NoSQL数据库之Redis数据操作持久化Jedis缓存处理的详解
Posted ahcfl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NoSQL数据库之Redis数据操作持久化Jedis缓存处理的详解相关的知识,希望对你有一定的参考价值。
typora-copy-images-to: assets
理解NOSQL的概念
redis的常用数据类型
五种数据类型的命令
redis的string操作命令
redis的hash操作命令
redis的list操作命令
redis的set操作命令
redis的两种持久化机制(了解)
jedis对redis进行操作(通过Java访问Redis)
什么是NoSQL:Not Only SQL通常指定是非关系型数据库
NoSQL有哪四大类?
- 键值对:redis
- 列存储
- 文档型存储:mongodb
- 图形存储方式
- 为什么要使用NoSQL?
解决三高问题:高并发,海量数据存储,高可扩展性和可维护性
一、【NoSQL非关系型】数据库
NoSQL概念
- Not Only SQL 通常指的是非关系型数据库,**通常用于提升数据查询的速度,有时也叫缓存。**Redis是非关系型 数据库的一种。非关系型数据库不能代替关系型数据库,只是关系型数据库的补充。
【1】非关系数据库的本质:内存存储(数据库存储运行在内存中)。如果不持久化,那么数据就会丢失。
【2】数据之间不存在对应关系。
- 关系型数据库:MySQL,Oracle,SQL Server等。数据与数据之间是有关系的:1对1,1对多,多对多。表中还有各种约束,数据添加进去的时候,约束的检查,关系型数据库还是事务控制。如果数据库中数据越来越多的时候,查询速度越来越慢。
【1】数据存储本质:把数据存储在硬盘上(持久化存储)
【2】使用数据表存储数据(表与表之间存在关联关系)
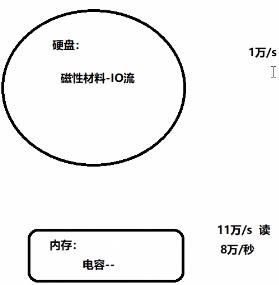
【补充】关于内存和硬盘
1**.硬盘属于磁性材料,交互数据使用IO流**。每秒1万次
2.内存:采用电容方式操作数据。读数据:11万/s 写数据:8万/s
NoSQL数据库的优缺点
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,
可以是文档或者键值对等。
优点
- 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型,例如字符、整数类型。
- 速度快:nosql可以使用硬盘或者随机存储器RAM(也叫主存,是与CPU直接交换数据的内部存储器)作为载体,而关系型数据库只能使用硬盘;
- 成本低:nosql数据库部署简单,基本都是开源软件。
缺点
- 不提供sql支持,学习和使用成本较高;
- 无事务处理;(高版本也逐渐开始支持事务了)
- 数据结构相对复杂,复杂查询方面不方便。
NoSQL数据库的分类
按存储的格式分成四类
1、键值(Key-Value)存储数据库:Map
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Redis**就是这种类型。**Redis是使用C语言编写的,免费开源。
2、列存储数据库
通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。如:Cassandra, HBase, Riak.
3、文档型数据库
文档型数据库可以看作是键值数据库的升级版,允许嵌套键值对。
而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb。
4、图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。
