Java学习笔记系列-基础篇-集合
Posted klsstt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java学习笔记系列-基础篇-集合相关的知识,希望对你有一定的参考价值。
Java学习笔记
Java学习笔记是一个持续更新的系列,工作多年,抽个空对自身知识做一个梳理和总结归纳,温故而知新,同时也希望能帮助到更多正在学习Java 的同学们。
本系列目录
入门篇
基础篇
集合
集合是一组可变数量的数据项的组合,在Java中集合可以当成对象的容器,它长度不定,并且可以存储不同类型数据,还提供很多方法对数据进行筛选和处理。
面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象进行操作,就需要对对象进行存储。
由于数组声明时便固定长度,并且支持只同一种类型就导致我们在工作中更倾向于使用集合。
集合框架
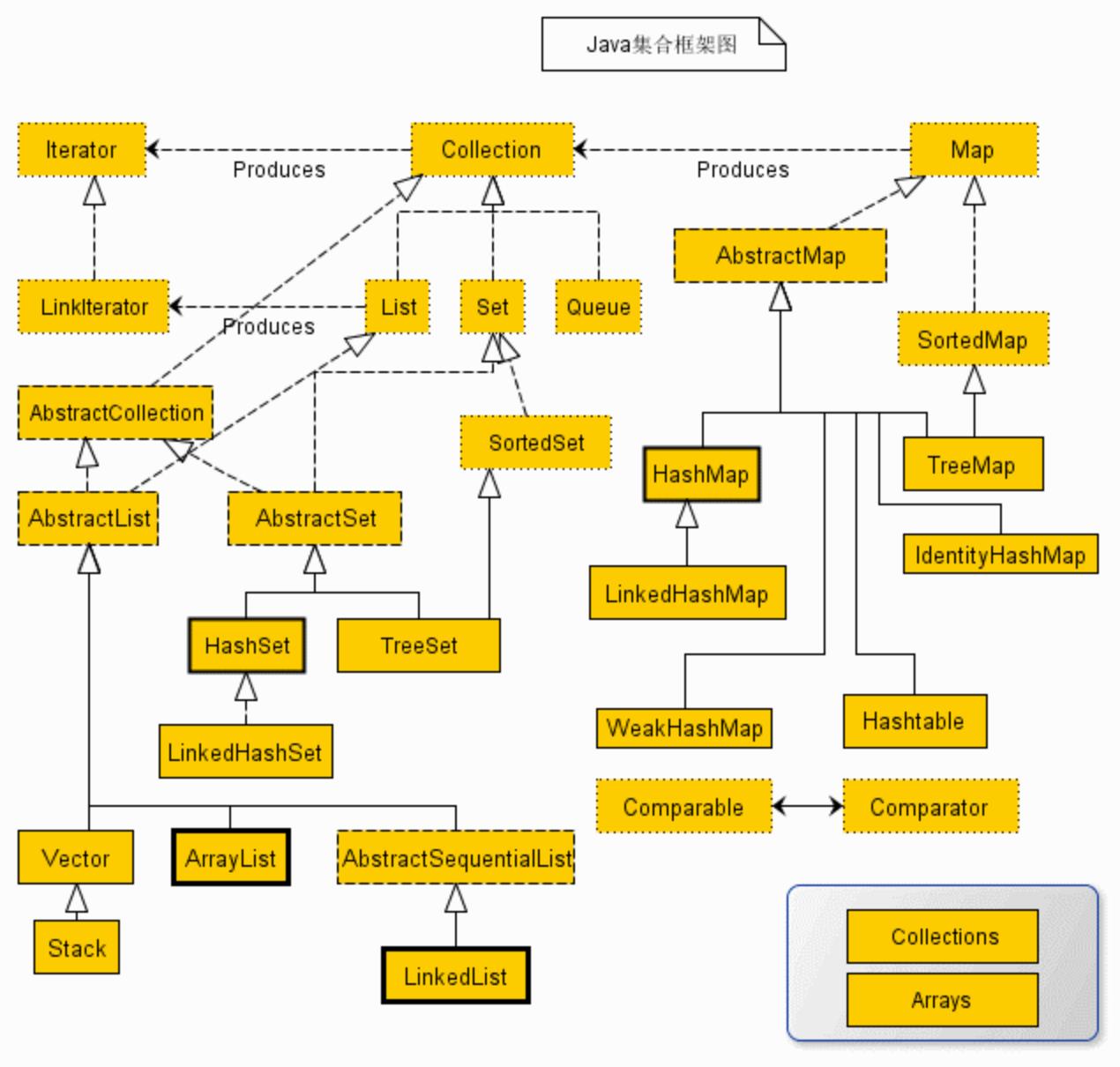
Java 中提供的集合框架主要包括两种类型,一种是Collection集合,存储单个元素容器,另一种是Map,以键值对映射的方式进行存储。
Collection
Collection 是最基本的集合接口,有三种子类型(List、Set 、 Queue),常用的实现类有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
一个Collection代表一组Object,即Collection的元素(Elements)。
Collection //接口的接口 对象的集合
|——List //元素按进入先后有序保存,可重复
|——|——LinkedList //接口实现类, 链表, 插入删除, 没有同步, 线程不安全
|——|——ArrayList //接口实现类, 数组, 随机访问, 没有同步, 线程不安全
|——|——Vector //接口实现类 数组, 同步, 线程安全
|——|——|——Stack //是Vector类的实现类
|——Set //仅接收一次,不可重复,并做内部排序
|——|——HashSet //使用hash表(数组)存储元素
|——|——|——LinkedHashSet //链表维护元素的插入次序
|——TreeSet //底层实现为二叉树,元素排好序
由以上结构树可看出来,Java 中提供的子类都是继承自Collection的接口,例如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数
1.无参数的构造函数用于创建一个空的Collection,
2.有一个 Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素,而后一个构造函数允许用户复制一个Collection。
不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代类型Iterator,使用该类即可逐一访问Collection中每一个元素。
常用方法
| 方法名 | 描述 |
|---|---|
| boolean add(Object obj) | 添加一个元素,添加非引用类型时自动装箱 |
| boolean addAll(Collection c) | 添加一个集合 |
| void clear() | 移除所有元素 |
| boolean remove(Object o) | 移除一个元素 |
| boolean removeAll(Collection c) | 移除一个集合的元素(是一个还是所有) |
| boolean contains(Object o) | 判断集合中是否包含指定的元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含指定的集合元素(是一个还是所有) |
| boolean isEmpty() | 判断集合是否为空 |
| Iterator iterator() | 获取迭代器 |
| int size() | 元素的个数 |
| boolean retainAll(Collection c) | 两个集合都有的元素,即集合的交集 |
| Object[] toArray() | 把集合转换为数组 |
用法实例如下:
public class HelloWrod {
public static void main(String[] args) {
HelloWrod helloWrod=new HelloWrod();
//collection是接口,不能直接声明
Collection collection=new ArrayList();
//add方法可以添加所有引用类型,非引用类型自动装箱
collection.add("abc");
collection.add("d");
collection.add(123);
collection.add(helloWrod);
//判断集合中是否包含指定的元素
System.out.println(collection.contains(123));
collection.remove(123);
System.out.println(collection.contains(123));
//遍历集合元素
Iterator it = collection.iterator(); // 获得一个迭代器
while(it.hasNext()) {//判断是否还有下一个元素,有则返回true
Object obj = it.next(); //指针下移,返回下一个元素
System.out.println(obj.toString());
}
//除了自带的迭代器之外也可以使用循环语句进行迭代遍历,具体用法见分支语句章节。
...
}
}
由Collection接口派生的两个接口是List和Set。
List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置,并且不需要像数组一样提前指定集合长度,还允许元素重复,通常在工作中用来替代数组使用。
用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
-
LinkedList类
