想学Python就一定要知道的十个爬虫框架集合
Posted 日常分享Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了想学Python就一定要知道的十个爬虫框架集合相关的知识,希望对你有一定的参考价值。

Python爬虫框架的优点真是说也说不完,它可以让程序员以更少的代码实现自定义功能,还可以将更多的精力集中在业务逻辑上,更加的轻松便利。因此本文将为大家推荐十款常见且好用的爬虫框架。
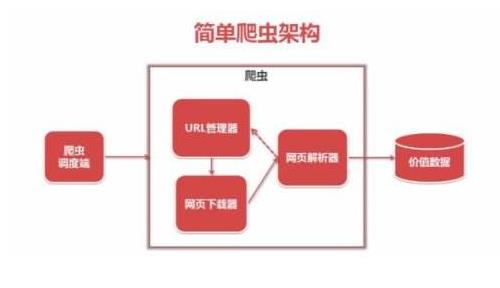
一、Scrapy

Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
二、PySpider
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
1、安装pyspider:pip3 install pyspider
2、安装Phantomjs:在官网下载解压后,并将pathtomjs.exe拖进安装python路径下的Scripts下即可。
下载地址:https://phantomjs.org/dowmload.html
官方API地址:http://www.pyspider.cn/book/pyspider/self.crawl-16.html

三、Crawley
Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
四、Portia
Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
五、Newspaper
Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。

六、Beautiful Soup
Beautiful Soup 是一个可以从html或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
七、Grab
Grab是一个用于构建Web刮板的Python框架。借助Grab,您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网络请求和处理接收到的内容,例如与HTML文档的DOM树进行交互。

八、Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。
九、selenium
Selenium 是自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果在这些浏览器里面安装一个 Selenium 的插件,可以方便地实现Web界面的测试. Selenium 支持浏览器驱动。Selenium支持多种语言开发,比如 Java,C,Ruby等等,PhantomJS 用来渲染解析JS,Selenium 用来驱动以及与 Python 的对接,Python 进行后期的处理。

十、Python-goose框架
Python-goose框架可提取的信息包括:
文章主体内容
文章主要图片
文章中嵌入的任何Youtube/Vimeo视频
元描述
元标签
以上就是十款十款Python爬虫框架大推荐 ,希望可以帮助大家在工作中更加方便高效。


以上是关于想学Python就一定要知道的十个爬虫框架集合的主要内容,如果未能解决你的问题,请参考以下文章