为什么要使用NOSQL
疑问:非关系数据库存储什么样的数据呢?
用于查询比较多,增删改比较少的表。Redis相当于一个缓存,避免了mysql的重复查询。

具体表现为对如下三高问题的解决:
High Performance - 数据库高并发访问
在同一个时间点,同时有海量的用户并发访问。往往要达到每秒上万次读写请求。关系数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。
如天猫的双11,从凌晨0点到2点这段时间,每秒达到上千万次的访问量。
12306春运期间,过年回家买火车抢票的时间,用户不断查询有没有剩余票。
Huge Storage - 海量数据的存储
数据库中数据量特别大,数据库表中每天产生海量的数据。类似QQ,微信,微博,每天用户产生海量的用户动态,每天产生几千万条记录。对于关系数据库来说,在一张几亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。
High Scalability && High Availability- 高可扩展性和高可用性的需求
关系型数据库进行扩展和升级是比较麻烦的一件事,对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。非关系型数据库可以通过不断的添加服务器节点来实现扩展,而不需对原有的数据库进行维护。
二、Redis的数据类型
Redis的5种数据类型
redis是一种高级的key-value的存储系统,键是string类型,其中value支持五种数据类型
键(key):
【1】key值不能重复
【2】作用:标识存储的数据
【3】数据类型:string
【4】命名规则:
1)不能太长:因为查询的效率低,查询起来不方便
2)不能太短:容易重复,同时可读性也差
3)按照规范:HEIMA_STU_LIST
**值(value):**支持5种数据类型
| 值的数据类型 | 值的格式说明 |
|---|---|
| string | 字符串类型,类似于Java中String |
| hash | 由键值对组成,类似于Java中Map |
| list | 列表类型,类似于Java中List,元素是有序,可以重复。 |
| set | 集合类型,类似于Java中Set,元素是无序,不可重复 |
| sorted set/zset | 有序的集合类型,每个元素有一个分数用来决定它的顺序。 |
1、string类型的命令
字符串类型是Redis中最为基础的数据存储类型,它在Redis中以二进制保存。
无论存入的是字符串、整数、浮点类型都会以字符串写入。
在Redis中字符串类型的值最多可以容纳的数据长度是512M,这是以后最常用的数据类型
| 命令 | 功能 |
|---|---|
| set 键 值 | 添加或修改一个键和值,键不存在就是添加,存在就是修改 |
| get 键 | 获取值,如果存在就返回值,不存在返回nil(就是C语言中NULL) |
| del 键 | 删除指定的键和值,返回删除的个数 |
补充:
批量操作:
mset name lisi addr sh 添加或修改多个键和值
mget name age addr 获取多个键对应的值
del name age 删除多指定的键和值
练习:
1. 添加一个键为name,值为zhangsan
2. 再设置一个键为age,值为13
3. 得到name和age的值
4. 删除name
5. 批量添加name lisi addr sh
6. 批量获取name age addr的值
7. 批量删除name age
8. 修改addr的值为bj
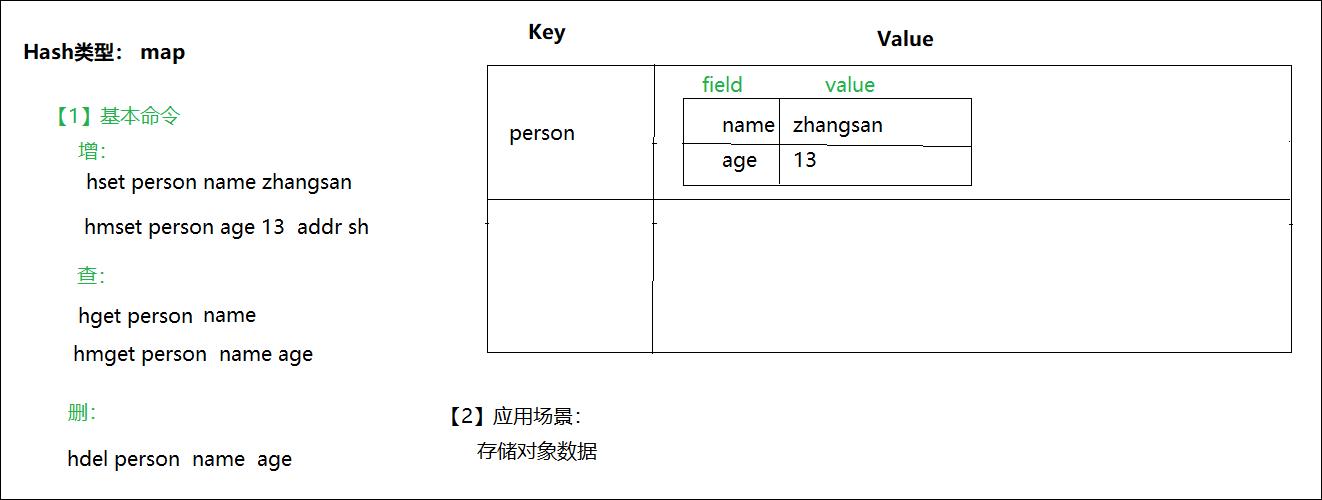
2、hash类型的操作命令
