hashMap的循环姿势你真的使用对了吗?
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hashMap的循环姿势你真的使用对了吗?相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨小胖
来源丨java金融
hashMap 应该是java程序员工作中用的比较多的一个键值对处理的数据的类型了。这种数据类型一般都会有增删查的方法,今天我们就来看看它的循环方法。hashMap 有常见的六七种遍历的方式。这么多的选择,大家平时都是使用哪一种来遍历数据列?欢迎大家在下方留言哦。说实话这么多种方式,想记也不记不住,也不想浪费时间来记这玩意,所以本人在JDK1.8以前基本上都是用Map.Entry的方式来遍历,1.8及以后就习惯性用forEach了,不过这个不能有continue或者break操作这个有时候还是挺不方便的,其他几种基本上没怎么用过,也没太研究这几种方式,哪种性能是比较好的。反正就是挑自己熟悉的方式。好了话不多说,我们还是直入今天的主题。先来看看每种遍历的方式:
在for循环中使用entries实现Map的遍历
public static void forEachEntries() {
for (Map.Entry<String, String> entry : map.entrySet()) {
String mapKey = entry.getKey();
String mapValue = entry.getValue();
}
}
在for循环中遍历key
public static void forEachKey() {
for (String key : map.keySet()) {
String mapKey = key;
String mapValue = map.get(mapKey);
}
}
在for循环中遍历value
public static void forEachValues() {
for (String key : map.values()) {
String val = key;
}
}
Iterator遍历
public static void forEachIterator() {
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
}
}
forEach jdk1.8遍历
public static void forEach() {
map.forEach((key, val) -> {
String key1 = key;
String value = val;
});
}
Stream jdk1.8遍历
map.entrySet().stream().forEach((entry) -> {
String key = entry.getKey();
String value = entry.getValue();
});
Streamparallel jdk1.8遍历
public static void forEachStreamparallel() {
map.entrySet().parallelStream().forEach((entry) -> {
String key = entry.getKey();
String value = entry.getValue();
});
}
以上就是常见的对于map的一些遍历的方式,下面我们来写个测试用例来看下这些遍历方式,哪些是效率最好的。下面测试用例是基于JMH来测试的 首先引入pom
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
关于jmh测试如可能会影响结果的一些因素这里就不详细介绍了,可以参考文末的第一个链接写的非常详细。以及测试用例为什么要这么写(都是为了消除JIT对测试代码的影响)这是参照官网的链接:编写测试代码如下:
package com.workit.autoconfigure.autoconfigure.controller;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @author:公众号:java金融
* @Date:
* @Description:微信搜一搜【java金融】回复666
*/
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class InstructionsBenchmark {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder().include(InstructionsBenchmark.class.getSimpleName()).result("result.json").resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
static final int BASE = 42;
static int add(int key,int val) {
return BASE + key +val;
}
@Param({"1", "10", "100", "1000","10000","100000"})
int size;
private static Map<Integer, Integer> map;
// 初始化方法,在全部Benchmark运行之前进行
@Setup(Level.Trial)
public void init() {
map = new HashMap<>(size);
for (int i = 0; i < size; i++) {
map.put(i, i);
}
}
/**
* 在for循环中使用entries实现Map的遍历:
*/
@Benchmark
public static void forEachEntries(Blackhole blackhole) {
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
Integer mapKey = entry.getKey();
