字节面试官:java解析xml中文乱码
Posted 爱看动漫的Java程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节面试官:java解析xml中文乱码相关的知识,希望对你有一定的参考价值。
重要
大环境对于我们能力要求越来越高,医学专家又说今年冬天新冠肺炎将“席卷重来”。
如果疫情再次爆发,势必将再次影响企业的正常运作,一波裁员浪潮你又能否抗住?
不管如何,明年金三银四又是一波跳槽时机,也该趁着这个时间开始提升一下自己的技术了。
不多说,十余位互联网一线大厂的大牛联合手写的Java高级知识,直接手撕面试官。

ES 集群架构演进之路
1、初始阶段
订单中心ES初始阶段如一张白纸,架设方案基本没有,很多配置都是保持集群默认配置。整个集群部署在集团的弹性云上,ES集群的节点以及机器部署都比较混乱。同时按照集群维度来看,一个ES集群会有单点问题,显然对于订单中心业务来说也是不被允许的。
2、集群隔离阶段
和很多业务一样,ES集群采用的混布的方式。但由于订单中心ES存储的是线上订单数据,偶尔会发生混布集群抢占系统大量资源,导致整个订单中心ES服务异常。
显然任何影响到订单查询稳定性的情况都是无法容忍的,所以针对于这个情况,先是对订单中心ES所在的弹性云,迁出那些系统资源抢占很高的集群节点,ES集群状况稍有好转。但随着集群数据不断增加,弹性云配置已经不太能满足ES集群,且为了完全的物理隔离,最终干脆将订单中心ES集群部署到高配置的物理机上,ES集群性能又得到提升。
3、节点副本调优阶段
ES的性能跟硬件资源有很大关系,当ES集群单独部署到物理机器上时,集群内部的节点并不是独占整台物理机资源,在集群运行的时候同一物理机上的节点仍会出现资源抢占的问题。所以在这种情况下,为了让ES单个节点能够使用最大程度的机器资源,采用每个ES节点部署在单独一台物理机上方式。
但紧接着,问题又来了,如果单个节点出现瓶颈了呢?我们应该怎么再优化呢?
