GFS(GlusterFS) 分布式存储平台
Posted serendipity_cat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GFS(GlusterFS) 分布式存储平台相关的知识,希望对你有一定的参考价值。
GFS 分布式存储平台
一、GFS概述
GFS(Gluster File System) 是一个可扩展、开源的分布式文件系统(可以很好的体现出弹性伸缩的特点),用于大型的、分布式的、对大量数据进行访问的应用
在传统的解决方案中,GFS 能够灵活的结合物理的,虚拟的和云资源去体现高可用和企业级的性能存储
1.1 GFS的三个组件
1.1.1 存储服务器(Brick Server)
客户端(不在本地)(且,有客户端,也会有服务端,这点类似于 NFS,但是更为复杂)
1.1.2 存储网关(NFS/Samaba)
无元数据服务器
元数据是核心,描述对象的信息,影响其属性
例如NFS,存放数据本身,是一个典型的元数据服务器可能存在单点故障,故要求服务器性能较高,服务器一旦出现故障就会导致数据丢失
反过来看,所以无元数据服务不会有单点故障
那么数据存放在哪里呢?会借用分布式的原则,分散存储,不会有一个统一的数据服务器
1.2 GFS的特点
1.2.1 扩展性和高性能
可扩展性,扩展节点
通过多节点提高性能
1.2.2 高可用性
不存在单点故障,有备份机制
类似 Raid 的容灾机制
1.2.3 全局统一命名空间
集中化管理,类比 API 的性质/概念
系统里根据他命名所定义的隔离区域,是一个独立空间
统一的名称空间,与客户端交互,把请求存放至后端的块数据服务器
1.2.4 弹性卷管理
方便扩容及对后端存储集群的管理与维护
较为复杂
1.2.5 基于文件系统的标准使用协议
基于标准化的文件使用协议
让 CentOS 兼容 GFS
二、GFS平台部署
2.1 拓扑图
| 节点名 | IP地址 | 磁盘 |
|---|---|---|
| master | 192.168.0.10 | /dev/sdb-e |
| slave1 | 192.168.0.20 | /dev/sdb-e |
