flink源码分析之kafka consumer的执行流程
Posted 开发架构二三事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink源码分析之kafka consumer的执行流程相关的知识,希望对你有一定的参考价值。
背景
线上flink任务稳定运行了两个多月了,突然之间收到了消息堆积较多的报警,kafka上看到的现象是消息堆积较多。问过业务人员得知,对应的流表在前一天重新刷了一遍数据,在我们的这个任务中有两次维表关联,而且内层有一个split操作会造成外层维表关联的数据量膨胀(最大可能为80倍,即split之后产生了80条新记录)。开始了问题分析之路。
问题
查看taskmanager的log时发现有如下报警信息:
WARN org.apache.flink.streaming.connectors.kafka.internal.Kafka010Fetcher - Committing offsets to Kafka takes longer than the checkpoint interval. Skipping commit of previous offsets because newer complete checkpoint offsets are available. This does not compromise Flink's checkpoint integrity.问题是说在flink执行checkpoint的间隔内,从kafka中拉取到的数据还没有处理完成,导致offset没办法提交,而下一次的checkpoint已经开始了,这样flink会跳过对offset的提交。
分析
我们的场景是业务刷了大量的数据,导致短时间内生产了大量的数据,flink从kafka拉取的第一批还没有处理完成时,下一次checkpoint开始了,此时检查到上一次的checkpoint还未提交就会报这个警告并跳过当前这次checkpoint时对offset的提交。由于kafka中堆积的数据量足够,下一批还是会拉取一批数据在我们这里是500条(外层膨胀后会有几万条),然后仍然会处理超时,长此以往会频繁跳过offfset的提交,在kafka控制台上看到的结果是该消费者对应的consumer Group消息堆积越来越多(实际上是有消费,只是消费得比较慢)。为什么慢?库里同时有大量写入的操作,维表关联的性能急剧下降。这里不讨论维表性能的优化,我们主要基于问题来分析下flink中消费kafka的源码流程。
针对kafka消费的流程,我们来从头分析一下:
Task角度
Task是一个Runnable对象,它的run方法定义如下:
/*** The core work method that bootstraps the task and executes its code.*/@Overridepublic void run() {try {doRun();} finally {terminationFuture.complete(executionState);}}
在它的doRun方法中会真正执行StreamTask的逻辑,StreamTask同时也是AbstractInvokable的子类。Task的doRun方法的部分代码如下:
