Linux Shell三剑客之Grep
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux Shell三剑客之Grep相关的知识,希望对你有一定的参考价值。
假设有一个文件(或一堆文件),并且想要在这些文件中搜索特定的字符串或配置关键字。Windows下,你可能会打开这些文件用搜索框(CTRL+F)输入关键字点搜索,这很麻烦而且还不能随心所欲的搜。在Linux就不同了,我们可以用Grep,可以用正则表达式随心所欲的搜,不仅可以搜一个文件,还可以搜一堆文件。搜索的入口和出口可以对接上管道,搜索别的工具的结构或者把搜索结果传递给其他工具用。

今天我们就来讲Linux Shell下的文本处理三剑客之Grep。为了了解其用法最简便方法是使用系统帮助和man:
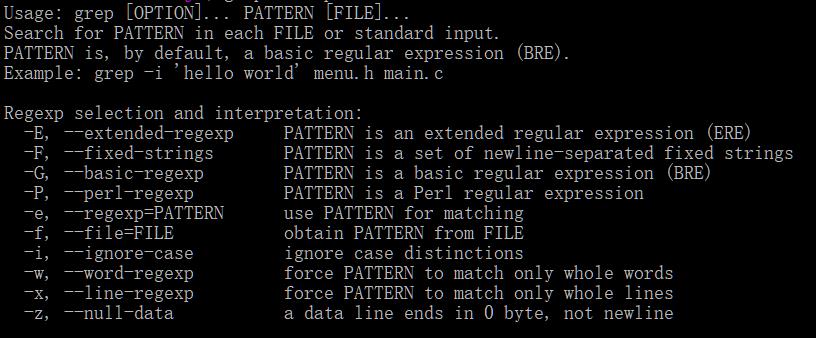
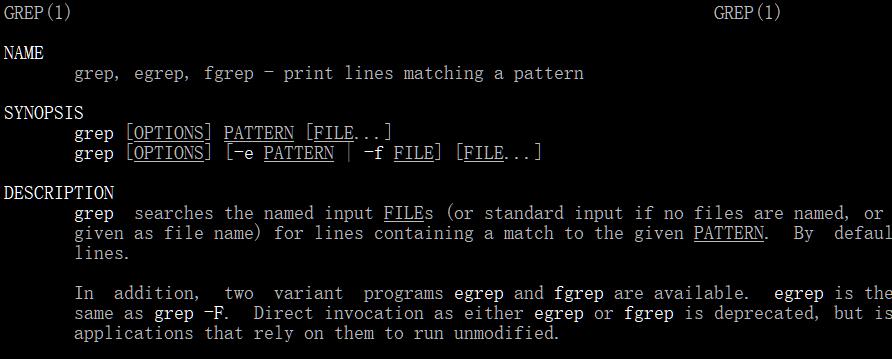
其中man的比较详细,来自于其帮助手册,在linux(centos为例)下查询内置命令帮助手册的方法是用rpm -qd grep
-q表示查询;-d表示列出其文档(document):
rpm -qd grep
grep基础
在开始之前,我们以centos自带的字典文件为范例,该文件位于/usr/share/dict/words
wc /usr/share/dict/words
479829 479829 4953699 /usr/share/dict/words
文件包含48万个单词,一行一个单词,由centos的word包提供。grep 也有一个-c(--count)选项对搜索匹配的行进行统计,我们先来用他来统计下它的单词树
grep --count '.' /usr/share/dict/words
479829
这和wc的结果一样。
搜索中我们制定了模式为".",表示搜索包含至少一个字符,空格,空格,制表符等的行。
grep正则表达式基础
grep最重要两个优点:一个是搜索相当快,一个是支持正则表达式(RE,regexes)。正则表达式让grep变得更强大。所以我们首先要介绍下正则表达式基础。
