ElasticsearchElasticsearch自定义评分的N种方法
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticsearchElasticsearch自定义评分的N种方法相关的知识,希望对你有一定的参考价值。

1.概述
首先参考文章:【Elasticsearch】Elasticsearch 相关度评分 TF&IDF
然后转载文章:实战 | Elasticsearch自定义评分的N种方法
2.三个问题
期望Elasticsearch搜索结果更准确,不可回避的三个问题
问题1:用户真正的需求是什么?
如果不能获得用户的搜索意图,搜索的准确性无从谈起。
比如:同样输入“锤子”,工匠期望的是钉子对应的“锤子”,老罗的粉丝期望的是“锤子科技”、“锤子便签”、“锤子手机”等。
即使同一用户发出的同一个查询,也可能因为用户所处场景不同,其期望结果也存在很大差异。
问题2:哪些信息是和用户需求真正相关的?
搜索引擎本质是一个匹配过程,即从海量的数据中找到匹配用户需求的内容。
判定内容与用户查询的相关性(relevance,如上图),一直是搜索引擎领域核心研究课题之一。
Relevance is a search engine’s holy grail. People want results that are closely connected to their queries.— Marc Ostrofsky
https://medium.com
问题3:哪些信息是最值得用户信赖的?
衡量信息满足用户需求的两个核心属性。
其一:如前所述的相关性。
其二:信息是否值得信赖。
举例:疫情环境下,新华网、人民网发布文章的可信性远大于某公众号大V发布的。
3.相关性
Elasticsearch相关性是如何控制的?
结构化数据库如mysql,只能查询结果与数据库中的row的是否匹配?回答往往是“是”、“否”。
如:
select title from hbinfos where title like ‘%发热%’。
而全文搜索引擎Elasticsearch中不仅需要找到匹配的文档,还需根据它们相关度的高低进行排序。
实现相关度排序的核心概念是评分。
_score就是Elasticsearch检索返回的评分。该得分衡量每个文档与查询的匹配程度。
"hits" : [
{
"_index" : "kibana_sample_data_flights",
"_type" : "_doc",
"_id" : "FHLWlHABl_xiQyn7bHe2",
"_score" : 3.4454226,
每个文档都有与之相关的评分,该得分由正浮点数表示。文档分数越高,则文档越相关。
分数与查询匹配成正比。查询中的每个子句都将有助于文档的得分。
4.Elasticsearch 如何计算评分?
官方文档相关度评分背后的理论解读如下:
Lucene(或 Elasticsearch)使用 布尔模型查找匹配文档,并用一个名为 实用评分函数的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率和 向量空间模型,同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
Elasticsearch 5 之前的版本,评分机制或者打分模型基于 TF-IDF实现。
注意:从Elasticsearch 5之后, 缺省的打分机制改成了Okapi BM25。
BM25 的 BM 是缩写自 Best Match, 25 貌似是经过 25 次迭代调整之后得出的算法,它也是基于 TF/IDF 进化来的。
4.1 TF-IDF与BM25 的相同点
TF-IDF 和 BM25 同样使用 逆向文档频率 来区分普通词(不重要)和非普通词(重要),同样认为:
-
文档里的某个词出现次数越频繁,文档与这个词就越相关,得分越高。 -
某个词在集合所有文档里出现的频率是多少?频次越高,权重 越低,得分越低 。某个词在集合中所有文档中越罕见,得分越高。
4.2 TF-IDF与BM25 的不同点
BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
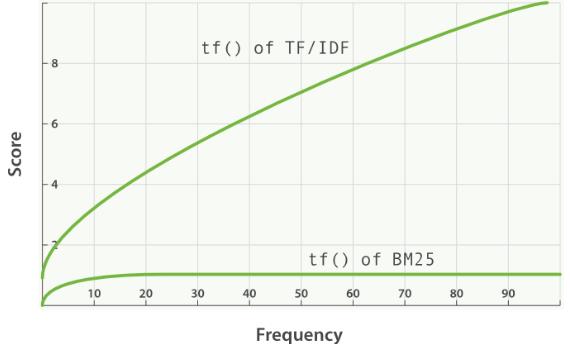
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量k,用来限制TF值的增长极限。下面是两者的公式:
传统 TF Score = sqrt(tf)
BM25的 TF Score = ((k + 1) * tf) / (k + tf)
BM25还引入了平均文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。BM25的TF公式里,除了常量k外,引入另外两个参数:L和b。
(1)L是文档长度与平均长度的比值。如果文档长度是平均长度的2倍,则L=2。
(2)b是一个常数,它的作用是规定L对评分的影响有多大。加了L和b的公式变为:
TF Score = ((k + 1) * tf) / (k * (1.0 - b + b * L) + tf)
更多细节原理推荐:
https://blog.mimacom.com/elasticsearch-scoring-algorithm-changes/
https://blog.mimacom.com/bm25-got/
5、Elasticsearch 哪些查询影响相关性评分?
