java面经题-1
Posted 尚墨1111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java面经题-1相关的知识,希望对你有一定的参考价值。
1. 为什么hashmap是线程不安全的?
1)数据插入覆盖
HashMap底层是一个Entry数组。当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。此实现不是同步的。如果多个线程同时访问一个哈希映射第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
底层为什么要用红黑树
红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。加快检索速率。红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于插入删除等操作效率提高很多。红黑树不像avl树一样追求绝对的平衡,他允许局部很少的不完全平衡,这样对于效率影响不大,但省去了很多没有必要的调平衡操作,avl树调平衡有时候代价较大,所以效率不如红黑树。
因为一开始数据存数组如果发生hash冲突,这个时候需要把冲突的数据放到后面的链表中(链地址法),如果hash冲突的数据过多,就会让链表过长,查询效率会变低,所以jdk1.8之后当链表长度大于8时就是转化为红黑树。其中换会牵涉到一个数组扩容,
为什么是红黑树?为什么不直接采用红黑树还要用链表?
1、因为红黑树需要进行左旋,右旋操作, 而单链表不需要,
如果元素小于8个,查询成本高,新增成本低
如果元素大于8个,查询成本低,新增成本高
扩容后数组元素的位置(无链)
参考:文章
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
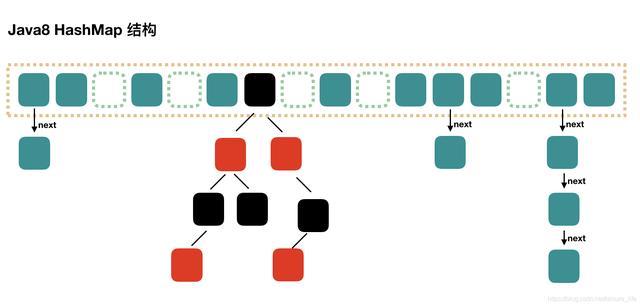
是通过hash 值(通过一个hash方法进一步运算过的)与数组长度减一进行与运算 得到的,如下图所示:
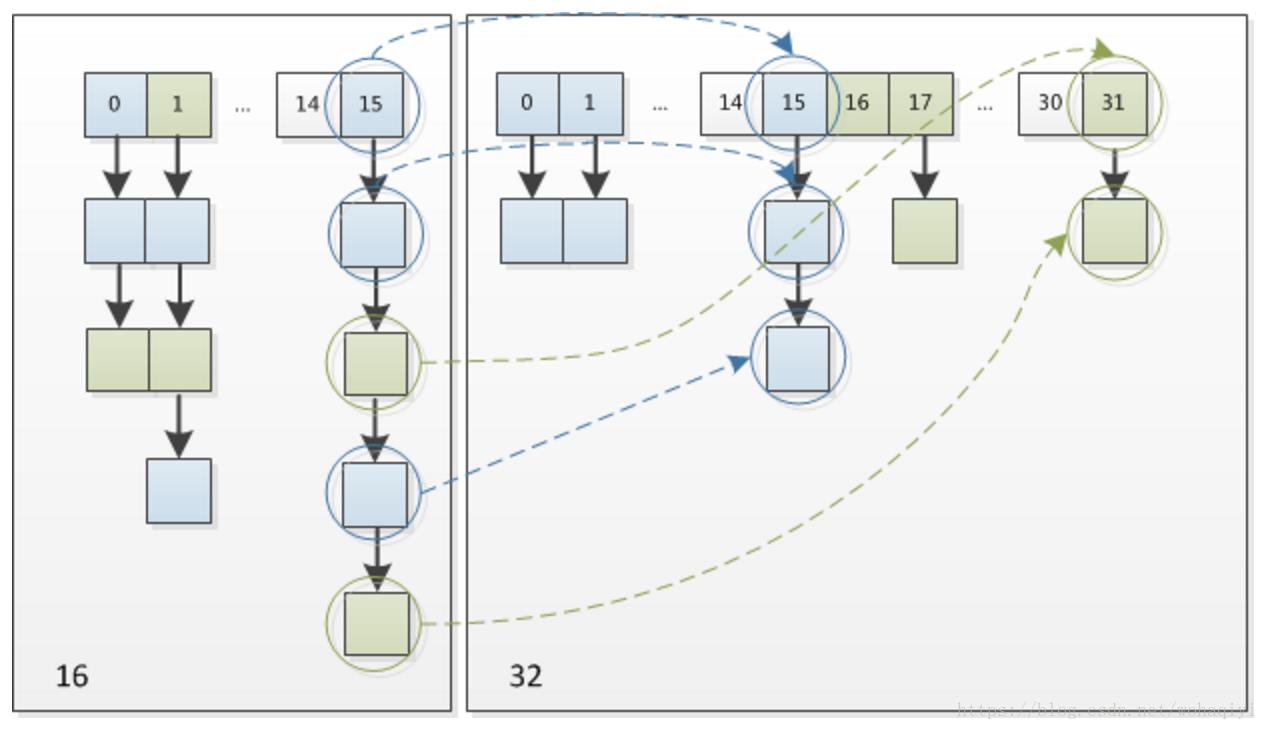
原来的元素,要么在原位置,要么在原位置+原数组长度 那个位置上。
扩容后元素的位置(有链)
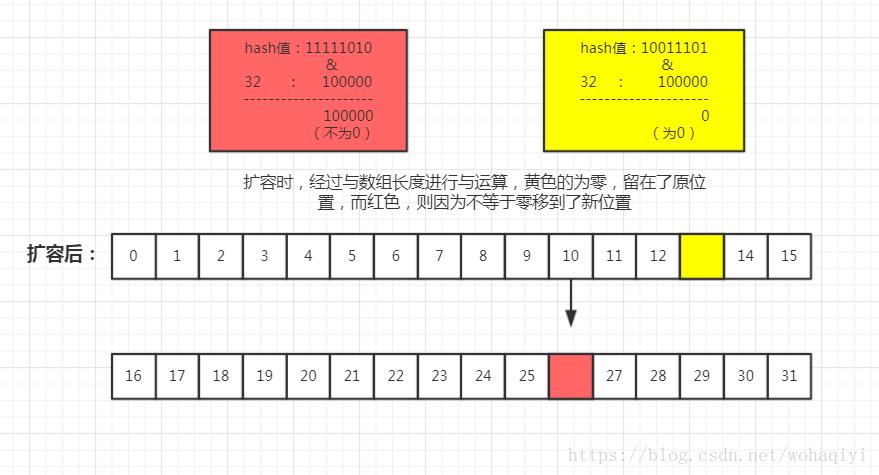
(e.hash & oldCap) == 0 来将链上的元素分成两份,
对元素分别放到了原位置 和原位置+原数组长度 上。
2. 如果要存放1000个键值对,初始化多大的hashmap不需要动态扩容呢?
table.size == threshold * loadFactor
构造方法传递的 initialCapacity,最终会被 tableSizeFor() 方法动态调整为 2 的 N 次幂,以方便在扩容的时候,计算数据在 newTable 中的位置。
若 thresholdNew * 0.75 > 1000,则 thresholdNew > 1333.3。
而我们上面分析构造传1000的时候,thresholdNew 会被 tableSizeFor() 调整为 1024,1024 < 1333.3不满足。
又我们知道了 tableSizeFor() 这个方法返回大于输入参数且最接近的2的整数次幂的数,则我们构造时传入1024~2048之间的数,就会保证HashMap存1000条数据不需要动态扩容。
3. Java中 volatile和 synchronize的区别?
①volatile轻量级,只能修饰变量。synchronized重量级,还可修饰方法
②volatile只能保证数据的可见性,不能用来同步,因为多个线程并发访问volatile修饰的变量不会阻塞。
synchronized不仅保证可见性,而且还保证原子性,因为,只有获得了锁的线程才能进入临界区,从而保证临界区中的所有语句都全部执行。多个线程争抢synchronized锁对象时,会出现阻塞。
volatile本质是在告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化.
