MySQL 架构
Posted 烟锁迷城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 架构相关的知识,希望对你有一定的参考价值。
1、mysql体系架构
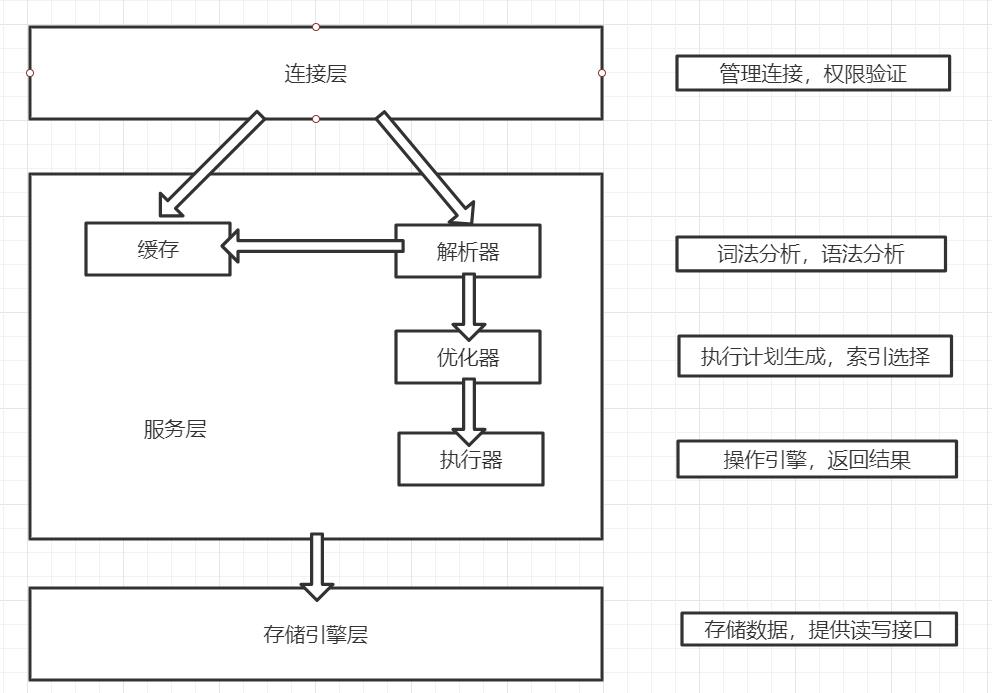
1.1、连接层
客户端要连接到MySQL服务器3306端口,就必须和服务器建立连接,服务层就负责管理所有的连接,客户端的登信息等。
1.2、服务层
连接层会把SQL语句交给服务层。服务层负责查询缓存,根据SQL调用对应的接口,对SQL进行解析,优化,最后执行。
1.3、存储引擎层
存储引擎是存放数据的地方,MySQL支持多种不同的引擎。
2、查询SQL的执行过程探讨
2.1、执行前准备
对数据库的连接方式可以分为以下几种
- 通信类型:同步/异步
- 连接方式:长连接/短连接
- 协议:TCP/Unix Socket
2.1.1、连接线程
MySQL是一个单进程,多线程的模型,客户端每产生一个连接session,MySQL就会产生一个线程来处理这个连接,默认线程数为151个。
查询数据库当前线程的使用情况:
show global status like 'Thread%'
| 属性 | 解释 |
|---|---|
| Threads_cached | 数据库缓存线程数 |
| Threads_connected | 数据库连接线程数 |
| Threads_created | 数据库创建线程数 |
| Threads_running | 数据库当前运行线程数 |
既然数据库是使用线程来进行连接,如果长时间不使用,就会造成性能的浪费,因此还有超时时间来释放线程。
查询非交互超时时间,如JDBC程序:
show global variables like 'wait_timeout'
查询交互超时时间,如数据库工具:
show global variables like ‘interactive_timeout’
2.1.2、查询缓存
在MySQL-5.7版本中,查询的缓存默认关闭
查询缓存开关
show variables like 'query cache%'
这个缓存用处不大,一旦数据有更新或者条件略微不同都会导致缓存失效,所以应该把缓存交给更加专业的工具。
2.2、语句执行
SQL语句的执行必然会经过如下所述的阶段,每个阶段都会完成查询的必要步骤。
2.2.1、解析器
一条语句在执行之前,MySQL会对它进行两项检查。
- 词法分析:MySQL会把一个完整的SQL语句打碎成一个个单词
- 语法分析:MySQL会进行SQL语法检查。
分析完成后,整个SQL语句会被打散成解析树。
2.2.2、预处理器