ES查询的原理,当请求打到某号分片的时候,如果没有指定分片类型(Preference参数)查询,请求会负载到对应分片号的各个节点上。而集群默认副本配置是一主一副,针对此情况,我们想到了扩容副本的方式,由默认的一主一副变为一主二副,同时增加相应物理机。
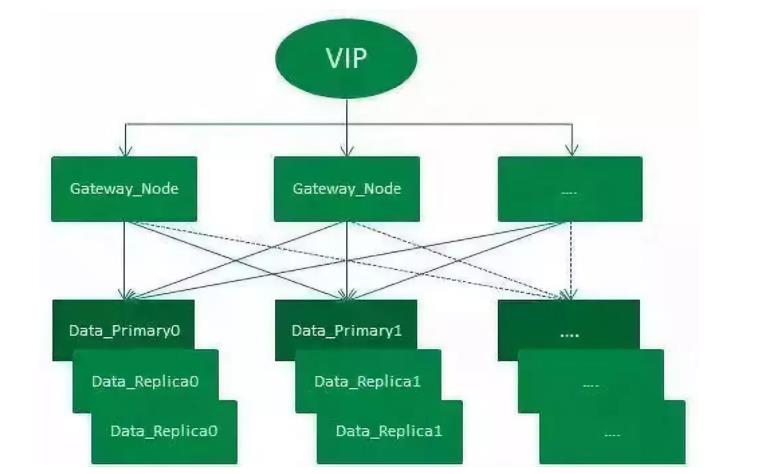
订单中心ES集群架设示意图
如图,整个架设方式通过VIP来负载均衡外部请求:
整个集群有一套主分片,二套副分片(一主二副),从网关节点转发过来的请求,会在打到数据节点之前通过轮询的方式进行均衡。集群增加一套副本并扩容机器的方式,增加了集群吞吐量,从而提升了整个集群查询性能。
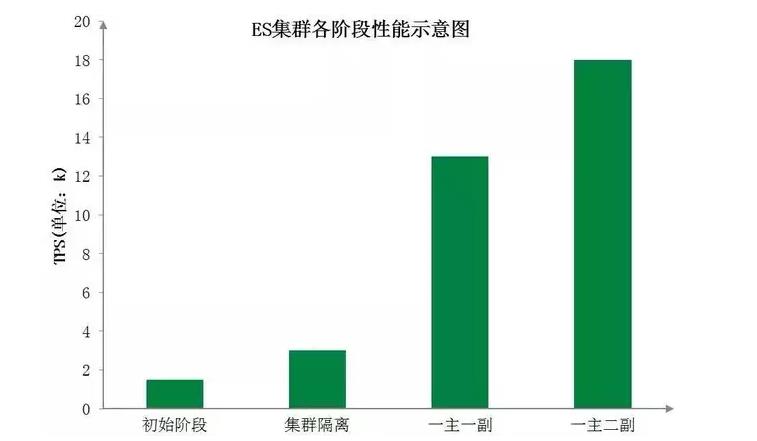
下图为订单中心ES集群各阶段性能示意图,直观地展示了各阶段优化后ES集群性能的显著提升:
当然分片数量和分片副本数量并不是越多越好,在此阶段,我们对选择适当的分片数量做了进一步探索。分片数可以理解为mysql中的分库分表,而当前订单中心ES查询主要分为两类:单ID查询以及分页查询。
分片数越大,集群横向扩容规模也更大,根据分片路由的单ID查询吞吐量也能大大提升,但聚合的分页查询性能则将降低;分片数越小,集群横向扩容规模也更小,单ID的查询性能也会下降,但分页查询的性能将会提升。
所以如何均衡分片数量和现有查询业务,我们做了很多次调整压测,最终选择了集群性能较好的分片数。
4、主从集群调整阶段
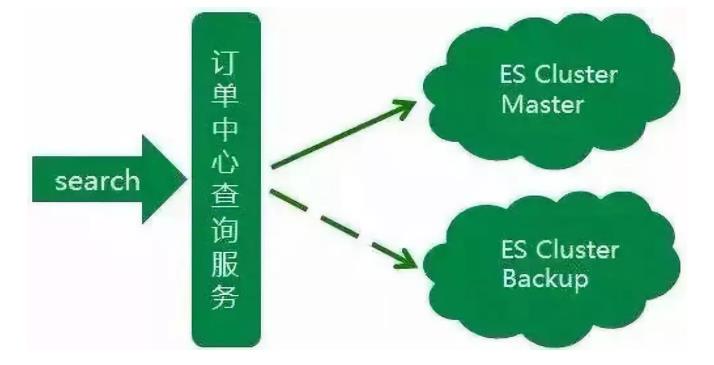
到此,订单中心的ES集群已经初具规模,但由于订单中心业务时效性要求高,对ES查询稳定性要求也高,如果集群中有节点发生异常,查询服务会受到影响,从而影响到整个订单生产流程。很明显这种异常情况是致命的,所以为了应对这种情况,我们初步设想是增加一个备用集群,当主集群发生异常时,可以实时的将查询流量降级到备用集群。
那备用集群应该怎么来搭?主备之间数据如何同步?备用集群应该存储什么样的数据?
