Go | 结构体及内存对齐
Posted Lindbergh_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go | 结构体及内存对齐相关的知识,希望对你有一定的参考价值。
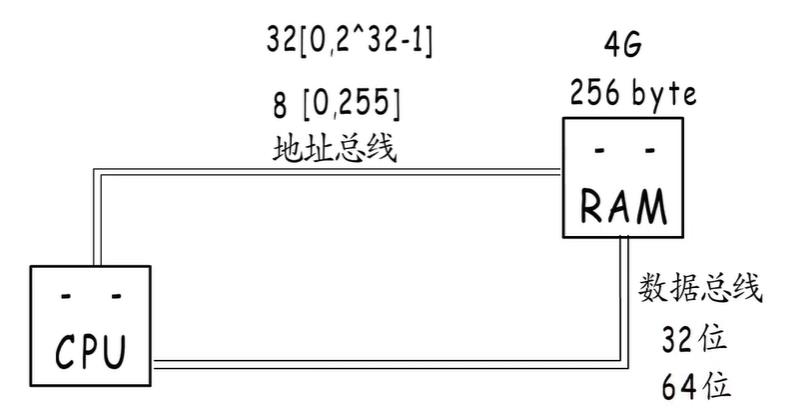
CPU 要想从内存读取数据,需要通过地址总线,把地址传输给内存,内存准备好数据,输出到数据总线,交给CPU。
如果地址总线只有8根[0,255],那这个地址就只有8位,可以表示256个地址,因为表示不了更多的地址,就用不到更大的内存,所以256byte就是8根地址总线最大的寻址空间,要使用更大的空间,就要有更宽的地址总线。
例如:32位地址总线[0,2^32-1],就可以寻址4G内存了
每次操作1字节太慢,那就加宽数据总线,要想每次操作4字节,就要有至少32位数据总线,8字节就要64位数据总线。
这里每次操作的字节数,就是所谓的机器字长
内存布局
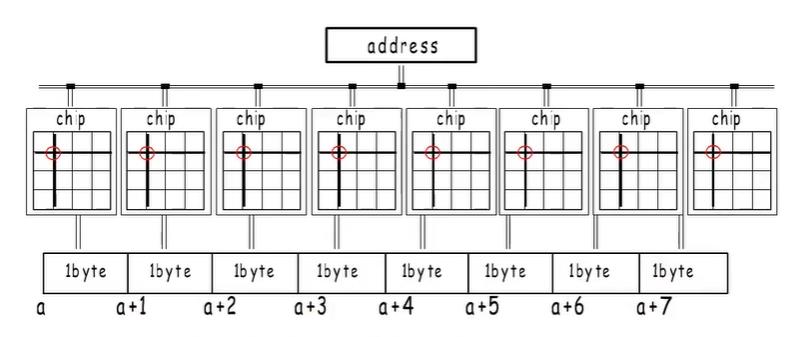
通过8个bank就可以选择行选择列来定位一个地址,这不像我们逻辑上认为的,那样连续的存在,但他们公用同一个地址。
各自选择同一个位置的一个字节,再组合起来作为我们逻辑上认为的连续8个字节,通过这样的并行计算,提高了内存访问的效率,但是用这种设计,addrss就只能是8的倍数。
如果非要错开一个格儿,由于最后一个字节对应的位置与前七个不同,不能在一次操作中被同一个地址选中,所以这样的地址是不能用的。硬件不支持
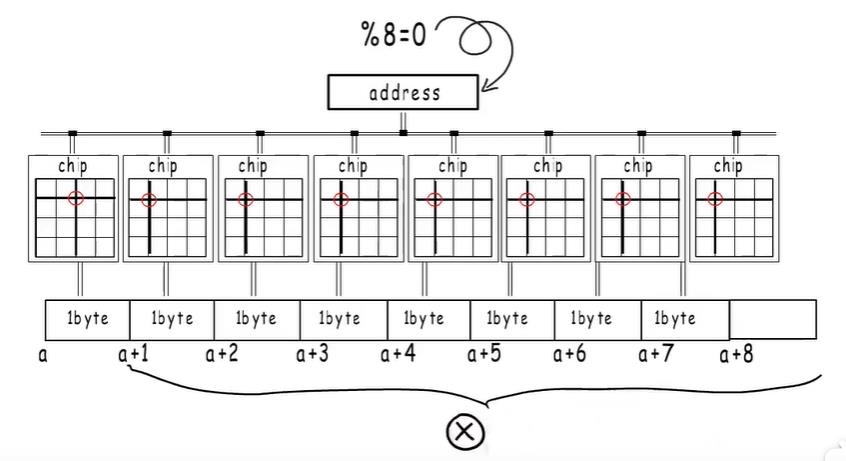
之所有些CPU能够支持访问任意地址,是因为它做了许多处理
