VQA文献阅读VQS:将语义分割与视觉问答结合起来(ICCV2017)
Posted Leokadia Rothschild
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VQA文献阅读VQS:将语义分割与视觉问答结合起来(ICCV2017)相关的知识,希望对你有一定的参考价值。
VQS: Linking Segmentations to Questions and Answers for Supervised Attention in VQA and Question-Focused Semantic Segmentation
文章目录
- VQS: Linking Segmentations to Questions and Answers for Supervised Attention in VQA and Question-Focused Semantic Segmentation
Abstract
丰富而密集的人为标记数据集是近期视觉语言理解发展的主要因素。许多看似遥远的注释(例如,语义分割和视觉问答(VQA)),其本质上是相互联系的,因为它们揭示了人类对相同视觉场景的理解的不同层次和视角-甚至是同一组图像(例如,COCO的图像)。COCO的流行与那些注释和任务有关。明确地将它们联系起来可能会使个人任务以及视觉语言的统一建模都受益匪浅。
我们提出了将COCO提供的实例分割与VQA数据集中的问题和答案(QA)相关联的初步工作,并将收集的链接命名为视觉问题和分割答案(VQS)。他们在以前单独的任务之间转移人员监督,为现有问题提供更有效的手段,并为新的研究问题和模型打开大门。我们在本文中研究了VQS数据的两个应用:监督VQA的注意力和一个新的以问题为中心的语义分割任务。对于前者,我们通过使用分割-QA链接作为显式监督学习的一些注意特征来简单地增加多层感知器,从而获得关于VQA实际多选任务的最新结果。为了对后者进行观察,我们研究了两种可能的方法,并将它们与假设在测试阶段给出了实例分割的oracle方法进行比较。
1. Introduction
近年来,将视觉理解与自然语言联系起来受到了广泛的关注。我们已经目睹了图像字幕的复兴[41,28,18,6,39,4,46,12,32,10],这通常是通过用深度神经网络对视觉和文本内容进行联合建模来解决的。然而,图像字幕往往是多样的和主观的——很难评估由不同算法生成的字幕的质量[7,40,1],并且往往会错过微妙的细节——在训练中,模型可能会导致捕捉场景级的要点,而不是细粒度的实体。鉴于图像字幕的前提和缺点,提出了并行的视觉问题回答(VQA) [3,50,35,13]和视觉基础[34,15,36,27,16,42,49],以适应对视觉实体(例如,场景,对象,活动,属性,上下文,关系等)的自动评估和多级聚焦。).丰富而密集的人类注释数据集可以说是视觉语言理解这一系列令人兴奋的工作的主要“推动者”之一。COCO [24]在其中尤为引人注目。它主要包含经典标签(例如,分割、对象类别和实例、关键点等)。)和图像标题。许多研究小组随后为各种任务收集了可可图像的附加标签。Agrawal等人众包了关于COCO图像和抽象场景子集的问答(QaS)[3]。朱等。与图像中的边界框相关联[50]。Mao等人[27]和Y u等人[49]让用户给出引用表达式,每个表达式在图像中指出一个唯一的对象。视觉基因组数据集[21]也在图像方面与可可相交,并提供密集的人类注释,特别是场景图。