开头
假设我们想搜以C开头单词,我们需要要使用正则模式的开头模式:(^)加一个开头字符。比如:
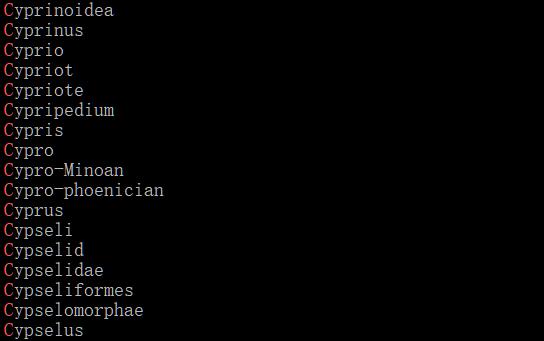
结尾
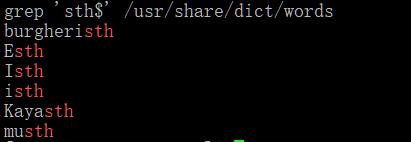
要搜索以特定字符结尾的模式,使用符号($)表示字符串的结尾。比如要搜索以sth结尾的单词
grep 'sth$' /usr/share/dict/words
其他RE模式
正则表达式语法很复杂,而且各个系统可能略有差异,具体需要参考对应文档,grep中常用的语法还有:
. 表示单个字符
* 表示其之前字符出现0次或者多次,比如.*表示任意字符。
+ 表示其之前字符出现1个或者多个。注意这个只在强化的egrep或者grep -E下可用。基本grep下要用\\+
? 表示其之前字符出现0个或者一个。基本grep下要用\\?
{}表示之前字符出现的次数限定,比如:{n} n次,{n,m}n到m次,{n,}至少n次,{0,m}最多m次。grep下要用\\{n\\}
[a-z] [0-9] 表示a~z,0~9的范围。
[^] 取反,表示匹配除了范围之外的模式。
\\<, \\b: 词首,\\>, \\b:词尾。
() 表示分组。基本grep下要用\\(\\)。
| 表示逻辑或,匹配多个表达式的任何一个。基本grep下要用\\|
清除注释(-v)
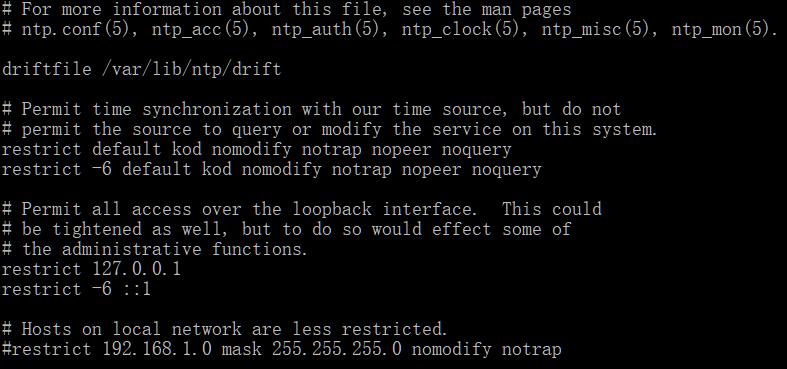
前面初窥grep的门道,我们接着以一些实例来说明写grep的具体应用。我们知道在linux下很多配置文件都包含了大量的注释(#开头的行),解释很详尽,但是一般我们不愿去仔细了解,所以希望浏览时候去除掉。我们以ntp.conf为例:
cat /etc/ntp.conf
grep 的-v选项表示排除模式,表示显示所有不匹配的内容,比如要去除ntp.conf中的注释我们使用:
grep -v '^#' /etc/ntp.conf
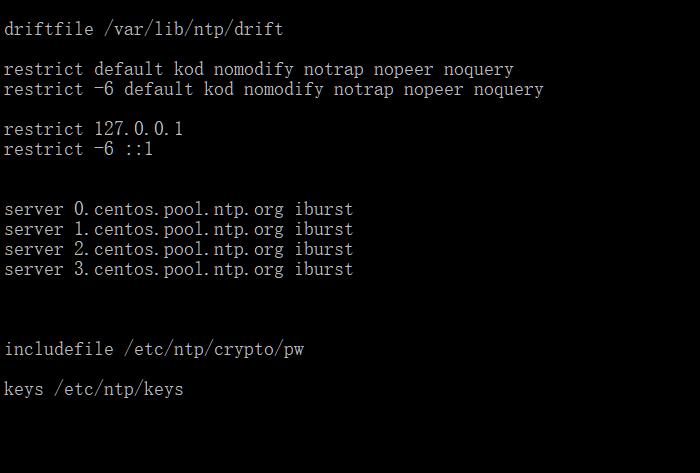
上面所有注释行都用空行了,显示清晰了一点,但是看着也有点别扭,不是吗?