在完成解析器解析后,会进行语义解析,即检查表是否存在,字段是否存在。
2.2.3、优化器
优化器的主要功能是优化SQL,生成、选择执行路径(基于cost)
- 子查询优化
- 等价谓词重写
- 条件化简
- 外连接消除
- 嵌套连接消除
- 连接消除
- 语义优化
- 非SPJ优化
2.2.4、执行计划
SQL的具体执行情况由执行计划决定,可以通过关键字EXPLAIN来模拟SQL语句的执行。
EXPLAIN select * from table
如果想要得到更加详细的数据,可以执行如下语句
EXPLAIN FORMAT=JSON select * from table
这样可以得到一个有关详细信息的JSON字符串。
2.2.5、执行器
执行器用来执行存储引擎。
2.2.6、表类型(存储引擎)
MySQL提供不同的存储引擎,可用语句指定表的存储引擎
ENGINE = Innodb
5.7版本之后,默认指定为InnoDB,也可以将表的类型进行修改。
主要的表类型介绍:
- InnoDB:事务安全,崩溃恢复,行级别锁,一致性非锁定读,聚集索引,外键。
- MyISAM:表锁定,适用于只读。
- Memory:内存表,读取极快,不持久化,适用于临时表。
- CSV:纯文本,用标点和换行存储数据,适用于备份和数据迁移。
- Archive:结构紧凑,无索引,适用于存储归档数据。
MySQL支持自定义存储引擎,只要开发的自定义引擎符合定义规范,所有的存储引擎都有共同的接口调用,因此表可以切换存储引擎。
至此,整个SQL的执行过程就已经全部结束。
3、修改SQL的执行过程探讨
3.1、Buffer pool
无论是查询,修改,新增还是删除,都要调用InnoDB存储在磁盘上的数据到内存上。从磁盘上读取数据会用到页缓存,之前已经在RocketMQ一章中提及过。页缓存的大小是4KB,但InnoDB的数据页是16KB。
为了进一步提升效率,InnoDB还使用了内存缓存,将查询过的数据存到专门的内存缓冲区buffer pool中,无论是写入新数据还是读取数据,都会先存到buffer pool中以提升效率,因此,在buffer pool中还没有同步到磁盘上的数据页就叫脏页,同步过的就叫干净页,同步数据的功能是由一个后台线程定时执行的,被称为刷脏。由于是定时执行刷脏,一旦出现事故,内存中的buffer pool数据就会丢失。
3.2、redo log
为了避免数据丢失,InnoDB使用redo log来持久化buffer pool的数据日志到硬盘中,当事故发生后,会先检查redo log中是否有还未同步的数据,然后做进一步的数据恢复。
这里有一个明显的矛盾,明明是为了提升效率,采用内存缓存,但是又对缓存做日志持久,这样似乎还不如直接存磁盘。实际上,redo log使用顺序I/O,日志连续写入,无需寻址,关于顺序I/O和随机I/O,在Kafka一章中有详细说明。