Redis中的Hash类型可以看成是键和值都是String类型的Map容器,
每一个Hash可以存储4G个键值对。
该类型非常适合于存储对象的信息。如一个用户有姓名,密码,年龄等信息,
则可以有username、password和age等键。
| 命令 | 功能 |
|---|---|
| hset 键 字段 值 | 添加键,字段,值 |
| hget 键 字段 | 通过键,字段得到值 |
| hmset 键 字段 值 字段 值 | multiply多个,一次添加多个字段和值 |
| hmget 键 字段 字段 | 通过键,获取多个字段和值 |
| hdel 键 字段 字段 | 删除一个或多个字段的值 |
| hgetall 键 | 得到这个键下所有的字段和值 |
1. 创建hash类型的键为person,并且添加一个字段为name,值为zhangsan
2. 向person中添加字段为age,值为13
3. 向person中批量添加字段为addr,值为sh;字段为company,值为heima
4. 分别得到person中的name、age的字段值
5. 批量得到person中的name、age和addr的字段值
6. 获取person中所有的字段以及对应的值
7. 删除person中的name
8. 批量删除person中的age、addr以及company
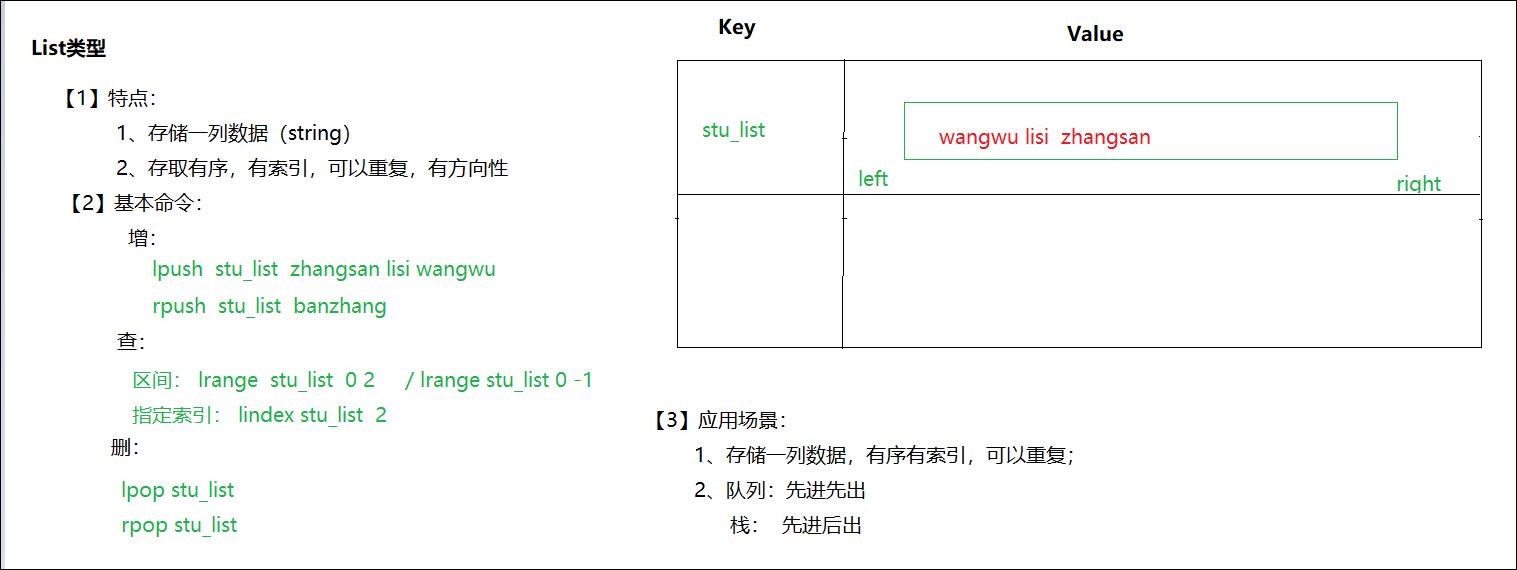
3、list类型的操作命令
**在Redis中,List类型是按照插入顺序排序的字符串链表。**和数据结构中的普通链表一样,我们可以在其左部(left)和右部(right)添加新的元素。
在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。
与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。
List中可以包含的最大元素数量是4G个。
| 命令 | 行为 |
|---|---|
| lpush 键 元素 元素… | left 从左边向指定的键中添加1个或多个元素,返回列表中元素的个数 |
| rpush 键 元素 元素… | right 从右边向指定的键中添加1个或多个元素 |
| lpop 键 | 从左边删除一个元素,返回被删除的元素 |
| rpop 键 | 从右边删除一个元素,返回被删除的元素 |
| lrange 键 开始 结束 | 得到键中指定范围的元素的数据 每个元素都有一个索引号,从左向右0~n 从右向左索引号:-1~-(n+1),每个元素有2个索引号 如果要取出整个列表中所有的元素,索引号应该是:0~-1 |
| lindex 键 索引值 | 查询指定索引的元素 |
| llen 键 | 获取列表的长度 |

1. **从左边添加元素: lpush**
2. **从右边添加元素: rpush**
3. **从左边删除元素: lpop**
4. **从右边删除元素: rpop**
5. **得到指定范围的元素: lrange**
6. **得到列表的长度: llen**
练习:
1. 向mylist键的列表中,从左边添加a b c三个元素
2. 从右边添加one two three三个元素
3. 查询索引0到2的数据
4. 查询所有的元素
5. 查询索引是2的数据
6. 从右边添加一个重复的元素three
7. 删除最左边的元素c
8. 删除最右边的元素three
9. 获取列表中元素的个数
4、set类型的操作命令
在Redis中,我们可以将Set类型看作为没有排序的字符集合,和List类型一样,我们也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。
Set可包含的最大元素数量是4G,和List类型不同的是,Set集合中不允许出现重复的元素。