它会初始化invokable实例并调用invokable的invoke方法。invokable实例是StreamTask类型的。
StreamTask角度
kafka源对应的StreamTask为SourceStreamTask,它的结构为:
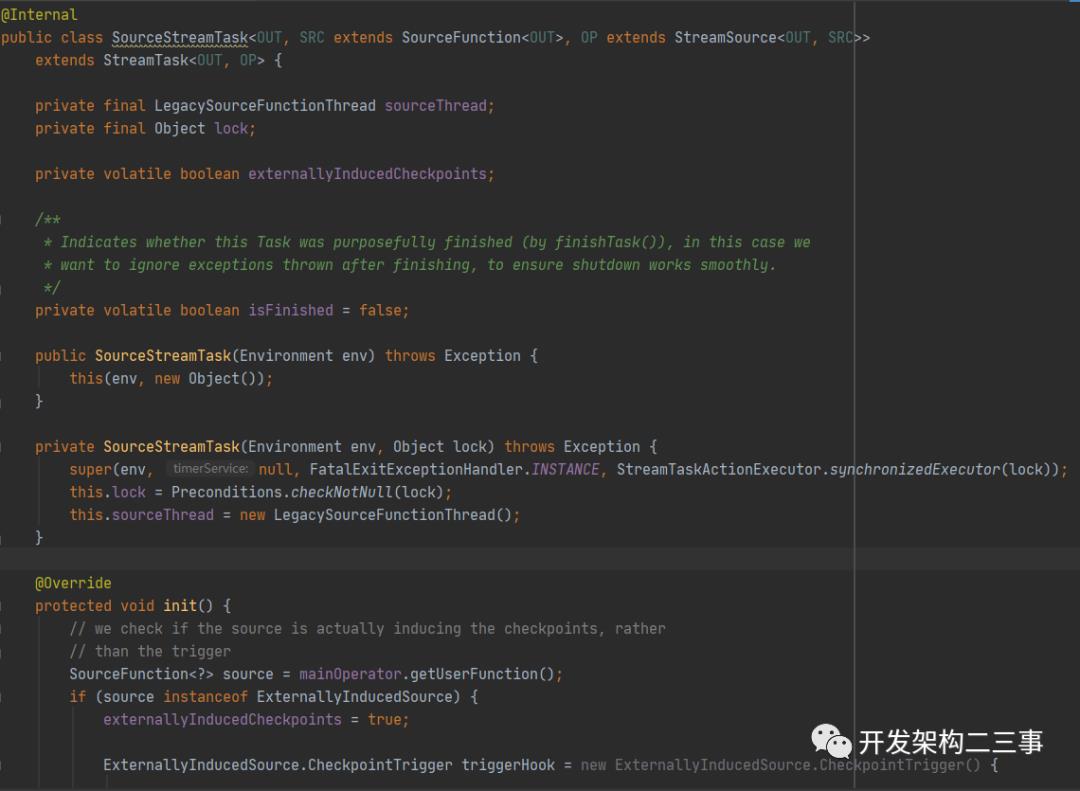
我们来看SourceStreamTask的invokable过程,它的invokable方法为org.apache.flink.streaming.runtime.tasks.StreamTask#invoke:
try {beforeInvoke();// final check to exit early before starting to runif (canceled) {throw new CancelTaskException();}// let the task do its workrunMailboxLoop();// if this left the run() method cleanly despite the fact that this was canceled,// make sure the "clean shutdown" is not attemptedif (canceled) {throw new CancelTaskException();}afterInvoke();}//----------省略部分代码
在这里我们不深究StreamTask的完整的初始化流程,只关注下我们本文要关注的重点,其他内容后面再在专门的篇幅中具体分析。
beforeInvoke方法
我们来看beforeInvoke方法:
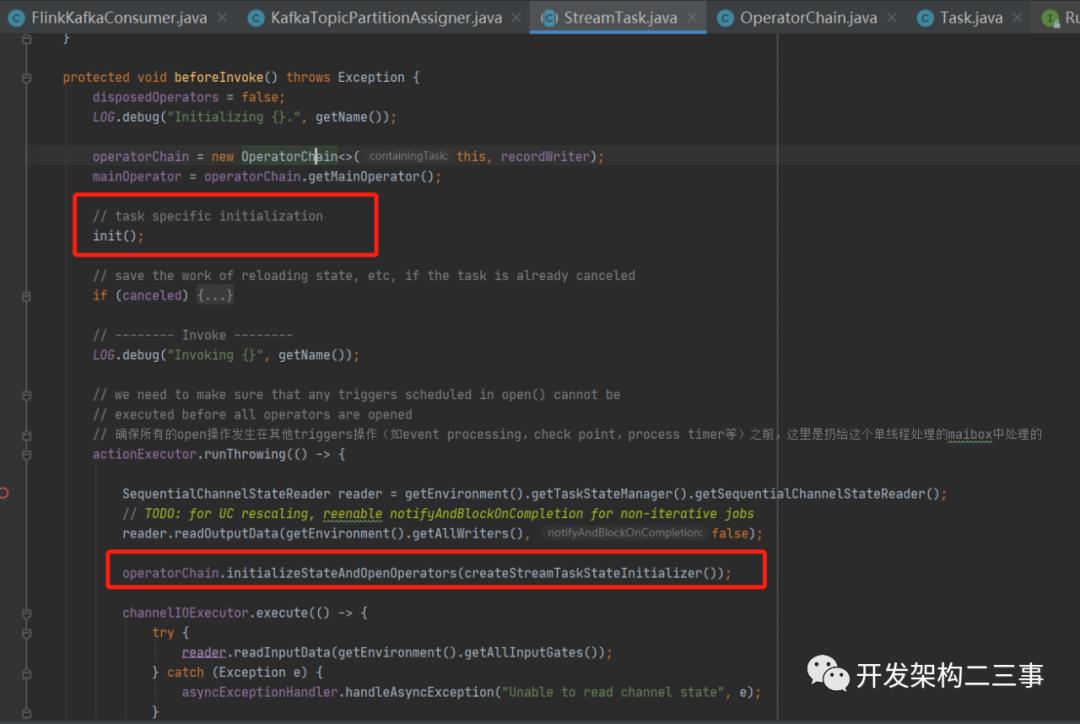
我们主要关注它的两个动作:
•执行SourceStreamTask的init方法。在init方法中主要执行一些和checkpoint和operator的udf相关的信息。•执行operatorChain.initializeStateAndOpenOperators方法。在org.apache.flink.streaming.runtime.tasks.OperatorChain#initializeStateAndOpenOperators方法中主要执行operator的open操作,代码如下:
protected void initializeStateAndOpenOperators(StreamTaskStateInitializer streamTaskStateInitializer) throws Exception {for (StreamOperatorWrapper<?, ?> operatorWrapper : getAllOperators(true)) {StreamOperator<?> operator = operatorWrapper.getStreamOperator();operator.initializeState(streamTaskStateInitializer);operator.open();}}