| slave2 | 192.168.0.30 | /dev/sdb-e |
| slave3 | 192.168.0.40 | /dev/sdb-e |
2.2 更改节点名称
#配置所有服务器节点名称[需要不同]
hostnamectl set-hostname node1
su -
2.3 磁盘批量格式化[所有节点]
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
#关闭防火墙及安全机制
#推荐使用xshell并列执行
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\\np\\n\\n\\n\\nw\\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh
#赋权脚本并执行
df -hT
#确认磁盘空间
echo "192.168.0.10 node1" >> /etc/hosts
echo "192.168.0.20 node2" >> /etc/hosts
echo "192.168.0.30 node3" >> /etc/hosts
echo "192.168.0.40 node4" >> /etc/hosts
#添加四个节点的域名解析
2.4 安装GFS[所有节点]
yum install centos-release-gluster -y
yum install -y glusterfs glusterfs-server glusterfs-fuse
yum install glusterfs-rdma -y
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
2.5 添加节点并创建集群
2.5.1 Node1
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
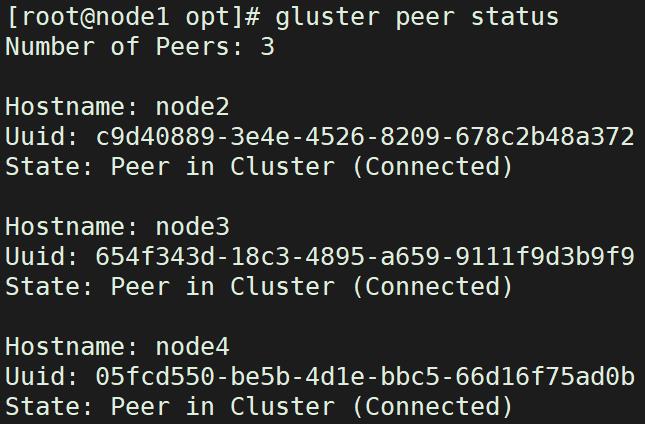
gluster peer status
2.6 根据需求创建卷
| 卷名称 | 卷类型 | Brick |
