面试官:这些错误都没见过,还敢说会安装Elasticsearch?
Posted 双子孤狼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:这些错误都没见过,还敢说会安装Elasticsearch?相关的知识,希望对你有一定的参考价值。
面试官:这些错误都没见过,还敢说会安装Elasticsearch
前言
随着互联网的普及,数据爆炸式的增长,传统的关系型数据库在快速搜索的性能上面已越来越无法满足要求,比如我们输入一个关键词,需要实现分词和高亮等功能,传统关系型数据库的 like 搜索不光从功能上还是从速度上均无法满足要求。当然,现在有些传统关系型数据库也支持全文索引检索(如 mysql),但是这却依然无法满足需求,所以我们就越来越需要一个专业的搜索引擎来处理搜索功能,以达到快速搜索和分析数据的目的。
什么是 Elasticsearch
Elasticsearch 是一个基于 Apache Lucene 的分布式搜索引擎,其核心功能可以用两个词来概括:搜索(search)和分析(analysis)。
Elasticsearch 为所有的数据类型提供了近乎实时的搜索和分析功能。无论数据类型是结构化文本还是非结构化文本,数字类型或者地理数据类型等,Elasticsearch 都能高效的进行存储,并且以一定的方式构建索引来实现快速搜索。而且因为其天生的分布式特性,数据量增大的同事,部署也可以无缝升级。
聊聊 Apache Lucene
Apache Lucene 是一个高性能、全功能的文本搜索引擎库,是一款非常优秀的,成熟的,开源的,免费的全文索引检索工具包,其诞生的使命就是提供全球级的全文搜索。
Lucene 的原作者是 Doug Cutting,最初采用的是 Java 语言编写,在 2001 年的时候,Lucene 有了一定的用户基础,作者将其捐献给了 Apache。慢慢的,Apache Lucene 也发展出了 C++ ,C#,Python 等语言版本。
Apache Lucene 有着非常活跃的社区,而且因为其开源,并且已经非常成熟,所以除 ElasticSearch 之外,Solr 也是基于 Apache Lucene 实现的搜索(可以类比一下 MySQL 的存储引擎,Lucence 相当于查询引擎层,而 ElasticSearch 和 Solr 就相当于 MySQL 的服务层)。
常见名词
初次接触 Elasticsearch 的朋友可能会对其中的一些名词感到陌生,接下来我们就以关系型数据库为对比来解释一下 Elasticsearch 当中常见的名词。
- 索引(index):相当于关系型数据库中的数据库。
- 映射类型(mapping type):相当于传统数据库中的表,这个在 7.x 版本中已经被标注过期,在未来的 8.x 版本中将不再支持。
- 文档(document):相当于关系型数据库中的一行数据。
- 域(field):相当于关系型数据库中的字段。
- 映射(mapping):相当于传统数据库中的建表语句,可以设置一些列中的数据类型及其他一些特性,如果不设置
mapping,则会默认创建。
为什么移除 mapping type
移除 mapping type 主要有两个原因:
- 将映射类型类比为数据库中的表并不准确,因为在传统的关系型数据库中,不同表中如果存在两个同名字段,那么这两个也是毫无关系的(从存储角度,不考虑逻辑上的关系),但是在
ElasticSearch中,在同一个index中,不同的mapping type中,假如存在两个同名字段,那么其底层的Lucence都是用同一个字段进行存储。也就是说,同一个索引中不同映射类型中的同名字段必须具有相同的mapping(数据结构定义)。这种情况在某些场景下可能会导致冲突的情况发生。 - 在同一个
index中存储很少或没有共同字段的不同mapping type会导致数据稀疏,并影响Lucene有效压缩文档的能力,这也是更重要的一个原因。
没有了 mapping type 那么我们在使用的时候就可以将不同的数据类型定义成不同的 index 来区分,而不是通过 mapping type 来区分,这种做法也有两个优点:
- 数据更可能是密集的,因此可以更好的利用
Lucene中使用的压缩技术。 - 全文索引中用于评分的统计可能会更为准备,因为在相同索引的所有文档都属于同一个实体。
Elasticsearch 的安装和配置
关于 Elasticsearch 的安装非常简单,基本上下载下来就可以直接启动了,相关版本的下载链接可以点击这里。需要注意的是 Elasticsearch 对 Java 的要求是至少要 1.8 版本以上,而且启动的时候不能使用 root 用户启动,必须创建一个其他用户。
下载好 Elasticsearch 之后,其主目录就是 ES_HOME 目录:
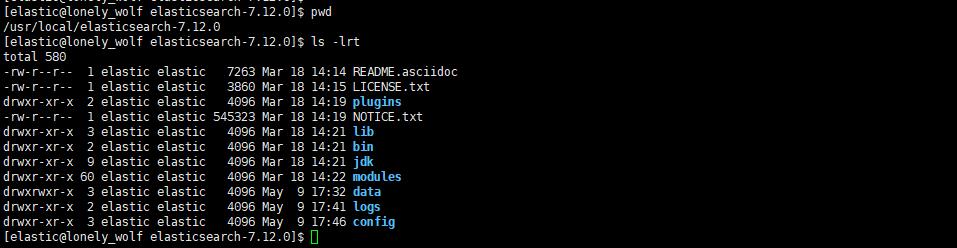
如果是通过 tar.gz 或者 zip 格式安装,那么默认配置文件在 $ES_HOME/config 目录,此时可以通过设置环境变量 ES_PATH_CONF 来修改配置文件的默认路径。config 目录中主要有以下三个配置文件:
- elasticsearch.yml:搜索相关配置。
- jvm.options:
jvm相关配置。 - log4j2.properties:日志相关配置。
你必须知道的配置
使用 Elasticsearch,有一些配置比较关键,需要知道如何配置,下面就介绍一些非常重要的配置信息。
配置 data 和 log
配置 data 或者 log 目录,使用如下配置(不配置则默认目录为 $ES_HOME)
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
其中 data 目录支持多个,如果要配置多个目录,可以使用如下配置:
path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3
配置集群名称(cluster name)
如果使用了 Elasticsearch 集群的话,那么就必须要配置集群名字(默认集群名字为 elasticsearch),集群名字需保证唯一:
cluster.name: logging-prod
配置节点名(node name)
节点名字非常重要,包含在了许多 API 调用的结果 Response 中,如果不配置节点名,那么在启动时,默认使用当前服务器的主机名作为节点名:
node.name: prod-data-2
配置网络 ip
和大部分中间件一样,如果不配置网络 ip,那么默认只有本机可以访问,如果想要其他机器可以访问,则需进行以下配置:
network.host: 192.168.1.10
如果需要对所有机器都可访问,那么可以直接配置为 0.0.0.0。
不过需要注意的是,一旦配置了 0.0.0.0 或者其他外网地址(non-loopback address),此时 Elasticsearch 会从开发模式到生产模式,那么这时候就会强制开启启动检查,所以此时就会报错(未配置前即开发模式只是警告,可以启动成功):
bootstrap check failure [1] of [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
本地回环地址
non-loopback address 即本地回环地址,本地回环地址指的是以 127 开头的 ip 地址,大部分情况下都会将本地回环地址指向 127.0.0.1(ipv6 中则等价于 ::1),同时再指向 localhost,所以在部分人的认知里 127.0.0.1 等价于 localhost。实际上回环地址不一定是 127.0.0.1,而 127.0.0.1 也不一定等价于 localhost,这些都要看具体配置。
发现集群信息配置
上面我们提到,当我们将 network.host 配置成一个非本地回环地址时,Elasticsearch 就会切换到生产模式,切换到生产模式之后就必须要配置一些集群相关参数。
配置 discovery.seed_hosts