总结一下redo log的作用
- 保证内存数据的安全性,延迟刷盘时机,进而提升系统吞吐。
- 为InnoDB提供了崩溃恢复的特性,实现持久性
- Redo log记录的是“在某个数据页上做了什么修改”,属于物理日志
- Redo log的大小是固定的,前面的内容会被覆盖,一旦文件写满,就会触发Buffer pool到磁盘的同步,以便腾出空间记录后面的修改。
3.3、Undo log
与之类似的日志还有Undo log,它记录事务发生之前的数据状态,是发生异常时回滚的依据,保证原子性。
redo log和undo log都与事务密切相关,因此统称为事务日志。
3.4、总结
了解到这些,就可以大概知道更新的执行流程:
- 事务开始,从内存buffer pool或磁盘data file取到包含这条数据的数据页,返还给Server的执行器。
- Server的执行器修改数据页的这一行数据的值
- 记录数据修改情况到undo log
- 记录数据修改情况到redo log
- 调用存储引擎接口,记录数据页到buffer pool
- 事务提交
4、InnoDB总体架构
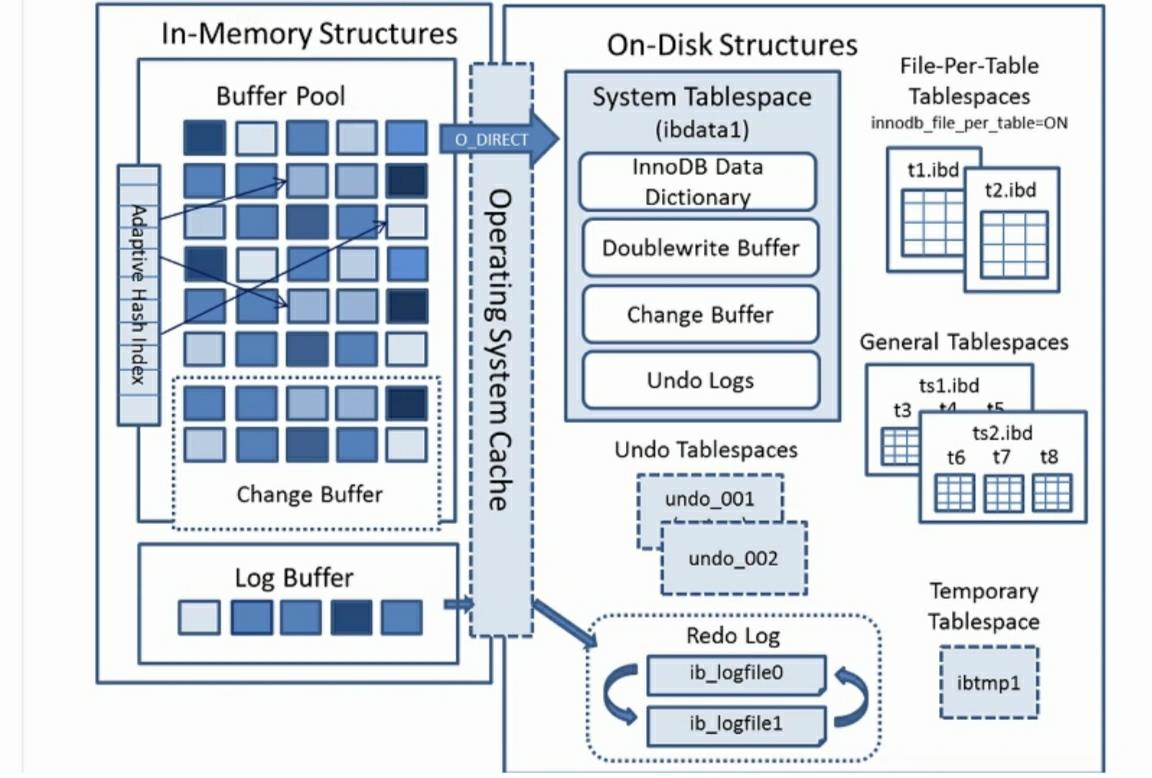
4.1、内存结构
buffer pool包含三个部分,buffer pool,change buffer,adaptive hash index,此外还有(redo)log buffer
4.1.1、buffer pool 缓冲池
可以使用SQL查看buffer pool的状态
Show variables like ‘%innodb buffer pool%’;
Buffer pool会使用大量的内存空间,因此会出现内存占满的情况,和Redis类似,它采用了LRU淘汰算法,算法详情在Redis一章中已经详细说明。
在buffer pool中,算法同样得到了改进。
4.1.2、LRU算法
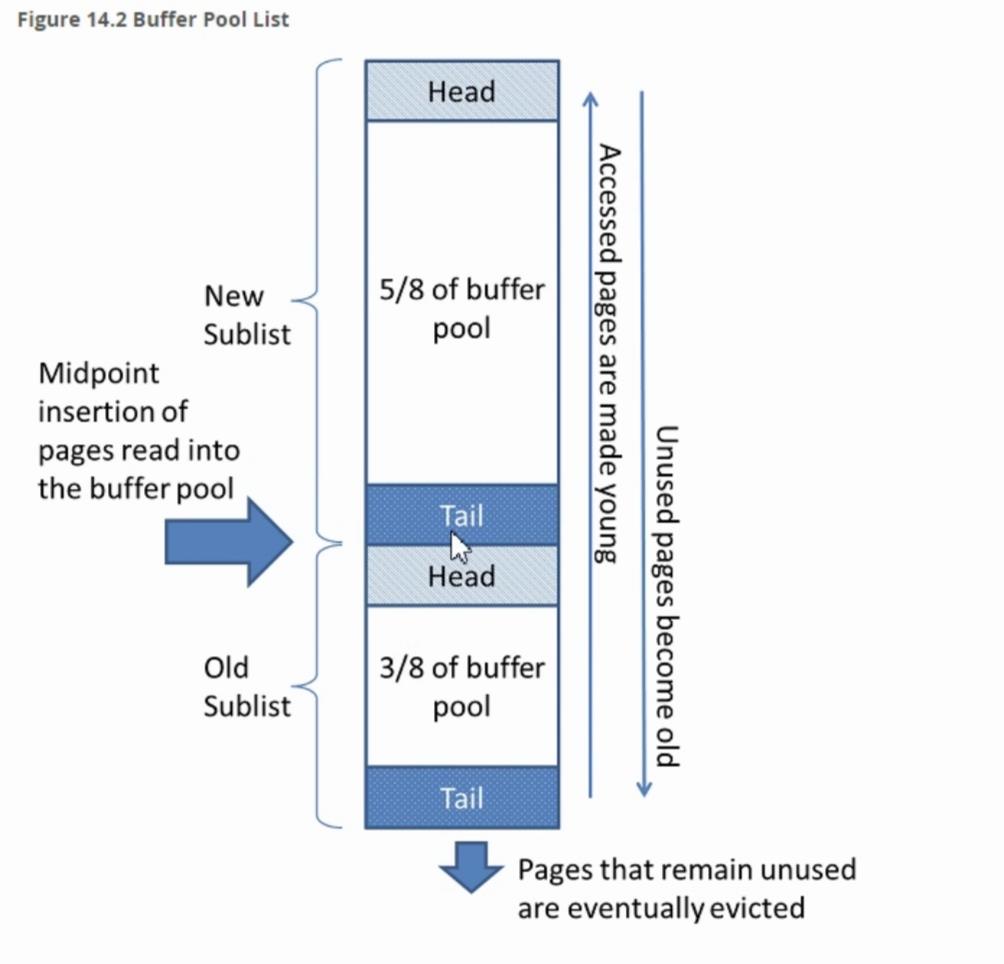
4.1.2.1、预读
InnoDB的数据页有一个预读机制,即在访问某一个数据页的时候,相邻的一些数据页可能很快被访问到,所以要先放到buffer pool中缓存起来。
这种预读的机制分为两种:
- 线性预读:InnoDB中把64个相邻的page叫做一个extent区,如果顺序地访问一个extent的56个page,InnoDB就会把下一个extent缓存到buffer pool中。
- 随机预读:如果buffer pool已经缓存了同一个extent的数据页超过13个,就会把这个extent剩下的全部page全部缓存到buffer pool中。此功能默认关闭
