Mysql中随机查询数据的几种算法
Posted IT菜佬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql中随机查询数据的几种算法相关的知识,希望对你有一定的参考价值。
有这样一个需求,需要随机在数据库中选择一条(或多条)数据,刚开始觉得很简单,研究后发现学问很多。
首先,数据库主键使用雪花算法生成,其有如下性质:
-
「全局唯一性」 -
「递增性」 -
高可用性 -
高性能性
数据表结构
mysql> desc t_words;
+-----------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+-------------------+-----------------------------+
| id | bigint(25) | NO | PRI | NULL | |
| content | varchar(500) | NO | | NULL | |
| tags | varchar(50) | YES | | | |
| timestamp | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-----------+--------------+------+-----+-------------------+-----------------------------+
4 rows in set (0.00 sec)
方式一
select * from t_words order by RAND() limit 1;
这种方式借鉴了mysql官方文档中提供的方式:
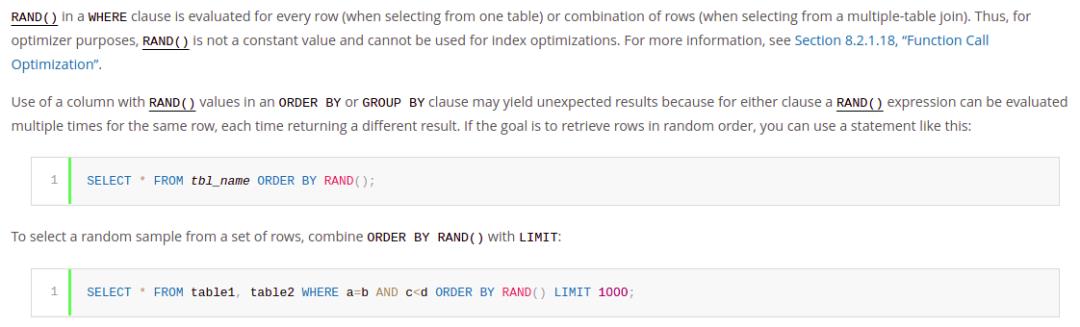
官方提示说这种语法会导致非预期的结果,也就是说每次的结果都是随机的。
使用explain看一下:
explain select * from t_words order by RAND() limit 1\G
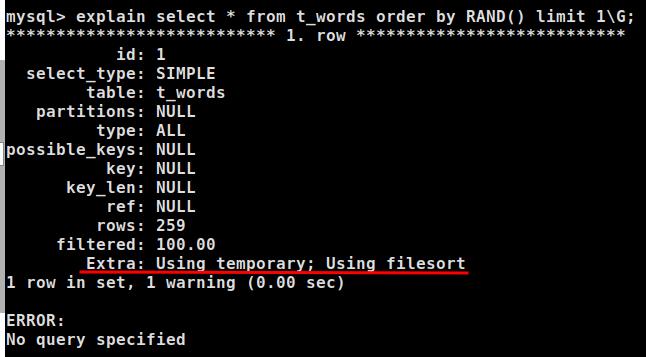
这种方式的的原理是:mysql会把所有数据都查出来,同时会为每一行数据生成一个介于[0-1]的随机浮点数,然后再根据这个浮点数将所有数据排序,最后取出前几条数据。
显然,这种方式虽然简单,但是非常耗时,因为它不能被索引优化,并且受数据体量的影响,因为每次都会取出所有数据,性能受限。
方式二
使用LIMIT子句
-
先查出所有记录数 total
SELECT count(*) AS total FROM t_words;
-
查出[0-total]之间的一条记录
SELECT * FROM t_words LIMIT [0-total], 1;
LIMIT第一个参数可以是0~total之间的一个随机整数,这个整数可以通过应用程序生成,生成后再请求一次查询结果。
这种方法的优点在于没有使用ORDER BY语句,避免了排序的过程,且第二步可以数据库引擎可以使用索引优化,性能上有一定提升。
缺点是要发两次请求,且需要编写额外代码,有一定复杂度和工作量。
刚开始笔者考虑直接使用一条SQL语句把数据查出来,就是在LIMIT语句的第一个参数中使用子查询,在使用RAND()函数生成一个[0-total]之间的随机值,但是一直报语法错误。查阅官方文档发现,LIMIT子句必须接收整型「常量」。所以没办法,必须分成两步,额外编写代码。其实这种方法性能上非常可以了,相关代码量也没多少。

方式三
SELECT tw.* FROM t_words AS tw JOIN (SELECT ((1/COUNT(*))*100) as n FROM t_words) as x WHERE RAND()<=x.n ORDER BY RAND() LIMIT 1;
这种方式使用数学思维,第二个子查询计算根据数据总数计算每一行出现的概率,乘以100防止结果过小,WHERE条件中使用RAND()函数筛选出随机值小于概率的数据,最后再根据RAND()函数排序。这种方式优点在于随机性比较强,使用了两次RAND()函数,结果跟数据总数相关。缺点主要有两个:
-
在一定条件下,查询的结果总数可能不能满足
LIMIT指定的数目例如在笔者测试表中总共有259条数据,
LIMIT 100的话很可能只有90多条的样子。image-20210512154309953 -
从下图(WorkBench的Visual Explain)可以看出在
ORDER BY子句中还是使用了临时表和文件存储,当数据总数过多时是还是会性能受限
其它
还有其他方法,例如使用MAX(),MIN()函数等,不过都大同小异了。
参考资料
-
https://www.jianshu.com/p/f80df9ab2164 -
https://dev.mysql.com/doc/refman/5.7/en/mathematical-functions.html#function_rand -
http://mysql.taobao.org/monthly/2017/03/05/
以上是关于Mysql中随机查询数据的几种算法的主要内容,如果未能解决你的问题,请参考以下文章