在默认情况下,Elasticsearch 无需任何网络配置,开箱即用。因为 Elasticsearch 在启动的时候,会自动搜索本机 9300 到 9305 端口服务,并尝试连接组成集群。这种模式并不安全,所以当我们开启外网的时候,就会切换到生产模式,此时需要使用静态配置来发现集群主机,即通过 discovery.seed_hosts 指定集群 ip 或者域名(当省略端口时,则端口默认为 9300,当使用 ivp6 时,需使用 [])。
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
- [0:0:0:0:0:ffff:c0a8:10c]:9301
需要注意的时,如果使用域名,当域名解析出多个 ip 时,Elasticsearch 会尝试连接所有 ip。
配置 discovery.seed_providers
在上面配置 discovery.seed_hosts 过程中,如果集群中的有资格成为 master 节点的节点(是否有资格成为 master 节点通过 node-master:true 参数控制)没有固定的名称或地址,则可以使用 discovery.seed_providers 提供程序动态查找它们的地址。这个查找方式也可以分为两种,在这里不展开介绍,后面介绍集群的时候会再介绍。
配置 cluster.initial_master_nodes
当首次启动 Elasticsearch 集群时,集群会确定第一次选举中有资格成为 master 节点的投票数,而在开发模式中,如果没有 discovery 相关配置,那么这个步骤就会由 Elasticsearch 自己自动执行,而这种自动执行模式本身又是不安全的,所以在生产模式下启动新集群时,必须显式列出所有有资格成为 master 的节点,这些节点的投票应该在第一次选举中被计算。
PS:这里配置的节点名必须和上面的 node.name 保持一致。
启动
经过上面的解释,因为我这边是单机,所以我们只需要修改如下配置:
network.host: 0.0.0.0
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
修改完配置后,进入到对应的 bin 目录,执行 ./elasticsearch 就可以启动,如果要在后台启动,则可以执行命令 ./elasticsearch -d 命令。
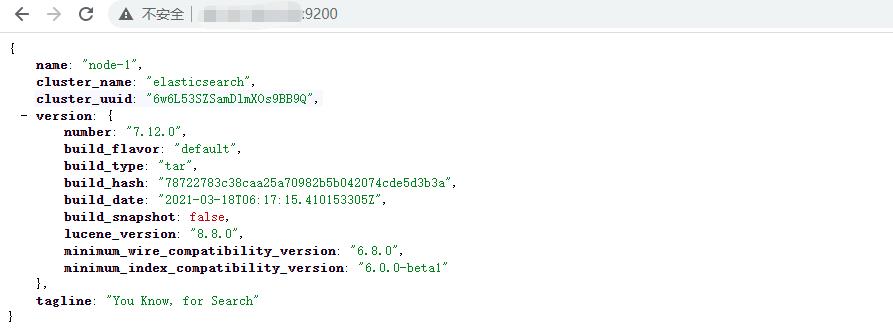
启动之后,默认端口 9200,访问 http://ip:9200 出现如下信息则说明启动成功:
启动中其他错误
在启动过程中,如果没有修改过 max_map_count,那么还会出现如下错误:
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
这是因为 Elasticsearch 默认使用一个 mappfs 目录来存储索引。而操作系统默认情况下对 mmap 计数的限制太低,可能会导致内存不足异常(如果使用 RPM 等格式安装会自动修改)。
在 Linux 系统中,可以使用 sysctl -w vm.max_map_count=262144 进行修改,修改之后可以执行 sysctl vm.max_map_count 进行确认是否生效。或者可以执行命令 vim /etc/sysctl.conf 进入编辑修改,修改之后执行 sysctl -p 命令使之生效。
总结
本文主要介绍了什么是 Elasticsearch 及其底层搜索引擎 Apache Lucene 的发展历史,最后介绍了 Elasticsearch 的一些主要配置参数,通过这些参数我们也可以了解到 Elasticsearch 的一些特性,相信通过本文,大家已经对 Elasticsearch 有了一个模糊的印象,下一篇,将会介绍 Elasticsearch 的基本使用。
以上是关于面试官:这些错误都没见过,还敢说会安装Elasticsearch?的主要内容,如果未能解决你的问题,请参考以下文章
SPI都不知道?还敢说懂Dubbo?面试官怼的我哑口无言啊!!!