kafka Source对应的Operator为StreamSource类型的,是AbstractUdfStreamOperator的一个子类,它的open方法代码如下:
@Overridepublic void open() throws Exception {super.open();FunctionUtils.openFunction(userFunction, new Configuration());}
需要注意的是,这个userFunction是FlinkKafkaConsumer的一个实例。FlinkKafkaConsumer是FlinkKafkaConsumerBase类型的,openFunction方法会调用到org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase#open方法,在该方法中会使用partitionDiscoverer获取到分区信息,然后尝试去state中获取,如果restoreState不为空则将partition信息与restoreState进行同步,将放入到subscribedPartitionsToStartOffsets容器中;如果restoreState为空则根据StartupMode来按照相应的模式处理partition列表中的信息。
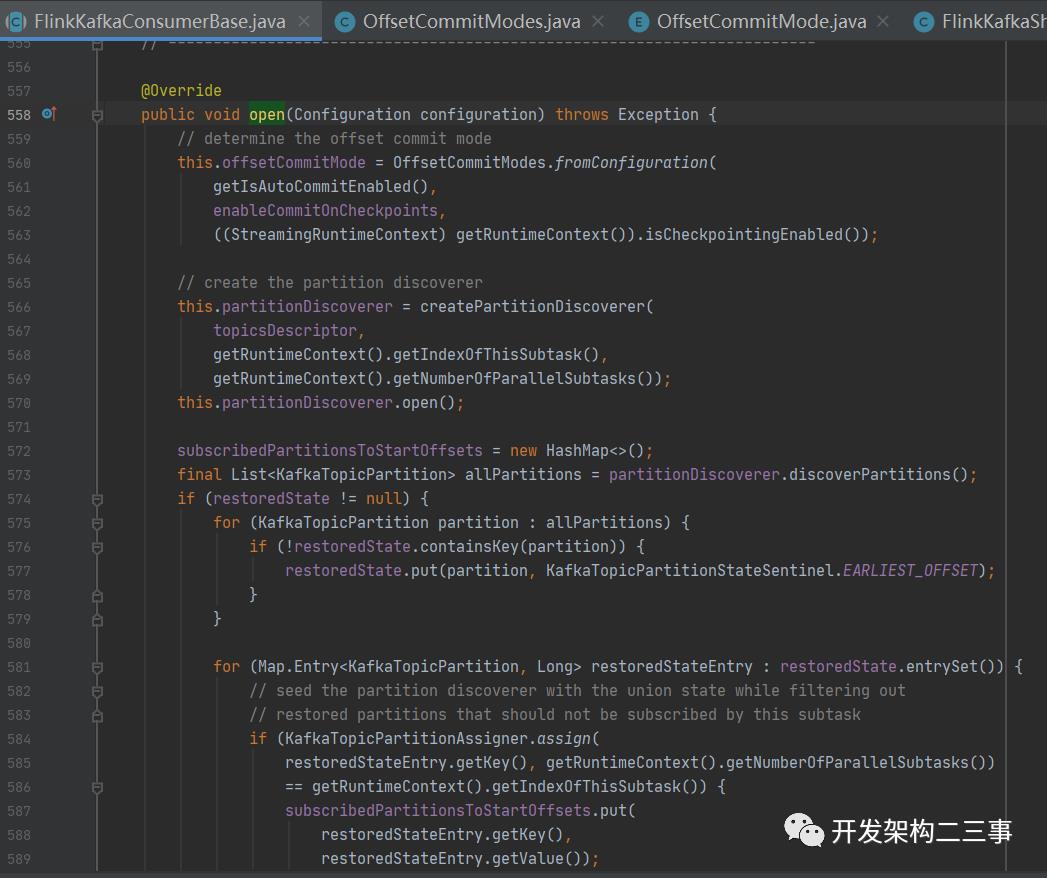
在FlinkKafkaConsumerBase的open方法中还有一点需要注意的是,对于offset的处理逻辑。我们来看下第一行代码:
// determine the offset commit modethis.offsetCommitMode = OffsetCommitModes.fromConfiguration(getIsAutoCommitEnabled(),enableCommitOnCheckpoints,((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled());
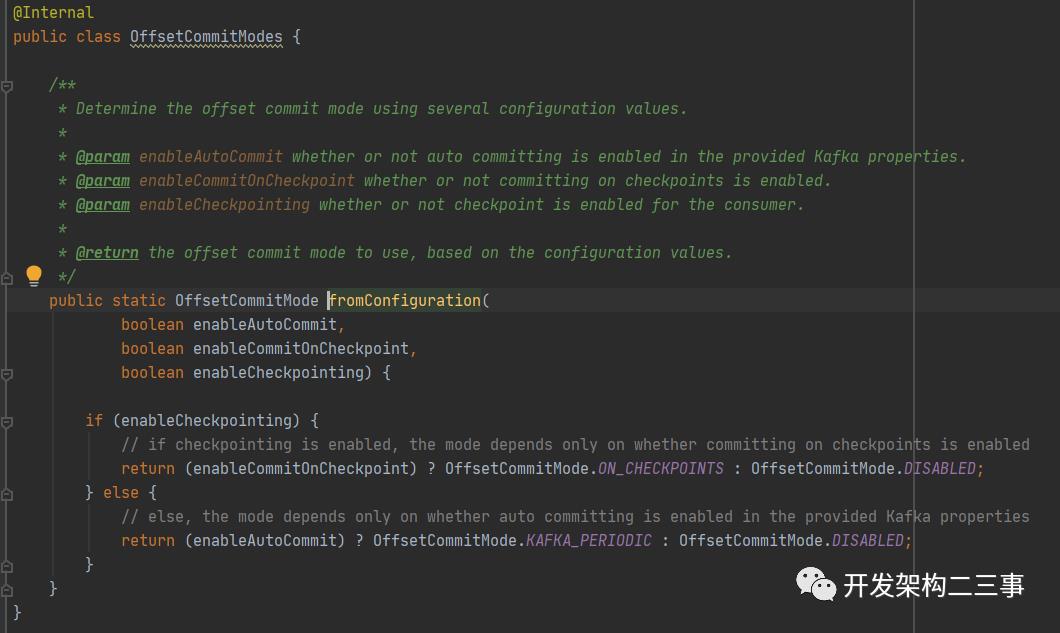
•如果启用了checkpoint,直接通过是否启动了enableCommitOnCheckpoint来决定提交的模式,enableCommitOnCheckpoint默认为true,可以通过org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase#setCommitOffsetsOnCheckpoints方法来修改。如果enableCommitOnCheckpoint为false则不进行offset的提交。•如果禁用了checkpoint,则根据是否启动了自动提交来判断,如果没有启动则不进行offset提交。
runMailboxLoop方法
我们直接来看org.apache.flink.streaming.runtime.tasks.StreamTask#runMailboxLoop代码:
public void runMailboxLoop() throws Exception {mailboxProcessor.runMailboxLoop();}
我们先来看下在StreamTask的构造方法中对mailboxProcessor的定义:
// 创建 mailboxProcessorthis.mailboxProcessor = new MailboxProcessor(this::processInput, mailbox, actionExecutor);
第一个入参为MailboxDefaultAction,第二个入参为一个mailbox队列,第三人入参为线程执行器。其中MailboxDefaultAction对象为lambda表达式。
接下来我们来看org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor#runMailboxLoop方法:
/*** Runs the mailbox processing loop. This is where the main work is done.*/public void runMailboxLoop() throws Exception {// 邮箱final TaskMailbox localMailbox = mailbox;Preconditions.checkState(localMailbox.isMailboxThread(),"Method must be executed by declared mailbox thread!");assert localMailbox.getState() == TaskMailbox.State.OPEN : "Mailbox must be opened!";// 邮箱controller,与processor绑定final MailboxController defaultActionContext = new MailboxController(this);// 当mailbox循环处于运行状态时,会一直消费Mailbox中的message(实际上是一个FIFO的队列)while (isMailboxLoopRunning()) {// The blocking `processMail` call will not return until default action is available.processMail(localMailbox, false);if (isMailboxLoopRunning()) {// 进行 task 的 default action,也就是调用 processInput()// 这里的defaultAction是在StreamTask的构造方法中的this.mailboxProcessor = new MailboxProcessor(this::processInput, mailbox, actionExecutor)中的this::processInput。mailboxDefaultAction.runDefaultAction(defaultActionContext); // lock is acquired inside default action as needed}}}
