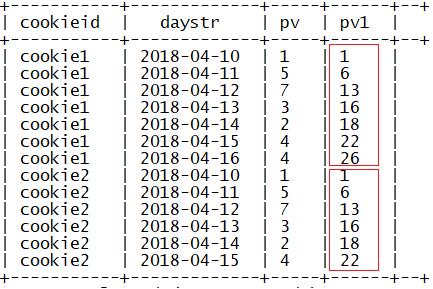
sum(参数) over(partition by 列1 )
指定了partition by,没有指定窗口大小
默认窗口大小:第一行到最后一行
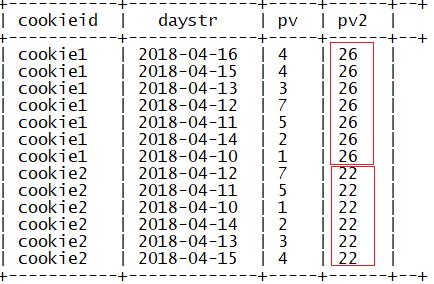
sum(参数) over(partition by 列1 order by 列2 rows
between unbounded preceding and current row)
指定窗口大小为当前行到最后一行,结果和指定分区和排序结果一致
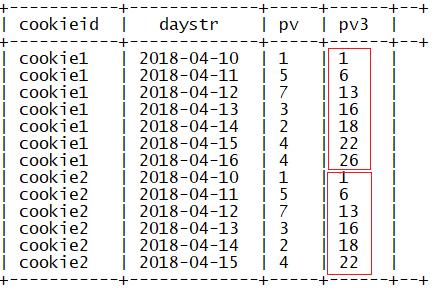
sum(参数) over(partition by 列1 order by 列2 rows
between 2 preceding and current row)
指定窗口大小为前2行到当前行
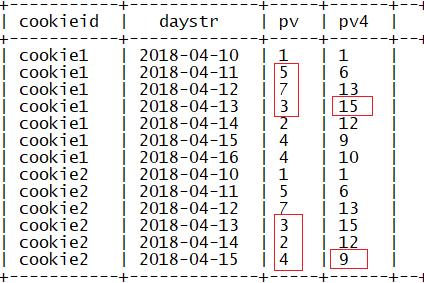
sum(参数) over(partition by 列1 order by 列2 rows
between 2 preceding and 1 following)
指定窗口大小为前两行到后一行
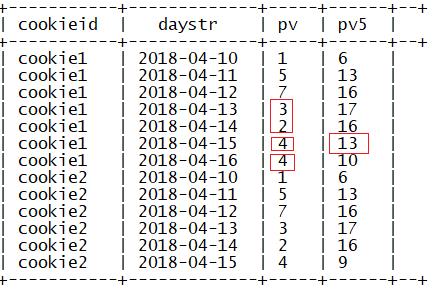
sum(参数) over(partition by 列1 order by 列2 rows
between current row and 2 following)
指定窗口大小为当前行到后两行
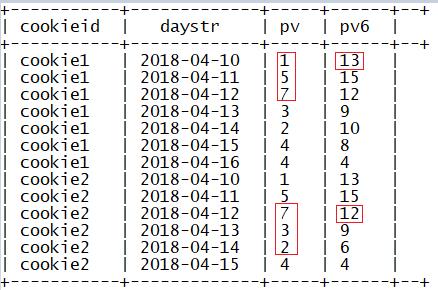
sum(参数) over(partition by 列1 order by 列2 rows
between current row and unbounded following)
指定窗口大小当前行到最后一行
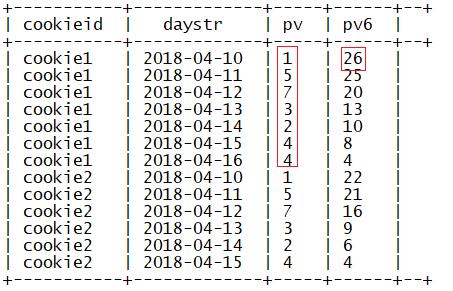
八、Hive函数:窗口位置函数
1.first_value
功能:取每个分区内某列的第一个值
语法:
first_value(列1) over (partition by 列 order by 列3 desc)
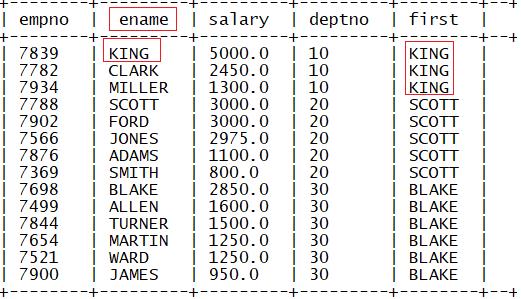
2.last_value
功能:取每个分区内某列的最后一个值
语法:
last_value(列1) over (partition by 列 order by 列3 descrows between unbounded preceding and unbounded following)
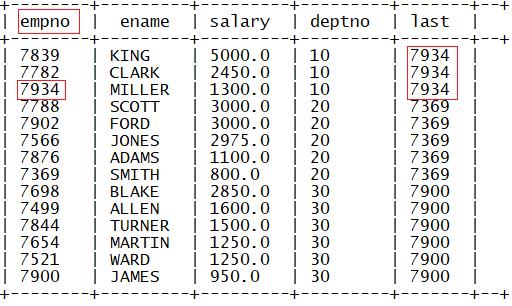
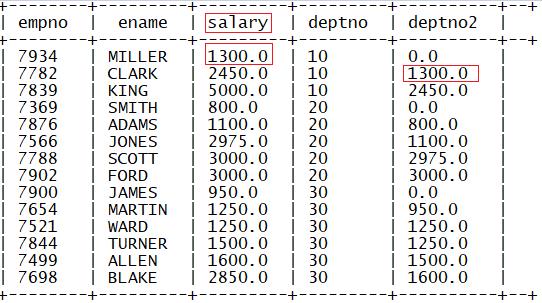
3.lag
功能:取每个分区内某列的相对当前行前N行该行的值
语法:
log(列1,N,defaultValue) over (partition by 列2 order by 列3)
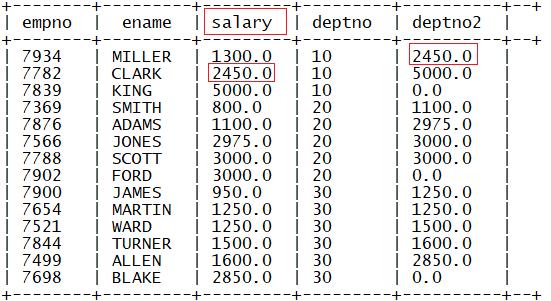
4.lead
功能:取每个分区内某列的相对当前行后N行该行的值
语法:
lead(列1,N,defaultValue) over (partition by 列2 order by 列3)
九、Hive函数:窗口分析函数
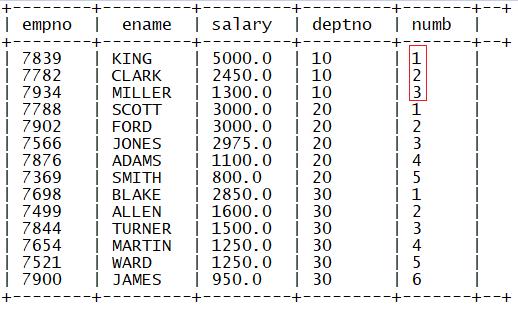
1.row_number
功能:用于实现分区内记录编号