Integer mapValue = entry.getValue();
blackhole.consume(add(mapKey,mapValue));
}
}
/**
* 在for循环中遍历key
*/
@Benchmark
public static StringBuffer forEachKey(Blackhole blackhole) {
StringBuffer stringBuffer = new StringBuffer();
for (Integer key : map.keySet()) {
// Integer mapValue = map.get(key);
blackhole.consume(add(key,key));
}
return stringBuffer;
}
/**
* 在for循环中遍历value
*/
@Benchmark
public static void forEachValues(Blackhole blackhole) {
for (Integer key : map.values()) {
blackhole.consume(add(key,key));
}
}
/**
* Iterator遍历;
*/
@Benchmark
public static void forEachIterator(Blackhole blackhole) {
Iterator<Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Entry<Integer, Integer> entry = entries.next();
Integer key = entry.getKey();
Integer value = entry.getValue();
blackhole.consume(add(key,value));
}
}
/**
* forEach jdk1.8遍历
*/
@Benchmark
public static void forEachLamada(Blackhole blackhole) {
map.forEach((key, value) -> {
blackhole.consume(add(key,value));
});
}
/**
* forEach jdk1.8遍历
*/
@Benchmark
public static void forEachStream(Blackhole blackhole) {
map.entrySet().stream().forEach((entry) -> {
Integer key = entry.getKey();
Integer value = entry.getValue();
blackhole.consume(add(key,value));
});
}
@Benchmark
public static void forEachStreamparallel(Blackhole blackhole) {
map.entrySet().parallelStream().forEach((entry) -> {
Integer key = entry.getKey();
Integer value = entry.getValue();
blackhole.consume(add(key,value));
});
}
}
运行结果如下:「注:运行环境idea 2019.3,jdk1.8,windows7 64位。」
Benchmark (size) Mode Cnt Score Error Units
InstructionsBenchmark.forEachEntries 1 avgt 5 10.021 ± 0.224 ns/op
InstructionsBenchmark.forEachEntries 10 avgt 5 71.709 ± 2.537 ns/op
InstructionsBenchmark.forEachEntries 100 avgt 5 738.873 ± 12.132 ns/op
InstructionsBenchmark.forEachEntries 1000 avgt 5 7804.431 ± 136.635 ns/op
InstructionsBenchmark.forEachEntries 10000 avgt 5 88540.345 ± 14915.682 ns/op
InstructionsBenchmark.forEachEntries 100000 avgt 5 1083347.001 ± 136865.960 ns/op
InstructionsBenchmark.forEachIterator 1 avgt 5 10.675 ± 2.532 ns/op
InstructionsBenchmark.forEachIterator 10 avgt 5 73.934 ± 4.517 ns/op
InstructionsBenchmark.forEachIterator 100 avgt 5 775.847 ± 198.806 ns/op
InstructionsBenchmark.forEachIterator 1000 avgt 5 8905.041 ± 1294.618 ns/op
InstructionsBenchmark.forEachIterator 10000 avgt 5 98686.478 ± 10944.570 ns/op
InstructionsBenchmark.forEachIterator 100000 avgt 5 1045309.216 ± 36957.608 ns/op
InstructionsBenchmark.forEachKey 1 avgt 5 18.478 ± 1.344 ns/op
InstructionsBenchmark.forEachKey 10 avgt 5 76.398 ± 12.179 ns/op
InstructionsBenchmark.forEachKey 100 avgt 5 768.507 ± 23.892 ns/op
InstructionsBenchmark.forEachKey 1000 avgt 5 11117.896 ± 1665.021 ns/op
