面试官对数据库问得这么详细!Redis的AOF和RDB持久化方式看一篇就够了!
Posted Charzous
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官对数据库问得这么详细!Redis的AOF和RDB持久化方式看一篇就够了!相关的知识,希望对你有一定的参考价值。
目录
小C今天刚好去面试,面试一开始,面试官直接问:看你写了熟悉Redis数据库,那具体讲讲它的持久化方式有哪些?
然后,小C没想到这么快,直接进入面试……那就来吧!
一、Redis的持久化方式了解哪些?
答:哦哦,Redis支持AOF持久化(Append Only File)和RDB持久化(Redis DataBase)两种机制,持久化功能很好地避免进程结束导致数据丢失的问题,所以持久化对于数据恢复还原非常重要!
所以,下面会对两种机制分别具体介绍,简单易懂!
二、AOF持久化实现原理是怎么样的?
答:AOF持久化通过保存Redis数据库服务器的写命令来记录数据库状态,是Redis持久化主流方式,保证数据持久化实时性。我画个简单直观图给你看:
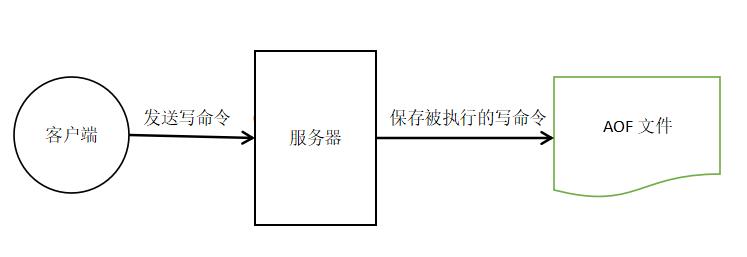
1、持久化实现
AOF持久化主要功能的实现有3个步骤:命令写入、文件同步、文件重写,当然,数据恢复时候有一个重启加载步骤。
命令写入:因为Redis的命令请求协议是纯文本格式,所以写入AOF文件的命令都是以文本格式保存的。
要看看效果,我在redis.windows.conf配置文件开启了AOF持久化,另外默认开启的是每秒进行一次文件同步。

然后执行几条命令
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379> set name Charzous
OK
127.0.0.1:6379> set age 21
OK
127.0.0.1:6379> set phone 123
OK
127.0.0.1:6379>打开appendonly.aof文件,可以看到确实是保存每一条执行的命令,select命令指定数据库是服务器自动添加的。
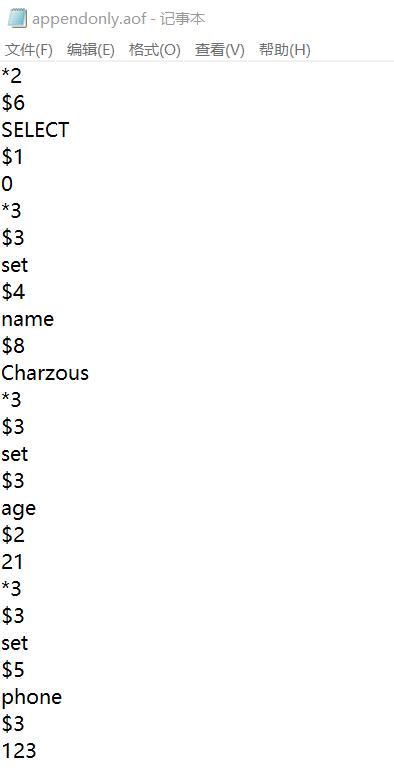
文件同步:Redis服务器的事件循环负责接收客户端的命令请求,首先会写入aof_buf缓冲区,然后根据同步选项值将缓冲区的数据同步到硬盘上。
AOF缓冲区同步策略,由参数appendfsync控制,配置值包括:
1、always:命令写入缓冲区后调用系统fsync操作同步到aof文件,完成后线程返回
2、everysec:默认配置,兼顾性能和安全。命令写入缓冲区后调用系统write操作,完成后线程返回。fsync同步文件操作有专门线程每秒调用一次。
3、no:调用write,不对aof做同步,有操作系统负责,同步周期最长30秒。
写入缓冲区aof_buf是为了提高文件写入的效率,当调用write函数,会将数据暂存于内存缓冲区,等到空间填满或者时间到,再将缓冲区数据写入硬盘。
2、AOF文件数据载入还原
答:上面的演示可以看到AOF文件包含了重建数据库状态的所有命令,所有数据恢复时候服务器只需要执行一遍文件中的命令,就能还原关闭之前的数据库状态。
详细过程就是这样:
- 创建一个伪客户端,目的是从本地AOF文件而不是网络连接读取写命令。
- 从AOF文件中分析并读取一条命令。
- 使用伪客户端执行这条命令。
- 重复2、3步骤,直到AOF保存的所有命令被执行完毕。
我们来简单验证一下,先退出客户端和服务器端会显示如下,说明进行了AOF持久化:
[19992] 10 May 15:18:12.021 * 1 changes in 900 seconds. Saving...
[19992] 10 May 15:18:12.865 * Background saving started by pid 2892
[19992] 10 May 15:18:13.367 # fork operation complete
[19992] 10 May 15:18:13.370 * Background saving terminated with success
[19992] 10 May 15:18:13.367 # fork operation complete
[19992] 10 May 15:18:13.370 * Background saving terminated with success
[19992] 10 May 16:50:14.547 # User requested shutdown...
[19992] 10 May 16:50:14.548 * Calling fsync() on the AOF file.
[19992] 10 May 16:50:14.552 * Saving the final RDB snapshot before exiting.
[19992] 10 May 16:50:14.605 * DB saved on disk
[19992] 10 May 16:50:14.605 # Redis is now ready to exit, bye bye...然后再启动服务器和客户端,可以发到数据载入没有丢失。
服务器显示从AOF文件加载数据:
[11672] 10 May 16:50:33.345 # Server started, Redis version 3.2.100
[11672] 10 May 16:50:33.379 * DB loaded from append only file: 0.031 seconds
[11672] 10 May 16:50:33.379 * The server is now ready to accept connections on port 6379再启动客户端,数据依然存在。