这些看似遥远的注释在某种意义上是内在联系的,它们揭示了人类对相同可可图像理解的不同视角。COCO的流行可能与这些注释——甚至任务——密切相关。正如我们所设想的,明确地将它们联系起来,可以极大地有利于个体任务和统一的视觉语言理解,以及相应的方法和模型。 我们在本文中的贡献之一是启动这方面的初步工作。特别是,我们着重于将COCO[24]提供的分割与VQA数据集[3]中的质量保证联系起来。显示图像和关于图像的问答配对,我们要求参与者选择图像的分段,以便直观地回答问题。

图1展示了一些收集的“可视化答案”。对于“狗旁边是什么?”,输出应该是人的分割掩码。对于“几点了?”,时钟应该分段输出。另一个有趣的例子是,汽车是回答“这条街是空的吗?”,为简单文本回答“否”提供了必要的视觉证据。请注意,虽然在一个问题中可以提到许多视觉实体,但我们只要求参与者选择视觉上回答问题的目标分段。这简化了注释任务,并导致参与者之间更高的一致性。第2节详细介绍了注释收集过程和统计数据#
Two related datasets
达斯等人为VQA任务收集了一些人类注意力地图[5]。他们模糊图像,然后要求用户抓挠图像,以寻找有助于回答问题的视觉线索。得到的注意力图往往很小,揭示的是有意义的部分,而不是完整的物体。对象部分也与背景区域以及彼此混合。因此,与我们在分割和质量保证之间建立的联系相比,人类注意力地图对基于注意力的VQA方法的监督可能不太准确。我们的实验验证了这个假设(参见第3节)。虽然在Visual7W [50]中为质量保证体系中的对象提及提供了边界框,但除了“指向”类型的问题之外,它们并不用于直接回答问题。相比之下,我们以分段的形式为更多的问题类型提供直接的可视化答案。
1.1. Applications of the segmentation-QA links
我们将VQA数据集[3]中COCO分段[24]和质量保证对之间收集的链接称为视觉问题和分段答案(VQS)。这种联系在先前分离的任务之间转移了人的监督,即语义分割和VQA。它们使我们能够以比以前更有效的杠杆作用解决现有的问题,也为视觉语言理解的新研究问题和模型打开了大门。本文研究了我们的VQS数据集的两个应用:VQA的监督注意和一个新的以问题为中心的语义分割任务(QFSS)。对于前者,我们通过简单地用注意力特征扩充[17]的多层感知器(MLP)来获得关于VQA实多重选择任务的最新结果。
1.1.1 Supervised attention for VQA
VQA旨在以短文形式回答关于图像的自然语言问题。注意力方案通常通过关注特定的图像区域[47,45,44,25,23]或建模对象关系[2,26]而对VQA有用。然而,由于缺乏明确的注意力注释,现有方法选择潜在变量并使用间接线索(如文本答案)进行推理。因此,机器生成的注意力图与人类注意力图的相关性很差[5]。这并不奇怪,因为由于缺乏明确的训练信号,潜在变量很难匹配语义解释;类似的观察也存在于其他研究中,例如,目标检测[8],视频识别[11]和文本处理[48]。这些现象强调了在视觉和文本答案之间建立明确联系的必要性,这在VQS的作品中得到了体现。我们表明,通过使用所收集的分割问答链接来参与不同图像区域的监督学习,我们可以将简单的MLP模型[17]提升到在VQA真实多项选择任务上非常引人注目的性能。
1.1.2 Question-focused semantic segmentation (QFSS)
以问题为中心的语义分割(QFSS)
