理解CPU使用率和CPU上下文切换
Posted longshengguoji
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解CPU使用率和CPU上下文切换相关的知识,希望对你有一定的参考价值。
1、CPU使用率
1.1 CPU使用率查看
当发现服务或机器卡的时候,我们都是先通过top命令查看服务器CPU使用率
#默认每3秒刷新一次
top
top - 18:10:58 up 1216 days, 7:38, 4 users, load average: 23.06, 24.54, 23.72
Tasks: 839 total, 15 running, 824 sleeping, 0 stopped, 0 zombie
%Cpu(s): 4.2 us, 0.7 sy, 0.0 ni, 94.7 id, 0.3 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 26390464+total, 3420264 free, 44052232 used, 21643214+buff/cache
KiB Swap: 7812092 total, 7812092 free, 0 used. 11175941+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15135 postgres 20 0 98.579g 2.376g 2.375g R 52.9 0.9 131:00.20 postgres
18147 postgres 20 0 98.628g 29640 25648 R 52.9 0.0 0:00.09 postgres
15438 postgres 20 0 98.628g 136444 128192 S 41.2 0.1 0:01.02 postgres
18244 postgres 20 0 98.628g 18608 15440 S 29.4 0.0 0:00.05 postgres
18276 postgres 20 0 98.628g 18848 15564 S 17.6 0.0 0:00.03 postgres
…
输出结果字段解释如下:
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
空格之后是进程的实时信息,每个进程都有一个%CPU列,表示进程的CPU使用率。它是用户态和内核态CPU使用率的总和,包括进程用户使用的CPU、通过系统调用执行的内核空间CPU、以及在就绪队列允许的CPU。但是该命令没有屈服进程的用户态CPU和内核态CPU。需要怎么查看每个进程的详细情况就需要pidstat命令了。
#每隔1秒输出一组数据,共5组
$ pidstat 1 5
Linux 3.10.0-327.36.3.el7.x86_64 (map-traffic-dataprocess00.gz01) 06/06/2020 x86_64 (48 CPU)
06:26:56 PM UID PID %usr %system %guest %CPU CPU Command
06:26:57 PM 0 58 0.00 0.96 0.00 0.96 22 rcu_sched
06:26:58 PM 26 22926 1.00 1.00 0.00 2.00 6 postgres
06:26:58 PM 26 22943 1.00 0.00 0.00 1.00 8 postgres
…
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 0 58 0.00 0.98 0.00 0.98 - rcu_sched
Average: 26 22943 0.49 0.00 0.00 0.49 - postgres
Average: 26 22950 0.49 0.00 0.00 0.49 - postgres
…
输出数据的字段解释如下:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
1.2 如何分析CPU使用率高的进程
经常使用perf分析CPU性能问题,常用方法是使用perf top ,类似于top,能够实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数
$ perf top
Samples: 314K of event ‘cycles’, Event count (approx.): 128422426035
Overhead Shared Object Symbol
24.60% libc-2.17.so [.] __strcoll_l
18.70% libc-2.17.so [.] get_next_seq
4.90% postgres [.] XLogInsert
3.98% postgres [.] _bt_compare
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
2、系统上下文切换
CPU上下文切换按照场景分为:进程上下文切换、线程上下文切换和中断上下文切换。下面重点介绍如何分析CPU上下文切换问题:
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析CPU上下文切换和中断的次数。
#每隔5秒输出一组数据
$ vmstat 5
procs -----------memory---------- —swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
8 3 0 3620412 13352 202348336 0 0 765 126 0 0 4 1 95 0 0
60 0 0 2957900 13372 203044688 0 0 340577 50 170121 307445 14 2 81 2 0
60 3 0 3517864 13380 202474976 0 0 326373 37 175463 315599 18 2 77 2 0
分析这个结果,需要特别关注4列内容:
- cs (context switch) 每秒上下文切换次数
- in (interrupt) 每秒中断的次数
- r (Running or Runnable) 就绪队列的长度,等于正在运行和等待CPU的进程数
- b (Blocked) 处于不可中断睡眠状态的进程数
可以看到上述例子中上下文切换次数CS都大于10W次,而系统中断次数in也都大于10W次,就绪队列长度r为10,不可中断状态的进程数是0.