可以看到在该方法中会先循环执行processMail方法,然后执行mailboxDefaultAction.runDefaultAction(defaultActionContext)方法。这里我们主要关心后者,通过上文我们知道mailboxDefaultAction初始化为一个lambda表达式,在执行runDefaultAction时实际调用的是org.apache.flink.streaming.runtime.tasks.StreamTask#processInput方法。在我们本文的分析中它对应的是org.apache.flink.streaming.runtime.tasks.SourceStreamTask#processInput方法:
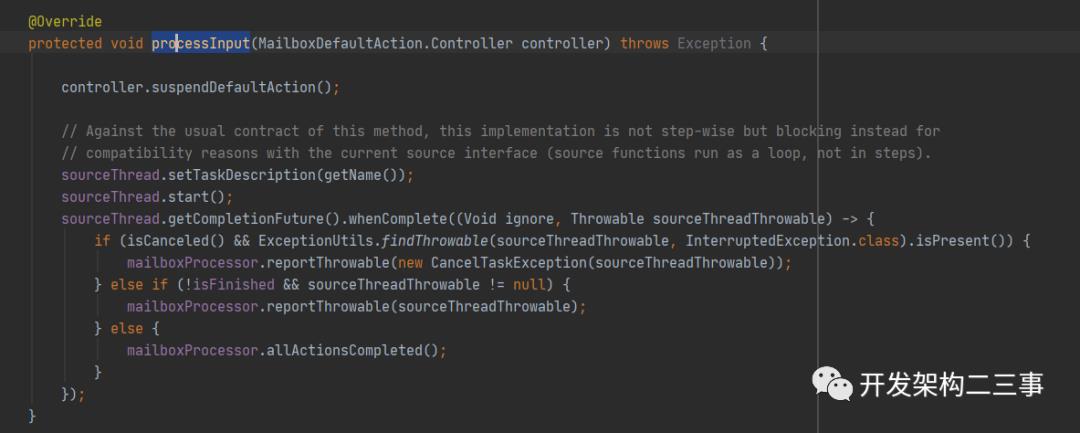
这里会启动sourceThread线程,sourceThread线程为LegacySourceFunctionThread类型的,我们来看下它run方法中的运行逻辑:
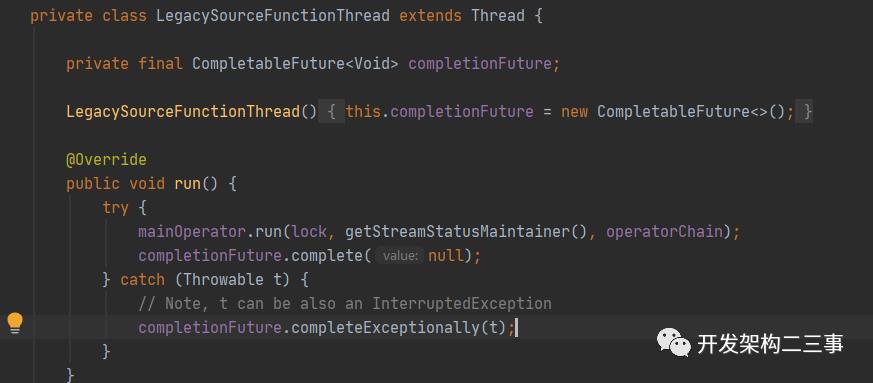
mainOperator的run方法的调用链为:
org.apache.flink.streaming.api.operators.StreamSource#run(java.lang.Object, org.apache.flink.streaming.runtime.streamstatus.StreamStatusMaintainer, org.apache.flink.streaming.runtime.tasks.OperatorChain) 到org.apache.flink.streaming.api.operators.StreamSource#run(java.lang.Object, org.apache.flink.streaming.runtime.streamstatus.StreamStatusMaintainer, org.apache.flink.streaming.api.operators.Output<org.apache.flink.streaming.runtime.streamrecord.StreamRecord
FlinkKafkaConsumerBase的run方法部分代码如下:
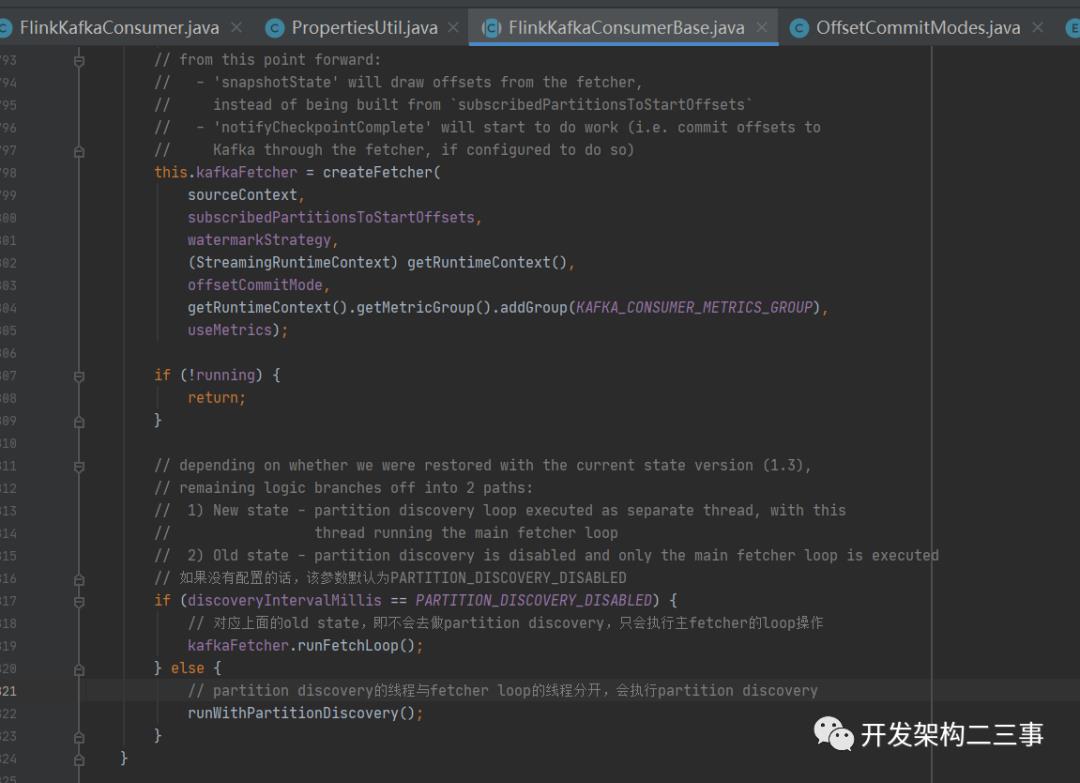
主要有两种操作:
1.创建KafkaFetcher;2.执行KafkaFetcher的loop操作,最多是增加一路partition discovery的操作。
KafkaFetcher
构造方法的部分代码如下:
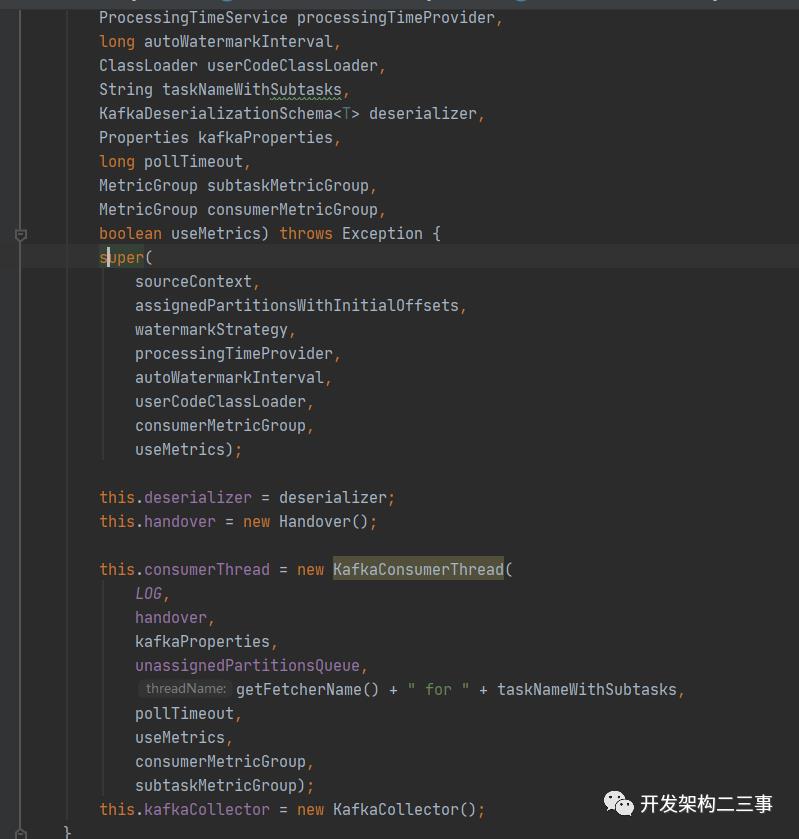
主要的操作是设置上下文信息、watermark信息、checkpoint信息、checkpointLock、类加载器、handover缓存、consumerThread、kafkaCollector等。这里我们来关注下对于consumerThread的初始化操作:
this.consumerThread = new KafkaConsumerThread(LOG,handover,kafkaProperties,unassignedPartitionsQueue,getFetcherName() + " for " + taskNameWithSubtasks,pollTimeout,useMetrics,consumerMetricGroup,subtaskMetricGroup);