除了为更好地解决VQA问题而受到监督的关注之外,VQS还使我们能够探索一种新颖的以问题为中心的语义分割(QFSS)任务。因为VQA只需要文本答案,所以对于学习代理来说存在潜在的捷径,例如,生成正确的答案而不需要精确地推理不同视觉实体的位置和关系。虽然视觉基础(VG)通过在目标视觉实体上放置边界框[34,36,27,16]或分割[15]来避免警告,但是现有VG作品中文本表达的范围通常限于图像中存在的视觉实体。为了将VQA和VG的优点结合在一起,我们提出了QFSS任务,其目标是产生像素级分割,以便直观地回答关于图像的问题。它有效地借用了VQA的通用问题,同时在像素分割作为期望的输出方面类似于VG的设计。
给定一幅图像和一个关于该图像的问题,我们提出了一种掩码聚合方法来生成一个分割掩码作为视觉答案。由于QFSS是一个新的任务,从长远来看,我们不仅将建议的方法与竞争基线进行比较,而且还通过假设所有实例分段在测试阶段都作为预言给出来研究一种上限方法。
胡等人的著作[15]与最为相关。他们学习以图像分割的形式来表达文本。与本书中使用的问题不同,本书灵活地结合了常识和知识库,而[15]中文本短语的表达范围通常仅限于相关图像中的视觉实体。本文的其余部分组织如下。
第2节详细介绍了我们的VQS数据的收集过程和分析。在第3节中,我们展示了如何使用收集的分割-问答链接来学习监督注意特征和增强现有的VQA方法。在3.2节中,我们研究了一些潜在的框架来解决新的以问题为中心的语义分割任务。第四部分总结全文。
2. Linking image segmentations to text QAs 将图像分割链接到文本质量评估
在本节中,我们详细描述了如何收集语义图像分割和文本问答之间的链接。我们的工作建立在COCO[24]中的图像和实例分割遮罩以及VQA数据集[3]中的质量保证基础上。COCO图像主要是关于日常场景,包含自然环境中的常见对象,适应不同视觉实体之间的复杂交互和关系。为了避免分割和质量保证对之间的琐碎联系,我们在这项工作中只保留包含至少三个实例分割的图像。VQA [3]中的问题多种多样,涵盖了图像的各个部分、不同层次的语义解释以及常识和知识库。接下来,我们详细说明注释说明,并提供一些关于收集的数据集的分析。
2.1.Annotation instructions 注释说明
我们向注释者显示一个图像,它在COCO数据集中的实例分割,以及一个关于来自VQA数据集的图像的问答配对。除了问题之外,还会给出文本答案,以方便参与者选择正确的分段作为视觉答案。以下是我们给注释者的说明(参见图形用户界面的补充材料):
- 请在图像中选择正确的分割来回答问题。请注意,文本答案显示在问题之后。
- 关于目标实体的问题可能会使用其他实体来帮助引用目标。只选择目标实体,不选择其他实体(例如,“女人旁边的长凳上有什么?”在图2(g)中)。
- 问题可能与某项活动有关。选择活动中涉及的所有视觉实体。以图2(j)为例,选择人和摩托车来回答“这个人在做什么?”。
- 有时,除了分割遮罩覆盖的图像区域,您可能还需要其他区域来回答问题。要包含它们,请在区域上绘制紧密的边界框。
- 对于“多少”类型的问题,所选部分的数量(加上边界框)必须与答案相匹配。如果答案大于3,在问题中被询问的实体周围放置一个边界框是很好的。
- 如果您认为问题必须通过完整图像来回答,请勾选问题下方的黑色按钮。
- 如果您觉得问题不明确,或者您不确定选择哪个部分/地区来回答问题请勾选问题下方的灰色按钮。