| 命令 | 行为 |
|---|---|
| sadd 键 元素 元素… | 向一个键中添加1个或多个元素 |
| smembers 键 | 得到这个集合中所有的元素 |
| sismember 键 元素 | 判断指定的元素在集合中是否存在,存在返回1,不存在返回0 |
| srem 键 元素 元素… | 通过键删除一个或多个元素 |
1. **添加元素:sadd**
2. **删除元素:srem**
3. **得到所有元素:smembers**
4. **判断元素是否存在:sismember**
练习:
1. 向myset集合中添加A B C 1 2 3 六个元素
2. 再向myset中添加B元素,看能否添加成功
3. 显示所有的成员,发现与添加的元素顺序不同,元素是无序的
4. 删除其中的C这个元素,再查看结果
5. 判断A是否在myset集合中
6. 判断D是否在myset集合中
5、zset/sorted set类型的操作命令
Redis 有序集合和set集合一样也是无序不可以重复。不同的是每个元素都会关联一个分数(排序因子)。
redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复,每个集合可存储40多亿个成员。

| 命令 | 行为 |
|---|---|
| zadd 键 分数 值 分数 值 | 添加1个或多个元素,每个元素都有一个分数 |
| zrange 键 开始索引 结束索引 | 获取指定范围的元素,得到所有的元素,索引是0到-1 |
| zrange 键 开始索引 结束索引 withscores | 查询指定的元素和对应的分数 |
| zrevrange 键 开始索引 结束索引 withscores | 按照分数倒叙获取指定的元素和对应的分数 |
| zrem 键 值 值 | 删除一个或多个值 |
| zcard 键 | 得到元素个数 |
| zrank 键 值 | 得到元素的索引号 |
| zscore 键 值 | 得到元素的分数 |
| **zadd** | 添加 |
| ---------- | -------- |
| **zrange** | 查询 |
| **zrem** | 删除 |
| **zcard** | 个数 |
| **zrank** | 索引号 |
| **zscore** | 得到分数 |
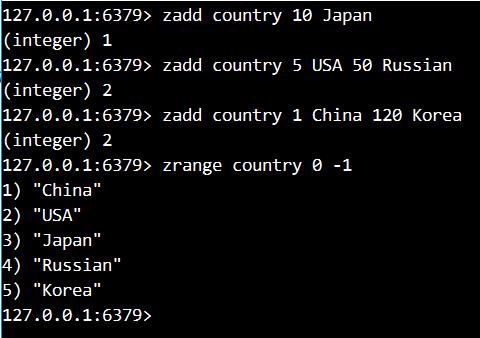
练习:
1. 添加键country,分数排名是10,值是Japan
2. 添加键country,分数排名是5,值是USA,添加键country,分数是50,值是Russia
3. 添加键country,分数排名是1,值是China,分数是120,值是Korea
4. 查询country中所有的元素
5. 查询所有的元素和对应的分数
6. 按照分数倒叙获取所有的元素和对应的分数
7. 查询索引是0 到 1的值
1. 查询Japan的索引号(从0开始)
2. 删除值为USA的元素
3. 查询country中还有多少个元素
4. 显示Russia的分数值
Redis的通用命令
| 命令 | 功能 |
|---|---|
| keys 匹配字符 | 查询所有的键,可以使用通配符 ***** 匹配多个字符 ? 匹配1个字符 |
| del 键1 键2 | 删除任何的值类型,而且可以同时删除多个键 |
| exists 键 | 判断指定的键是否存在 |
| type 键 | 判断指定的键,值的类型。返回是类型的名字 |
| select 数据库编号 | 选择其它的数据库 |
| move 键 数据库编号 | 将当前数据库中指定的键移动到另一个数据库中 |
| expire 键 时间 | 为当前key设置过期时间(单位是秒) |
1. keys: 找到所有的键,通配符:* ?