考虑到ES集群暂时没有很好的主备方案,同时为了更好地控制ES数据写入,我们采用业务双写的方式来搭设主备集群。每次业务操作需要写入ES数据时,同步写入主集群数据,然后异步写入备集群数据。同时由于大部分ES查询的流量都来源于近几天的订单,且订单中心数据库数据已有一套归档机制,将指定天数之前已经关闭的订单转移到历史订单库。
所以归档机制中增加删除备集群文档的逻辑,让新搭建的备集群存储的订单数据与订单中心线上数据库中的数据量保持一致。同时使用ZK在查询服务中做了流量控制开关,保证查询流量能够实时降级到备集群。在此,订单中心主从集群完成,ES查询服务稳定性大大提升。
5、现今:实时互备双集群阶段
期间由于主集群ES版本是较低的1.7,而现今ES稳定版本都已经迭代到6.x,新版本的ES不仅性能方面优化很大,更提供了一些新的好用的功能,所以我们对主集群进行了一次版本升级,直接从原来的1.7升级到6.x版本。
集群升级的过程繁琐而漫长,不但需要保证线上业务无任何影响,平滑无感知升级,同时由于ES集群暂不支持从1.7到6.x跨越多个版本的数据迁移,所以需要通过重建索引的方式来升级主集群,具体升级过程就不在此赘述了。
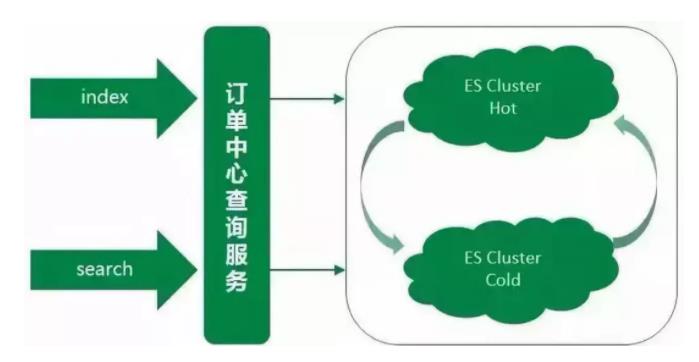
主集群升级的时候必不可免地会发生不可用的情况,但对于订单中心ES查询服务,这种情况是不允许的。所以在升级的阶段中,备集群暂时顶上充当主集群,来支撑所有的线上ES查询,保证升级过程不影响正常线上服务。同时针对于线上业务,我们对两个集群做了重新的规划定义,承担的线上查询流量也做了重新的划分。
备集群存储的是线上近几天的热点数据,数据规模远小于主集群,大约是主集群文档数的十分之一。集群数据量小,在相同的集群部署规模下,备集群的性能要优于主集群。
然而在线上真实场景中,线上大部分查询流量也来源于热点数据,所以用备集群来承载这些热点数据的查询,而备集群也慢慢演变成一个热数据集群。之前的主集群存储的是全量数据,用该集群来支撑剩余较小部分的查询流量,这部分查询主要是需要搜索全量订单的特殊场景查询以及订单中心系统内部查询等,而主集群也慢慢演变成一个冷数据集群。
同时备集群增加一键降级到主集群的功能,两个集群地位同等重要,但都可以各自降级到另一个集群。双写策略也优化为:假设有AB集群,正常同步方式写主(A集群)异步方式写备(B集群)。A集群发生异常时,同步写B集群(主),异步写A集群(备)。
ES 订单数据的同步方案
MySQL数据同步到ES中,大致总结可以分为两种方案:
- 方案1:监听MySQL的Binlog,分析Binlog将数据同步到ES集群中。
- 方案2:直接通过ES API将数据写入到ES集群中。
考虑到订单系统ES服务的业务特殊性,对于订单数据的实时性较高,显然监听Binlog的方式相当于异步同步,有可能会产生较大的延时性。且方案1实质上跟方案2类似,但又引入了新的系统,维护成本也增高。所以订单中心ES采用了直接通过ES API写入订单数据的方式,该方式简洁灵活,能够很好的满足订单中心数据同步到ES的需求。
由于ES订单数据的同步采用的是在业务中写入的方式,当新建或更新文档发生异常时,如果重试势必会影响业务正常操作的响应时间。
所以每次业务操作只更新一次ES,如果发生错误或者异常,在数据库中插入一条补救任务,有Worker任务会实时地扫这些数据,以数据库订单数据为基准来再次更新ES数据。通过此种补偿机制,来保证ES数据与数据库订单数据的最终一致性。
遇到的一些坑