预读虽然加快读取速度,但是也会导致占用的内存空间更多,剩余的空闲页更少,这样会导致真正需要的数据很快就被淘汰。
4.1.2.2、冷热分离
InnoDB的存储区域被划分为两大块,冷数据区(old sublist)和热数据区(new sublist)。新数据被查询到之后,先进入到冷数据区的head中,无论是由预读还是普通的读得到的数据。如果有一些预读的数据没有被用到,会在冷数据区被直接淘汰。如果冷数据区的数据被再次访问,就会被移动到热数据区的head,如果热数据区的数据长时间没有被访问,就会被移动到冷区head,最后被慢慢淘汰。
在默认情况下,热数据区占用5/8的大小,冷数据区占用3/8,这个值由innodb_old_blocks_pct控制,它代表冷数据区的大小比例。
4.1.2.3、时间窗口
如果冷数据被短暂地访问一次,之后就再也不会被访问,这样大量的冷数据就会污染热数据区,为了解决这个问题,InnoDB增加了时间窗口,只有超过这个时间之后被访问,才被认定为有效地访问。InnoDB通过innodb_old_blocks_time这个参数控制,默认一秒钟。
4.1.2.4、移动优化
为了避免并发问题,LRU的操作是需要加锁的,也就是说每一次链表的异动,都会带来锁的争夺,因此要尽量减少LRU链表的移动。
如果一个数据处于热数据区的前1/4区域,那么访问这个数据页时,不需要将它移动到热数据区的head,如果处于后3/4区域,就会移动到热数据区的head。
4.1.3、change buffer 写缓冲
如果数据页不是唯一索引,不存在数据重复的情况,也就不需要从磁盘加载索引页判断数据是不是重复。这种情况下可以先把修改记录放在内存的缓冲池中,从而提升更新语句的执行速度。
把change buffer记录到数据页的操作叫做merge,在访问这个数据页的时候,数据库shut down或者redo log写满时触发。
如果数据库大部分索引都是非唯一索引,并且业务室写多读少,不会在写数据后立即读取,就可以使用change buffer。
4.1.4、Adaptive Hash Index
一种hash索引
4.1.5、redo log buffer
Redo log也不是每一次都直接写入磁盘,在buffer pool里面有一块内存区域(log buffer) 专门用来保存即将要写入日志文件的数据,默认16M,它一样可以节省磁盘I/O
使用SQL查看其大小:
show variables like ‘innodb_log_buffer_size’;
需要注意的是,redo log的内容主要是用于崩溃恢复。磁盘的数据文件,数据来自于buffer pool。redo log写入磁盘,不是写入数据文件。