偶尔,视觉回答应该只是COCO给出的实例片段的一部分。例如,麦当劳的标志回答“能看到什么快餐店?”在图2(o)中,但是在COCO中没有相应的徽标分割。再比如戒指上回答“女方戴戒指了吗?”(参见图2 ( c ) )。对于这些情况,我们要求参与者在他们周围画出紧密的边界框。如果我们将它们分割出来,QFSS的学习代理可能永远无法为它们产生正确的分割,除非我们在将来包含更多的训练图像,因为这些区域(例如,麦当劳标志、环)是非常细粒度的视觉实体,在我们的数据收集过程中只出现几次。
Quality control 质量控制
我们在开始的时候尝试了AMTurk来收集注释。虽然注释者之间在关于对象和人的问题上的一致程度很高,但是对于涉及活动的问题有许多不一致的注释(例如,“玩什么运动?”).此外,AMTurk的工作人员倾向于经常勾选黑色按钮,表示完整的图像是视觉答案,灰色按钮,表示问题是模糊的。为了获得更高质量的注释,我们邀请了10名本科生和研究生志愿者,并亲自对他们进行了培训(我们在补充材料中包括了一些用于培训的幻灯片)。为了进一步控制注释质量,每个注释者被要求完成100幅图像(大约300个问答对)的作业,然后我们再次与他们会面,一起查看他们的注释所有的志愿者都被要求参与讨论,并共同决定每个问题的预期注释。作为对高质量工作的奖励,我们还逐步将小时工资从12美元/小时提高到14美元/小时。

2.2. Tasks addressed by the participants
由于阿格沃尔等人收集了丰富的问题集[3]和COCO[24]中复杂的视觉场景,参与者必须解析问题,理解视觉场景和上下文,推断视觉实体之间的交互,然后拾取回答问题的分段。我们发现许多视觉任务可能在这个过程中发挥作用。图2显示了一些典型的例子,以方便下面的讨论。
Object detection 物体探测
许多问题直接询问图像中一些对象的属性。在图2(b)中,参与者应该在“咖啡杯是什么颜色?”这个问题的混乱场景中识别杯子。
Semantic segmentation 语义分割
对于某些问题,答案的视觉证据最好用语义分段来表示。以图2(j)和(k)为例。简单地检测骑车人和/或自行车不足以表达他们的空间相互作用。
Spatial relationship reasoning 空间关系推理
类似“女人旁边的长椅上是什么?”(图2(g))通过包括长凳、女人和答案包在内的物体之间的空间关系向参与者提出了挑战。图2(i)是这个领域的另一个例子。
Fine-grained activity recognition 细粒度的活动识别
当问题是关于一项活动时(例如,“正在进行什么运动?”在图2(1)中,我们要求参与者标记所有涉及的视觉实体(例如,人、网球拍和网球)。换句话说,他们应该发现活动的细节。
Commonsense reasoning 常识推理
常识知识可以帮助参与者显著减少对问题答案的搜索空间,例如,回答“几点了?”在图1中,用麦当劳的标志来回答“能看到什么快餐店?”如图2(o)所示。
2.3. Data statistics 数据统计
在收集注释之后,我们移除问题-图像对,对于这些问题-图像对,用户分别选择黑色按钮(完整图像)或灰色按钮(未知)来避免琐碎和模糊的分割-问答链接。总的来说,我们保留了37,868幅图像、96,508个问题、108,537个实例分割和43,725个边界框。在下文中,我们不区分分割和边界框,以便于呈现,也是为了边界框紧密、小,并且比分割少得多。
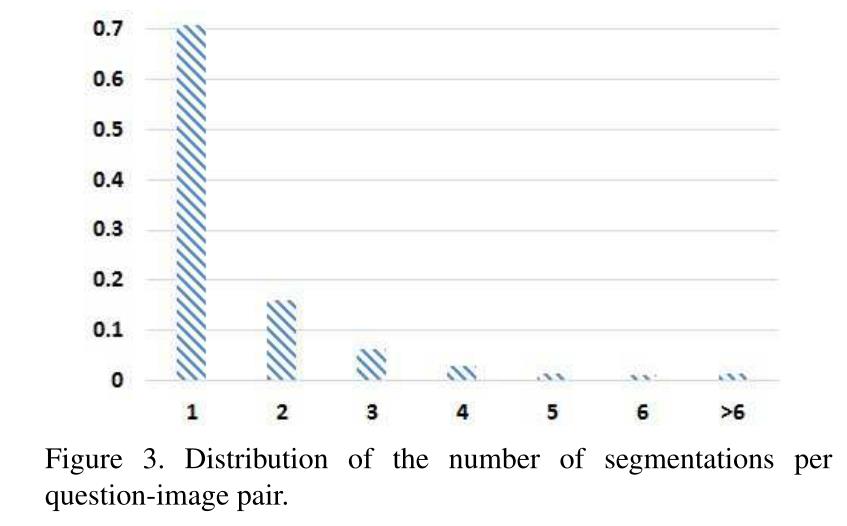