例如你想从地址1开始读八个字节的数据。
CPU会分两次读,第一次从0-7,但只取后七字节,第二次从8-15,但只取第一个字节,再把两次结果拼接起来拿到所需数据,但这必然会影响性能。
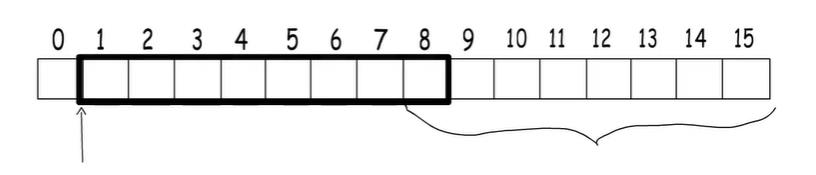
所以保证程序顺利高效的运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐。
每种类型的对齐值就是它的对齐边界,内存对齐要求数据存储地址,以及占用的字节数都要是它对齐边界的倍数。
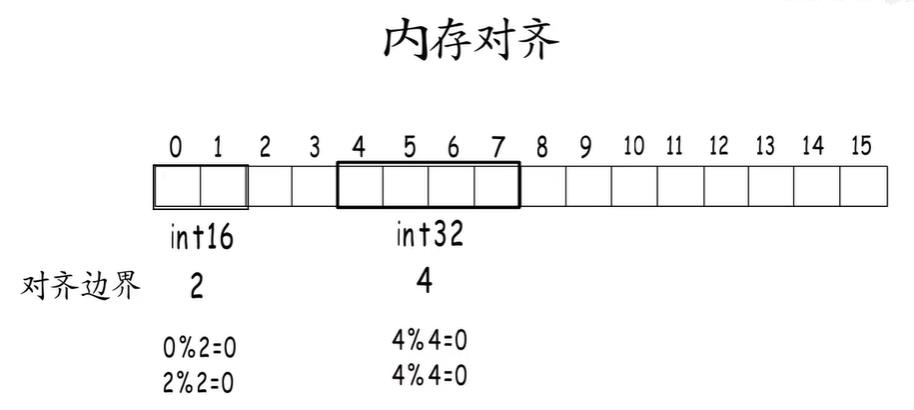
这个int32要错开两个字节,从4开始,却不能紧接着从2开始
如何确定对齐边界呢
这和平台有关,Go语言支持这些平台。

可以看到常见的32位平台,指针宽度和寄存器宽度都是4字节。64位平台上都是8字节,而被Go语言称为寄存器宽度的这个值,就可以理解为机器字长,也是平台对应的最大对齐边界
数据类型的对齐边界,是取类型大小与平台最大对齐边界中较小的那个。不过要注意同一个类型在不同平台上,大小可能不同,对齐边界也可能不同

内存边界这样选择,依然是为了减少浪费,提高性能
为什么不统一使用平台最大对齐边界,或者统一按照类型大小来对齐
假设目前是64位平台,最大对齐边界为8字节。
int8只有一个字节,按照一字节对齐的话,他可以放在任何位置,因为总能通过一次读取把它完整拿出来。如果统一对齐到8字节,虽然同样只要读取一次,但是每个int8类型的变量都要浪费7个字节,所以对齐到1。
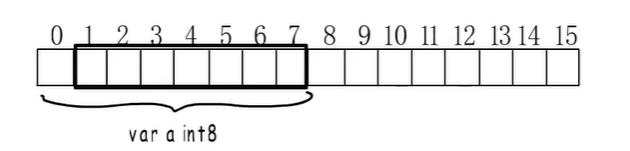