4. java中的单例模式
单例模式有以下特点:
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。在计算机系统中,线程池、缓存、日志对象、对话框、打印机、显卡的驱动程序对象常被设计成单例。这些应用都或多或少具有资源管理器的功能。每台计算机可以有若干个打印机,但只能有一个Printer Spooler,以避免两个打印作业同时输出到打印机中。每台计算机可以有若干通信端口,系统应当集中管理这些通信端口,以避免一个通信端口同时被两个请求同时调用。总之,选择单例模式就是为了避免不一致状态,避免政出多头。
1、饿汉式(线程安全,调用效率高,但是不能延时加载):
public class ImageLoader{
private static ImageLoader instance = new ImageLoader;
private ImageLoader(){}
public static ImageLoader getInstance(){
return instance;
}
}
一上来就把单例对象创建出来了,要用的时候直接返回即可,这种可以说是单例模式中最简单的一种实现方式。但是问题也比较明显。单例在还没有使用到的时候,初始化就已经完成了。也就是说,如果程序从头到位都没用使用这个单例的话,单例的对象还是会创建。这就造成了不必要的资源浪费。所以不推荐这种实现方式。
2.懒汉式(线程安全,调用效率不高,但是能延时加载):
public class SingletonDemo2 {
//类初始化时,不初始化这个对象(延时加载,真正用的时候再创建)
private static SingletonDemo2 instance;
//构造器私有化
private SingletonDemo2(){}
//方法同步,调用效率低
public static synchronized SingletonDemo2 getInstance(){
if(instance==null){
instance=new SingletonDemo2();
}
return instance;
}
}
3.静态内部类实现模式(线程安全,调用效率高,可以延时加载)
1 public class SingletonDemo3 {
2
3 private static class SingletonClassInstance{
4 private static final SingletonDemo3 instance=new SingletonDemo3();
5 }
6
7 private SingletonDemo3(){}
8
9 public static SingletonDemo3 getInstance(){
10 return SingletonClassInstance.instance;
11 }
12
13 }
4.枚举类(线程安全,调用效率高,不能延时加载,可以天然的防止反射和反序列化调用)
1 public enum SingletonDemo4 {
2
3 //枚举元素本身就是单例
4 INSTANCE;
5
6 //添加自己需要的操作
7 public void singletonOperation(){
8 }
9 }
5. Java中UUID类的简单了解与使用
什么是UUID?,Universally Unique Identifier,即通用唯一识别码。