图3统计了在回答一个问题时,每个图像所选择的实例分割的可能数量的分布。超过70%的问题由一个细分回答。平均而言,每个问题图像对有6.7个候选分割,其中1.6个被标注者选择作为视觉答案。
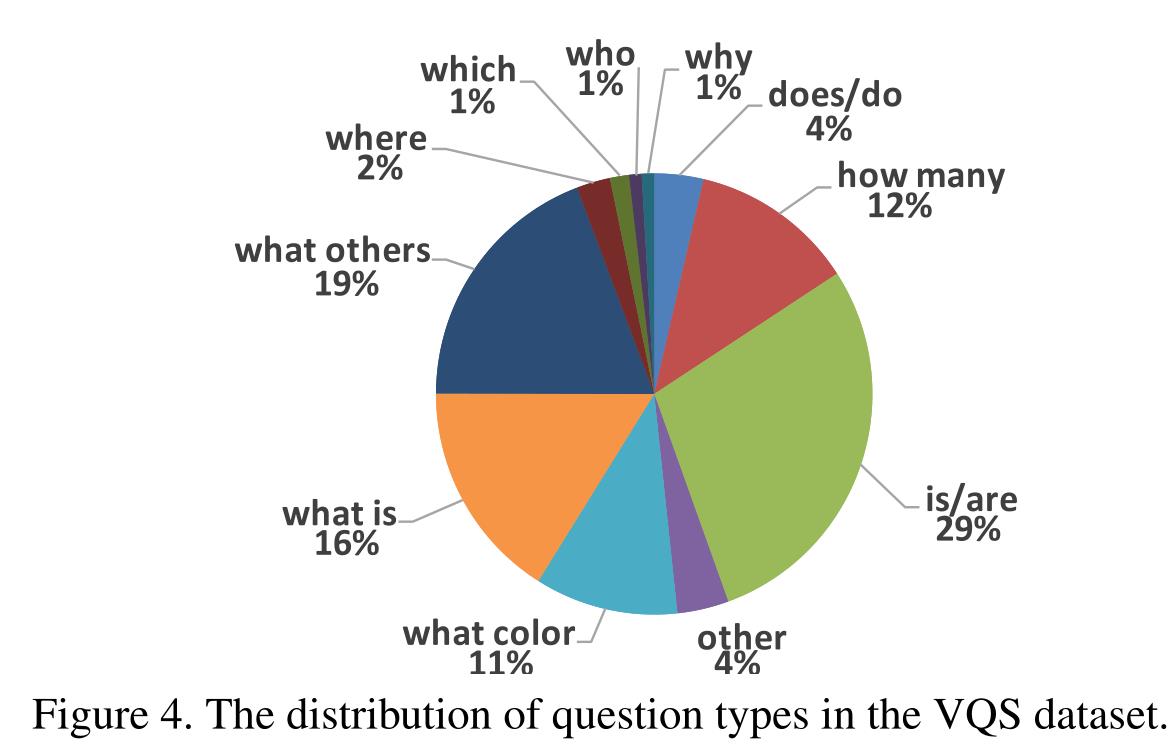
在图4中,我们可视化了问题类型的分布。最受欢迎的类型是“什么”问题(46%)。共有31,135个“是/是”和“做/做”问题(32.1%)。请注意,尽管对这些问题的文本回答只是简单的是或否,但在VQS,我们要求参与者通过制作语义分割遮罩来明确地展示他们对视觉内容的理解。在表3的第三列中,我们显示了用户从每种问题类型的平均候选人数中选择的平均分段数。
3. Applications of VQS
用户将视觉问题和分段联系起来,后者在视觉上回答前者,这是非常通用的。它们为至少两个问题提供了比以前更好的杠杆作用,即VQA的监督注意和以问题为中心的语义分割(QFSS)。
3.1.Supervised attention for VQA VQA的监督注意力
VQA旨在以短文形式回答关于图像的自然语言问题。我们猜想,在训练中,如果用户链接到质量保证体系的分段具有特权访问权,学习代理可以产生更准确的文本答案。为了验证这一点,我们设计了一个简单的实验来扩充[17]中的MLP模型。增强MLP显著改进了普通版本,并在VQA真正的多项选择任务中产生了最先进的结果[3]。
Experiment setup 实验设置
我们在VQA真多重选择上进行实验[3]。该数据集包含248,349个培训问题、121,512个验证问题和244,302个测试问题。每个问题有18个候选答案选择,学习代理需要找出其中的正确答案。我们按照[3]中建议的指标评估我们的结果。
MLP for VQA Multiple Choice MLP为VQA多选
由于VQA多项选择任务为每个问题提供了候选答案,贾布里等人建议将问题转化为一堆二元分类问题[17],并通过多层感知器(MLP)模型来解决它们:
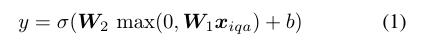
其中
x
i
q
a
x_iqa
xiqa是图像的特征表示、关于图像的问题和候选答案的连接,σ(·)是sigmoid函数。隐藏层有8096个单位和一个ReLU激活。这种模式很有竞争力,尽管很简单。
3.1.1 Augmenting MLP by supervised attention 通过监督关注增强MLP
我们建议通过更丰富的问题、答案、图像的特征表示来扩充MLP模型特别是通过下面详细描述的监督注意特征。
Question and answer features
xq&xa。对于一个问题或答案,我们通过对组成单词的300个单词2vec [29]向量进行平均,然后进行l2 normalization来表示它。这与[17]中的相同。
Image features
我们从输入图像中提取两种类型的特征:ResNet [14] pool5激活和属性特征[43],后者是属性检测分数。我们通过修改ResNet的输出层实现了一个属性检测器。特别地,给定C = 256个属性,我们为每个属性强加一个sigmoid函数,然后使用二元交叉熵损失来训练网络。训练数据从COCO图像字幕[24]中获得。我们将最频繁出现的256个单词作为属性保留下来。
Attention features注意特征。
我们进一步将注意力特性
x
a
t
t
x_{att}
xatt连接到原始输入