1、实时性要求高的查询走DB
推荐阅读:ES 几十亿数据检索 3 秒返回。
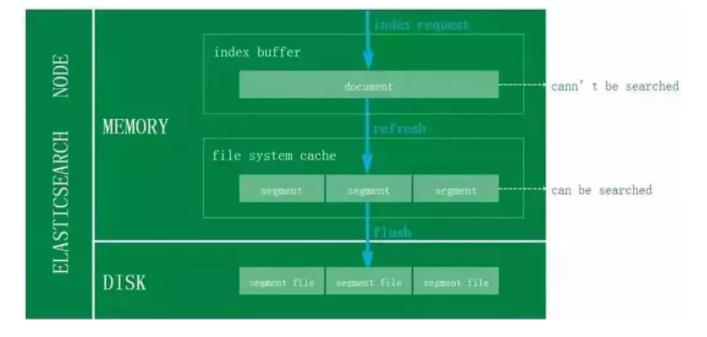
对于ES写入机制的有了解的同学可能会知道,新增的文档会被收集到Indexing Buffer,然后写入到文件系统缓存中,到了文件系统缓存中就可以像其他的文件一样被索引到。
然而默认情况文档从Indexing Buffer到文件系统缓存(即Refresh操作)是每秒分片自动刷新,所以这就是我们说ES是近实时搜索而非实时的原因:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
当前订单系统ES采用的是默认Refresh配置,故对于那些订单数据实时性比较高的业务,直接走数据库查询,保证数据的准确性。
2、避免深分页查询
ES集群的分页查询支持from和size参数,查询的时候,每个分片必须构造一个长度为from+size的优先队列,然后回传到网关节点,网关节点再对这些优先队列进行排序找到正确的size个文档。
假设在一个有6个主分片的索引中,from为10000,size为10,每个分片必须产生10010个结果,在网关节点中汇聚合并60060个结果,最终找到符合要求的10个文档。
由此可见,当from足够大的时候,就算不发生OOM,也会影响到CPU和带宽等,从而影响到整个集群的性能。所以应该避免深分页查询,尽量不去使用。
3、FieldData与Doc Values
FieldData:
线上查询出现偶尔超时的情况,通过调试查询语句,定位到是跟排序有关系。排序在es1.x版本使用的是FieldData结构,FieldData占用的是JVM Heap内存,JVM内存是有限,对于FieldData Cache会设定一个阈值。
如果空间不足时,使用最久未使用(LRU)算法移除FieldData,同时加载新的FieldData Cache,加载的过程需要消耗系统资源,且耗时很大。所以导致这个查询的响应时间暴涨,甚至影响整个集群的性能。针对这种问题,解决方式是采用Doc Values。
Doc Values:
Doc Values是一种列式的数据存储结构,跟FieldData很类似,但其存储位置是在Lucene文件中,即不会占用JVM Heap。随着ES版本的迭代,Doc Values比FieldData更加稳定,Doc Values在2.x起为默认设置。
完结
Redis基于内存,常用作于缓存的一种技术,并且Redis存储的方式是以key-value的形式。Redis是如今互联网技术架构中,使用最广泛的缓存,在工作中常常会使用到。Redis也是中高级后端工程师技术面试中,面试官最喜欢问的问题之一,因此作为Java开发者,Redis是我们必须要掌握的。
Redis 是 NoSQL 数据库领域的佼佼者,如果你需要了解 Redis 是如何实现高并发、海量数据存储的,那么这份腾讯专家手敲《Redis源码日志笔记》将会是你的最佳选择。
。
Redis 是 NoSQL 数据库领域的佼佼者,如果你需要了解 Redis 是如何实现高并发、海量数据存储的,那么这份腾讯专家手敲《Redis源码日志笔记》将会是你的最佳选择。
[外链图片转存中…(img-Wh4b6WtY-1620878751439)]
感兴趣的朋友可以通过点赞+戳这里的方式免费获取腾讯专家手写Redis源码日志笔记pdf版本!
以上是关于字节面试官:java解析xml中文乱码的主要内容,如果未能解决你的问题,请参考以下文章