数据写入到磁盘的时候,操作系统本身就是有缓存的,log buffer写入log file的时候就是flush将缓冲区数据写入磁盘的时候。log buffer写入磁盘的时机由一个参数控制,默认为1.
可以使用SQL查看刷盘设置
Show variables like ‘%innodb_flush_log_at_trx_commit%’;
| 数值 | 作用 |
|---|---|
| 0(延迟写) | log buffer将每秒一次写入log file中,并且log file的flush操作同时进行,该模式下,在事务提交的时候,不会主动触发写入磁盘的操作 |
| 1 | 每次事务提交时mysql都会吧log buffer的数据写入log file,并且刷到磁盘中去。 |
| 2 | 每次事务提交时mysql都会吧log buffer的数据写入log file,并且刷到磁盘中去。但是flush操作并不会同时进行,该模式下,mysql会每秒执行一次flush操作 |
4.2、磁盘结构
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中,InnoDB的表空间分为五大类
4.2.1、系统表空间 system tablespace
在默认情况下,InnoDB存储引擎有一个共享表空间,也叫系统表空间,对应文件ibdata1。
InnoDB系统表空间包含InnoDB数据字典和双写缓冲区,change buffer和undo log,如果没有指定file-per-table,也包含用户创建的表和索引空间。
- undo 在后面介绍,因为也可以设置独立表空间
- 数据字典,由内部系统表组成,存储表和索引的元数据(定义信息)
- 双写缓冲,InnoDB的一大特性
InnoDB的页和操作系统的页大小不一致,InnoDB页大小一般为16K,操作系统页大小为4K,InnoDB的页写入到磁盘时,一个页需要分4次写。
如果存储引擎正在写入页的数据到磁盘时发生了事故,可能出现页上只写了一部分的情况,这就叫做部分写失效(partial page write),可能会导致数据丢失。
在这种情况下,redo log也是无法做崩溃恢复的,因为如果这个页本身已经损坏了,用它来做崩溃恢复是没有意义的。所以在对于应用redo log之前,需要一个页的副本,如果出现了写入失效,就用页的副本来还原这个页,然后再应用redo log。这个页的副本就是double write,InnoDB的双写技术,通过它实现数据页的可靠性。
可以使用SQL,查看双写缓冲。
Show variables like ‘innodb_doublewrite’;
和redo log类似,double write由两部分组成,一部分是内存,一部分是磁盘,因为double write是顺序写入,开销很小。