x
i
q
a
x_{iqa}
xiqa。注意力特征是由[47,eq]中图像区域特征和问题特征的加权组合所激发的。(22)],其中每个图像区域的非负权重
p
i
=
f
(
Q
p_i= f(Q
pi=f(Q,{ri}
)
)
)是问题Q和区域特征{ri}的函数。我们借用了杨等人[47,第3.3节]的网络架构和代码实现来实现此功能,只不过我们通过交叉熵损失来训练此网络,以将权重{pi}与从数据集中的分段中获得的“基本事实”注意相匹配。特别地,我们将与每个问题图像对相关联的分割图下采样到与图像区域的数量相同的大小,然后l1将其归一化为有效的概率分布。通过训练网络使权重
p
i
=
f
(
Q
p_i= f(Q
pi=f(Q,{ri}
)
)
)与这种关注相匹配,我们对与用户选择的分割相对应的区域实施更大的权重。
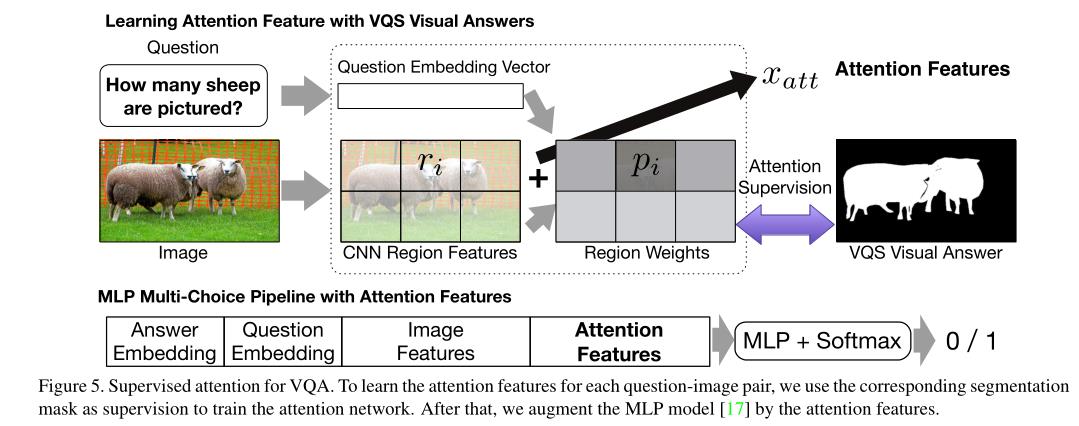
图5的上半部分显示了提取注意力特征的过程,下半部分显示了MLP模型[17],该模型增加了我们对VQA多项选择题的注意力特征。
3.1.2 Experimental results 实验结果
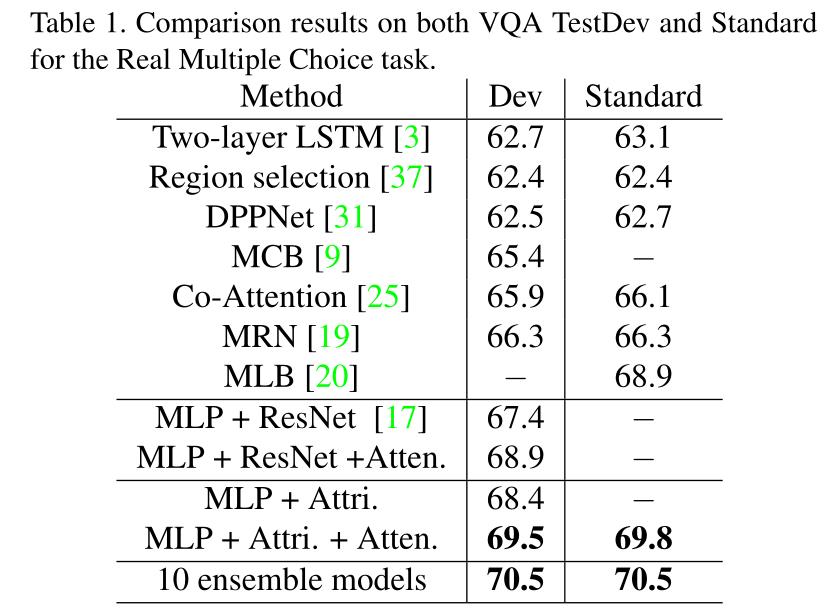
表1报告了在VQA真实多项选择任务中用几种最先进的方法增强MLP注意特征的比较结果。我们主要使用测试开发进行比较。在确定了我们最好的单个模型和集合模型之后,我们还将它们提交给评估服务器,以获取测试标准的结果。
首先,我们注意到,通过简单地使用所学的注意力特征(MLP +ResNet+Atten.)来增强它,相对于普通的MLP模型(MLP +ResNet)有1.5%的绝对改善。).
第二,图像的属性特征实际上相当有效。通过用属性特征替换ResNet图像特征,我们获得了比普通MLP 1.0%的改进。(参见MLP +Attri. vs MLP+ResNet)。尽管如此,通过将注意力特征附加到MLP + Attri.,我们仍然可以观察到1.1%的绝对增益。最后,用五个MLP+ ResNet + Atten.的模型和五个MLP + Attri. + Atten. 截止到论文提交日期,我们提交给评估服务器的论文在VQA真实多项选择任务的测试标准中排名第二。
3.1.3 What is good supervision for attention in VQA?在VQA,什么是值得关注的良好监管?
在这一节中,我们将VQS数据与人类注意力地图[5]和紧紧围绕VQS分割的边界框进行对比。
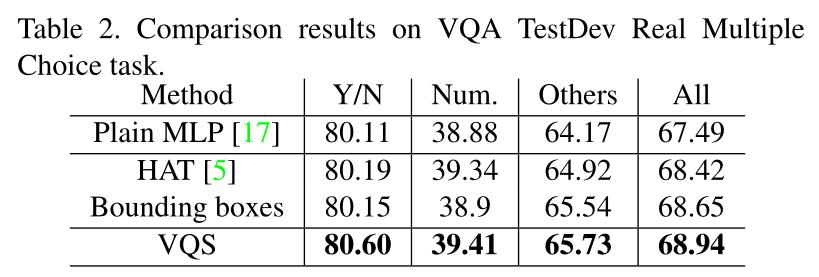
表2中报告的比较结果是在VQA真实多项选择的测试开发数据集上评估的。我们可以看到,链接到质量保证的分割比包围盒产生更好的结果,这进一步优于质量保证。这些确认源对象在VQA的注意力的监督学习中可能是最佳的,因为它们通常显示对象的小部分并包含大部分背景。然而,我们认为研究VQS的更一般的基于注意力的VQA模型仍然是有趣的[47,45,44,25,23,2,26]。
在补充材料中,我们描述了集成模型的详细实现。我们还展示了研究不同分辨率的分割遮罩如何影响VQA结果的其他结果。
3.2. Question-focused semantic segmentation 以问题为中心的语义分割
