大数据之Hive入门操作
Posted Mr.zhou_Zxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Hive入门操作相关的知识,希望对你有一定的参考价值。
Hive入门操作
1 认识Hive
1.1 hive是什么
hive是一个数据仓库工具。基于hadoop的,可以通过类sql的语句进行数据读、写、分析、管理。
特点:
- 支持类SQL轻松访问数据的工具
- 它的数据直接存储在HDFS中,或者HBase。
- 它在做数据分析的时候,它自己本身也没有分析的能力,它是利用底层的分析引擎:Mapreduce(default)、Tez、Spark。
- 使用HQL(类SQL)语言进行查询
- 可以实现亚秒级的查询
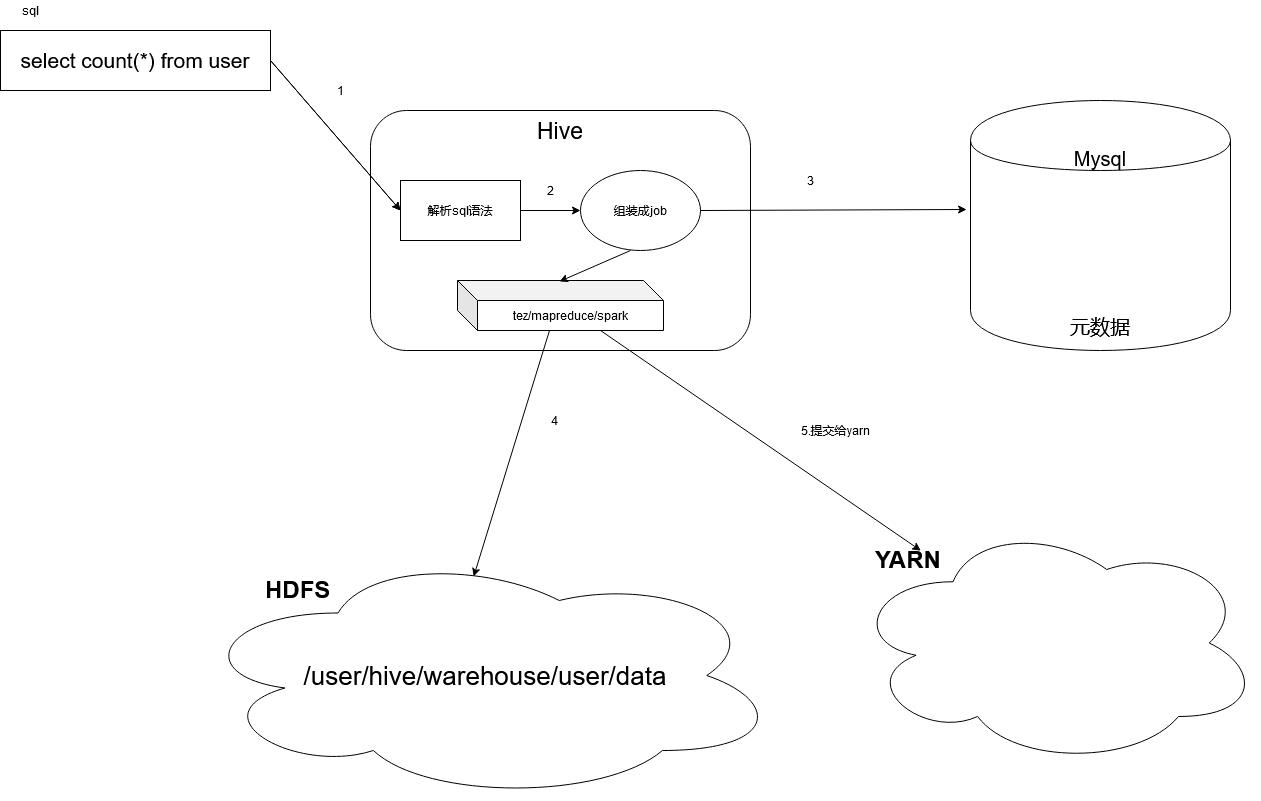
1.2 Hive底层是如何运行的
1.3 Hive的架构
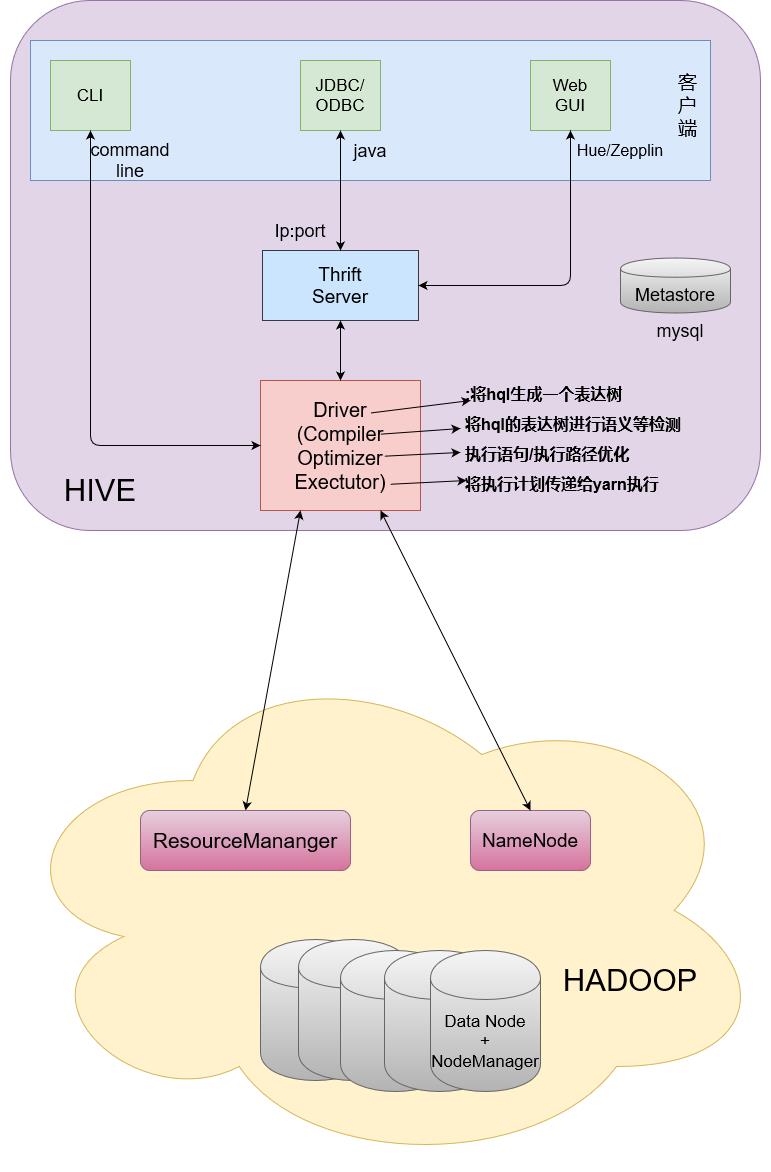
hive默认端口是10000
元数据库:默认Derby。我们后面要切换为mysql
1.4 快速入门(Hadoop、Jdk、mysql)
1.4.1 安装步骤
##1. 解压apache-hive-1.2.1-bin.tar.gz
[root@hadoop software]# tar -zxvf apache-hive-1.2.1-bin.tar.gz
##2. 改名
[root@hadoop apps]# mv apache-hive-1.2.1-bin/ hive-1.2.1
##3. 配置环境变量
[root@hadoop hive-1.2.1]# vi /etc/profile
## 自定义环境变量
export JAVA_HOME=/opt/apps/jdk1.8.0_45
export HADOOP_HOME=/opt/apps/hadoop-2.8.1
export HIVE_HOME=/opt/apps/hive-1.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib
##4. 启动命令行
[root@hadoop bin]# start-dfs.sh