这里我们主要关注下unassignedPartitionsQueue,它是在AbstractFetcher中初始化的,AbstractFetcher的构造方法部分代码为:
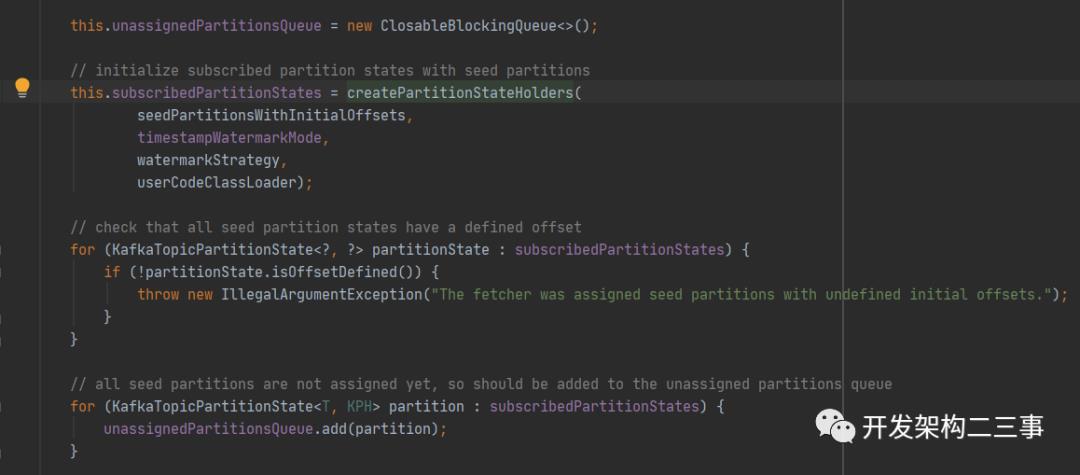
也就是说在初始化Fetcher时会将所有的partition信息放到unassignedPartitionsQueue中,意思是未分配的partition队列。
我们接着来看KafkaFetcher的runFetchLoop方法:
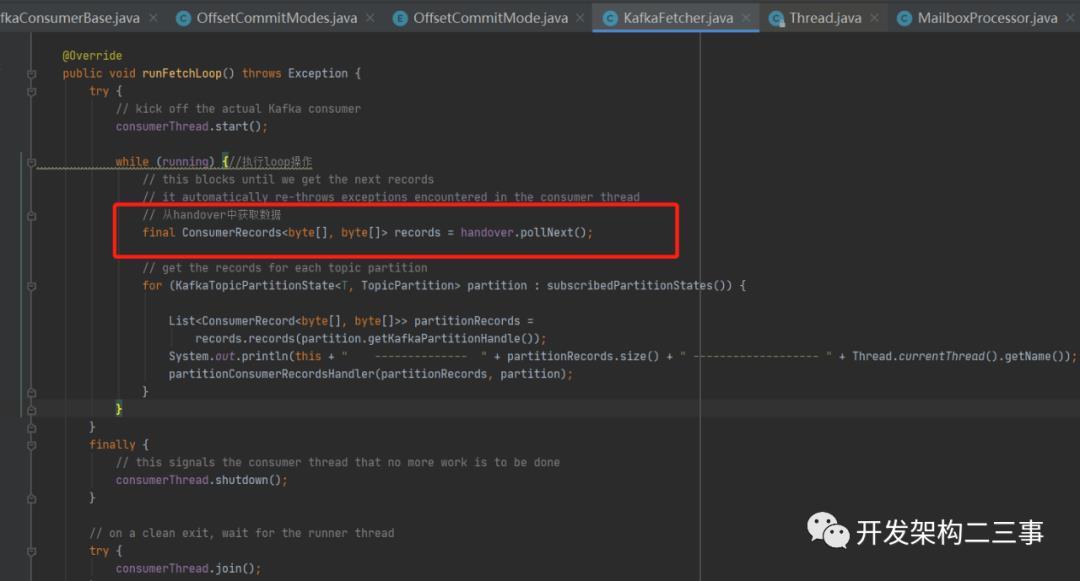
主要操作是启动consumerThread,然后执行loop操作从handover中消费数据。
拉取数据与提交offset的核心逻辑在ConsumerThread中,我们来看对应代码:
1.run方法的初始部分
public void run() {// early exit checkif (!running) {return;}// this is the means to talk to FlinkKafkaConsumer's main threadfinal Handover handover = this.handover;// This method initializes the KafkaConsumer and guarantees it is torn down properly.// This is important, because the consumer has multi-threading issues,// including concurrent 'close()' calls.try {// 获取consumer,每次来获取都是new一个新的KafkaConsumerthis.consumer = getConsumer(kafkaProperties);}catch (Throwable t) {handover.reportError(t);return;}// -------------省略-------
•初始化实例的handover对象;•获取一个新的consumer实例(因为kafkaConsumer是线程不安全的)。
1.fetch loop
// -------省略代码---------------// main fetch loopwhile (running) {// check if there is something to commitif (!commitInProgress) {// 默认为false// get and reset the work-to-be committed, so we don't repeatedly commit the samefinal Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback> commitOffsetsAndCallback =nextOffsetsToCommit.getAndSet(null);if (commitOffsetsAndCallback != null) {// 