在默认情况下,所有的表共享一个空间,这个文件会越来越大,而且不会收缩。
独占表空间 file-per-tabel tablespaces
在MySQL中,可以让每张表独占一个表空间,这个开关是通过innodb_file_per_table设置,默认开启
Show variables like ‘innodb_file_per_table’;
开启后,每张表都会占有一个表空间,这个文件就是数据目录下的ibd文件,存放表的索引和数据。
但是其他类的数据,如回滚信息,插入缓冲索引页,系统事务信息,二次写入缓冲等还放在原来的共享表空间中。
4.2.2、通用表空间 general tablespaces
通用表空间也是一种共享的表空间,类似共享表空间ibdata1。可以创建一个通用的表空间,用来存储不同数据库的表,数据路径和文件可以自定义。
create tablespace ts1 add datafile '/var/lib/mysql/ts1.ibd' file_block_size = 16K engine = innodb
在创建表的时候可以指定表空间,用alert修改表空间可以转移表空间。
create table ts1 (id integer) tablespace ts1
不同表空间的数据是可以移动的,删除表空间之前需要先删除里面所有的表。
drop table ts1
drop tablespace ts1
4.2.3、临时表空间 temporary tablespaces
存储临时表的数据,包括用户创建的临时表和磁盘的内部临时表,对应数据目录下的ibtmp1文件。当数据服务器正常关闭时,该表空间会被删除,下次重新产生。
- redo log:磁盘结构里面的redo log,在前面已经介绍过了。
- undo log tavlespace:undo log的数据默认在系统表空间ibdata1文件中,因为共享表空间不会自动收缩,也可以单独创建一个undo log表空间。
5、后台线程
后台线程的主要作用是负责刷新内存池中的数据和把修改的数据页刷新到磁盘。后台线程分为:master thread,I/O thread,purge thread,page cleaner thread。
后台线程的主要作用是负责刷新内存池中的数据和把修改的数据页刷新到磁盘,后台线程为:
- master thread:负责刷新缓存数据到磁盘并协调调度其他后台进程
- I/O thread:分为insert buffer,log,read,write进程,分别用来处理insert buffer,重做日志,读写请求的I/O回调
- purge thread:回收undo log
- page cleaner thread:刷新脏页