2. exists:判断指定的键是否存在
3. type: 判断指定键值的类型
4. select:切换数据库默认是0-15
5. move: 将键移动另一个数据库
6. del: 删除多个键
练习:
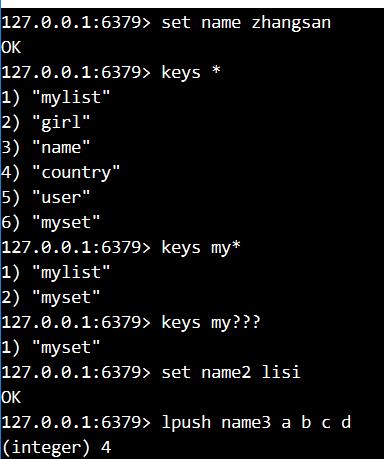
1. 添加字符串name的值为zhangsan, myset 的值为20
2. 显示所有的键
3. 显示所有以my开头的键
4. 显示所有my后面有三个字符的键
5. 添加一个字符串:name2 lisi
6. 添加一个list:name3 a b c d
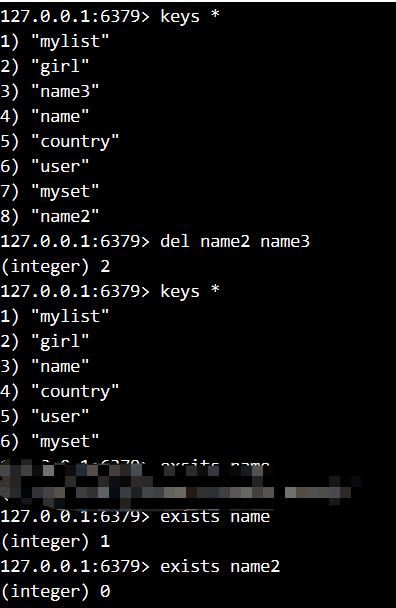
1. 显示所有的键
2. 一次删除name2和name3这两个键,其中name2和name3是不同的类型,显示所有键
3. 分别判断name和name2是否存在
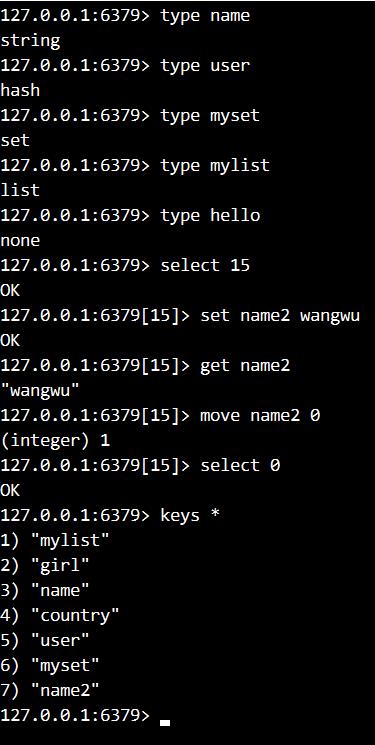
1. 分别判断name user myset mylist分别是什么类型
2. 切换数据库到15,向15中添加一个name2 wangwu,得到name2的值显示。
3. 将15中的name2移到0中
4. 切换到数据库0,显示所有的键
三、Redis持久化机制
问题:把服务端关闭了,再重新开启服务器,数据会不会丢失?
会部分丢失,因为默认redis服务器每隔一段时间写入一次内存中数据到硬盘上。
演示步骤:
1.向redis数据库中存储数据:name zhangsan
2.关闭服务器
3.重启服务器
4.使用客户端连接redis服务器,查看结果。
通过上述演示我们发现name-zhangsan数据丢失了,但是之前存储的数据都还在。
我们可以得知redis属于内存中存储的数据具有一定危险性,数据容易丢失,
但是redis中的数据也可以持久保存,这些和redis持久化是有关联的。
Redis有哪两种持久化机制?RDB持久化的配置?
什么是Redis的持久化?
**持久化:**把内存中的数据保存到硬盘上。 **作用:**防止数据在断电的情况下丢失。
Redis是一个内存存储的数据库,内存必须在通电的情况下才能够对数据进行存储。
如果 ,在使用redis的过程中突然发生断电,数据就会丢失。为了防止数据丢失,
redis提供了数据持久化的支持。redis需要经常将内存中的数据同步到磁盘来保证持久化。
redis支持两种持久化方式,
一种是RDB(快照)也是默认方式,另一种是Append Only File(缩写AOF)的方式。
redis将内存中数据,写在硬盘文件上。服务器关闭,电脑重启数据也不会丢失。
Redis持久化的两种方式:
1、RDB方式[了解]
Redis DataBase 默认的持久化方式。这种方式就是将内存中数据以快照的方式写入到二进制文件中,每隔一段时间写入一次。默认的文件名为:dump.rdb。
补充:快照:当前内存中数据的状态。

可以通过配置设置自动做快照持久化的方式。如下面配置的是RDB方式数据持久化时机,
必须两个条件都满足的情况下才进行持久化的操作:
| 关键字 | 时间(秒) | 修改键数 | 解释 |
|---|---|---|---|
| save | 900 | 1 | 到了15分钟修改了1个键,则发起快照保存 |
| save | 300 | 10 | 到了5分钟修改了10个键,则发起快照保存 |
| save | 60 | 10000 | 到了1分钟,修改了1万个键,则发起快照保存 |
我们很难模拟上面的配置方式,所以我们这里要自己对配置文件进行一个修改。
就可以演示rdb的持久化效果了。
RDB持久化机制配置
-
配置命令:
save 时间秒 修改的键 -
启动服务器:
redis-server 配置文件
下面详细介绍快照保存过程:
1.在redis.windows.conf配置文件中有如下说明:
| 语法 | 说明 |
|---|---|
| save <时间间隔> <修改键数> | 过多久(单位是秒),修改了多少个键(增删改) |
2.修改redis.windows.conf 文件的101行
添加1行:save 20 3 (表示20秒内修改3个键,则写入到dump.rdb文件中)
save 900 1
save 300 10
save 60 10000
save 20 3
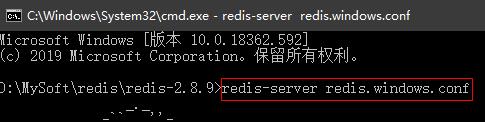
3.使用指定的配置文件启动服务器:redis-server redis.windows.conf
打开dos窗口,使用命令redis-server加载redis.windows.conf 配置文件。
4.打开客户端,向数据库中增加三个键
set name zhangsan
set age 18
set addr sh
直接关闭服务器窗口。然后打开dos窗口,使用命令redis-server加载redis.windows.conf 配置文件,再开启服务器,查看所有的键
数据没有丢失。表示关闭redis数据库服务器的时候,数据被写入到数据库dump.rdb文件中了。再次启动redis服务器将dump.rdb文件中的数据加载到redis服务器中。
RDB持久化机制问题
不能完全避免数据丢失,因为RDB是每隔一段时间写入数据,所以系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2、AOF的存储方式[了解]