如果不为空,代表上次的提交没有完成,这里会继续进行异步提交log.debug("Sending async offset commit request to Kafka broker");// also record that a commit is already in progress// the order here matters! first set the flag, then send the commit command.commitInProgress = true;consumer.commitAsync(commitOffsetsAndCallback.f0, new CommitCallback(commitOffsetsAndCallback.f1));}}try {if (hasAssignedPartitions) {// 如果已经分配好分区,查看是否有未分配的partition,分配分区的newPartitions = unassignedPartitionsQueue.pollBatch();}else {// if no assigned partitions block until we get at least one// instead of hot spinning this loop. We rely on a fact that// unassignedPartitionsQueue will be closed on a shutdown, so// we don't block indefinitelynewPartitions = unassignedPartitionsQueue.getBatchBlocking();}if (newPartitions != null) {reassignPartitions(newPartitions);}} catch (AbortedReassignmentException e) {continue;}if (!hasAssignedPartitions) {// Without assigned partitions KafkaConsumer.poll will throw an exceptioncontinue;}// get the next batch of records, unless we did not manage to hand the old batch overif (records == null) {try {records = consumer.poll(pollTimeout);}catch (WakeupException we) {continue;}}try {handover.produce(records);records = null;}//---------省略代码
这个部分需要注意以下几点:
•commitInProgress的状态变化:默认为false,在执行consumer.commitAsync之前会置为true,在consumer.commitAsync操作callback通知后会置为false以便进行下一次的consumer.commitAsync操作;•nextOffsetsToCommit变量的变化点在org.apache.flink.streaming.connectors.kafka.internals.KafkaConsumerThread#setOffsetsToCommit方法中,该方法的调用链路为:
这个发生在notifyCheckpointComplete方法的调用中,也就是说在一次checkpoint完成后会执行setOffsetsToCommit方法。同时这里提一点题外话,这个过程是在processMail中执行的,也证明了flink在处理event processing、Processing-Time的定时器和checkpoint使用mailbox后的改进(题外话,可以参考之前写过的StreamTask线程模型分析的文章)。同时在执行一次consumer.commitAsync操作后会将nextOffsetsToCommit的值置为null。
我们来看下setOffsetsToCommit的一段代码:
// record the work to be committed by the main consumer thread and make sure the consumer notices thatif (nextOffsetsToCommit.getAndSet(Tuple2.of(offsetsToCommit, commitCallback)) != null) {//设置新值,返回老值,老值是否为nulllog.warn("Committing offsets to Kafka takes longer than the checkpoint interval. " +"Skipping commit of previous offsets because newer complete checkpoint offsets are available. " +"This does not compromise Flink's checkpoint integrity.");}
如果执行checkpoint操作时,上一次拉取的数据的offset还没有提交,这里会抛出警告并跳过本次offset的提交。这里需要注意的是consumer每次拉取数据会自己维护offset的变化,不依赖于kafka broker上当前消费者组的offset(如下图所示),但是在consumer重新初始化时会依赖这个。
•newPartitions的初始化,第一次进入时hasAssignedPartitions为false,会依赖unassignedPartitionsQueue.getBatchBlocking()方法进行初始化,并进入reassignPartitions方法进行分区的分配逻辑,将hasAssignedPartitions置为true,后面loop到这段代码时会执行 unassignedPartitionsQueue.pollBatch(),将一些新加入的或者之前分配失败的分区进行分配。•consumer.poll 执行kafkaConsumer的拉取数据的操作。•handover.produce:将数据放入到handover中,这里的数据会被KafkaFetcher中的Loop操作消费掉。
以上是关于flink源码分析之kafka consumer的执行流程的主要内容,如果未能解决你的问题,请参考以下文章