那我们就想办法去掉空行,方法也简单就是用管道对接到另一个grep,再去除掉空行($)
grep -v '^#' /etc/ntp.conf |grep -v '^$'
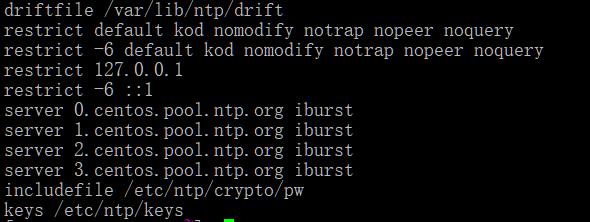
OK,这下清爽多了。
仅输出/et /passwd用户名(-o)
为了演示grep的功能和正则表达式的用法,我们需要解析/etc/passwd文件并仅打印用户名。
cat /etc/passwd
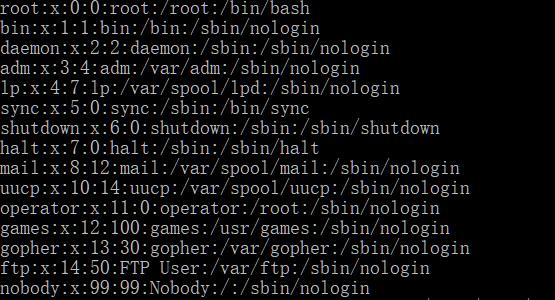
文件中各行的字段具体含义:
<name用户名>:<明码密码,现在都为x表示在shadow加密保存>:<UID>:<GID>:<GECOS用户备注信息>:<用户目录>:<shell>
为了仅输出用户名,可以使用如下查询
grep -o '^[a-zA-Z_-]\\+' /etc/passwd

在上面的grep命令中,我们使用了grep -o(--only-matching)选项,表示仅显示匹配<PATTERN>的行那部分。
显示临近行(-C,-A,-B)
我们在查看日志时候,有时不能只看匹配的行,而需要上下文信息。grep也提供了这样的功能,显示匹配行之前或者之后的行。这在故障排查过程中非常有用,你再也不需要打开文章,定位,然后再看上下文了。
-C n 表示打印匹配行及前后n行的信息。此处-C可以省略,用-n
-A n表示打印匹配行及之后n行的信息。
-B n表示打印匹配行及之前n行的信息。
比如我们搜索tomcat catalina.out日志中的严重错误,可以用:
grep 'SEVERE: Error' catalina.out
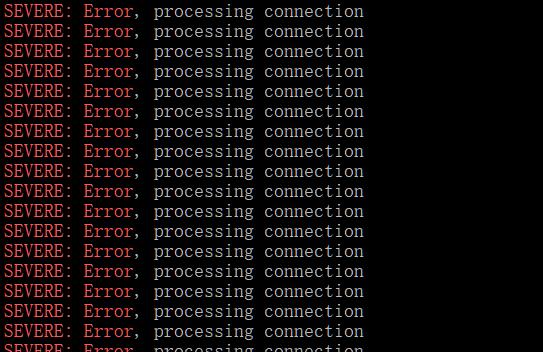
由于缺乏上下文,具体信息无法获取。这时候就可以使用-C