InstructionsBenchmark.forEachKey 10000 avgt 5 84871.880 ± 12056.592 ns/op
InstructionsBenchmark.forEachKey 100000 avgt 5 1114948.566 ± 65582.709 ns/op
InstructionsBenchmark.forEachLamada 1 avgt 5 9.444 ± 0.607 ns/op
InstructionsBenchmark.forEachLamada 10 avgt 5 76.125 ± 5.640 ns/op
InstructionsBenchmark.forEachLamada 100 avgt 5 861.601 ± 98.045 ns/op
InstructionsBenchmark.forEachLamada 1000 avgt 5 7769.714 ± 1663.914 ns/op
InstructionsBenchmark.forEachLamada 10000 avgt 5 73250.238 ± 6032.161 ns/op
InstructionsBenchmark.forEachLamada 100000 avgt 5 836781.987 ± 72125.745 ns/op
InstructionsBenchmark.forEachStream 1 avgt 5 29.113 ± 3.275 ns/op
InstructionsBenchmark.forEachStream 10 avgt 5 117.951 ± 13.755 ns/op
InstructionsBenchmark.forEachStream 100 avgt 5 1064.767 ± 66.869 ns/op
InstructionsBenchmark.forEachStream 1000 avgt 5 9969.549 ± 342.483 ns/op
InstructionsBenchmark.forEachStream 10000 avgt 5 93154.061 ± 7638.122 ns/op
InstructionsBenchmark.forEachStream 100000 avgt 5 1113961.590 ± 218662.668 ns/op
InstructionsBenchmark.forEachStreamparallel 1 avgt 5 65.466 ± 5.519 ns/op
InstructionsBenchmark.forEachStreamparallel 10 avgt 5 2298.999 ± 721.455 ns/op
InstructionsBenchmark.forEachStreamparallel 100 avgt 5 8270.759 ± 1801.082 ns/op
InstructionsBenchmark.forEachStreamparallel 1000 avgt 5 16049.564 ± 1972.856 ns/op
InstructionsBenchmark.forEachStreamparallel 10000 avgt 5 69230.849 ± 12169.260 ns/op
InstructionsBenchmark.forEachStreamparallel 100000 avgt 5 638129.559 ± 14885.962 ns/op
InstructionsBenchmark.forEachValues 1 avgt 5 9.743 ± 2.770 ns/op
InstructionsBenchmark.forEachValues 10 avgt 5 70.761 ± 16.574 ns/op
InstructionsBenchmark.forEachValues 100 avgt 5 745.069 ± 329.548 ns/op
InstructionsBenchmark.forEachValues 1000 avgt 5 7772.584 ± 1702.295 ns/op
InstructionsBenchmark.forEachValues 10000 avgt 5 74063.468 ± 23752.678 ns/op
InstructionsBenchmark.forEachValues 100000 avgt 5 994057.370 ± 279310.867 ns/op
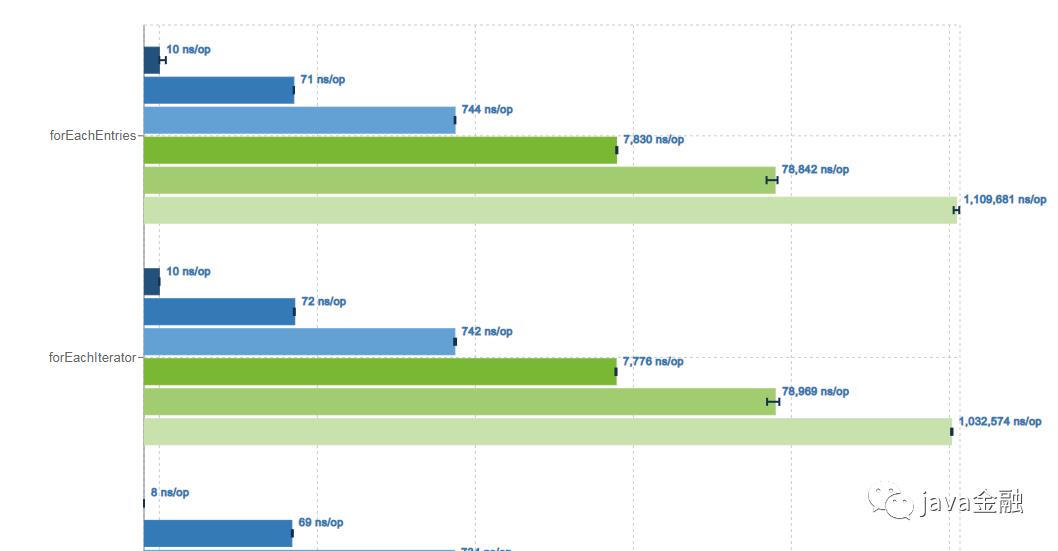
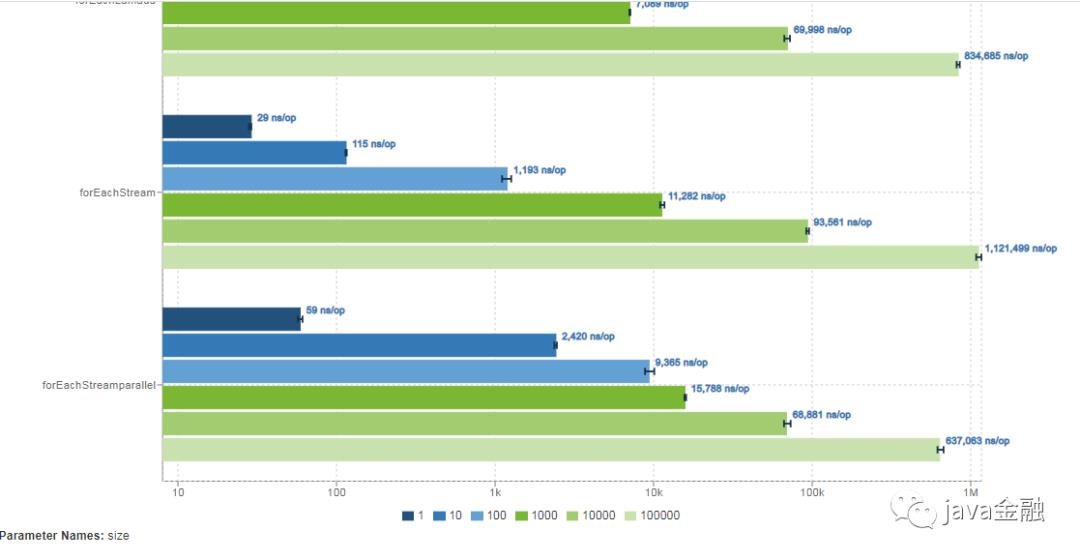
通过上述的图我们可以发现,数据量较小的时候forEachEntries和forEachIterator、以及lamada循环效率都差不多forEachStreamarallel的效率反而较低,只有当数据量达到10000以上parallelStream的优势就体现出来了。所以平时选择使用哪种循环方式的时候没必要太纠结哪一种方式,其实每种方式之间的效率还是微乎其微的。选择适合自己的就好。为什么parallelStream在数据量较小的时候效率反而不行?这个大家可以在下方留言哦。
总结
上面小实验只是在我机器上跑出来的结果,可能放到不同的机器运行结果有不一样哦,大家感兴趣的同学可以把代码贴到自己的机器上跑一跑,也许我这这个结论就不适用了。
结束
由于自己才疏学浅,难免会有纰漏,假如你发现了错误的地方,还望留言给我指出来,我会对其加以修正。
如果你觉得文章还不错,你的转发、分享、赞赏、点赞、留言就是对我最大的鼓励。
感谢您的阅读,十分欢迎并感谢您的关注。
巨人的肩膀摘苹果:
https://www.cnkirito.moe/java-jmh/
https://jmh.morethan.io/
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于hashMap的循环姿势你真的使用对了吗?的主要内容,如果未能解决你的问题,请参考以下文章
forforeachstream 哪家的效率更高,你真的用对了吗?