除了InnoDB架构中的日志文件,MySQL的server层也有一个日志文件,叫做binlog,它可以被所有的存储引擎使用。
6、Binlog
binlog以事件的形式记录了所有的DDL和DML语句(因为它记录的是操作而不是数值,属于逻辑日志),可以用来做主从复制和数据恢复。
与redo log不一样,它的文件内容可以追加,没有大小限制。
在开启了binlog功能的情况下,可以将binlog导出成sql语句,把所有的操作重放一遍,来实现数据恢复。
binlog的第二个功能就是主从复制,原理为从服务器读取主服务器的binlog,然后执行一遍。
有了这两个日志之后,可以查看一下更新语句是如何执行的。
6.1、更新过程
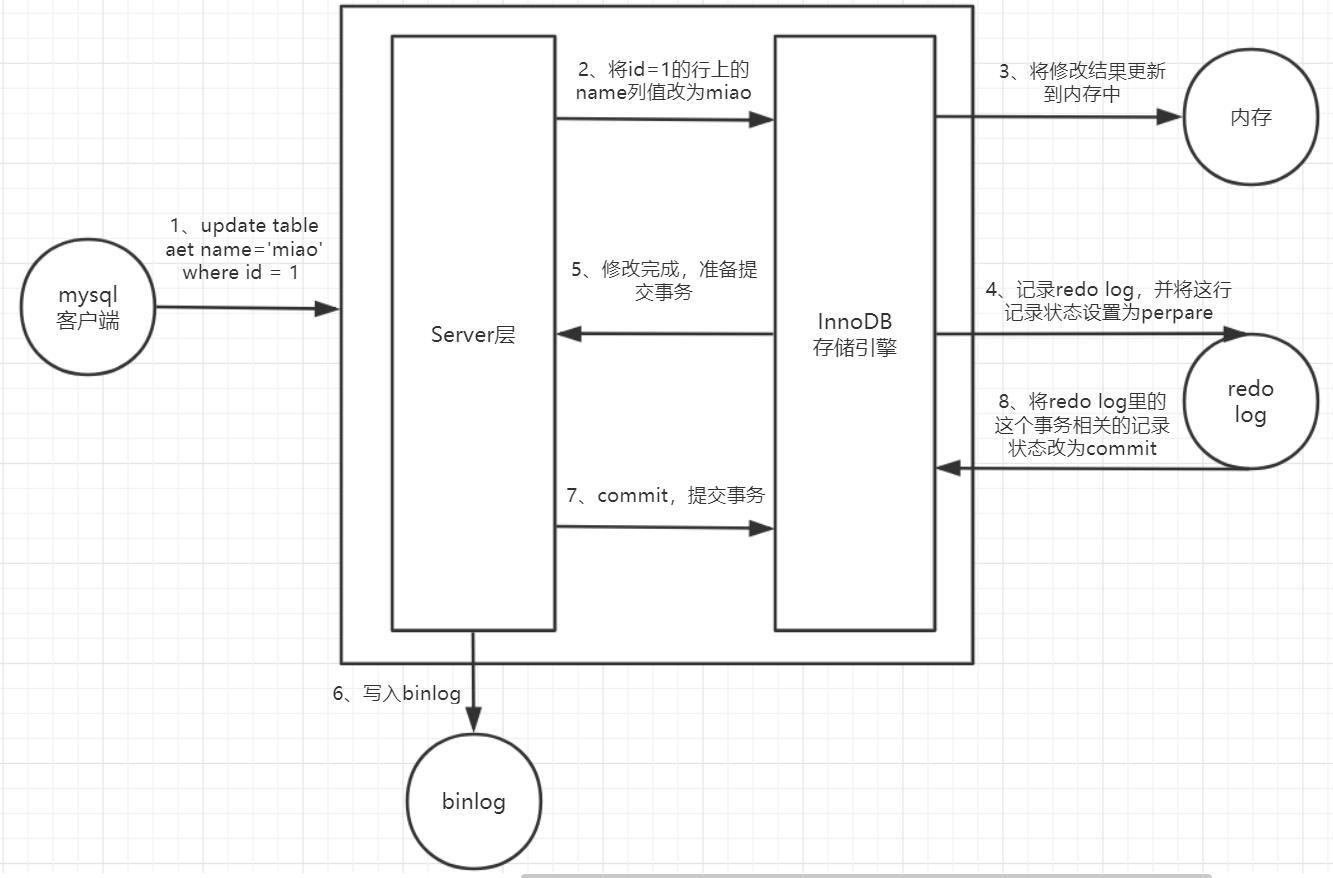
- 先查询到这条数据,如果有缓存,也会用到缓存。
- 把name改为miao,然后调用引擎的API接口,写入这一行数据到内存,同时记录redo log,这是redo log进入prepare状态,然后告诉执行器,执行完成,准备提交。
- 执行器收到通知后记录binlog,然后调用存储引擎接口,设置redo log状态为commit。
- 更新完成。
执行的关键在于,
- 先记录到内存,再写日志文件。
- 记录redo log分为两个阶段
- 存储引擎和Server记录不同日志
- 先记录redo,再记录binlog
6.2、两段提交
如果执行更新过程中,写完redo log还没有写binlog的时候,mysql重启,因为redo log可以在重启的时候用于恢复数据,所以写入磁盘的是新数据,但是binlog没有记录相关的逻辑日志,就会出现数据不一致的情况。
所以在写两个日志的时候,binlog就充当了一个事务的协调者。通知InnoDB来执行prepare或者commit或者rollback。
如果binlog写入失败,将不会提交事务,这里的设计类似于分布式事务,没有全部成功,就算全部失败。
在崩溃恢复的时候,判断事务是否需要提交的条件为:
- binlog无记录,redo log无记录:在redo log写入之前的crash,恢复操作:回滚事务。
- binlog无记录,redo log状态prepare:在binlog写完之前的crash,恢复操作:回滚事务。
- binlog有记录,redo log状态prepare:在binlog写完提交事务之前的crash,恢复操作:提交事务。
- binlog有记录,redo log状态commit:在redo log写入之前crash,恢复操作:无需恢复。
这样看来,只要binlog中有记录,事务一定要提交,反之则一定要回滚。
以上是关于MySQL 架构的主要内容,如果未能解决你的问题,请参考以下文章