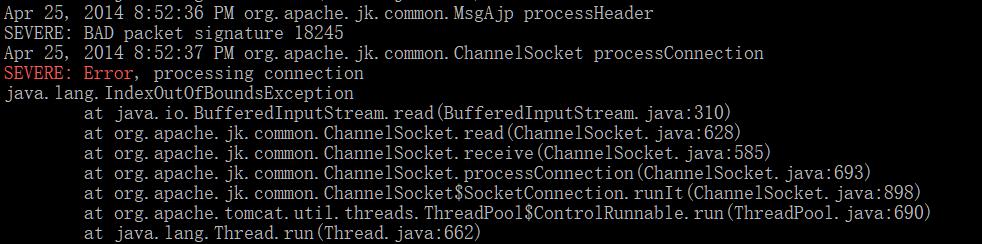
grep -20 'SEVERE: Error' catalina.out
这样可以获取完成错误信息进行错误定位:
搜索二进制文件(-a)
grep 是一个文本三剑客之一,但是文本剑客并不意味着他就只能处理文本文件了。实际上对二进制文件也是可以的。这就是grep的-a(--binary-files=text)选项,可以对二进制的文本进行搜索和显示。这在安全领域很有用,比如有时候需要对某些文件判断是否有害,是否有木马,可以简单用grep搜索其特征即可。我们举个例子比如,对一个java class文件x.class,我们用javap解析这个类文件
javap x.class
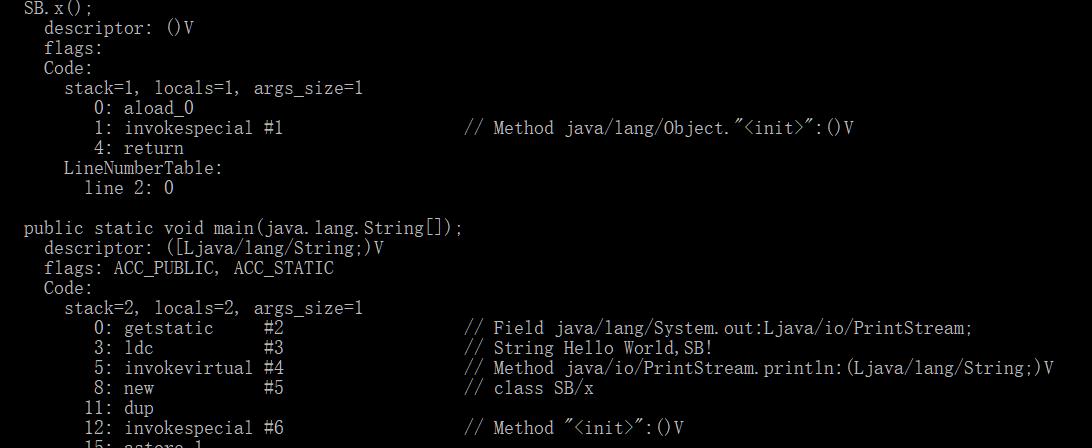
我们用grep –a查看:
grep -a '.' x.class
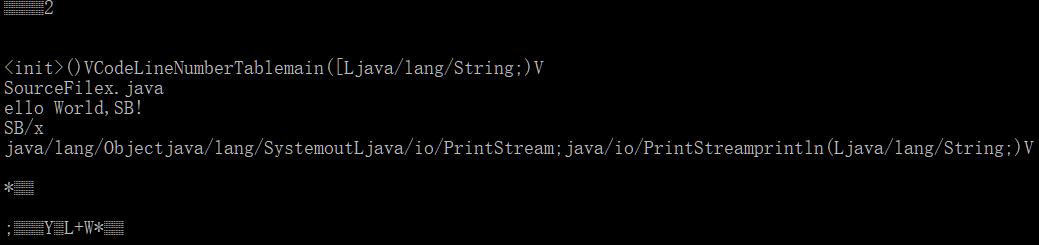
有World,我们用他做关键字搜索
grep -ia 'world' x.class
就能搜到结果:
ello World,..
java/lang/Objectjava/lang/SystemoutLjava/io/PrintStream;java/io/PrintStreamprintln(Ljava/lang/String;)
注意上面用了-i选项,表示忽略大小写,也是常用的grep选项之一。
总结
本文我们介绍了Linux下的shell三剑客之一,文本搜索神器grep,希望能对大家有所帮助。其他两个剑客是流式文本处理工具sed 和awk语言,以后有机会我们再做介绍。
以上是关于Linux Shell三剑客之Grep的主要内容,如果未能解决你的问题,请参考以下文章