AOF的格式:文本文件
文件名: appendonly.aof
三种配置策略
- 每秒记录
- 每修改记录
- 不记录
由于快照方式是在一定间隔时间做一次的,所以如果redis宕机,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用AOF持久化方式。
AOF指的是Append only file,使用AOF持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是appendonly.aof).当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
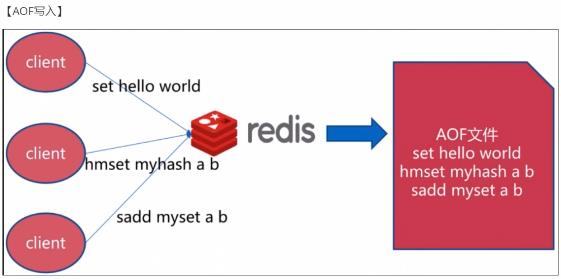
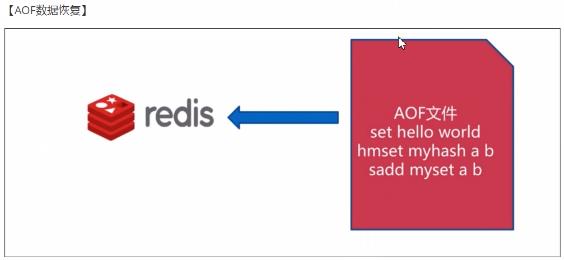
AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。也可以通过该文件完成数据的重建。该机制可以带来更高的数据安全性,所有的操作都是异步完成的。
| Redis中提供了3种同步策略 | 说明 |
|---|---|
| 每秒同步 | 每过一秒中记录一次 |
| 每修改同步 | 每次修改(增删改)都会记录一次 |
| 不同步 | 不记录任何操作 |
AOF持久化机制配置
1、开启AOF持久化
AOF默认是关闭的,首先需要开启AOF模式
| 参数配置 | 说明 |
|---|---|
| appendonly no/yes | 默认是no,关闭。如果要打开,设置成yes。 如果打开的AOF,RDB中存储的数据读取不出来。 |
2、AOF持久化时机
| 关键字 | 持久化时机 | 解释 |
|---|---|---|
| appendfsync | everysec | 每秒记录 |
| appendfsync | always | 每修改记录 |
| appendfsync | no | 不记录 |
everysec:每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中。
always:收到写命令就立即写入磁盘,最慢,但是保证完全的持久化。
no:完全依赖操作系统,性能最好,持久化无法保证。
3、演示:AOF的持久化
-
打开AOF的配置文件redis.windows.conf,找到APPEND ONLY MODE配置块,392行。设置appendonly yes

-
通过redis-server redis.windows.conf 启动服务器,在服务器目录下出现appendonly.aof文件。大小是0个字节。

- 添加3个键和值
- 打开appendonly.aof文件,查看文件的变化。会发现文件记录了所有操作的过程。

说明:
1.*2表示有两个命令 select 0 选择第一个数据库
2.$6表示select 有六个字符 $1 表示0有一个字符
5.再次打开redis服务器,查看结果。redis-server redis.windows.conf 启动服务器
查看上述保存的数据依然存在。
3、AOF重写机制介绍[了解]
为什么需要AOF 重写
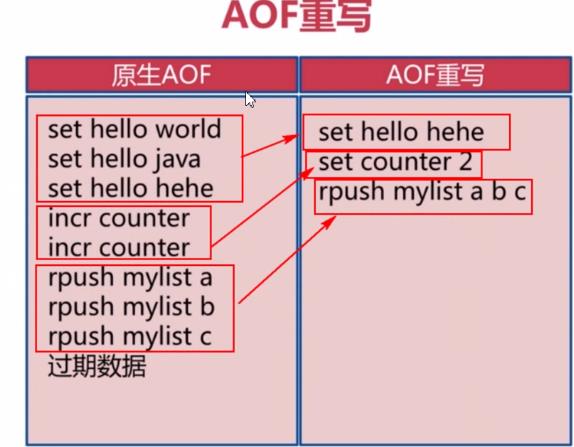
随着命令不断从AOF缓存中写入到AOF文件中,AOF文件会越来越大,为了解决AOF文件体积膨胀的问题,Redis提供了AOF重写功能:Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个文件所保存的数据库状态是相同的,但是新的AOF文件不会包含任何浪费空间的冗余命令,通常体积会较旧AOF文件小很多。简单来说redis引入了AOF重写机制就是来压缩AOF文件的。
AOF重写触发的方式
手动触发
用户通过调用bgrewriteaof命令手动触发。
bgrewriteaof命令:
bg:background 后台
re:repeat 重复
write:写
在客户端直接书写bgrewriteaof命令,这里我们只关注redis文件夹下appendonly.aof文件即可。
不用关注旧的文件了。
appendonly.aof文件被重写了。
自动触发
如果全部满足条件的话,就触发自动的AOF重写操作。

全部满足自动触发的条件:
-
没有RDB持久化/AOF持久化在执行,没有bgrewriteaof在进行;
-
当前AOF文件大小要
大于redis.windows.conf配置的auto-aof-rewrite-min-size大小;
-
当前AOF文件大小和最后一次重写后的大小之间的比率等于或者等于指定的增长百分比(在配置文件设置了auto-aof-rewrite-percentage参数,不设置默认为100%)
原来的数据:

【演示:AOF后台自动重写】
-
关闭服务器,删除生成的aof和rdb文件
-
修改redis.windows.conf配置文件如下:
# 大于原来的10%就自动重写 auto-aof-rewrite-percentage 10 # 自动重写的最小尺寸 auto-aof-rewrite-min-size 10b
3.带配置文件启动服务器: redis-server redis.windows.conf
4.进行一些设置获得等命令操作
5.生成的重写文件