LinkedList实现了List接口,允许null元素,底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
观察LinkedList底层源码,它默认声明了Node类型的
first和last属性,记录双向链表的首尾节点,双向链需要维护Node节点信息,Node节点属于内部类,它包含了上一个节点信息prev,下一个节点信息next。/** * Pointer to first node. * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */ transient Node<E> first; /** * Pointer to last node. * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */ transient Node<E> last; private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }当执行
add()方法时,将值封装到Node节点中,创建Node对象,由于每个节点之间都是双相联系,可以根据每个Node对象的prev和next知道它上一个节点和下一个节点的信息,默认为null。
注意:LinkedList没有线程同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。 -
ArrayList类
ArrayList实现了可变大小的数组,它允许所有元素,包括null,底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素。每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。
这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。
当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。如下是ArrayList源码,可以看到它的构造函数声明是一个Object类型的数组。
/** * Default initial capacity. */ private static final int DEFAULT_CAPACITY = 10; /** * The array buffer into which the elements of the ArrayList are stored. * The capacity of the ArrayList is the length of this array buffer. Any * empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA * will be expanded to DEFAULT_CAPACITY when the first element is added. */ transient Object[] elementData; // non-private to simplify nested class access public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }ArrayList在声明时,默认创建了一个
Object数组elementData,当执行add()方法时,如果是第一次执行,会先声明数组长度为10,下一次add()时会判断长度是否足够,如果不够则会发生扩容(创建一个新的数组,长度为原来长度的1.5倍),同时将原来的数组复制到新的数组中,所以我们在使用ArrayList时应当避免它在使用时发生扩容(被动发生扩容可能会浪费空间)。 -
Vector类
Vector底层实现非常类似ArrayList,但是Vector是同步的,它是比较老的一种实现类,线程安全。由Vector创建的Iterator,虽然和 ArrayList创建的Iterator是同一接口,但是因为Vector是线程同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了 Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出 ConcurrentModificationException,因此必须捕获该异常。
-
Stack 类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。
基本的push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。
Stack刚创建后是空栈。
常用方法
List继承了Collection,所以它除了拥有Collection的方法,也有一些自己定义的方法。
| 方法名 | 描述 |
|---|---|
| void add(int index, E element) | 在指定位置插入元素,后面的元素都往后移一个元素。 |
| boolean addAll(int index, Collection<? extends E> c) | 在指定的位置中插入c集合全部的元素,如果集合发生改变,则返回true,否则返回false。 |
| E get(int index) | 返回list集合中指定索引位置的元素 |
| int indexOf(Object o) | 返回list集合中第一次出现o对象的索引位置,如果list集合中没有o对象,那么就返回-1 |
| ListIterator listIterator() | 返回此列表元素的列表迭代器(按适当顺序)。 |
| ListIterator listIterator(int index) | 从指定位置开始,返回此列表元素的列表迭代器(按适当顺序)。 |
| E remove(int index) | 删除指定索引的对象 |
| E set(int index, E element) | 在索引为index位置的元素更改为element元素 |
| List subList(int fromIndex, int toIndex) | 返回从索引fromIndex到toIndex的元素集合,包左不包右 |
实战演示