UUID的作用,让分布式系统中的所有元素都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。
public class GenerateUUID {
//java、中默认生成 UUID
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
}
}
java锁
说说偏向锁是什么?
说说可重入锁是什么?
如何实现可重入锁?
可重入锁如何判别是同一个对象获取锁?
java异常
1.java异常
2.静态变量与实例变量的区别
3.反射机制,应用
4.单例模式
反射机制的底层实现是什么?动态呢?动态的实现原理?
说一下 java 类加载器的工作机制
jvm内存模型
JVM内存分配策略
GC过程
类加载过程
双亲委派模型
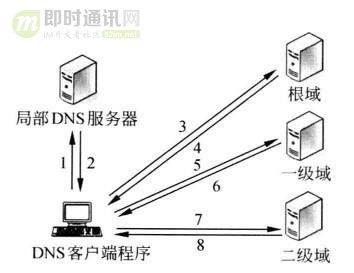
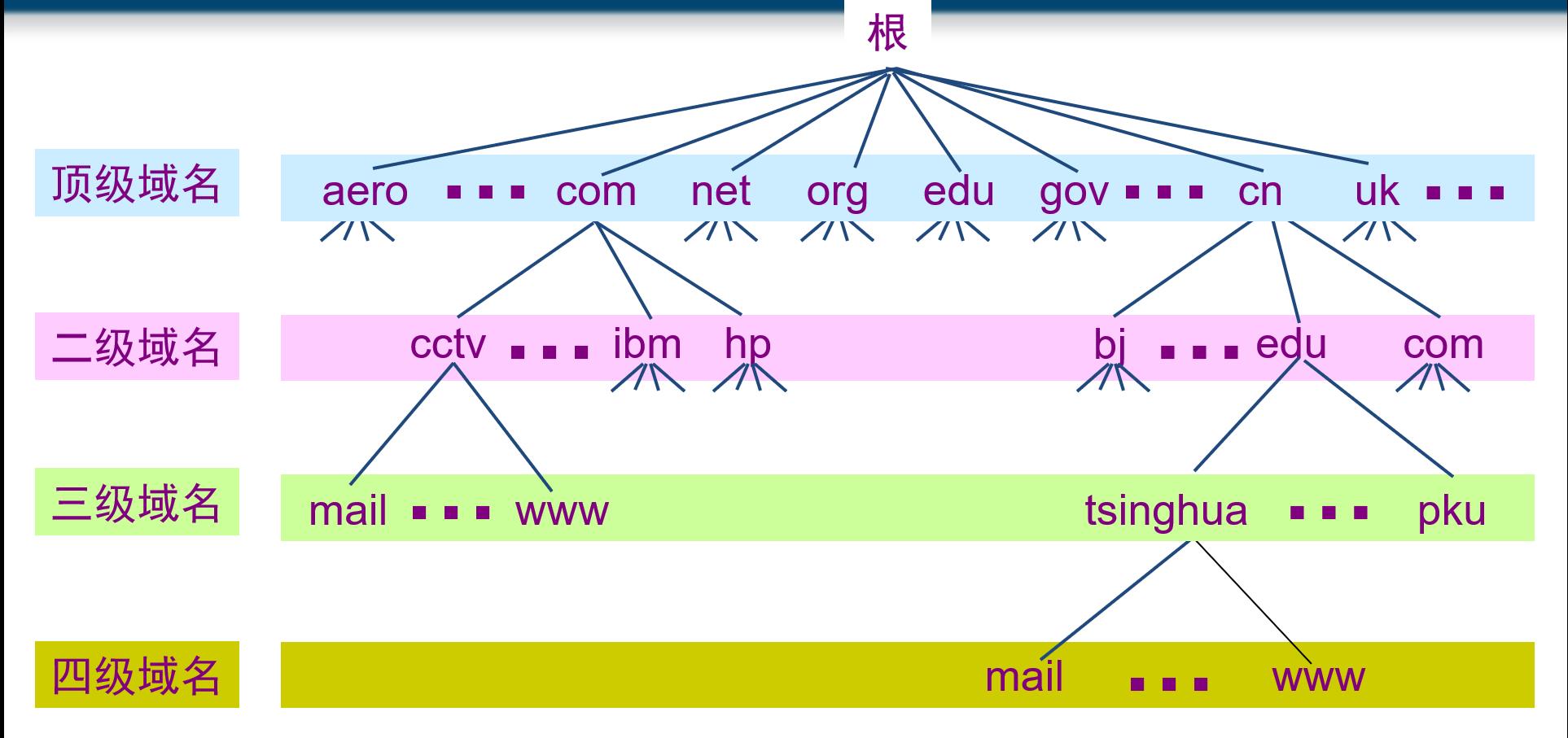
DNS解析的具体步骤
根就如同顶级域名后面的那个点。根把不同的顶级域名解析指到不同的服务器上。是顶级域名的上级。
递归查询
浏览器查询缓存,是否有百度的ip,如果有结束
hosts文件中是否有百度的ip地址,如果有结束
如果本地DNS有百度的ip地址,如果有,本地DNS将其返回给请求主机,然后结束
根服务器根据com后缀,将请求转发给顶级域名服务器
顶级域名服务器查询自己的权威DNS服务器
权威DNS域名服务器查询到百度的IP,将结果返回给顶级,顶级返回给根,根返回给本地,本地返回给请求主机,结束。
迭代查询
浏览器查询缓存,是否有百度的ip,如果有结束
hosts文件中是否有百度的ip地址,如果有结束
如果本地DNS有百度的ip地址,如果有,本地DNS将其返回给请求主机,然后结束
(前三步不变)
根服务器根据com后缀,将顶级服务器IP告诉给本地服务器
本地服务器访问顶级DNS,顶级DNS将权威DNS返回给本地
本地服务器访问权威DNS,权威DNS将百度IP返回给本地
本地将百度IP返回给请求主机
mysql数据库
16.数据库中有哪些引擎,之间有哪些区别?
17.B+树索引和hash树索引的区别?
MySQL的存储引擎是什么?
innodb的数据结构是什么?
b+树中的主键索引和普通索引的叶子结点有啥区别
b+树中的主键索引和唯一索引的叶子结点的区别
InnoDB与MyISAM的区别
各自的优势是什么,能用在什么场合
事务的四大特性
事务的隔离级别
1.数据库什么引擎,什么特点,索引有什么特点,B+树有什么优势。
2.聚簇索引比非聚簇索引有什么优势,劣势。
3.维护索引有什么代价。
4.事务怎么实现。
5.默认隔离级别。
7.分页:查第1页和查第10000页有什么区别。性能上有不同吧。
11.数据库连接池,遇到过什么问题吗。
16.sql优化,慢查询
17.数据库编码。
18.varchar存多少个字符
介绍你认为学习成果最多的两个项目
项目的组织结构
如何优化你的项目(***)
为何考虑使用mysql+redis(***)
操作系统
7.操作系统中用户态和内核态的区别?
8.操作系统的线程和进程的区别?
9.线程间的通信方式有哪些?
10.线程间的切换和进程间的切换哪个代价大?
排序算法,及相应的时间复杂度
22.有序链表删除重复节点,实现基本的数据结构
以上是关于java面经题-1的主要内容,如果未能解决你的问题,请参考以下文章