|---|---|---|
| dis-volume | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| stripe-volume | 条带卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| rep-volume | 复制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| dis-stripe | 分布式条带卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| dis-rep | 分布式复制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1) |
2.6.1 创建分布式卷组
分布式卷将文件分布在卷中的单元之间。您可以使用分布式卷,其中需要扩展存储,冗余不是很重要,就是由其他硬件/软件层提供
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume list
#查看类型
gluster volume start dis-volume
#开启
gluster volume info dis-volume
#查看卷信息
2.6.2 创建复制卷
复制的卷在卷中的砖块之间复制文件。您可以在高可用性和高可靠性至关重要的环境中使用复制卷

gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
#指定类型为replica,数值为2,且后面跟了2个Brick Server,所以创建的是复制卷
gluster volume start rep-volume
gluster volume info rep-volume
2.6.3 创建分布式复制卷
分布式复制卷跨卷中的复制块分布文件。您可以在需要扩展存储且高可靠性至关重要的环境中使用分布式复制卷。分布式复制卷在大多数环境中还提供了更好的读取性能

gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
#指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume start dis-rep
gluster volume info dis-rep
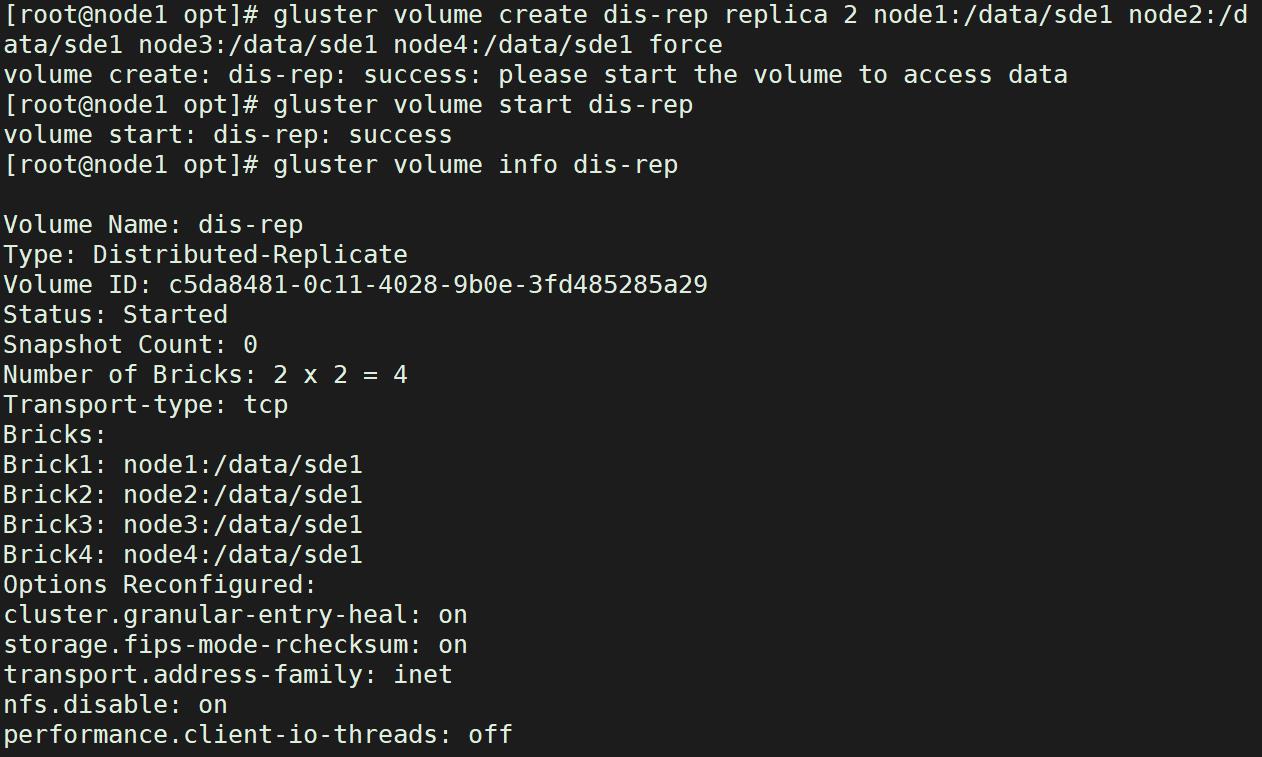
2.6.4 分散
分散的卷基于擦除代码,提供空间效率高的磁盘或服务器故障保护。它将原始文件的编码片段存储到每个块中,这种方式只需要片段的一个子集就可以恢复原始文件。在不丢失对数据访问的情况下丢失的块的数量是由管理员在卷创建时配置的
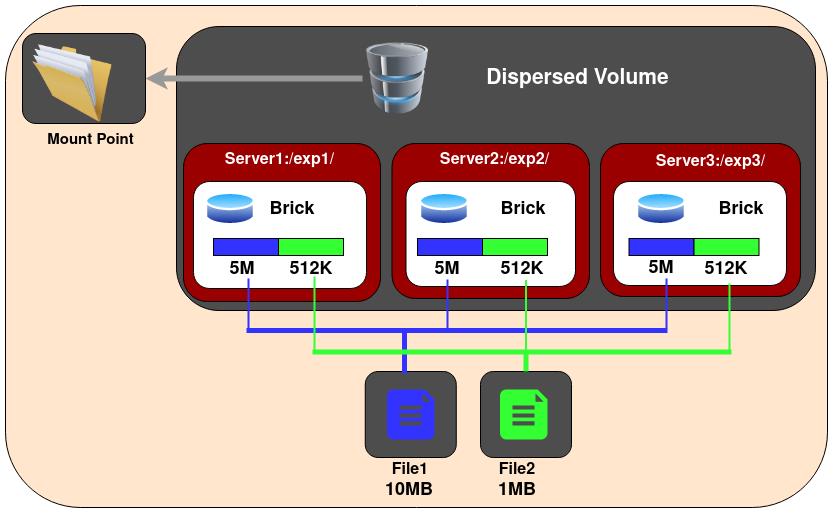
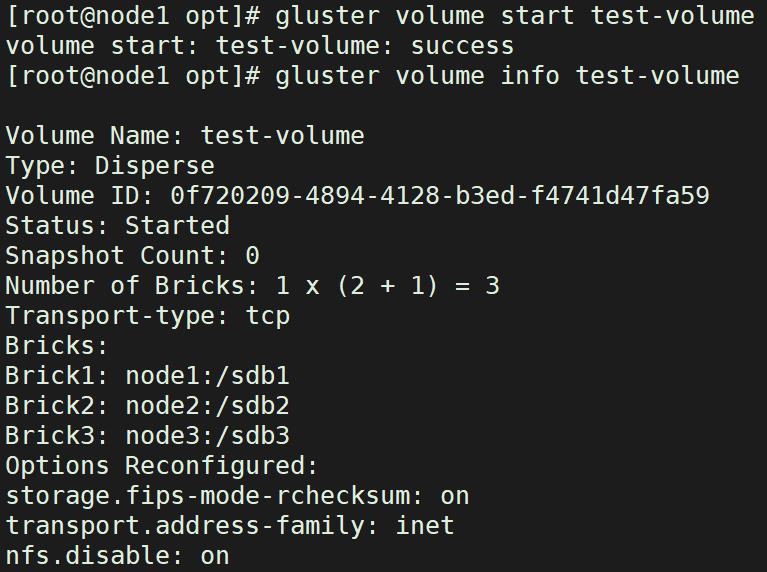
gluster volume create test-volume disperse 3 redundancy 1 node1:/sdb1 node2:/sdb2 node3:/sdb3 force
gluster volume start test-volume
gluster volume info test-volume
2.6.5 分布式分散卷
跨分散的子卷分发文件。这与分发复制卷具有相同的优点,但是使用分散将数据存储到块中
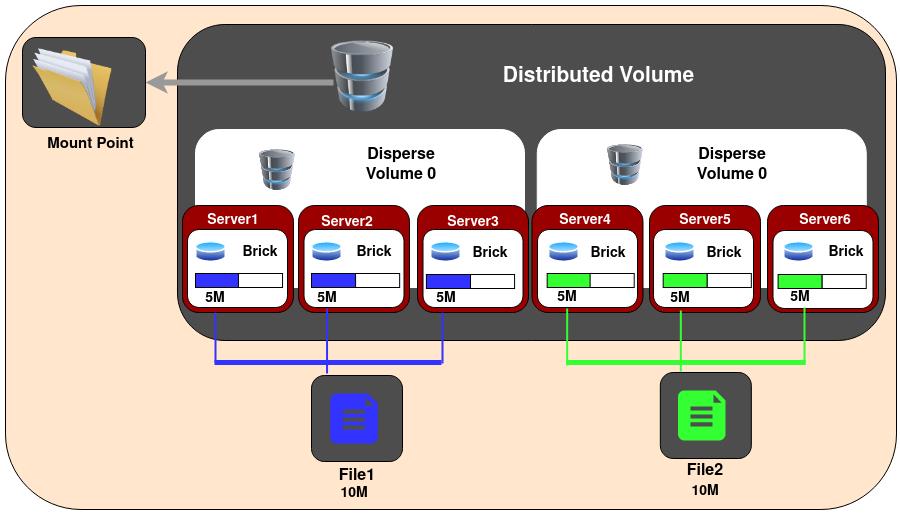
gluster volume create test-volume disperse 3 redundancy 1 server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6
gluster volume start test-volume
gluster volume info test-volume
三、Client客户端部署与测试
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
yum install -y glusterfs glusterfs-fuse