3、AOF文件重写(Rewrite)
重写机制:把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
(1)已经超时的数据不在写入文件。
(2)旧的AOF文件含有无效命令,重新进程内新的AOF文件只保留最终数据的写入命令。
(3)多条写命令可以合并为一个。
目的:降低文件占用的空间;更小的AOF文件可以被服务器更快的加载。
正是AOF持久化机制保存文件的特点,带来了一个问题是,随着AOF文件越来越多,文件体积变大,这可能对数据库服务器和计算机影响很大。比如,客户端请求命令包括许多个RPUSH,AOF也保存了这一连串的命令,所以AOF重写功能实现冗余命令的去除,使得文件体积变得更小。
具体实现原理:首先创建一个新的AOF文件,对于一连串同类型的命令,比如列表键(RPUSH)和集合键(SADD)的写入,先遍历数据库中的所有键值,然后用一条命令代替之前记录这些键值的多条命令,用新的AOF文件代替旧的AOF,保存的数据库状态是相同的。
现在简单验证一下,添加4条列表键值对:
127.0.0.1:6379> Rpush list "A" "B"
(integer) 2
127.0.0.1:6379> rpush list "C"
(integer) 3
127.0.0.1:6379> rpush list "D" "E"
(integer) 5
127.0.0.1:6379> rpush list "F"
(integer) 6手动触发重写,调用BGREWRITEAOF函数。
127.0.0.1:6379> bgrewriteaof
Background append only file rewriting started
(0.82s)查看AOF重新文件,发现合并为一条命令:

4、后台重写过程
上面举的例子使用了手动触发方式调用BGREWRITEAOF函数让AOF重写文件,另外还有自动触发,由配置文件两个参数决定。
手动触发:直接调用bgrewriteaof命令。
自动触发:根据下面两个参数自动触发。
auto-aof-rewrite-min-size:运行AOF重写时文件的最小体积,默认64M。
auto-aof-rewrite-percentage:当前AOF文件空间和冲刺重写后的空间大小比值。当大于文件最小体积且比值大于等于设定的值,则自动触发。
可以看到重写过程需要时间,Redis数据库是单线程处理命令请求的,因此如果有大量的写入操作,将会长时间阻塞,服务器无法处理客户端发送的请求。
所以解决方法就是,Redis将重新程序放到子进程中,由子进程执行,服务器进程仍然可以继续处理客户端的请求。
这样的好处,子进程带有父进程的数据副本,而不像线程那样,可以在不用锁机制的情况下,保证数据的安全性。
不过,正是解决了原来服务器阻塞无法处理Client请求的问题,这时又带来了一个问题,是什么呢?
子进程在进行AOF重写期间,注意重写是对旧的AOF文件进行操作,服务器处理了客户端请求,这些命令可能对数据库进行更新修改,导致了数据库不一致的状态。
为了解决这个新的问题,引入了一个新的AOF重写缓冲区!那现在子进程AOF重写期间,服务器进程需要完成三个事情:
- 执行客户端请求命令;
- 将执行后的写命令追加到AOF缓冲区;
- 将执行后的写命令追加到AOF重写缓冲区。
画个图更加直观,给面试官看!
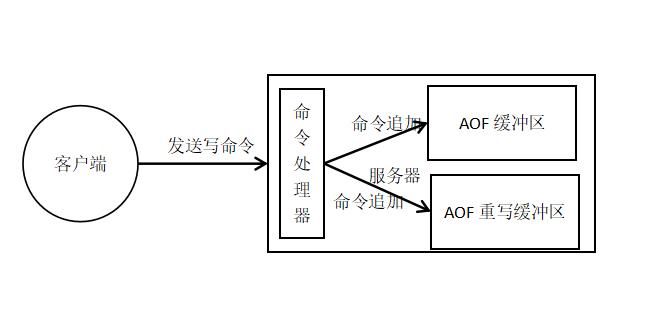
这样终于解决了存在的问题,可以保证数据库一致,具体过程:
- AOF缓冲区的内容会被定时写入和同步到文件。
- 子进程重写开始之后,请求的命令都会保存到AOF重写缓冲区。
- 重写完成之后,子进程发送一个信号通知服务器进程。
- 服务器进行将AOF重写缓冲区的内容写入新的AOF文件,覆盖旧的文件。
- AOF后台重写工作完毕。
三、RDB持久化实现原理呢?
答:有了解过,RDB持久化跟AOF持久化方式不同之处在于,它是通过保存数据键值对的方式记录数据库状态的,将当前数据生成二进制快照文件保存在硬盘中。
1、手动触发:save和bgsave
sava命令直接阻塞服务器进程,直到RDB文件保存完毕,服务器这期间无法处理命令请求。
bgsave命令跟bgwriteaof命令有点相似,通过创建子进程来进行RDB持久化,服务器仍然可以处理请求。
验证一下,客户端输入两条命令并调用手动save命令。
127.0.0.1:6379> sadd city "A"
(integer) 1
127.0.0.1:6379> sadd city "B"
(integer) 1
127.0.0.1:6379> save
OK服务器端显示:

打开dump.rdb文件,看到二进制格式的数据。

需要注意的是,加载RDB文件的时候,服务器进程会阻塞直到载入完毕。
2、自动触发:间隔保存条件
自动触发保存RDB文件,则是通过设置变量参数值。在redies.windows.conf配置文件中可以看到:
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000意思就是只要满足三个条件中的一个,则自动执行RDB持久化:
- 服务器在900秒内,对数据库进行了至少1次修改。
- 服务器在300秒内,对数据库进行了至少10次修改。
- 服务器在60秒内,对数据库进行了至少10000次修改。
服务器检测到900s内有1次修改,触发RDB保存。
[22228] 10 May 21:20:40.053 * 1 changes in 900 seconds. Saving...
[22228] 10 May 21:20:40.426 * Background saving started by pid 13364
[22228] 10 May 21:20:40.629 # fork operation complete
[22228] 10 May 21:20:40.629 * Background saving terminated with success这写参数条件保存在savaparams数组中,另外服务器通过维护一个dirty计数器和lastsave属性,遍历数组后判断是否满足条件,实现RDB持久化的自动触发。
dirty计数器:命令修改一次数据库则计数加一。
lastsave属性:记录上次执行保存操作的时间戳。
四、那AOF和RDB持久化区别在哪,优缺点呢?
1、AOF的优缺点
答:那先说优点。
- AOF持久化实时性好,可以更好的保护数据不丢失,默认AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
- AOF文件以append-only模式写入,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
缺点也回答一二:
- 对于同一份数据来说,AOF文件通常比RDB数据快照文件更大,原因在前面有提到。
- AOF是基于命令日志重放数据库状态的方式,比基于RDB每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有bug。
2、RDB的优缺点
答:很多时候对同一件事有不同的处理方式,那RDB和AOF的优缺点应该就是相反的。
优点:
- 压缩紧凑的二进制文件,代表Redis某个时间点上的数据快照,文件体积小。
- 加载RDB文件恢复数据速度远远快于AOF。
缺点:
- 不能做到实时持久化,bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,成本高。
- 特定二进制格式保存,各版本有多种格式RDB,老版本Redis无法兼容新版本的RDB格式。
五、总结一下
时间过得太快了,没想到面试官对Redis数据库问得这么详细,已经过去1个小时,小C把Redis的AOF和RDB持久化方式原理和实践都给讲的明明白白!
他看了看时间,说:不错啊,原理讲得很详细,简单举例实践也有,基础不错,以后能有实际项目应用更好。时间也差不多,回去等HR通知!
看到小C的经历,你是不是觉得 Redis数据库的AOF和RDB持久化基本知识 看一篇就够了,赶紧收藏好,备用!
如果觉得不错欢迎“一键三连”哦,点赞收藏关注,评论提问建议,欢迎交流学习!一起加油进步!

我的CSDN博客:https://csdn-czh.blog.csdn.net/article/details/116596657
以上是关于面试官对数据库问得这么详细!Redis的AOF和RDB持久化方式看一篇就够了!的主要内容,如果未能解决你的问题,请参考以下文章