查看系统CPU 个数为48个
$ grep ‘model name’ /proc/cpuinfo | wc -l
48
结合vmstat的结果看,r列的值为60,大于系统CPU 个数,所以肯定会有大量的CPU竞争
in列中断次数大于10W次,说明中断处理也是个潜在的问题。
vmstat给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用pidstat命令。给它加上-w选项,可以查看每个进程上下文切换的情况。
#每隔 5 秒输出 1 组数据
pidstat -w 5
Linux 3.10.0-327.36.3.el7.x86_64 (xxxxxxxxxxxx) 06/05/2020 x86_64 (48 CPU)
06:25:04 PM UID PID cswch/s nvcswch/s Command
06:25:09 PM 0 58 376.34 0.00 rcu_sched
06:25:09 PM 26 42818 80.91 0.00 postgres
Average: UID PID cswch/s nvcswch/s Command
Average: 0 1555 0.20 0.00 odin-log-agent
Average: 0 1878 0.99 0.00 supervisord
Average: 0 2689 0.40 0.00 kworker/5:0H
Average: 26 4370 12433.72 0.00 postgres
这个结果中有两列内容是我们重点关注的对象:cswch(voluntary context switches)和nvscwch(non voluntary context switches)。cswch表示每秒自愿上下文切换的次数,nvcswch描述每秒非自愿上下文切换的次数。
自愿上下文切换是指进程无法获取所需资源,导致的上下文切换,比如I/O、内存等系统资源不足时发生的切换
非自愿上下文切换是指由于进程时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如大量进程都在争抢CPU时,就容易发生非自愿上下文切换。
从pidstat输出结果可以看出,上下文切换则是来自postgres进程,
中断类型定位
中断类型定位需要从/proc/interrupts文件中读取。/proc是Linux的一个虚拟文件系统,用于内核空间与用户空间直接的通信。/proc/interrutps就是这种通信机制的一部分,提供了一个只读的中断使用情况。
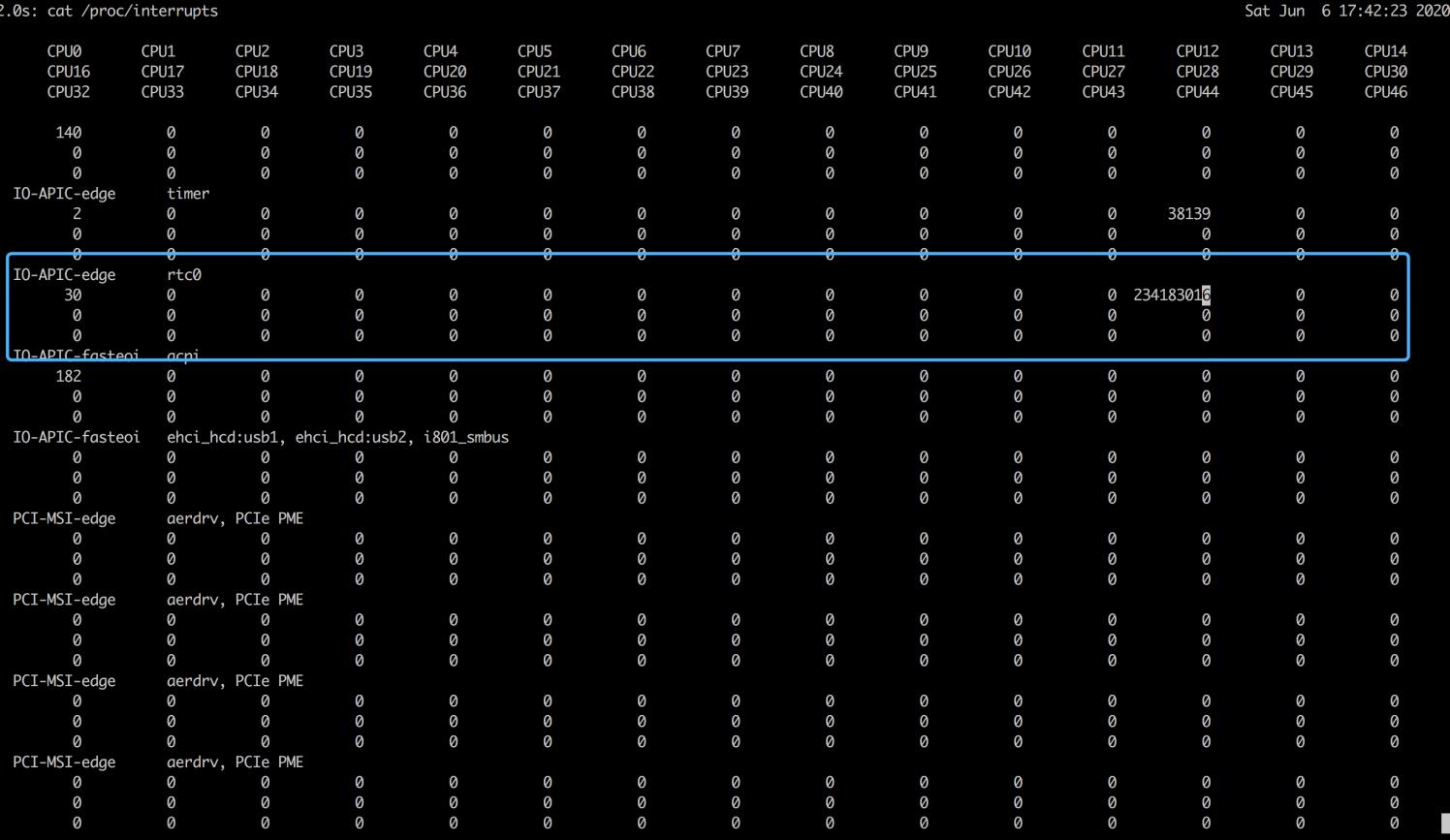
总结
每秒上下文切换多少次才算正常呢?这个数值其实取决于系统本身的CPU性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内都应该算是正常的。单当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
这时还需要根据上下文切换的类型,再做具体分析:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了I/O等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,说明都在争抢CPU,CPU成了瓶颈
- 中断次数变多了,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
以上是关于理解CPU使用率和CPU上下文切换的主要内容,如果未能解决你的问题,请参考以下文章