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test
echo "192.168.0.10 node1" >> /etc/hosts
echo "192.168.0.20 node2" >> /etc/hosts
echo "192.168.0.30 node3" >> /etc/hosts
echo "192.168.0.40 node4" >> /etc/hosts
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:test-volume /test/dis_per
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-rep /test/dis_rep
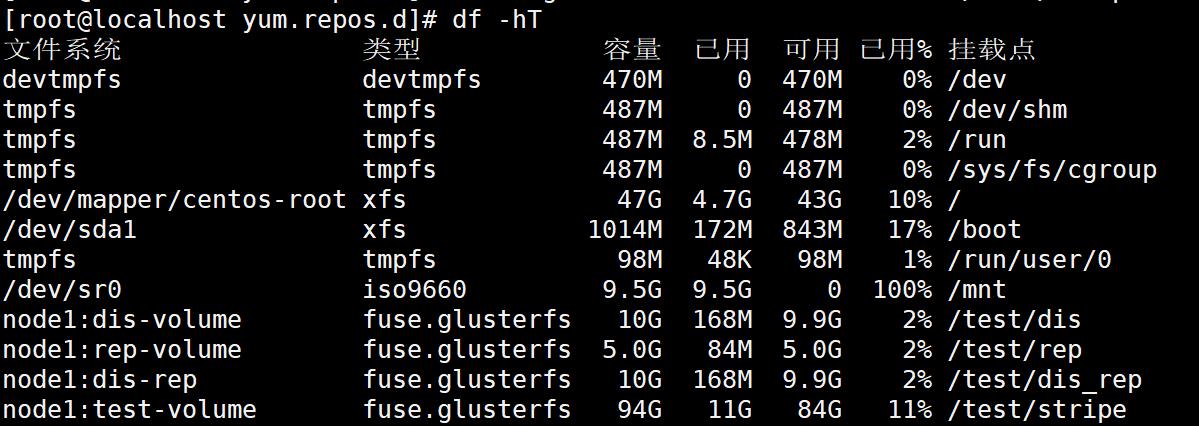
df -hT
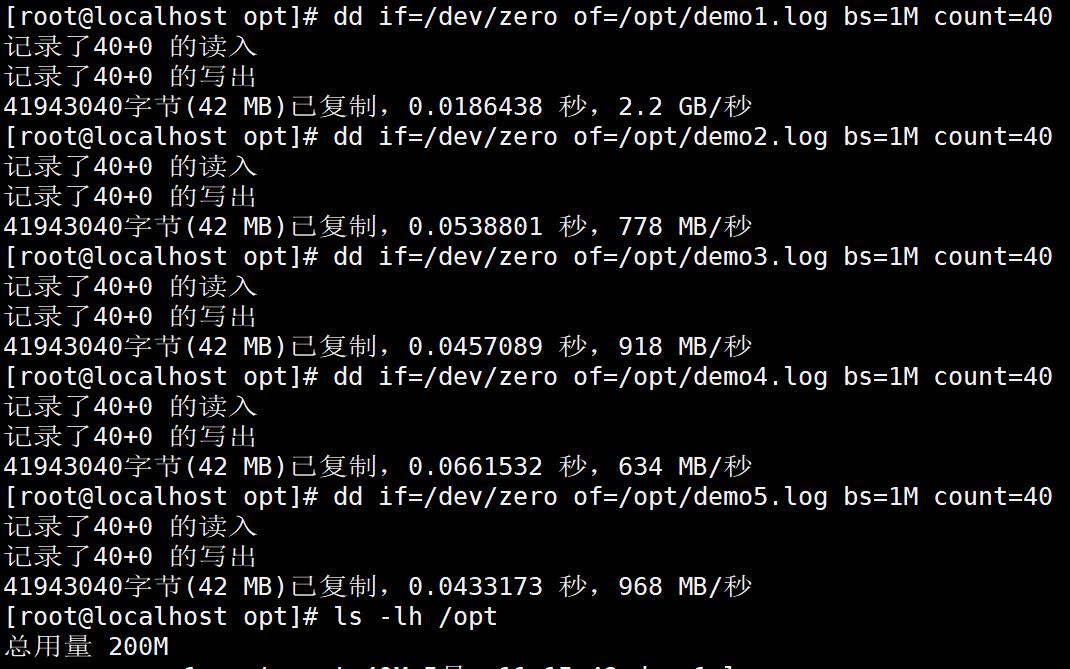
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40
#生成一个特定大小的文件给与/opt/demo*.log下,大小为1M,共处理40次
ls -lh /opt
cp demo* /test/dis
cp demo* /test/stripe/
cp demo* /test/rep/
cp demo* /test/dis_rep/
3.1 查看文件分布
3.1.1 查看分布式文件分布
node1
ls -lh /data/sdb1

node2

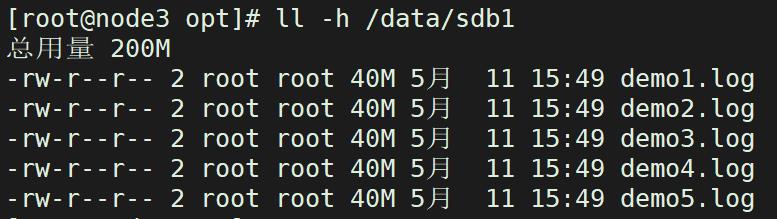
3.1.2 查看复制卷文件分布
node3/node4
ll -h /data/sdb1

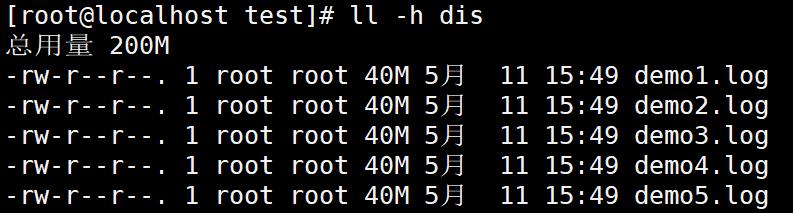
3.2 冗余测试
3.2.1 在客户端查看文件
cd /test/
ll -h dis
以上是关于GFS(GlusterFS) 分布式存储平台的主要内容,如果未能解决你的问题,请参考以下文章