机器学习笔记一 绪论
Posted 猛男Banana君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记一 绪论相关的知识,希望对你有一定的参考价值。
一、统计学习
简单理解:统计学习就是机器学习
研究对象:数据
目的:对数据预测与分析(尤其是新数据)
方法:基于数据构建概率模型
分类:监督学习、无监督学习、半监督学习、强化学习
二、统计学习分类
基本分类
1)监督学习(需要大量数据)
定义:从标注数据中学习预测模型的机器学习问题。
输入空间:输入所有可能取值的集合。
输出空间:输出所有可能取值的集合。
(上述两者可以是有限元素的集合,也可以是整个欧氏空间)
监督学习的目的就是学习一个输入到输出的映射,用一个模型表示。若该模型属于由输入空间到输出空间的映射的集合,该集合就是假设空间。
独立同分布→相互独立的

2)无监督学习
定义:从无标注数据中学习预测模型的机器学习问题。
3)强化学习
定义:智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。
4)半监督学习(不需要很多数据)
定义:利用标注数据和未标注数据学习预测模型的机器学习问题。
5)主动学习
定义:机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。
按模型分类
1)概率&非概率模型
概率模型→条件概率 P(y|x)
非概率模型→函数形式 y=f(x)
基本概率公式:

2)线性&非线性模型
3)参数化&非参数化模型
按算法分类
分为在线学习和批量学习。
按技巧分类
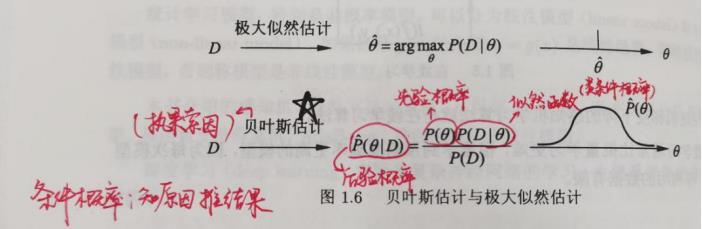
1)贝叶斯学习

P(B|A)也是似然函数。
先验概率:是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的“因”出现的概率。
贝叶斯公式很重要,它可以看作完全概率公式的变形。
条件概率:知道原因推结果
贝叶斯公式:执果索因
似然函数:

贝叶斯估计关系图:
2)核方法
定义:使用核函数表示和学习非线性模型的一种机器学习方法,适用于监督学习&无监督学习。
外积→点乘(数量积),得到结果是一个数
内积→叉乘,得到结果是一个向量
三、统计学习方法三要素
精髓:方法=模型+策略+算法!
模型
模型的假设空间包含所有可能的条件概率或决策函数。
策略
监督学习两个基本策略:经验风险最小化&结构风险最小化。
当样本容量很大时,经验风险最小化有优势。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化 <=> 极大似然估计。
当样本容量很小时,经验风险最小化就劣势了,会过拟合。
结构风险最小化就是为了防止过拟合而提出的 <=> 正则化。
指示函数:指示函数是定义在某集合X上的函数,表示其中有哪些元素属于某一子集A。

符号函数:数学上的Sgn 函数返回一个整型变量,指出参数的正负号。语法Sgn(number), number 参数是任何有效的数值表达式。返回值如果 number 大于0,则Sgn 返回1;等于0,返回0;小于0,则返回-1。number 参数的符号决定了Sgn 函数的返回值。
四、模型评估&选择
训练误差&测试误差
数据集=训练集+测试集+验证集
训练误差是模型关于训练数据集的平均损失。
测试误差是模型关于测试数据集的平均损失。
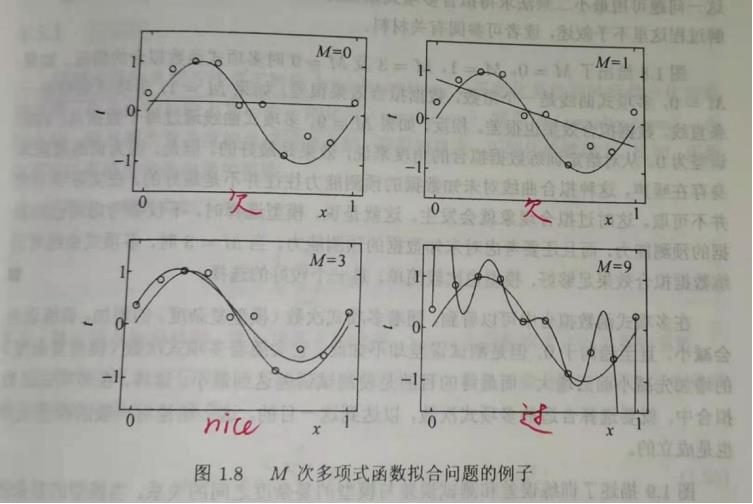
过拟合&模型选择
过拟合&欠拟合
点击这里查看解释~
图示:
五、正则化
正则化是模型选择的典型方法,它是结构风险最小化的实现,在经验风险上加一个正则化项或罚项即可。
简单来说,正则化是把一个大的区间压缩到一个小的范围内。
六、泛化能力
定义:指由学习方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。
一般通过测试误差评价某个学习方法的泛化能力。
百度解释的泛化能力是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
通俗的解释:

七、生成模型&判别模型
监督学习方法又分为:生成方法&判别方法。
学习得到的模型又分别称为生成模型&判别模型。
八、监督学习的应用
三大应用:分类、标注、回归
监督学习从数据中学习一个分类模型或分类决策函数,称为分类器。
而分类器对新的输入进行输出的预测,称为分类。可能的输出称为类别。
对二分类问题常用的评价指标是精确率&召回率。
标注常用的统计学习方法:隐马尔可夫模型、条件随机场。
回归学习最常用的损失函数是平方损失函数,此情况下可用最小二乘法求解。
连乘图解:
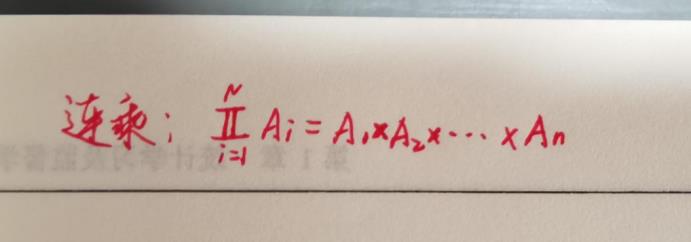
以上是关于机器学习笔记一 绪论的主要内容,如果未能解决你的问题,请参考以下文章