List list=new ArrayList();
list.add(123);//添加123
System.out.println(list.get(0));//返回位置0的元素
list.add(1,"asdf");//index的上一个元素不能为空,否则会报IndexOutOfBoundsException
System.out.println(list.get(1));//get的下标也必须是存在的
System.out.println(list.indexOf(123));//查找123的位置
list.remove(1);//删除位置1的元素
Set接口
Set是一种无序的,不包含重复的元素的容器,通过元素的equals方法,来判断是否为重复元素。
Set的构造函数有一个约束条件,传入的Collection参数不能包含重复的元素。
实战演示
Set set=new HashSet();
set.add(111);
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add(123);
set.add(123);//添加时会按照equals方法判断,是否重复。
Iterator iterator=set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().toString());
}
//输出123一次,说明第二次add的123没有生效,111顺序和add时不同。
a
b
c
d
123
111
Set没有定义新的方法,使用的方法都是继承自Collection接口。
Set常用子类有HashSet和TreeSet
HashSet
HashSet集合实现了Set接口,线程不安全,可以存储null值,其内部存储数据时依靠哈希表和数组,所以它无法保证迭代顺序与元素的存储顺序相同。
哈希表底层,使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法(这个算法其实就是
Object类中的hashCode方法),计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。
存储自定义类型元素
当你用HashSet对象调用add方法时,它会去你存入的值的类型的那个类里调用它的HashCode方法,计算该对象内容的hash值。
计算完成后就会去容器中找有没有该hash值对应的值,没有的话,则把该元素添加到容器中去。如果有的话,再调用要存入值的类型的类中的equals方法比较内容。如果内容也一样,就丢掉这个值,不存入容器。如果内容不一样,则存入容器。
如果两个对象
hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个值存放在哈希表中。
注意
保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写
hashCode和equals方法建立属于当前对象的比较方式。
初始化HashSet部分源代码
private transient HashMap<E,Object> map;
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
通过源代码我们可以看到HashSet初始化时实际上是声明了一个HashMap,它们之间有一定的关系。
LinkedHashSet
在HashSet下面有一个子类LinkedHashSet,它是链表和哈希表组合的一个数据存储结构,LinkedHashSet集合保证元素的存入和取出的顺序。
在添加数据的同时,每个数据还维护了两个引用,记录此数据的前一个数据和后一个数据。
Set set=new LinkedHashSet();
set.add(111);
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add(123);
set.add(123);//添加时会按照equals方法判断,是否重复。
Iterator iterator=set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().toString());
}
//按添加顺序输出
111
a
b
c
d
123
TreeSet
TreeSet集合实现了Set接口,线程不安全,TreeSet类中所存储的元素必须是属于同一个类型,底层使用二叉树算法,不能有重复数据,存储的数据是自动排好序的,默认是自然排序规则,可以指定排序规则,不允许放入null值。
按照默认的自然排序方式进行
TreeSet set=new TreeSet();
set.add("a");
set.add("c");
set.add("b");
set.add("d");
set.add(123);//屏蔽这行,才可以正常运行
Iterator iterator=set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().toString());
}
//运行之后报错,需要删除不一致的类型。
java.lang.Integer cannot be cast to java.lang.String
//正常输出结果
a
b
c
d
以上实例运行之后报类型错误,说明TreeSet存储类型必须保持一致。
按照字符串长度排序规则
TreeSet<String> treeSet=new TreeSet<String>(new Comparator<String>() {
public int compare(String o1, String o2) {
int n1 = o1.length() - o2.length();
int n2 = o1.compareTo(o2);
return n1==0?n2:n1;
}
});
treeSet.add("aaaa");
treeSet.add("bb");
treeSet.add("ccc");
treeSet.add("d");
iterator=treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().toString());
}
//输出结果
d
bb
ccc
aaaa
Map