[root@hadoop bin]# start-yarn.sh
[root@hadoop bin]# hive
hive>show databases;
OK
default
hive> create table t_user(
> id int,
> name string);
hive> show tables;
OK
t_user
hive> insert into t_user values(1, 'lixi'); ## 这句话会执行mr
hive> select * from t_user;
hive> select count(*) from t_user; ## 这句话会执行mr
我们默认使用的存储元数据的是hive自带的derby数据库。这个数据库最大的缺点是只支持单session
1.4.2 hive的远程模式——元数据在其他的服务器
[root@hadoop hive-1.2.1]# cd conf
[root@hadoop conf]#vim hive-site.xml
- hive-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3307/hive?createDataBaseIfNotExists=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
- 上传一个mysql jdbc的驱动jar到hive的lib
mysql-connector-java-5.1.47-bin.jar
上传之后
- mysql的服务启动着
- mysql远程授权
mysql> grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; mysql> flush privileges; # hadoop是当前虚拟机的主机名 mysql> grant all privileges on *.* to 'root'@'hadoop' identified by '123456' with grant option; mysql> flush privileges;
HDFS/YARN开启
[root@hadoop conf]# start-dfs.sh [root@hadoop conf]# start-yarn.sh环境变量
java+hadoop+hive环境变量配置成功新建数据库(可视化工具中操作)
[root@hadoop conf]# hive
1.4.3 thrift server
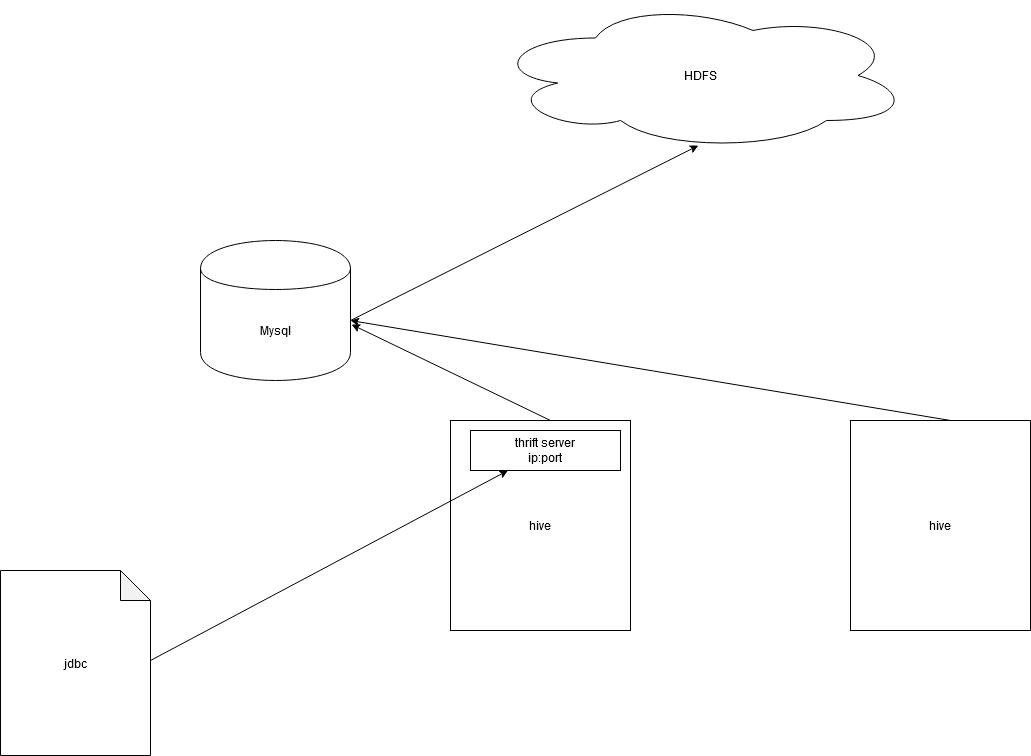
##1. 开启hiveserver2
[root@hadoop bin]# hive --service hiveserver2 &
##2. beeline客户端链接
[root@hadoop bin]# beeline
beeline> !connect jdbc:hive2://hadoop:10000
Enter username for jdbc:hive2://hadoop:10000: root
Enter password for jdbc:hive2://hadoop:10000: ******
0: jdbc:hive2://hadoop:10000> show databases;
OK
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
1 row selected (0.948 seconds)
0: jdbc:hive2://hadoop:10000> show tables;
OK
+-----------+--+
| tab_name |
+-----------+--+
| t_user |
+-----------+--+
1 row selected (0.037 seconds)
0: jdbc:hive2://hadoop:10000> select * from t_user;
OK
+------------+--------------+--+
| t_user.id | t_user.name |
+------------+--------------+--+
| 1 | lixi |
+------------+--------------+--+
1 row selected (0.347 seconds)
0: jdbc:hive2://hadoop:10000>
以上是关于大数据之Hive入门操作的主要内容,如果未能解决你的问题,请参考以下文章