这一部分探索了一个新的任务,以问题为中心的语义分割(QFSS),这是可行的,因为收集的VQS连接了两个以前分开的任务(即分割和VQA)。给定一个关于图像的问题,QFSS期望学习代理通过从图像中语义分割出正确的视觉实体来输出视觉答案。它的设计方式类似于自然语言表达式的分割[15],可能应用于机器人视觉、照片编辑等。
为了正确地看待新的任务,我们提出了一种针对QFSS的掩码聚合方法,研究了一个基线,并通过假设在测试阶段所有的实例分段都作为预言给出,研究了一种上限方法。
3.2.1 Mask aggregation for QFSS
我们提出了一种解决QFSS问题的掩码聚合方法。建模假设是期望的输出分割掩模可以由高质量的分割建议组成。特别地,我们使用由SharpMask[33]给定图像生成的N = 25个分割建议e1、e2、… ,eN 每个建议都是与图像大小相同的二进制分割掩码。
然后,我们将这些掩码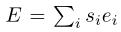 的凸组合阈值化为响应问题图像对的最终输出,其中第I个组合系数sii由问题特征
x
q
x_q
xq和第I个分割建议的表示
z
i
z_i
zi通过softmax函数确定,即si= softmax(
x
q
T
x^T_q
xqT
A
z
i
Az_i
Azi)。我们通过最小化用户选择的segmentationsE⋆and和模型生成的分割掩模e之间的L2损失来学习模型参数α。我们的当前模型是“浅的”,但是使其变深是直接的,例如,通过按照先前的实践(例如,记忆网络[44]和堆叠的注意力网络[47])将其输出与原始输入堆叠。
的凸组合阈值化为响应问题图像对的最终输出,其中第I个组合系数sii由问题特征
x
q
x_q
xq和第I个分割建议的表示
z
i
z_i
zi通过softmax函数确定,即si= softmax(
x
q
T
x^T_q
xqT
A
z
i
Az_i
Azi)。我们通过最小化用户选择的segmentationsE⋆and和模型生成的分割掩模e之间的L2损失来学习模型参数α。我们的当前模型是“浅的”,但是使其变深是直接的,例如,通过按照先前的实践(例如,记忆网络[44]和堆叠的注意力网络[47])将其输出与原始输入堆叠。
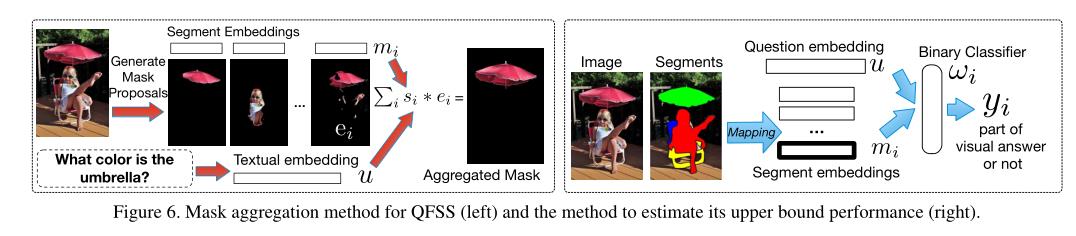
An oracle upper bound
我们通过
1)用MSCOCO发布的所有实例分段替换分段建议,假设它们在测试中作为预言可用,以及
2)使用二进制分类器来确定实例分段是否应该包括在可视答案中,来设计所提出方法的上限。结果可以被认为是我们的方法的上限,因为分割肯定比机器生成的建议更准确,并且二进制分类可以说比聚集多个掩码更容易解决。我们重新训练MLP(eq.1)这里为二进制分类器;现在,它将分段和问题的串联特征作为输入。图6用一个具体的问题图像例子描述了所提出的方法和upperbound方法。
A baseline using deconvolutional network
最后,我们研究了一个受FCN [15]文本制约的竞争基线。如图7所示,它包含三个组件,一个卷积神经网络[22],一个去卷积神经网络[30],以及一个在CNN中参与特征映射的问题嵌入。所有图像都被调整到224 × 224。卷积和反卷积网络遵循[30]中的规范。也就是说,VGG-16 [38]被修剪到最后一个卷积层,然后是两个完全连接的层,然后由解卷积网络镜像。对于输入问题,我们使用嵌入矩阵将其映射到与最后一个卷积层的特征映射相同的大小。问题嵌入然后是元素-wsie乘以特征映射。我们用输出掩码和基本事实分段掩码之间的L2损失来训练网络。