布尔查询中的每个must,should和must_not元素称为查询子句。
-
文档满足must或 should条款的标准的程度有助于文档的相关性得分。分数越高,文档就越符合您的搜索条件。
-
must_not子句中的条件被视为过滤器。它会影响文档是否包含在结果中,但不会影响文档的评分方式。在must_not里还可以显式指定任意过滤器,以基于结构化数据包括或排除文档。 -
filter:必须 匹配,但它以不评分、过滤模式来进行。filter内部语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
一句话概括:filter、must_not不影响评分,其他影响评分。
6.Elasticsearch 如何自定义评分?
这里说是自定义评分,核心还是通过修改评分修改文档相关性,在最前面返回用户最期望的结果。
6.1 Index Boost 索引层面修改相关性
6.1.1 原理说明
允许在跨多个索引搜索时为每个索引配置不同的级别。
6.1.2 适用场景
索引级别调整评分。
6.1.3 实战举例:
一批数据里,有不同的标签,数据结构一致,不同的标签存储到不同的索引(A、B、C),最后要严格按照标签来分类展示的话,用什么查询比较好?
要求:先展示A类,然后B类,然后C类
PUT index_a/_doc/1
{
"subject": "subject 1"
}
PUT index_b/_doc/1
{
"subject": "subject 1"
}
PUT index_c/_doc/1
{
"subject": "subject 1"
}
GET index_*/_search
{
"indices_boost": [
{
"index_a": 1.5
},
{
"index_b": 1.2
},
{
"index_c": 1
}
],
"query": {
"term": {
"subject.keyword": {
"value": "subject 1"
}
}
}
}
6.2 boosting 修改文档相关性
boosting分为两种类型:
第一种:索引期间修改文档的相关性。
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"boost": 2
}
}
}
}
索引期间修改相关性的弊端非常明显:修改boost值的唯一方式是重建索引,reindex数据,成本太高了!
第二种:查询的时候修改文档的相关性。
本小节着重讲解:查询时候修改文档相关性。
6.2.1 原理说明
通过boosting修改文档相关性。
boost取值:0 - 1 之间的值,如:0.2,代表降低评分;
boost取值:> 1, 如:1.5,代表提升评分。
6.2.2 适用场景
自定义修改满足某个查询条件的评分。
6.2.3 实战一把
POST _search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "pingpang best",
"fields": [
"title^3",
"content"
]
}
}
],
"should": [
{
"term": {
"user": {
"value": "Kimchy",
"boost": 0.8
}
}
},
{
"match": {
"title": {
"query": "quick brown fox",
"boost": 2
}
}
}
]
}
}
}
6.3 negative_boost 降低相关性
6.3.1 原理说明
negative_boost 对 negative部分query生效,
计算评分时,boosting部分评分不修改,negative部分query 乘以 negative_boost值。
negative_boost 取值:0-1.0,举例:0.3。
6.3.2 适用场景
对某些返回结果不满意,但又不想排除掉(must_not),可以考虑boosting query的negative_boost。
6.3.3 实战一把
GET /_search
{
"query": {
"boosting" : {
"positive" : {
"term" : {
"text" : "apple"
}
},
"negative" : {
"term" : {
"text" : "pie tart fruit crumble tree"
}
},
"negative_boost" : 0.5
}
}
}
6.4 function_score 自定义评分
6.4.1 原理说明
支持用户自定义一个或多个查询或者脚本,达到精细化控制评分的目的。
6.4.2 适用场景
支持针对复杂查询的自定义评分业务场景。
6.4.3 实战一把
实战问题1:如何同时根据 销量和浏览人数进行相关度提升?