语法:
row_number() over (partition by 列1 order by 列2)
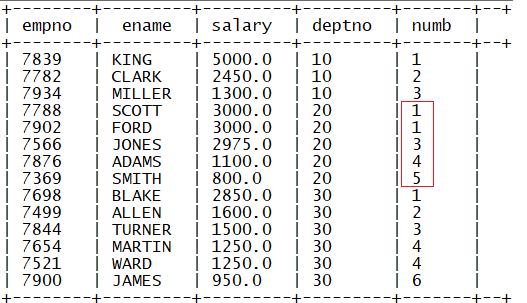
2.rank
功能:用于实现分区内排名编号(排名有间隔)
3.dense_rank
功能:用于实现分区内排名编号(排名没有间隔)
dense_rank() over (partition by 列1 order by 列2)
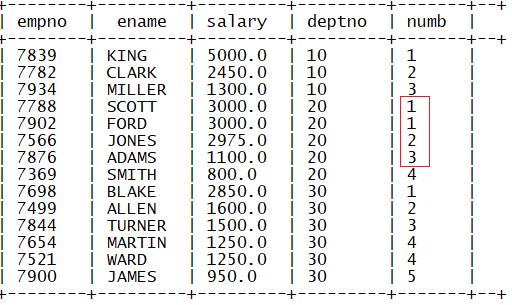
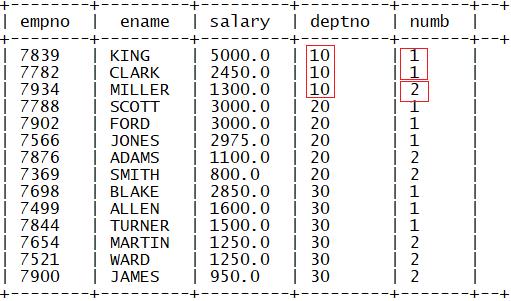
4.ntile
功能:将每个分区内排序后的结果均分成N份,如果不能均分,优先分配编号小的
语法:
ntile(N) over (partition by 列1 order by 列2)
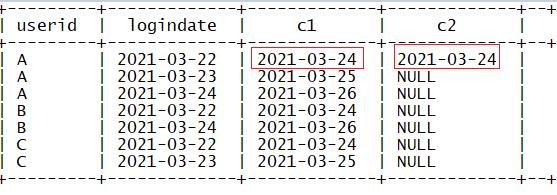
十、Hive函数:窗口函数案例
要求:统计连续登录N天的用户(N>=2)
1.创建表
#1.创建lg.txt文件
vim /export/data/lg.txt
#2.添加数据
A,2021-03-22
B,2021-03-22
C,2021-03-22
A,2021-03-23
C,2021-03-23
A,2021-03-24
B,2021-03-24
#3.创建表
create table if not exists lg(
userid string,
logindate date)
row format delimited fields terminated by ',';
#4.加载数据
load data local inpath '/export/data/lg.txt' into table lg;
2.HQL
统计连续登录3天的用户
select a.userid as userid,a.logindate as logindate from(
select
userid,
logindate,
date_add(logindate,2) as c1,
lead(logindate,2) over (partition by userid order by logindate) as c2
from lg) a
where a.c1=a.c2;

十一、Hive优化:参数优化
MapReduce参数优化:推测执行,JVM重用
Hive参数优化:Fetch Task,严格模式,并行执行,压缩
1.推测执行
问题:
经常运行一个Mapreduce程序,有多个MapTask和ReduceTask,由于网络或者资源故障导致有一个Task一直不能运行结束
解决:
开启推测执行
如果appmaster发现某个Task一直不能结束,会在另外节点上启动同一个Task,谁先运行结束,另外一个会被kill
属性
mapreduce.map.speculative=true
mapreduce.reduce.speculative=true
hive.mapred.reduce.tasks.speculative.execution=true
2.JVM重用
问题:
每次每个Task都会申请一个JVM进程来运行程序,JVM进程需要内存等资源,每个Task运行完成以后,这个JVM就被销毁了
解决:
申请了一个JVM进程的资源以后,可以运行多个Task,实现资源复用
配置
set mapreduce.job.jvm.numtasks=10
3.Fetch Task
Hive自带了小型计算引擎,一部分简单的SQL语句不走Mapreduce,直接由Fetch Task处理