4、AOF 文件重写的实现原理
因为AOF如果记录每一步操作,文件会越来越大,通过AOF的重写,可以缩小AOF文件的尺寸。同样可以达到数据还原效果
AOF重写并不需要对原有AOF文件进行任何的读取,写入,分析等操作,
这个功能是通过读取服务器当前的数据库状态来实现的。
# 假设服务器对键list执行了以下命令
127.0.0.1:6379> RPUSH list "A" "B"
(integer) 2
127.0.0.1:6379> RPUSH list "C"
(integer) 3
127.0.0.1:6379> RPUSH list "D" "E"
(integer) 5
127.0.0.1:6379> LPOP list
"A"
127.0.0.1:6379> LPOP list
"B"
127.0.0.1:6379> RPUSH list "F" "G"
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "C"
2) "D"
3) "E"
4) "F"
5) "G"
127.0.0.1:6379>
分析:
当前列表键list在数据库中的值就为[“C”,“D”, “E”, “F”, “G”]。要使用尽量少的命令来记录list键的状态,最简单的方式不是去读取和分析现有AOF文件的内容,而是直接读取list键在数据库中的当前值,然后用一条RPUSH
list “C” “D” “E” “F” "G"代替前面的6条命令。
5、Redis持久化机制RDB和AOF的区别
RDB持久化机制优点和缺点
优点
- 方便备份与恢复
整个Redis数据库将只包含一个文件,默认是dump.rdb,这对于文件备份和恢复而言是非常完美的。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
- 启动效率更高
相比于AOF机制,如果数据集很大,RDB的启动效率会更高。因为RDB文件中存储的是数据,启动的时候直接加载数据即可,而AOF是将操作数据库的命令存放到AOF文件中,然后启动redis数据库服务器的时候会将很多个命令执行加载数据。如果数据量特别大的时候,那么RDB由于直接加载数据启动效率会比AOF执行命令加载数据更高。
- 性能最大化
对于Redis的服务进程而言**,在开始持久化时,会在后台开辟子线程,由子线程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。**
缺点
- 不能完全避免数据丢失
因为RDB是每隔一段时间写入数据,所以系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
- 会导致服务器暂停的现象
由于RDB是通过子线程来协助完成数据持久化工作的,因此当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
就是数据量过大,会开辟过多的子线程进行持久化操作,那么会占用服务器端的大量资源,那么有可能会造成服务器端卡顿。同时会造成服务器停止几百毫秒甚至一秒。
AOF持久化机制优点和缺点
优点
AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。也可以通过该文件完成数据的重建。该机制可以带来更高的数据安全性,所有的操作都是异步完成的。
缺点
运行效率比RDB更慢:根据同步策略的不同,AOF在运行效率上往往会慢于RDB。
文件比RDB更大:对于相同数量的数据集而言,AOF文件通常要大于RDB文件。
一般在企业开发中两种持久化机制会配合着使用。
四、Jedis与Redis交互
通过dos窗口连接mysql数据库服务器,然后使用SQLYog图形化界面操作mysql数据库服务器,最后使用JDBC操作mysql数据库服务器。同理学习完使用dos窗口和图形化界面操作完redis数据库服务器之后,接下来我们要学习使用java代码如何操作redis数据库服务器。
可以访问redis官网,看下官网对操作redis数据库服务器的客户端的介绍:
https://redis.io/
1.找客户端
2.找星标记和笑脸标记
3.点击java
4.选择jedis
Jedis:java客户端技术-操作redis服务中的数据
Jedis的介绍
Redis不仅可以使用命令来操作,现在基本上主流的语言都有API支持,比如Java、C#、C++、php、Node.js、Go等。
在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis等其中官方推荐使用Jedis和Redisson。 使用Jedis操作redis需要导入核心jar包
或者导入maven的依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
Jedis类常用方法
每个方法就是redis中的命令名,方法的参数就是命令的参数。
在每次访问Redis数据库的时候,都需要创建一个Jedis对象。每个Jedis对象似于JDBC中Connection对象,类似于mybatis中session对象。
| 连接和关闭 | 功能 |
|---|---|
| new Jedis(host, port) | 创建Jedis连接对象,参数: host: 服务器地址 port:端口号6379 |
| void close() | 关闭连接 |