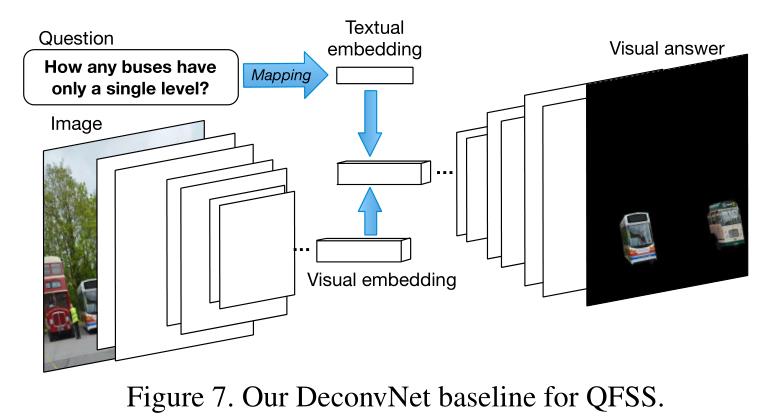
3.2.2 Experiments on QFSS
Features特征
除了使用第3.1.1节中的单词嵌入特征 x q x_q xq来表示问题之外,我们还测试了单词包特征。对于每个实例分割或建议,我们用0屏蔽掉图像中的所有其他像素,然后从ResNet-152 [14]的最后一个池层提取其特征。
Dataset Split 数据集分割
我们用的夏普Mask是从MS COCO的训练集里学来的。因此,我们以这样一种方式分割我们的VQS数据,即我们的测试集不与夏普Mask的训练集相交。特别是,我们使用26,995张图片和相应的68,509个问题作为我们的训练集。我们将剩余的图像和问题分成两部分:5000个图像和相关的验证问题,以及5873个图像和14875个问题作为测试集。
Results 结果
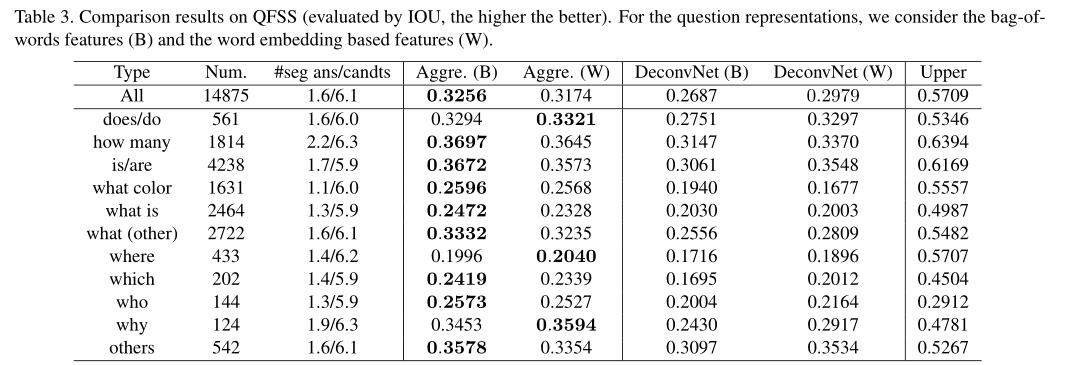
表3报告了QFSS的比较结果,通过交叉合并进行评估。此外,前三列是关于不同类型问题的数量和每个问题类型的用户选择的分段的平均数量。平均而言,任何问题类型都会选择多个细分。
首先,我们注意到所提出的掩码聚合优于基线解卷积,但明显差于其上限方法。掩码聚合优于解卷积,部分原因是它实际上使用了VQS数据之外的额外监督信息;也就是说,在微软COCO的训练集中的所有实例分割。上限结果表明,掩码聚合框架仍有很大的改进空间;一种可能性是在将来的工作中深入研究。
此外,我们还发现,两种问题表示法,单词包表示法和单词嵌入表示法,无论是对掩码聚合还是对解模糊网络都产生了可区分的结果。这个观察很有趣,因为它暗示了QFSS任务对问题表征方案有反应。因此,可以合理地预期,QFSS将从联合视觉和语言建模方法的进步中受益并取得进步。

最后,图8显示了一些定性的分割结果。请注意第一行中两个独立的实例分段,它们直观地回答了“有多少个”的问题。
4. Conclusion
在本文中,我们建议将COCO [24]提供的实例分段与VQA [3]中的问题和答案联系起来。收集的链接,命名为视觉问题和分割答案(VQS),在语义分割和VQA的个体任务之间转移了人类的监督,从而使我们能够以比以前更好的杠杆研究至少两个问题:VQA的监督注意和一个新的以问题为中心的语义分割任务。对于前者,我们通过简单地用一些注意力特征增加多层感知器来获得关于VQA实选择题的最先进的结果。对于后者,我们提出了一种基于掩码聚合的新方法。从长远来看,我们研究了一种基线方法和一种上限方法,假设实例分割是作为预言给出的。
我们的工作是从观察可可的受欢迎程度得到启发的[24]。我们怀疑现有的和看似不同的关于MSCOCO图像的注释是内在联系的。它们揭示了人类对同一视觉场景理解的不同层次和视角。显式地将它们联系起来不仅可以显著地有利于个体任务,还可以显著地有利于统一视觉的总体目标——语言理解。这篇论文只是表面文章。我们将在未来的工作中探索更多类型的注释和更丰富的模型。
Acknowledgement这项工作得到了美国国家科学基金会奖的部分支持,该奖由Adobe系统公司颁发,由英伟达公司颁发。c .甘获得国家基础研究计划(2011CBA00300 &2011CBA00301)和国家自然科学基金(61033001 & 61361136003)部分资助。
以上是关于VQA文献阅读VQS:将语义分割与视觉问答结合起来(ICCV2017)的主要内容,如果未能解决你的问题,请参考以下文章