问题来源:https://elasticsearch.cn/question/4345
问题描述:针对商品,例如有
商品 销量 浏览人数
A 10 10
B 20 20
C 30 30
想要有一个提升相关度的计算,同时针对销量和浏览人数
例如oldScore*(销量+浏览人数) field_value_factor好像只能支持单个field 求大神解答?
解答,可以借助:script_score实现。
实战如下:
PUT product_test/_bulk
{"index":{"_id":1}}
{"name":"A","sales":10,"visitors":10}
{"index":{"_id":2}}
{"name":"B","sales":20,"visitors":20}
{"index":{"_id":3}}
{"name":"C","sales":30,"visitors":30}
POST product_test/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"script_score": {
"script": {
"source": "_score * (doc['sales'].value+doc['visitors'].value)"
}
}
}
}
}
实战问题2:基于文章点赞数计算评分。以下:title代表文章标题;like:代表点赞数。
期望评分标准:基于点赞数评分,且最终评分相对平滑。
核心原理:field_value_factor函数使用文档中的字段来影响得分。
DELETE news_index
POST news_index/_bulk
{"index":{"_id":1}}
{"title":"ElasticSearch原理- 神一样的存在"}
{"index":{"_id":2}}
{"title":"Elasticsearch 快速开始","like":5}
{"index":{"_id":3}}
{"title":"开源搜索与分析· Elasticsearch","like":10}
{"index":{"_id":4}}
{"title":"铭毅天下 死磕Elasticsearch", "like":1000}
GET news_index/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Elasticsearch"
}
},
"field_value_factor": {
"field": "like",
"modifier": "log1p",
"factor": 0.1,
"missing": 1
},
"boost_mode": "sum"
}
}
}
注意:
评分计算公式解读:new_score = old_score + log(1 + 0.1 * like值)
missing含义:使用 field_value_factor 时要注意,有的文档可能会缺少这个字段,加上 missing 来个这些缺失字段的文档一个缺省值
6.4.4 实战常见问题
星球提问:有没有办法让同一个索引里面对固定的查询返回的相关性评分是在固定的范围之内的?比如0-100分这样的?
这样就可以知道对某些词语或文档的搜索,在索引里面是否有满足相关性的文档了。
回答:
参数1:“modifier”: “log1p”,使得评分结果平滑。
参数2:max_boost
通过设置max_boost参数,可以将新分数限制为不超过特定限制。
max_boost的默认值为FLT_MAX。
#define FLT_MAX 3.402823466e+38F
6.5 查询后二次打分rescore_query
6.5.1 原理说明
二次评分是指重新计算查询返回结果文档中指定个数文档的得分,Elasticsearch会截取查询返回的前N个,并使用预定义的二次评分方法来重新计算他们的得分。
6.5.2 适用场景
对查询语句的结果不满意,需要重新打分的场景。
但,如果对全部有序的结果集进行重新排序的话势必开销会很大,使用rescore_query只对结果集的子集进行处理。
6.5.3 实战一把
在5.4基础上实战
GET news_index/_search
{
"query": {
"exists": {
"field": "like"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"function_score": {
"script_score": {
"script": {
"source": "doc.like.value"
}
}
}
}
}
}
}
window_size含义:
query rescorer仅对query和 post_filter阶段返回的前K个结果执行第二个查询。
每个分片上要检查的文档数量可由window_size参数控制,默认为10。
以上是关于ElasticsearchElasticsearch自定义评分的N种方法的主要内容,如果未能解决你的问题,请参考以下文章