属性
hive.fetch.task.conversion
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
4.严格模式
老版本的属性:hive.mapred.mode=nonstrict/strict
如果为严格模式:hive会限制一些SQL语句的运行
新版本的属性:
hive.strict.checks.type.safe
是否允许一些风险性的类型比较
bigints and strings.
bigints and doubles.
hive.strict.checks.cartesian.product
是否允许笛卡尔的产生
5.并行执行
Hive在解析SQL时,默认不会并行执行Stage,只会单个Stage执行
设置并行度,提高Hive解析编译的性能
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8
6.压缩
先配置Hadoop中的压缩,设置Mapreduce的shuffle的中间输出压缩
属性
#配置多个Mapreduce中的中间Mapreduce的结果压缩
hive.exec.compress.intermediate=true
十二、Hive优化:SQL优化
基本规则:PPD
谓词下推 Predicate Pushdown(PPD)的思想简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,降低了Reduce端的数据负载,节约了集群的资源,也提升了任务的性能。
十三、Hive优化:表设计优化
1.分区表
优化底层MapReduce输入,提高性能
2.分桶表
提前将数据分桶存储,提高Join性能
3.文件格式
文件格式在创建表时可以指定,语法如下:
stored as file_format
默认格式:textfile
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
SEQUENCEFILE:二进制
列式存储:rcfile、orc、parquet
列式存储的优点:
相同的数据,存储占用的空间更小
列式存储:对于SQL分析读取列比较方便
构建列式索引
十四、数据倾斜:现象原因
现象:
运行一个程序,这个程序的某一个Task一直在运行,其他的Task都运行结束了,进度卡在99%或者100%
原因:
基本原因:这个ReduceTask的负载要比其他Task的负载要高,ReduceTask的数据分配不均衡
根本原因:分区的规则
默认分区:根据K2的Hash值取余reduce的个数
优点:相同的K2会由同一个reduce处理
缺点:可能导致数据倾斜
十五、数据倾斜:解决方案
数据倾斜场景:
group by/count(distinct)
join
1.group by / count(distinct)的解决方案
开启Combiner
hive.map.aggr=true
随机分区
方式1:开启参数
hive.groupby.skewindata=true
开启这个参数以后,底层会自动走两个MapReduce
第一个MapReduce自动实现随机分区,第二个MapReduce做最终的聚合
方式2:手动指定
distribute by rand()
2.join的解决方案
尽量避免走Reduce Join
Map Join:
尽量将不需要参加Join的数据过滤,将大表转换为小表
构建分桶Bucket Map Join
以上是关于Hive基础知识 03的主要内容,如果未能解决你的问题,请参考以下文章