| 对string操作的方法 | 说明 |
|---|---|
| set(String key,String value) | 添加字符串类型的键和值 |
| String get(String key) | 通过键得到字符串的值 |
| del(String … keys) | 删除一个或多个键 |
| 对hash操作的方法 | 说明 |
|---|---|
| hset(String key,String field,String value) | 添加一个hash类型的键,字段和值 |
| Map<String,String> hgetall(String key) | 通过一个键得到所有的字段和值,返回Map |
| 对list操作的方法 | 说明 |
|---|---|
| lpush(String key,String…values) | 从左边添加多个值到list中 |
| List<String> lrange(String key,long start,long end) | 通过键得到指定范围的元素 |
| 对set操作的方法 | 说明 |
|---|---|
| sadd(String key,String…values) | 添加一个或多个元素 |
| Set<String> smembers(String key) | 通过键得到集合所有的元素 |
| 对zset操作的方法 | 说明 |
|---|---|
| zadd(String key, double score, String member) | 添加一个键,分数和值 |
| Set<String> zrange(String key, long start, long end) | 查询一个指定范围的元素 |
Jedis使用【代码演示】
使用Jedis上面的方法来访问Redis,
向服务器中写入字符串、hash和list类型,并且取出打印到控制台上。
操作步骤
1.创建maven的java工程
2.创建maven的web工程
JavaWeb开发【使用Maven开发web项目详解】
将依赖导入到pom.xml文件中:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
</dependencies>
<!--插件管理-->
<build>
<plugins>
<!--编译插件:jdk1.8-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<!-- put your configurations here -->
<!--源码-->
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
3.创建测试类,书写操作redis数据库的代码,代码一共分为三步:
【1】创建jedis对象,连接redis数据库服务器 new Jedis(host,port)
【2】 操作数据
【3】 关闭连接
【1.下面是操作字符串数据的代码】:
1.一次性添加多个字符串数据,使用的方法如下:
mset(key1,value1,key2,value2,...)
2.一次性获取所有的字符串:
List<String> mget(key1,key2,key3...);
public class JedisTest01 {
@Test
public void test01(){
//1.创建jedis对象,连接redis数据库服务器 new Jedis(host,port)
Jedis jedis = new Jedis("127.0.0.1",6379);
//2.操作数据
//【1】字符串
jedis.set("username", "张三");
//获取
String username = jedis.get("username");
System.out.println("username = " + username);
//一次性添加多个数据 mset(key1,value1,key2,value2,...)
jedis.mset("addr", "sh", "company", "京东");
//获取所有的数据
List<String> values = jedis.mget("username", "addr", "company");
System.out.println("values = " + values);
//3.关闭连接
jedis.close();
}
}
【2.下面是操作hash数据的代码】:
1.向hash中添加一个数据:
jedis.hset(key, field, value);
2.向hash中添加多个数据:
jedis.hset(key, map集合);
3.获取hash中所有的数据:
Map<String, String> map1 = jedis.hgetAll(key);
public class JedisTest01 {
@Test
public void test01(){
//1.创建jedis对象,连接redis数据库服务器 new Jedis(host,port)
Jedis jedis = new Jedis("127.0.0.1",6379);
//2.操作数据
以上是关于NoSQL数据库之Redis数据操作持久化Jedis缓存处理的详解的主要内容,如果未能解决你的问题,请参考以下文章