int16占两字节,按照两字节对齐,可以从0、2、4、6、8、10…而且能保证只用读取一次,如果按照一字节对齐,就可能存成[7-8],那就要读取两次再截取拼接,很影响性能。
如果对齐到8字节,会向int8一样,会浪费内存
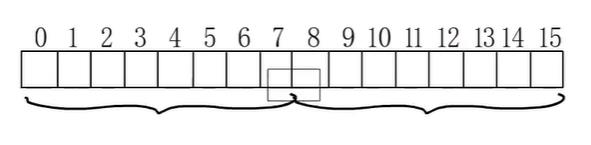
假设目前是32位平台,最大对齐边界为4字节。
int64占8字节,如果在前两个字节被占用的情况下,如果对齐到类型大小8,就要从8位置开始存,如果对齐到4,就可以从4位置开始存,内存浪费更少。
结构体的对齐边界
对结构体而言,首先要确定每个成员的对齐边界,然后取其中最大的,这就是这个结构体类型的对齐边界。
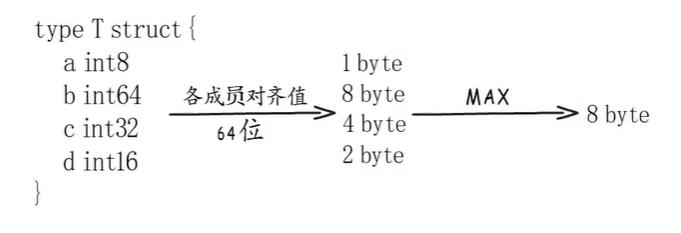
内存对齐要求:
- 存储这个结构体的起始地址是对齐边界的倍数,假设起始地址为0.
- 结构体的每个成员在存储时,都要把这个起始地址当作地址0,然后再用相对地址来决定自己该放在哪儿。
- 结构体整体占用字节数需要是类型对齐边界的倍数,不够的话要往后扩张一下。
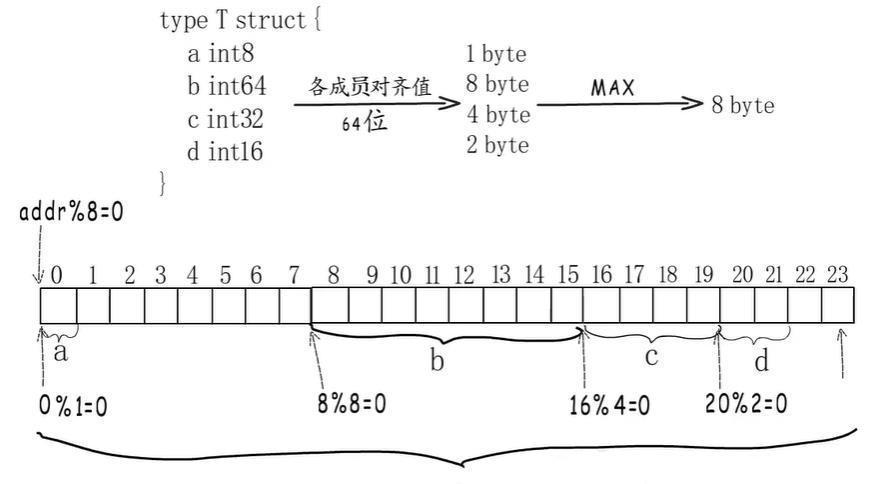
结构体整体占用字节数需要是类型对齐边界的倍数(22%8!=0),不够的话要往后扩张一下吗,所以他要扩充到相对地址32这里(24%8==0),最终这个结构体类型的大小就是24字节。
为什么要限制类型大小等于对齐边界的整数倍?
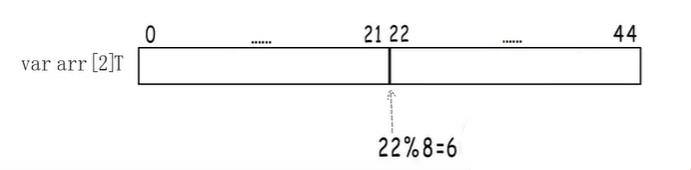
此时第二个元素并没有内存对齐。
所以只有每个结构体的大小都是对齐值的整数倍,才能保证数组中每一个都是内存对齐。
以上是关于Go | 结构体及内存对齐的主要内容,如果未能解决你的问题,请参考以下文章