Map用于保存具有映射关系的数据,Map里保存着两组数据即key和value(双列数据),它们都可以使任何引用类型的数据,但key不能重复,通过指定的key就可以取出对应的value。
Map 没有继承 Collection 接口
常用方法
| 方法名 | 描述 |
|---|---|
| put(K key,V value) | 为容器添加一组key和value |
| putAll(Map<? extends K,? extends V> map) | 将一个map集合放到容器中 |
| get(Object key) | 获取对应key的value,没有则返回NULL |
| values() | 获取map中所有的values值,返回一个Collection类型的容器 |
| keySet() | 获取所有的key值,返回Set类型 |
| size() | 获取元素长度的大小 |
| entrySet() | 获取map中的所有元素,返回Set<Map.Entry>类型容器 |
| remove(key) | 移除相应的key的元素 |
| clear() | 清除容器中所有元素 |
| containsValue(Object value) | 判断value是否存在,返回boolean类型 |
| containsKey(Object key) | 判断key是否存在,返回boolean类型 |
| isEmpty() | 判断容器是否为空 |
Map结构树
Map //接口 键值对的集合
|——Hashtable //接口实现类, 同步, 线程安全
|——HashMap //接口实现类 ,没有同步, 线程不安全
|——|——LinkedHashMap //双向链表和哈希表实现
|——|——WeakHashMap
|——TreeMap //红黑树对所有的key进行排序
实现Map接口的常用类有Hashtable,HashMap,TreeMap。
Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表,属于比较老版本的实现类,效率低,不能存储null的key和value,属于线程安全。
//使用Hashtable的简单示例如下
//将1,2,3放到Hashtable中,他们的key分是”one”,”two”,”three”
Hashtable numbers = new Hashtable();
numbers.put("one", new Integer(1));
numbers.put("two", new Integer(2));
numbers.put("three", new Integer(3));
//numbers.put(null, new Integer(3));//会报错,key和value都不能为null
//要取出一个数,比如2,用相应的key:
Integer n = (Integer)numbers.get("two");
System.out.println("two = " + n);
//迭代map
Iterator<Map.Entry> iterator=numbers .entrySet().iterator();
while (iterator.hasNext()){
Map.Entry entry = iterator.next();
System.out.println(entry.getKey()+":"+entry.getValue());
}
由于作为key的对象将通过计算其哈希值来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
public Hashtable() {
this(11, 0.75f);
}
/**
* Constructs a new, empty hashtable with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hashtable.
* @param loadFactor the load factor of the hashtable.
* @exception IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive.
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
由源代码可知Hashtable数据结构实际上是由Entry数组,初始化时声明了默认长度和加载因子,Entry类型即由key和value组成的键值对构成的元素。
HashMap类
HashMap属于Map接口主要实现类,和Hashtable类似,不同之处在于HashMap是非线程同步的,执行效率高,并且允许null,即null value和null key。
//使用HashMap的简单示例如下
HashMap numbers = new HashMap ();
numbers.put("one", new Integer(1));
numbers.put("two", new Integer(2));
numbers.put("three", null);
numbers.put(null, new Integer(3));//不会报错
//要取出一个数,比如2,用相应的key:
Integer n = (Integer)numbers.get("two");
System.out.println("two = " + n);
//迭代map
Iterator<Map.Entry> iterator=numbers .entrySet().iterator();
while (iterator.hasNext()){
Map.Entry entry = iterator.next();
System.out.println(entry.getKey()+":"+entry.getValue());
}
//输出结果,无序
two = 2
null:3
one:1
two:2
three:null
HashMap中的key属于无序不可重复值,底层实现为数组+链表+红黑树
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap(以上是关于Java学习笔记系列-基础篇-集合的主要内容,如果未能解决你的问题,请参考以下文章